Uncomplicated Reviews of Educational Research Methods
- Mean & Standard Deviation
.pdf version of this page
Descriptive statistics summarize data. To aid in comprehension, we can reorganize scores into lists. For example, we might put test scores in order, so that we can quickly see the lowest and highest scores in a group (this is called an ordinal variable, by the way. You can learn more about scales of measure here ). After arranging data, we can determine frequencies, which are the basis of such descriptive measures as mean, median, mode, range, and standard deviation. Let’s walk through an example using test scores:
Now, we can take those same scores and get some more useful information. Recall that Mean is arithmetic average of the scores, calculated by adding all the scores and dividing by the total number of scores. Excel will perform this function for you using the command =AVERAGE(Number:Number).
Now we know the average score, but maybe knowing the range would help. Recall that Range is the difference between the highest and lowest scores in a distribution, calculated by taking the lowest score from the highest. You can calculate this one by simple subtraction.
Understanding range may lead you to wonder how most students scored. In other words, you know what they scored, but maybe you want to know about where the majority of student scores fell – in other words, the variance of scores. Standard Deviation introduces two important things, The Normal Curve (shown below) and the 68/95/99.7 Rule. We’ll return to the rule soon.

The Normal Curve tells us that numerical data will be distributed in a pattern around an average (the center line).
Standard deviation is considered the most useful index of variability. It is a single number that tells us the variability, or spread, of a distribution (group of scores). Standard Deviation is calculated by:
Step 1. Determine the mean.
Step 2. Take the mean from the score.
Step 3. Square that number.
Step 4. Take the square root of the total of squared scores.
Excel will perform this function for you using the command =STDEV(Number:Number).
That number, 8.40, is 1 unit of standard deviation. The 68/95/99.7 Rule tells us that standard deviations can be converted to percentages, so that:
- 68% of scores fall within 1 SD of the mean.
- 95% of all scores fall within 2 SD of the mean.
- 99.7% of all scores fall within 3 SD of the mean.
For the visual learners, you can put those percentages directly into the standard curve:

Since 1 SD in our example is 8.40, and we know that the mean is 92, we can be sure that 68% of the scores on this test fall between 83.6 and 100.4. To get this range, I simply added 1 SD (8.40) to the mean (92), and took 1 SD away from the mean. Sometimes you see SD referred to as +/- in a journal article, which is indicating the same thing. Note: Quick thinkers will notice that since 50% of the sample is below the mean (to the left of 0 on the curve), you can add percentages. In other words, 84.13% of the scores fall 1SD above the mean. To get that number, I took the percentages between -3 SD and 0 on the left, (which equal 50), then added the percentage from 0 to 1 SD on the right (which is .3413).

Share this:
About research rundowns.
Research Rundowns was made possible by support from the Dewar College of Education at Valdosta State University .
- Experimental Design
- What is Educational Research?
- Writing Research Questions
- Mixed Methods Research Designs
- Qualitative Coding & Analysis
- Qualitative Research Design
- Correlation
- Effect Size
- Instrument, Validity, Reliability
- Significance Testing (t-tests)
- Steps 1-4: Finding Research
- Steps 5-6: Analyzing & Organizing
- Steps 7-9: Citing & Writing
- Writing a Research Report
Blog at WordPress.com.
- Already have a WordPress.com account? Log in now.
- Subscribe Subscribed
- Copy shortlink
- Report this content
- View post in Reader
- Manage subscriptions
- Collapse this bar

Regression to the Mean and Change Score Analysis
Regression to the mean refers to a phenomena where natural variation within an individual can mistakenly appear as meaningful change over time. To illustrate, imagine a patient who comes in for a regular check-up and is found to have high blood sugar levels. This may be cause for concern, and the doctor recommends several dietary adjustments and schedules a follow-up for the next week. During the follow-up visit, the patient’s blood sugar levels have seemingly returned to a normal range. Both the doctor and the patient attribute this reduction in blood sugar to the new diet.
However, the true explanation for these values lies in their statistical nature. Both values actually came from the same distribution, as shown in the Blood Sugar Measurements plot below. The first measurement, “Baseline”, is two standard deviations above the true mean blood sugar for this individual (99). The second value, “Follow-Up”, was much closer to the mean blood sugar level for this patient. The first value is an extremely rare value for this patient and was not representative of their average blood sugar before going on the diet. Therefore, the apparent improvement during the follow-up was not caused by the dietary change but was a result of regression to the mean - the return of a more typical measurement.

When variability is both random and nonsystematic, it results in rare occurrences of extreme values for an individual, making it more probable for them to eventually regress to a normal range over time. Understanding regression to the mean could help avoid misinterpretations and ensure a more accurate assessment of changes in values.
In their 2011 article entitled “Francis Galton and Regression to the Mean”, Stephen Senn delves into the history of the concept of regression to the mean and gives a real world example of its effect on research. In this study, they simulate values of diastolic blood pressure (DBP) for 1,000 people measured at two distinct time points, baseline and follow-up. DBP is categorized as either high DBP (hypertensive; \(\geq\) 95 mmHg) or normal DBP (normotensive; \(<\) 95 mmHg). In their simulation, the measurements have a correlation of about 0.80 and both measurements have a true mean of 90 mmHg and an interquartile range of 11 mmHg.
Let’s recreate their simulation with these parameters. We need to create two variables representing two measurements within 1,000 individuals. We will use the mvrnorm() function from the MASS package (version 7.3-60; Venables & Ripley, 2002) to simulate correlated variables from normal distributions and set the correlation between them to be 0.80. Both variables will be simulated to have a mean of 90. In order to use the mvrnorm() function, we need to convert interquartile range into units of standard deviation. Since a normal distribution’s interquartile range is approximately 1.35 standard deviations, we divide 11 by 1.35, giving us an approximate standard deviation of 8.
Now we have a data frame called df which contains two variables, “Baseline” and “FollowUp” that are correlated at 0.80 and each have a mean of around 90. Let’s look at a basic scatter plot of the two variables using the ggplot2 package (version 3.4.2; Wickham, 2016).

Visually we can see that these two variables are positively, linearly related to one another with some variation since they are not perfectly correlated with one another. In the Senn (2011) article they show a scatter plot grouping individuals by whether or not they were hypertensive at both time points, normotensive at both time points, or inconsistent (i.e., hypertensive at one time point and normotensive at the other). We will reproduce these below. First, let’s create a variable called “Trend” which contains the labels “Both Hypertensive”, “Both Normotensive”, and “Inconsistent” to represent each individual’s category. Then, we can add this to the previous scatter plot and change the shape and color of the points based on which category the individual falls in. We’ll also use geom_vline() and geom_hline() to add vertical and horizontal lines to the plot representing the true mean of the population the samples came from. Finally, we use geom_abline() to add a line with a slope of 1, as was done in Senn (2011).

Most of the sample (62.5%) was normotensive at both measurements, 18.1% of the sample is hypertensive at both measurements, and 19.4% of the sample were in different categories across the two time points. Since the true correlation between the variables is 0.80, there will be variation over time within individuals, but it is most probable for individuals to fall into a normotensive range at both time points.
Senn (2011) states that in reality, what we see in the above plot would not be the sample collected in most clinical trials. They state that in most clinical trials, follow-ups would not be conducted with individuals who present as normotensive at baseline. Instead, only individuals presenting as hypertensive would be asked to come back. In the following plot we use all the same settings as the above plot except that we subset the data set to contain only those individuals who are hypertensive-at-baseline.

Let’s say this data came from a clinical trial where participants were given some sort of manipulation (e.g., trial blood pressure medication) between baseline and follow-up. What would happen if we conducted a statistical analysis to test if DBP was reduced at follow-up? To see how many individuals did have a reduction in DBP, let’s change the color coding in the above plot to represent direction of change in DBP from baseline to follow-up.

Of the individuals with hypertension at baseline, a majority of them exhibited a decrease in blood pressure. In fact, for hypertensive-at-baseline individuals, the mean DBP at follow-up is 97.85, which is 2.35 mmHg lower than the mean baseline value (100.24). This change is attributable to regression to the mean rather than a meaningful reduction in DBP.
Senn (2011) provides some solutions to the problem of misattributing this change as meaningful:
- Include a control group,
- Investigate the differences between groups at the follow-up,
- Conduct a three-arm trial including an active (experimental) group, a placebo group, and a group given no manipulation (control group).
They favor the third approach since regression to the mean would appear in each group, then causal statements in the experimental and placebo groups would be more strongly supported.
Participants can get assigned into experimental groups in two general ways: random assignment or nonrandom assignment. Random assignment into experimental groups is considered the gold standard in experimental design; participants have an equal probability of being placed in experimental groups, thereby removing as many potential confounding variable effects as possible. Nonrandom assignment, however, means that participants are being placed into experimental groups based on some criteria. Within experimental groups, participants are more related to one another based on the assignment criteria, and between experimental groups participants are less related to one another based on the assignment criteria. This introduces differences in the experimental groups beyond just the experimental manipulation, (i.e., confounding variable(s)).
In the current example of blood pressure, it is possible that researchers believe it is unethical to withhold treatment from hypertensive individuals. Therefore, participants with higher DBP at baseline will be prioritized for the experimental group above participants with lower DBP. For the purposes of the present example, we will investigate the impact of both random and nonrandom assignment.
There are three common analyses used to assess experimental manipulation with baseline and follow-up values: dependent means t -test, change score analysis, and analysis of covariance (ANCOVA). The dependent means t -test tests whether there is a difference in the mean values between follow-up and baseline. We specifically use the dependent means t -test (rather than the independent means t -test) because we are comparing values within individuals.
Change score analysis tests the effect of treatment on the change in score from baseline to follow-up. The difference between baseline and follow-up values (change score) is calculated and the mean change score between experimental groups is compared. For change score analysis, we will use an independent means t -test when there are two experimental groups and an analysis of variance (ANOVA) when there are three experimental groups.
The ANCOVA method tests the mean difference in follow-up values between experimental groups, after adjusting for baseline value. It models follow-up values as the dependent variable and the experimental group as an independent variable, with baseline value as a covariate. Simply put, the ANCOVA method tests the effect of the experimental group on the follow-up values that is not explained by the baseline values.
Let’s run a simulation to compare the results of these analyses. Per the suggestions in Senn (2011) we will look at the impact of having a two-arm (experimental and control group) and a three-arm (experimental, control, and placebo group) design and compare this to the results of looking at change within individuals. We can look at the results of these analytic approaches across two types of samples, one with only individuals presenting as hypertensive-at-baseline, and one where all-baseline-DBP-levels are included. Additionally, let’s consider scenarios where random assignment and nonrandom assignment to experimental groups take place.
Because the scores at baseline and follow-up come from the same population, each analysis should not find significant differences. We will simulate 500 datasets of 1000 cases each, then sample from them to create a hypertensive-at-baseline sample and an all-baseline-DBP-levels sample. Then, we will conduct each statistical analysis on each sample. The p -value from each analysis will be recorded and then we can investigate any patterns in detecting significance based on sampling approach and experimental design. We will simulate 500 datasets in the same manner as above using the mvrnorm() function, also with the same parameters as above. Each dataset will be saved into a list of data frames called df.list .
Now we will sample from these data frames to create two types of samples: hypertensive-at-baseline and all-baseline-DBP-levels. In order to avoid any conflating effects of power, each sample will have a sample size of 250. Each new data frame will have seven variables:
- “Baseline” is the DBP value at baseline,
- “FollowUp” is the DBP value at follow-up,
- “ChangeScore” is calculated as the baseline value minus the follow-up value,
- “two.arm_random” represents random assignment to groups in a two-arm experimental design,
- “two.arm_nonrandom” represents nonrandom assignment to groups in a two-arm experimental design, where participants with higher baseline DBP are assigned to the experimental group and participants with lower baseline DBP are assigned to the control group,
- “three.arm_random” represents random assignment to groups in a three-arm experimental design,
- “three.arm_nonrandom” represents nonrandom assignment to groups in a three-arm experimental design where participants with higher baseline DBP are assigned to the experimental group and participants with lower baseline DBP are assigned to either the control group or placebo group.
Each new data frame will get stored in a list of data frames. Hypertensive-at-baseline samples will get stored into a list called hyper.list and samples with all-baseline-DBP-levels will get stored into a list called all.list . Both lists have length 500 since there are 500 samples.
On each data frame, we will conduct a dependent means t -test using the t.test() function comparing baseline to follow-up, making sure to set “paired = TRUE” (since the values across variables are dependent). As shown below, from the output of each t -test we can extract the p -value using $p.value .
The end goal of this simulation is to compare the proportion of times statistical significance is found across analytic technique, experimental design, and sampling approach. The easiest way to investigate this is to save all of the results into a single data frame, which we will call sim.df . We will iterate through both hyper.list and all.list conducting dependent means t -tests on each simulation condition, adding labels for the conditions, and merging this data into the sim.df object.
We now have a data frame called sim.df which contains the results of 1,000 dependent means t -tests (500 for hypertensive-at-baseline samples, and 500 for all-baseline-DBP-levels samples).
Next, let’s merge in the results of change score analyses. For the two-arm experimental design, we will run an independent means t -test comparing the change score across experimental groups. This time, the “paired” argument will be set to FALSE in the t.test() function since the values are independent.
For the three-arm experimental design, we will run an ANOVA comparing the change score means across the three experimental groups. We will use the Anova() function from the car package (version 3.1-2; Fox, 2019). The output of the Anova() function is structured such that we can attach $`Pr(>F)`[1] to the end of the function to extract the p -value.
We can iterate through hyper.list and all.list as before, conducting change score analyses on each simulation condition, adding labels for the conditions, and merging this data into the sim.df object.
Finally, let’s merge in the results of conducting an ANCOVA. For the ANCOVA, we will again use the Anova() function, modeling follow-up values by the experimental groups after controlling for baseline values. In this case, we’re interested in whether or not there are significant differences between experimental groups. Therefore, because of the way the model is specified, we want the second p -value from the “Pr(>F)” values and will attach $`Pr(>F)`[2] to the end of the function to extract this.
Now let’s iterate through both the hyper.list and all.list , assign the experimental design and sampling labels, and merge the results into sim.df .
Simulation Results
Now, let’s compare the results of these analyses across simulation conditions. First, we’ll add a variable to sim.df called “Significance” which will take on the value “Significant” if the “p.value” variable is less than .05 and “Non-Significant” otherwise.
Since the dependent means t -test comparing baseline and follow-up values was only run split by sampling method and not either experimental design methods, we will look at the results of it separately. Using a combination of the dplyr package (version 1.1.2; Wickham et al., 2023) and the ggplot2 package, we will create a bar plot split by sampling method. The bars will be stacked to represent the proportion of times within 500 samples the dependent means t -test was significant or non-significant.

When sampling from all-baseline-DBP-levels, 4% of the 500 samples showed significant differences between mean baseline and mean follow-up scores. However, when only sampling from those individuals presenting as hypertensive-at-baseline, 100% of the 500 samples showed significant differences. Recall we simulated this data with no treatment effect. By restricting our sample to those with DBP > 95 at baseline, we get statistically significant differences between baseline and follow-up 100% of the time despite there being no intervention when using a dependent means t -test.
For the change score analysis and ANCOVA methods, we can create a similar plot just looking at the proportion of significant/non-significant results across sampling methods.

In both sampling methods, the ANCOVA method finds significance about 5% of the time, which is the expected \(\alpha\) level of .05. However, change score analysis has a higher rate of significance than the ANCOVA within both sampling methods. Change score analysis finds significant differences between experimental groups 51.4% of the time when sampling from all-baseline-DBP-levels, and 29.25% of the time when sampling from only hypertensive-at-baseline individuals.
What would happen if we split this down further by experimental design methods?

The right hand portion of this plot indicates how many experimental groups were included, three-arm being the first row and two-arm being the second row. The top portion of the plot indicates the sampling approach and randomization method. Sampling from all-baseline-DBP-levels is represented in the first two columns, split by nonrandom assignment in the first column and random assignment in the second column. Sampling from hypertensive-at-baseline individuals is represented in the last two columns, split by nonrandom assignment in the third column, and random assignment in the fourth column.
Even when split by experimental design methods, the ANCOVA method maintains around a 5% rate of significance while the change score analysis has a much higher proportion of significant findings. The number of experimental groups appears to have no effect on the proportion of significant and non-significant findings. However, for change score analysis, nonrandom assignment has a much higher proportion of significant results than random assignment for both sampling methods. Nonrandom assignment produces significant results almost 100% of the time when sampling from all-baseline-DBP-levels and a little over 50% of the time when sampling from hypertensive-at-baseline individuals. Random assignment, in both sampling methods, produces significant results about 5% of the time (again, in line with the expected \(\alpha\) level of .05).
These results highlight the impact of misattributing natural variation as meaningful change. Based on the results of this small simulation, regression to the mean has particular influence on the results of dependent means t -tests and change score analyses, especially when sampling is not representative of the population and participants are not randomly assigned to experimental groups. Using an ANCOVA to analyze these data seems to be the best approach, still keeping in mind best practice for sampling methods and experimental design. Without proper sampling methods, experimental design, and analytic techniques, regression to the mean can impact the results of any study, mistaking natural variation within individuals for meaningful change.
- Fox J, Weisberg S (2019). An R Companion to Applied Regression , Third edition. Sage, Thousand Oaks CA. https://socialsciences.mcmaster.ca/jfox/Books/Companion/ .
- Galton, F. (1886) Regression towards mediocrity in hereditary stature. Journal of the Anthropological Institute of Great Britain and Ireland, 15, 246–263.
- Senn, S. (2011). Francis Galton and regression to the mean. Significance, 8(3), 124-126.
- Venables, W. N. & Ripley, B. D. (2002) Modern Applied Statistics with S. Fourth Edition. Springer, New York. ISBN 0-387-95457-0
- H. Wickham. ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York, 2016.
- Wickham H, François R, Henry L, Müller K, Vaughan D (2023). dplyr: A Grammar of Data Manipulation . R package version 1.1.2, https://CRAN.R-project.org/package=dplyr .
Laura Jamison StatLab Associate University of Virginia Library September 15, 2023
For questions or clarifications regarding this article, contact [email protected] .
View the entire collection of UVA Library StatLab articles, or learn how to cite .
Research Data Services
Want updates in your inbox? Subscribe to our monthly Research Data Services Newsletter!
Related categories:
If you're seeing this message, it means we're having trouble loading external resources on our website.
If you're behind a web filter, please make sure that the domains *.kastatic.org and *.kasandbox.org are unblocked.
To log in and use all the features of Khan Academy, please enable JavaScript in your browser.
Statistics and probability
Course: statistics and probability > unit 3.
- Statistics intro: Mean, median, & mode
- Mean, median, & mode example
Mean, median, and mode
Calculating the mean.
- Calculating the median
- Choosing the "best" measure of center
Mean, median, and mode review
Practice problems
- Your answer should be
- an integer, like 6
- a simplified proper fraction, like 3 / 5
- a simplified improper fraction, like 7 / 4
- a mixed number, like 1 3 / 4
- an exact decimal, like 0.75
- a multiple of pi, like 12 pi or 2 / 3 pi
Finding the median
- Arrange the data points from smallest to largest.
- If the number of data points is odd, the median is the middle data point in the list.
- If the number of data points is even, the median is the average of the two middle data points in the list.
Finding the mode
Practice problem, want to join the conversation.
- Upvote Button navigates to signup page
- Downvote Button navigates to signup page
- Flag Button navigates to signup page

- Foundations
- Write Paper
Search form
- Experiments
- Anthropology
- Self-Esteem
- Social Anxiety
- Statistics >
Statistical Mean
In Statistics, the statistical mean, or statistical average, gives a very good idea about the central tendency of the data being collected.
This article is a part of the guide:
- Calculate Standard Deviation
- Standard Error of the Mean
- Assumptions
- Normal Distribution
Browse Full Outline
- 1 Frequency Distribution
- 2.1 Assumptions
- 3 F-Distribution
- 4.1.1 Arithmetic Mean
- 4.1.2 Geometric Mean
- 4.1.3 Calculate Median
- 4.2 Statistical Mode
- 4.3 Range (Statistics)
- 5.1.1 Calculate Standard Deviation
- 5.2 Standard Error of the Mean
Statistical mean gives important information about the data set at hand, and as a single number, can provide a lot of insights into the experiment and nature of the data .

The concept of statistical mean has a very wide range of applicability in statistics for a number of different types of experimentation.
For example, if a simple pendulum is being used to measure the acceleration due to gravity, it makes sense to take a set of values, and then average the final result. This eliminates the random errors in the experiment and usually gives a more accurate value than a single experiment carried out.
The statistical mean also gives a good idea about interpreting the statistical data.
For example, the mean life expectancy in Japan is higher than that of Brazil, which suggests that on an average, the people in Japan are likely to live longer. There may be many viable conclusions about this, such as that it is due to better healthcare facilities in Japan, but the truth is that we do not know this unless we measure it.
Similarly, the mean height of people in Russia is higher than that of China, which means that on an average, you will find Russians to be taller than Chinese.
Statistical mean is a measure of central tendency and gives us an idea about where the data seems to cluster around.
For example, the mean marks obtained by students in a test is required to correctly gauge the performance of a student in that test. If the student scores a low percentage, but is well ahead of the mean, then it means the test is difficult and therefore his performance is good, something that simply a percentage will not be able to tell.

Different Statistical Means
There are different kinds of statistical means or measures of central tendency for the data points. Each one has its own utility. The arithmetic mean , geometric mean , median and mode are some of the most commonly used measures of statistical mean. They make sense in different situations, and should be used according to the distribution and nature of the data.
For example, the arithmetic mean is frequently used in scientific experimentation , the geometric mean is used in finance to calculate compounding quantities, the median is used as a robust mean in case of skewed data with many outliers and the mode is frequently used in determining the most frequently occurring data, like during an election.
- Psychology 101
- Flags and Countries
- Capitals and Countries
Siddharth Kalla (Jan 13, 2009). Statistical Mean. Retrieved May 26, 2024 from Explorable.com: https://explorable.com/statistical-mean
You Are Allowed To Copy The Text
The text in this article is licensed under the Creative Commons-License Attribution 4.0 International (CC BY 4.0) .
This means you're free to copy, share and adapt any parts (or all) of the text in the article, as long as you give appropriate credit and provide a link/reference to this page.
That is it. You don't need our permission to copy the article; just include a link/reference back to this page. You can use it freely (with some kind of link), and we're also okay with people reprinting in publications like books, blogs, newsletters, course-material, papers, wikipedia and presentations (with clear attribution).
Want to stay up to date? Follow us!
Save this course for later.
Don't have time for it all now? No problem, save it as a course and come back to it later.
Footer bottom
- Privacy Policy

- Subscribe to our RSS Feed
- Like us on Facebook
- Follow us on Twitter
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Mean Scores – tricks and traps

In recent posts, we examined the nature of the data types available to consumer or B2B market researchers including; nominal, ordinal, interval and ratio . The latter two categories allow the user to generate mean score or averages as part of their survey data analysis . Working with means gives the researcher access to a wealth of multivariate statistics, but mean scores are not without their issues. Let’s look at a few of them.
First, means are heavily influenced by extreme scores, also known as outliers. These high and/or low scores can pull the mean up or down depending upon their location. This is why variables that focus on wealth, income or prices are typically reported using the median, e.g. the median housing price or median monthly income. Variables with numerical categories such as customer satisfaction or brand awareness tend to be less influenced by outliers. Options for dealing with outliers include removing them from analysis or recoding them with the median value. Either option is not without considerations that need to be addressed. These are beyond the scope of this post.
Another concern is the overall distribution of the datapoints. If half of the survey respondents say they like their coffee hot while the other half say they like it cold, then the ‘mean’ is going to be in the middle or lukewarm. In cases such as this, the mean or average would be misleading. Further commentary by the researcher outlining the distribution of the data is called for. This highlights the distribution and makes it easier for the decision-maker to derive understanding.
In survey research , be it market or otherwise, if we report the mean score then we should also report the standard deviation, the median, and possibly the range (high – low) as well. These supporting statistics provide the end-user a picture to better understand the nature of the data. A graphic can also be useful.
Within all consumer data lays variation. This variability can show up clearly when looking at mean scores if you have the right filter applied.
Learn more about working with mean scores by reviewing Data Analysis .
MORE LIKE THIS
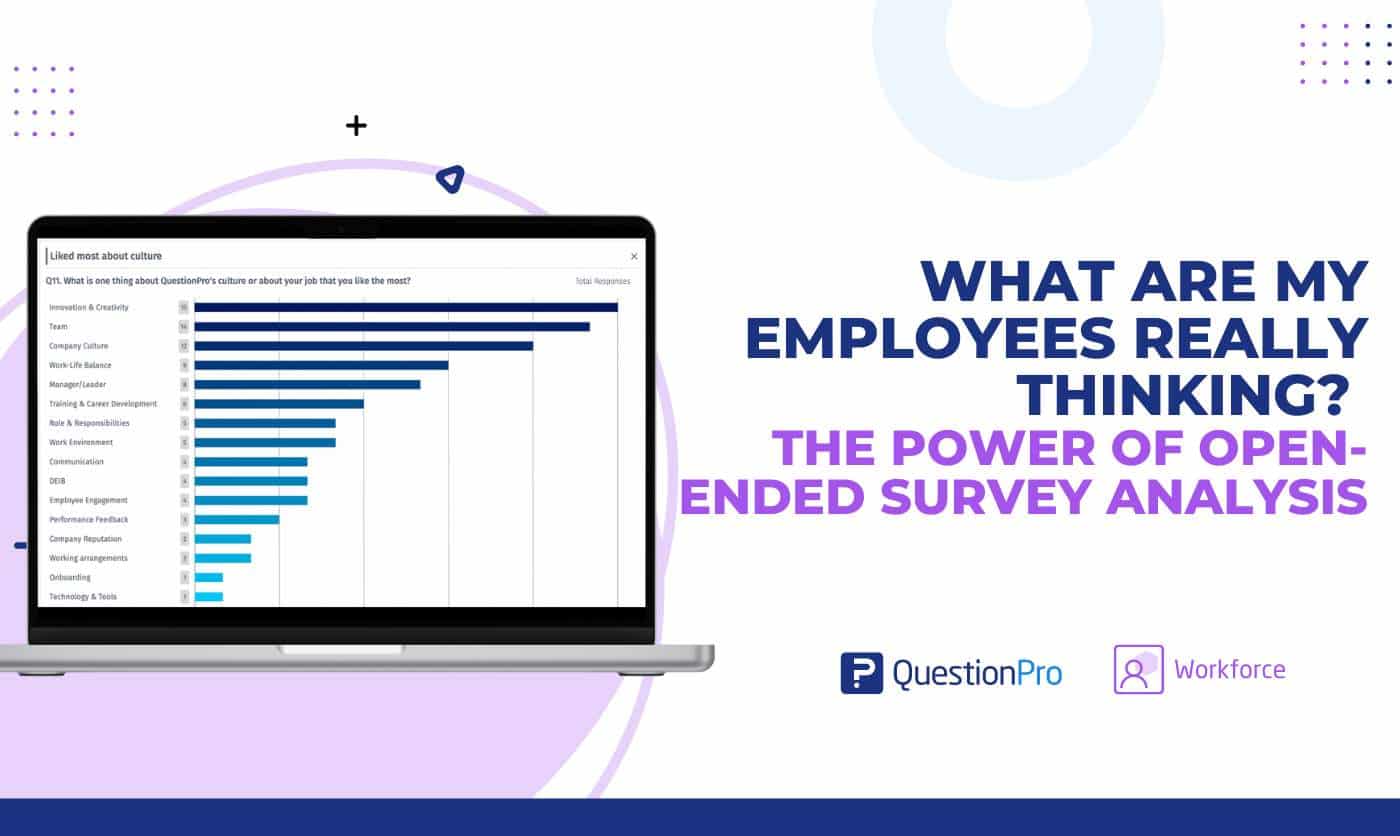
What Are My Employees Really Thinking? The Power of Open-ended Survey Analysis
May 24, 2024

I Am Disconnected – Tuesday CX Thoughts
May 21, 2024

20 Best Customer Success Tools of 2024
May 20, 2024

AI-Based Services Buying Guide for Market Research (based on ESOMAR’s 20 Questions)
Other categories.
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence
How to find the mean score of a set of numbers
Last updated
16 April 2023
Reviewed by
Cathy Heath
People often talk about finding the average of a set of numbers, such as household income, test scores, or traffic accidents. However, in statistics, there are several types of averages. The mean score is often used and differs from other averages, such as median and mode.
Make research less tedious
Dovetail streamlines research to help you uncover and share actionable insights
- What is a mean score?
A mean score, also known as the arithmetic average, is calculated by adding up all the values in a set of numbers and then dividing by the total number of values. The mean score is often used as a measure of central tendency, which represents the typical or most representative value in a dataset.
How to find a mean score
Let's take an example to see how a mean score is found. Suppose you want to find the mean score of students who took a test. Assume that there are a total of 10 test scores:
Adding up these numbers, we get a total of 789. Dividing this by 10, we get 78.9, which can be rounded up to 80.
For another example, suppose a theater or stadium wanted to calculate the mean attendance over three events.
The total for the three events is 32,191. Dividing this total by 3, we get 10,730.
What are mean scores and standard scores?
Standard scores are scores with the same mean and standard deviation. Standard deviation is used to account for variations from the mean. For example, the mean test score for students is 95%. However, the standard score may be lower if we account for the standard deviation created by a few students who scored 98%–100%.
- Types of mean score
The arithmetic mean, as defined above, is the most commonly used type of mean score. There are also others.
Weighted mean
Often used in statistics, a weighted mean is for when certain variables are more important (or carry more "weight") than others.
It's calculated by multiplying each value in a set by its assigned weight and then adding up the totals.
As is often the case, not all tests are equal in terms of an overall study grade. For example, suppose you want to calculate a weighted mean for a student’s performance on three exams. Suppose the first two exams contribute 25% of the student's grade while the third contributes 50%. The student then gets the following grades on each exam.
Exam 1: 80%
Exam 2: 100%
Exam 3: 90%
Multiply the grades by the weight.
Exam 1: .25 x 80 = 20
Exam 2: .25 x 100 = 25
Exam 3: .50 x 90 = 45
Now we would add up the totals: 20 + 25 + 45 = 90. The weighted average is 90 for the student’s overall grade.
Geometric mean
Geometric means are often used to track the performance of investments, profits, or economic variables such as the inflation rate. It allows investors and analysts to identify the long-term value of an investment.
The geometric mean is calculated by multiplying all values and then identifying the nth root of the product, where n is the number of values.
If you wanted to find the geometric mean between two numbers, such as 4 and 9, you would first multiply them, giving you 36. You would then take the square root of 36, which is 6, which is the geometric mean.
There are certain limitations when it comes to geometric means. It can only be used for positive numbers and cannot be used if losses are involved. If any of the variables is 0, the geometric average will also be 0.
Harmonic mean
Harmonic means are often used to compare companies’ price-earning ratios (P/E). It is especially useful when there is a need to give greater weight to smaller variables.
The harmonic mean is found by dividing the number of items in a series by the sum of each number's reciprocal. The reciprocal is found by dividing one by that number. For example, the reciprocal of four is 1/4.
If we want to find the harmonic mean of the values 4, 2, and 4, we'd add the reciprocal values.
.25 + .5 + .25 = 1
Since there are three items, we get 3/1 = 1.
- Mean vs. other types of averages
When people speak of averages, they may be referring to other frequently-used metrics such as:
Median — The middle value of a series. For example, in the series of numbers 1 through 10, the median is 5.5.
Mode — The number that occurs most frequently in a data set. For example, if you have a set of exam scores of 63, 70, 94, 59, 84, 70, and 88, the mode would be 70. Mode is most useful when you have a large data set and want to identify the most common value.
Range — The largest number minus the smallest number in a series. For example, in the series of numbers 2, 8, 12, 24, and 45, the range is 45-2 = 43.
- What are the uses of mean score?
Mean scores are helpful for identifying typical or frequently occurring scores or values. Teachers and school administrators want to know students' mean scores to track learning and progress. Financial advisors need to be aware of how assets perform over time, so mean scores help track the ups and downs of the market.
- Factors affecting mean scores
When analyzing data, it helps to be aware of factors that can affect your results. These may include any of the following.
These are values that are much higher or lower than the average and can affect the mean. For example, a student who scores much higher or lower than their classmates will raise or lower the mean. A very wealthy individual moving into a small town will artificially inflate the area’s mean income.
Seasonal factors
In business and finance, seasonal factors such as weather, holidays, and typical consumer habits can affect data. For example, data might show that mean retail profits rose in December, but this is likely to be a normal holiday fluctuation and not necessarily indicative of an economic upturn.
Differences in groups
- Advantages and disadvantages of mean score
There are advantages and disadvantages to using mean scores. The main advantage of mean scores is that they provide a clear idea of the central or most common tendency. The downside is that outliers can distort the mean. You can avoid this by calculating the standard score. Using other averages, such as the median, can also give you a more complete understanding of the data.
Should you be using a customer insights hub?
Do you want to discover previous research faster?
Do you share your research findings with others?
Do you analyze research data?
Start for free today, add your research, and get to key insights faster
Editor’s picks
Last updated: 11 January 2024
Last updated: 15 January 2024
Last updated: 17 January 2024
Last updated: 25 November 2023
Last updated: 12 May 2023
Last updated: 30 April 2024
Last updated: 13 May 2024
Latest articles
Related topics, .css-je19u9{-webkit-align-items:flex-end;-webkit-box-align:flex-end;-ms-flex-align:flex-end;align-items:flex-end;display:-webkit-box;display:-webkit-flex;display:-ms-flexbox;display:flex;-webkit-flex-direction:row;-ms-flex-direction:row;flex-direction:row;-webkit-box-flex-wrap:wrap;-webkit-flex-wrap:wrap;-ms-flex-wrap:wrap;flex-wrap:wrap;-webkit-box-pack:center;-ms-flex-pack:center;-webkit-justify-content:center;justify-content:center;row-gap:0;text-align:center;max-width:671px;}@media (max-width: 1079px){.css-je19u9{max-width:400px;}.css-je19u9>span{white-space:pre;}}@media (max-width: 799px){.css-je19u9{max-width:400px;}.css-je19u9>span{white-space:pre;}} decide what to .css-1kiodld{max-height:56px;display:-webkit-box;display:-webkit-flex;display:-ms-flexbox;display:flex;-webkit-align-items:center;-webkit-box-align:center;-ms-flex-align:center;align-items:center;}@media (max-width: 1079px){.css-1kiodld{display:none;}} build next, decide what to build next.

Users report unexpectedly high data usage, especially during streaming sessions.

Users find it hard to navigate from the home page to relevant playlists in the app.

It would be great to have a sleep timer feature, especially for bedtime listening.

I need better filters to find the songs or artists I’m looking for.
Log in or sign up
Get started for free

Mean, Mode and Median
Mean, mode and median are popular quantitative research methods used in business, as well as, engineering and computer sciences. In business studies these methods can be used in data comparisons such as comparing performances of two different businesses within the same period of time or comparing performance of the same business during different time periods.
Mean implies average and it is the sum of a set of data divided by the number of data. Mean can prove to be an effective tool when comparing different sets of data; however this method might be disadvantaged by the impact of extreme values.
Mode is the value that appears the most. A given set of data can contain more than one mode, or it can contain no mode at all. Extreme values have no impact on mode in data comparisons, however, the effectiveness of mode in data comparisons are compromised in the presence of more than one mode.
Median is the middle value when the data is arranged in numerical order. It is another effective tool to compare different sets of data, however, the negative impact of extreme values is lesser on median compared to mean.

John Dudovskiy

An official website of the United States government
The .gov means it's official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you're on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- Browse Titles
NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024 Jan-.

StatPearls [Internet].
Exploratory data analysis: frequencies, descriptive statistics, histograms, and boxplots.
Jacob Shreffler ; Martin R. Huecker .
Affiliations
Last Update: November 3, 2023 .
- Definition/Introduction
Researchers must utilize exploratory data techniques to present findings to a target audience and create appropriate graphs and figures. Researchers can determine if outliers exist, data are missing, and statistical assumptions will be upheld by understanding data. Additionally, it is essential to comprehend these data when describing them in conclusions of a paper, in a meeting with colleagues invested in the findings, or while reading others’ work.
- Issues of Concern
This comprehension begins with exploring these data through the outputs discussed in this article. Individuals who do not conduct research must still comprehend new studies, and knowledge of fundamentals in analyzing data and interpretation of histograms and boxplots facilitates the ability to appraise recent publications accurately. Without this familiarity, decisions could be implemented based on inaccurate delivery or interpretation of medical studies.
Frequencies and Descriptive Statistics
Effective presentation of study results, in presentation or manuscript form, typically starts with frequencies and descriptive statistics (ie, mean, medians, standard deviations). One can get a better sense of the variables by examining these data to determine whether a balanced and sufficient research design exists. Frequencies also inform on missing data and give a sense of outliers (will be discussed below).
Luckily, software programs are available to conduct exploratory data analysis. For this chapter, we will be examining the following research question.
RQ: Are there differences in drug life (length of effect) for Drug 23 based on the administration site?
A more precise hypothesis could be: Is drug 23 longer-lasting when administered via site A compared to site B?
To address this research question, exploratory data analysis is conducted. First, it is essential to start with the frequencies of the variables. To keep things simple, only variables of minutes (drug life effect) and administration site (A vs B) are included. See Image. Figure 1 for outputs for frequencies.
Figure 1 shows that the administration site appears to be a balanced design with 50 individuals in each group. The excerpt for minutes frequencies is the bottom portion of Figure 1 and shows how many cases fell into each time frame with the cumulative percent on the right-hand side. In examining Figure 1, one suspiciously low measurement (135) was observed, considering time variables. If a data point seems inaccurate, a researcher should find this case and confirm if this was an entry error. For the sake of this review, the authors state that this was an entry error and should have been entered 535 and not 135. Had the analysis occurred without checking this, the data analysis, results, and conclusions would have been invalid. When finding any entry errors and determining how groups are balanced, potential missing data is explored. If not responsibly evaluated, missing values can nullify results.
After replacing the incorrect 135 with 535, descriptive statistics, including the mean, median, mode, minimum/maximum scores, and standard deviation were examined. Output for the research example for the variable of minutes can be seen in Figure 2. Observe each variable to ensure that the mean seems reasonable and that the minimum and maximum are within an appropriate range based on medical competence or an available codebook. One assumption common in statistical analyses is a normal distribution. Image . Figure 2 shows that the mode differs from the mean and the median. We have visualization tools such as histograms to examine these scores for normality and outliers before making decisions.
Histograms are useful in assessing normality, as many statistical tests (eg, ANOVA and regression) assume the data have a normal distribution. When data deviate from a normal distribution, it is quantified using skewness and kurtosis. [1] Skewness occurs when one tail of the curve is longer. If the tail is lengthier on the left side of the curve (more cases on the higher values), this would be negatively skewed, whereas if the tail is longer on the right side, it would be positively skewed. Kurtosis is another facet of normality. Positive kurtosis occurs when the center has many values falling in the middle, whereas negative kurtosis occurs when there are very heavy tails. [2]
Additionally, histograms reveal outliers: data points either entered incorrectly or truly very different from the rest of the sample. When there are outliers, one must determine accuracy based on random chance or the error in the experiment and provide strong justification if the decision is to exclude them. [3] Outliers require attention to ensure the data analysis accurately reflects the majority of the data and is not influenced by extreme values; cleaning these outliers can result in better quality decision-making in clinical practice. [4] A common approach to determining if a variable is approximately normally distributed is converting values to z scores and determining if any scores are less than -3 or greater than 3. For a normal distribution, about 99% of scores should lie within three standard deviations of the mean. [5] Importantly, one should not automatically throw out any values outside of this range but consider it in corroboration with the other factors aforementioned. Outliers are relatively common, so when these are prevalent, one must assess the risks and benefits of exclusion. [6]
Image . Figure 3 provides examples of histograms. In Figure 3A, 2 possible outliers causing kurtosis are observed. If values within 3 standard deviations are used, the result in Figure 3B are observed. This histogram appears much closer to an approximately normal distribution with the kurtosis being treated. Remember, all evidence should be considered before eliminating outliers. When reporting outliers in scientific paper outputs, account for the number of outliers excluded and justify why they were excluded.
Boxplots can examine for outliers, assess the range of data, and show differences among groups. Boxplots provide a visual representation of ranges and medians, illustrating differences amongst groups, and are useful in various outlets, including evidence-based medicine. [7] Boxplots provide a picture of data distribution when there are numerous values, and all values cannot be displayed (ie, a scatterplot). [8] Figure 4 illustrates the differences between drug site administration and the length of drug life from the above example.
Image . Figure 4 shows differences with potential clinical impact. Had any outliers existed (data from the histogram were cleaned), they would appear outside the line endpoint. The red boxes represent the middle 50% of scores. The lines within each red box represent the median number of minutes within each administration site. The horizontal lines at the top and bottom of each line connected to the red box represent the 25th and 75th percentiles. In examining the difference boxplots, an overlap in minutes between 2 administration sites were observed: the approximate top 25 percent from site B had the same time noted as the bottom 25 percent at site A. Site B had a median minute amount under 525, whereas administration site A had a length greater than 550. If there were no differences in adverse reactions at site A, analysis of this figure provides evidence that healthcare providers should administer the drug via site A. Researchers could follow by testing a third administration site, site C. Image . Figure 5 shows what would happen if site C led to a longer drug life compared to site A.
Figure 5 displays the same site A data as Figure 4, but something looks different. The significant variance at site C makes site A’s variance appear smaller. In order words, patients who were administered the drug via site C had a larger range of scores. Thus, some patients experience a longer half-life when the drug is administered via site C than the median of site A; however, the broad range (lack of accuracy) and lower median should be the focus. The precision of minutes is much more compacted in site A. Therefore, the median is higher, and the range is more precise. One may conclude that this makes site A a more desirable site.
- Clinical Significance
Ultimately, by understanding basic exploratory data methods, medical researchers and consumers of research can make quality and data-informed decisions. These data-informed decisions will result in the ability to appraise the clinical significance of research outputs. By overlooking these fundamentals in statistics, critical errors in judgment can occur.
- Nursing, Allied Health, and Interprofessional Team Interventions
All interprofessional healthcare team members need to be at least familiar with, if not well-versed in, these statistical analyses so they can read and interpret study data and apply the data implications in their everyday practice. This approach allows all practitioners to remain abreast of the latest developments and provides valuable data for evidence-based medicine, ultimately leading to improved patient outcomes.
- Review Questions
- Access free multiple choice questions on this topic.
- Comment on this article.
Exploratory Data Analysis Figure 1 Contributed by Martin Huecker, MD and Jacob Shreffler, PhD
Exploratory Data Analysis Figure 2 Contributed by Martin Huecker, MD and Jacob Shreffler, PhD
Exploratory Data Analysis Figure 3 Contributed by Martin Huecker, MD and Jacob Shreffler, PhD
Exploratory Data Analysis Figure 4 Contributed by Martin Huecker, MD and Jacob Shreffler, PhD
Exploratory Data Analysis Figure 5 Contributed by Martin Huecker, MD and Jacob Shreffler, PhD
Disclosure: Jacob Shreffler declares no relevant financial relationships with ineligible companies.
Disclosure: Martin Huecker declares no relevant financial relationships with ineligible companies.
This book is distributed under the terms of the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International (CC BY-NC-ND 4.0) ( http://creativecommons.org/licenses/by-nc-nd/4.0/ ), which permits others to distribute the work, provided that the article is not altered or used commercially. You are not required to obtain permission to distribute this article, provided that you credit the author and journal.
- Cite this Page Shreffler J, Huecker MR. Exploratory Data Analysis: Frequencies, Descriptive Statistics, Histograms, and Boxplots. [Updated 2023 Nov 3]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024 Jan-.
In this Page
Bulk download.
- Bulk download StatPearls data from FTP
Related information
- PMC PubMed Central citations
- PubMed Links to PubMed
Similar articles in PubMed
- Contour boxplots: a method for characterizing uncertainty in feature sets from simulation ensembles. [IEEE Trans Vis Comput Graph. 2...] Contour boxplots: a method for characterizing uncertainty in feature sets from simulation ensembles. Whitaker RT, Mirzargar M, Kirby RM. IEEE Trans Vis Comput Graph. 2013 Dec; 19(12):2713-22.
- Review Univariate Outliers: A Conceptual Overview for the Nurse Researcher. [Can J Nurs Res. 2019] Review Univariate Outliers: A Conceptual Overview for the Nurse Researcher. Mowbray FI, Fox-Wasylyshyn SM, El-Masri MM. Can J Nurs Res. 2019 Mar; 51(1):31-37. Epub 2018 Jul 3.
- Qualitative Study. [StatPearls. 2024] Qualitative Study. Tenny S, Brannan JM, Brannan GD. StatPearls. 2024 Jan
- [Descriptive statistics]. [Rev Alerg Mex. 2016] [Descriptive statistics]. Rendón-Macías ME, Villasís-Keever MÁ, Miranda-Novales MG. Rev Alerg Mex. 2016 Oct-Dec; 63(4):397-407.
- Review Graphics and statistics for cardiology: comparing categorical and continuous variables. [Heart. 2016] Review Graphics and statistics for cardiology: comparing categorical and continuous variables. Rice K, Lumley T. Heart. 2016 Mar; 102(5):349-55. Epub 2016 Jan 27.
Recent Activity
- Exploratory Data Analysis: Frequencies, Descriptive Statistics, Histograms, and ... Exploratory Data Analysis: Frequencies, Descriptive Statistics, Histograms, and Boxplots - StatPearls
Your browsing activity is empty.
Activity recording is turned off.
Turn recording back on
Connect with NLM
National Library of Medicine 8600 Rockville Pike Bethesda, MD 20894
Web Policies FOIA HHS Vulnerability Disclosure
Help Accessibility Careers
- Open access
- Published: 24 May 2024
Rosace : a robust deep mutational scanning analysis framework employing position and mean-variance shrinkage
- Jingyou Rao 1 ,
- Ruiqi Xin 2 na1 ,
- Christian Macdonald 3 na1 ,
- Matthew K. Howard 3 , 4 , 5 ,
- Gabriella O. Estevam 3 , 4 ,
- Sook Wah Yee 3 ,
- Mingsen Wang 6 ,
- James S. Fraser 3 , 7 ,
- Willow Coyote-Maestas 3 , 7 &
- Harold Pimentel ORCID: orcid.org/0000-0001-8556-2499 1 , 8 , 9
Genome Biology volume 25 , Article number: 138 ( 2024 ) Cite this article
Metrics details
Deep mutational scanning (DMS) measures the effects of thousands of genetic variants in a protein simultaneously. The small sample size renders classical statistical methods ineffective. For example, p -values cannot be correctly calibrated when treating variants independently. We propose Rosace , a Bayesian framework for analyzing growth-based DMS data. Rosace leverages amino acid position information to increase power and control the false discovery rate by sharing information across parameters via shrinkage. We also developed Rosette for simulating the distributional properties of DMS. We show that Rosace is robust to the violation of model assumptions and is more powerful than existing tools.
Understanding how protein function is encoded at the residue level is a central challenge in modern protein science. Mutations can cause diseases and drive evolution through perturbing protein function in a myriad of ways, such as by altering its conformational ensemble and stability or its interaction with ligands and binding partners. In these contexts, mutations may result in a loss of function, gain of function, or a neutral phenotype (i.e., no discernable effects). Mutations also often exert effects across multiple phenotypes, and these perturbations can ultimately propagate to alter complex processes in cell biology and physiology. Reverse genetics approaches offer a powerful handle for researchers to investigate biology via introducing mutations and observing the resulting phenotypic changes.
Deep mutational scanning (DMS) is a technique for systematically determining the effect of a large library of mutations individually on a phenotype of interest by performing pooled assays and measuring the relative effects of each variant (Fig. 1 A) [ 1 , 2 , 3 ]. It has improved clinical variant interpretation [ 4 ] and provided insights into the biophysical modeling and mechanistic models of genetic variants [ 5 ]. Taking enzymes as an example, these phenotypes could include catalytic activity [ 6 ] or stability [ 7 , 8 ]. For a transcription factor, the phenotype could be DNA binding specificity or transcriptional activity [ 9 ]. The relevant phenotype for a membrane transporter might be folding and trafficking or substrate transport [ 10 ]. These phenotypes are often captured by growth-based [ 7 , 10 , 11 , 12 , 13 , 14 , 15 , 16 ], binding-based [ 9 , 17 , 18 ], or fluorescence-based assays [ 8 , 10 , 19 ]. Those experiments are inherently differently designed and merit separate analysis frameworks. In growth-based assays, the relative growth rates of cells are of interest. In a binding-based assay, the selection probabilities are of interest. In fluorescence-based assays, changes to the distribution of reporter gene expression are measured. In this paper, we focus solely on growth-based screens.

Deep mutational scanning and overview of Rosace framework. A Each amino acid of the selected protein sequence is mutated to another mutant in deep mutational scanning. B Cells carrying different variants are grown in the same pool under selection pressure. At each time point, cells are sequenced to output the count table. Replications can be produced either pre-transfection or post-transfection. C Rosace is an R package that accepts input from the raw sequencing count table and outputs the posterior distribution of functional score
In a growth-based DMS experiment, we grow a pool of cells carrying different variants under a selective pressure linked to gene function. At set intervals, we sequence the cells to identify each variant’s frequency in the pool. The change in the frequency over the course of the experiment, from initial frequencies to subsequent measurements, serves as a metric of the variant’s functional effects (Fig. 1 B). The functional score is often computed for each variant in the DMS screen and compared against those of synonymous mutations or wild-type cells to display the relative functional change of the protein caused by the mutation. Thus, reliable inference of functional scores is crucial to understanding both individual mutations and at which residue location variants tend to have significant functional effects.
The main challenge of functional score inference is that even under the simplest model, there are at least two estimators required for each mutation (mean and variance of functional change), and in practice, it is rare to have more than three replicates. As a result, it has been posited that under naïve estimators that have been commonly employed, there are likely issues with the false discovery rate and the statistical power of detecting mutations that significantly change the function of the protein [ 20 ]. Regardless, incorporating domain-specific assumptions is required to make inference tractable with few samples and thousands of parameters.
To alleviate the small-sample-size inference problem in DMS, four commonly used methods have been developed: dms_tools [ 21 ], Enrich2 [ 18 ], DiMSum [ 20 ], and EMPIRIC [ 22 ]. dms_tools uses Bayesian inference for reliable inference. However, rather than giving a score to each variant, dms_tools generates a score for each amino acid at each position, assuming linear addition of multiple mutation effects and ignoring epistasis coupling. Thus, dms_tools is not directly comparable to other methods and is excluded from our benchmarking analysis. Enrich2 simplifies the variance estimator by assuming that counts are Poisson-distributed (the variance being equal to the mean) and combines the replicates using a random-effect model. DiMSum , however, argues that the assumption in Enrich2 is not enough to control type-I error. As a result, DiMSum builds upon Enrich2 and includes additional variance terms to model the over-dispersion of sequencing counts. However, as presented in Faure et al. 2020 [ 20 ], this ratio-based method only applies to the DMS screen with one round of selection, while many DMS screens have more than two rounds of selection (i.e., sampling at multiple time points) [ 10 , 11 , 23 ]. Alternatively, EMPIRIC fits a Bayesian model that infers each variant separately with non-informative uniform prior to all parameters and thus does not shrink the estimates to robustly correct the variance in estimates due to the small sample size. Further, the model does not accommodate multiple replicates. In addition, mutscan [ 24 ], a recently developed R package for DMS analysis, employed two established statistical models edgeR and limma-voom . However, these two methods were originally designed for RNA-seq data and the data generation process for DMS is very different. One of the key differences is consistency among replicates. In RNA-seq, gene expression is relatively consistent across replicates under the same condition, while in DMS, counts of variants can vary much since the a priori representation in the initial variant library can be vastly inconsistent among replicates.
While these methods provide reasonable regularization of the score’s variance, additional information can further improve the prior. One solution is incorporating residue position information. It has been noted that amino acids in particular regions have an oversized effect on the protein’s function, and other frameworks have incorporated positions for various purposes. In the form of hidden Markov models (HMMs) and position-specific scoring matrices (PSSMs), this is the basis for the sensitive detection of homology in protein sequences [ 25 ]. These results directly imply that variants at the same position likely share some similarities in their behavior and thus that incorporating local information into modeling might produce more robust inferences. However, no existing methods have incorporated residue position information into their models yet.
To overcome these limitations, we present Rosace , the first growth-based DMS method that incorporates local positional information to increase inference performance. Rosace implements a hierarchical model that parameterizes each variant’s effect as a function of the positional effect, thus providing a way to incorporate both position-specific information and shrinkage into the model. Additionally, we developed Rosette , a simulation framework that attempts to simulate several properties of DMS such as bimodality, similarities in behavior across similar substitutions, and the overdispersion of counts. Compared to previous simulation frameworks such as the one in Enrich2 , Rosette uses parameters directly inferred from the specific input experiment and generates counts that reflect the true level of noise in the real experiment. We use Rosette to simulate several screening modalities and show that our inference method, Rosace , exhibits higher power and controls the false discovery rate (FDR) better on average than existing methods. Importantly, Rosace and Rosette are not two views of the same model— Rosette is based on a set of assumptions that are different from or even opposite to those of Rosace . Rosace ’s ability to accommodate data generated under different assumptions shows its robustness. Finally, we run Rosace on real datasets and it shows a much lower FDR than existing methods while maintaining similar power on experimentally validated positive controls.
Overview of Rosace framework
Rosace is a Bayesian framework for analyzing growth-based deep mutational scanning data, producing variant-level estimates from sequencing counts. The full (position-aware) method requires as input the raw sequencing counts and the position labels of variants. It outputs the posterior distribution of variants’ functional scores, which can be further evaluated to conduct hypothesis testing, plotting, and other downstream analyses (Fig. 1 C). If the position label is hard to acquire with heuristics, for example, in the case of random multiple-mutation data, position-unaware Rosace model can be run without position label input. Rosace is available as an R package. To generate the input of Rosace from sequencing reads, we share a Snakemake workflow dubbed Dumpling for short-read-based experiments in the GitHub repository described in the “ Methods ” section. Additionally, Rosace supports input count data processed from Enrich2 [ 18 ] for other protocols such as barcoded sequencing libraries.
Rosace hierarchical model with positional information and score shrinkage
Here, we begin by motivating the use of positional information. Next, we describe the intuition of how we use the positional information. Finally, we describe the remaining dimensions of shrinkage which assist in robust estimates with few experiment replicates.
A variant is herein defined as the amino acid identity at a position in a protein, where that identity may differ from the wild-type sequence. In this context, synonymous, missense, nonsense, and indel variants are all considered and can be processed by Rosace (see the “ Methods ” section for details). The sequence position of a variant p ( v ) provides information on the functional effects to the protein from the variant. We define the position-level functional score \(\phi _{p(v)}\) as the mean functional score of all variants on a given position.
To motivate the use of positional information, we take the posterior distribution of the position-level functional score estimated from a real DMS experiment, a cytotoxicity-based growth screen of a human transporter, OCT1 (Fig. 2 A). In this experiment, variants with decreased activity are expected to increase in abundance, as they lose the ability to import a cytotoxic substrate during selection, and variants with increased activity will decrease in abundance similarly. We observe that most position-level score estimates \(\widehat{\phi }_{p(v)}\) significantly deviate from the mean, implying that position has material idiosyncratic variation and thus carries information about the protein’s functional architecture.

Rosace shares information at the same position to inform variant effects. A Smoothed position-specific score (sliding window = 5) across positions from OCT1 cytotoxicity screen. Red dotted lines at score = 0 (neutral position). B A conceptual view of the Rosace generative model. Each position has an overall effect, from which variant effects are conferred. Note the prior is wide enough to allow effects that do not follow the mean. Wild-type score distribution is assumed to be at 0. C Plate model representation of Rosace . See the “ Methods ” section for the description of parameters
To incorporate the positional information into our model, we introduce a position-specific score \(\phi _{p(v)}\) where p ( v ) maps variant v to its amino acid position. The variant-specific score \(\beta _v\) is regularized and controlled by the value of \(\phi _{p(v)}\) . To illustrate the point, we conceptually categorize position into three types: positively selected ( \(\phi _{p(v)} \gg 0\) ), (nearly) neutral ( \(\phi _{p(v)} \approx 0\) ), and negatively selected ( \(\phi _{p(v)} \ll 0\) ) (Fig. 2 B). Variants in a positively selected position tend to have scores centered around the positive mean estimate of \(\phi _{p(v)}\) , and vice versa for the negatively selected position. Variants in a neutral position tend to be statistically non-significant as the region might not be important to the measured phenotype.
Regularization of the score’s variance is achieved mainly by sharing information across variants within the position and asserting weakly informative priors on the parameters (Fig. 2 C). Functional scores of the variants within the position are drawn from the same set of parameters \(\phi _{p(v)}\) and \(\sigma _{p(v)}\) . The error term \(\epsilon _{g(v)}\) in the linear regression on normalized counts is also shared in the mean count group (see the “ Methods ” section) to prevent biased estimation of the error and incorporate mean-variance relationship commonly modeled in RNA-seq [ 26 , 27 ]. Importantly, while we use the position information to center the prior, the prior is weak enough to allow variants at a position to deviate from the mean. For example, we show that the nonsense variants indeed deviate from the positional mean (Additional file 1: Fig. S3). The variant-level intercept \(b_v\) is given a strong prior with a tight distribution centered at 0 to prevent over-fitting.
Rosace performance on various datasets
To test the performance of Rosace , we ran Rosace along with Enrich2 , mutscan (both limma-voom and edgeR ), DiMSum , and simple linear regression (the naïve method) on the OCT1 cytotoxicity screen. DiMSum cannot analyze data with three selection rounds, so we ran DiMSum with only the first two time points. The data is pre-processed with wild-type normalization for all three methods. The analysis is done on all subsets of three replicates ( \(\{1\}, \{2\}, \{3\}, \{1,2\}, \{1,3\}, \{2,3\}, \{1,2,3\}\) ).
While we do not have a set of true negative control variants, we assume most synonymous mutations would not change the phenotype, and thus, we use synonymous mutation as a proxy for negative controls. We compute the percentage of significant synonymous mutations called by the hypothesis testing as one representation of the false discovery rate (FDR). The variants are ranked based on the hypothesis testing statistics from the method ( p -value for frequentist methods and local false sign rate [ 28 ], or lfsr ) for Bayesian methods). In an ideal scenario with no noise, the line of ranked variants by FDR is flat at 0 and slowly rises after all true variants with effect are called. Rosace has a very flat segment among the top 25% of the ranked variants compared to DiMSum , Enrich2 , and the naïve method and keeps the FDR lower than mutscan(limma) and mutscan(edgeR) until the end (Fig. 3 A). Importantly, we note that the Rosace curve moves only slightly from 1 replicate to 3 replicates, while the other methods shift more, implying that the change in the number of synonymous mutations called is minor for Rosace , despite having fewer replicates (Fig. 3 A).

False discovery rate and sensitivity on OCT1 cytotoxicity data. A Percent of synonymous mutations called (false discovery rate) versus ranked variants by hypothesis testing. The left panel is from taking the mean of analysis of the three individual replicates. Ideally, the line would be flat at 0 until all the variants with true effects are discovered. B Number of validated variants called (in total 10) versus number of replicates. If only 1 or 2 replicates are used, we iterate through all possible combinations. For example, the three points for Rosace on 2 replicates use Replicate \(\{1, 2\}\) , \(\{1, 3\}\) , and \(\{2, 3\}\) respectively. (DiMSum can only process two time points, and thus is disadvantaged in experiments such as OCT1)
While lower FDR may result in lower power in the method, we show that Rosace is consistently powerful in detecting the OCT1-positive control variants. Yee et al. [ 10 ] conducted lower-throughput radioligand uptake experiments in HEK293T cells and validated 10 variants that have a loss-of-function or gain-of-function phenotype. We use the number of validated variants to approximate the power of the method. As shown in Fig. 3 B, Rosace has comparable power to Enrich2 , mutscan(limma) , and mutscan(edgeR) regardless of the number of replicates, while the naïve method is unable to detect anything in the case of one replicate. Rosace calls significantly fewer synonymous mutations than every other method while maintaining high power, showing that Rosace is robust in real data.
In OCT1, loss of function leads to enrichment rather than depletion, which is relatively uncommon. To complement findings on OCT1, we conducted a similar analysis on the kinase MET data [ 11 ] (3 replicates, 3 selection rounds), whose loss of function leads to depletion. Applied to this dataset, Rosace and its position-unaware version have comparable power to Enrich2 , mutscan(limma) , and mutscan(edgeR) with any number of replicates used, and the naïve method remains less powerful than other methods, especially with one replicate only. Consistent with OCT1, Rosace again calls fewer synonymous mutations and better controls the false discovery rate. The results are visualized in the Supplementary Figures (Additional file 1: Figs. S12-15).
To test Rosace performance on diverse datasets, we also ran all methods on the CARD11 data [ 14 ] (5 replicates, 1 selection round), the MSH2 data [ 12 ] (3 replicates, 1 selection round), the BRCA1 data [ 13 ] (2 replicates, 2 selection rounds), and the BRCA1-RING data [ 23 ] (6 replicates, 5 selection rounds) (Table S1). In addition to those human protein datasets, we also applied Rosace to a bacterial protein, Cohesin [ 29 ] (1 replicate, 1 selection round) (Table S1). We use the pathogenic and benign variants in ClinVar [ 30 ], EVE [ 31 ], and AlphaMissense [ 32 ] to provide a proxy of positive and negative control variants. Rosace consistently shows high sensitivity in detecting the positive control variants in all three datasets while controlling the false discovery rate (Additional file 1: Figs. S5-S11). Noting that the number of clinically verified variants is limited and those identified in the prediction models usually have extreme effects, we do not observe a large difference between the methods’ performance.
To alleviate a potential concern that the position-level shrinkage given by Rosace is too large, we plot the functional scores calculated by Rosace against those by Enrich2 across several DMS datasets (Additional file 1: Figs. S2-4). We find that the synonymous variants’ functional scores are similar in magnitude to those of other variants, so synonymous variants are not shrunken too strongly to zero. We also find that stop codon and indel variants have consistently significant effect scores, implying that position-level shrinkage is not so strong that those variants’ effects are neutralized. This result implies that the position prior benefits the model mainly through a more stable standard error estimate enabling improved prioritization as a function of local false sign rate or other posterior ranking criteria that are a function of the variance.
Rosette : DMS data simulation which matches marginal distributions from real DMS data
To further benchmark the performance of Rosace and other related methods, we propose a new simulation framework called Rosette , which generates DMS data using parameters directly inferred from the real experiment to gain the flexibility of mimicking the overall structure of most growth-based DMS screen data (Fig. 4 A).

Rosette simulation framework preserves the overall structure of growth-based DMS screens. The plots show the result of using OCT1 data as input. A Rosette generates summary statistics from real data and simulates the sequencing count. B Generative model for Rosette simulation. C The distribution of real and predicted functional scores is similar. D , E Five summary statistics are needed for Rosette
Intuitively, if we construct a simulation that closely follows the assumptions of our model, our model should have outstanding performance. To facilitate a fair comparison with other methods, the simulation presented here is not aligned with the assumptions made in Rosace . In fact, the central assumption that variant position carries information is violated by construction to showcase the robustness of Rosace .
To re-clarify the terminology used throughout this paper, “mutant” refers to the substitution, insertion, or deletion of amino acids. A position-mutant pair is considered a variant. Mutants are categorized into mutant groups with hierarchical clustering schemes or predefined criteria (our model uses the former that are expected to align with the biophysical properties of amino acids). Variants are grouped in two ways: (1) by their functional change to the protein, namely neutral, loss-of-function (LOF), or gain-of-function (GOF), referred to as “variant groups,” and (2) by the mean of the raw sequencing counts across replicates, referred to as “variant mean groups.”
Rosette calculates two summary statistics from the raw sequencing counts (dispersion of the sequencing count \(\eta\) and dispersion of the variant library \(\eta _0\) ) (Fig. 4 D) and three others from the score estimates (the proportion of each mutant group \(\varvec{p}\) , the functional score’s distribution of each variant group \(\varvec{\theta }\) , and the weight of each variant group \(\varvec{\alpha }\) ) (Fig. 4 E). Since we are only learning the distribution of the scores instead of the functional characteristics of individual variants, the score estimates can be naïve (e.g., simple linear regression) or more complicated (e.g., Rosace ).
The dispersion of the sequencing counts \(\eta\) measures how much variability in variant representation there is in the entire experimental procedure, during both cell culture and sequencing. When \(\eta\) goes to infinity, it means that the sequencing count is almost the same as the expected true cell count (no over-dispersion). When \(\eta\) is small, it shows an over-dispersion of the sequencing count. In an ideal experiment with no over-dispersion, the proportion of synonymous mutations should be invariant to time due to the absence of functional changes. However, from the real data, we have observed a large variability of proportion changes within the synonymous mutations at different selection rounds, which is attributed to over-dispersion and cannot be explained by a simple multinomial distribution in existing simulation frameworks (Additional file 1: Fig. S1). Indeed, all methods, including the naïve method, achieve near-perfect performance in the Enrich2 simulations with a correlation score greater than 0.99 (Additional file 1: Fig. S27). Therefore, we choose to model the sequencing step with a Dirichlet-Multinomial distribution that includes \(\eta\) as the dispersion parameter.
The dispersion of variant library \(\eta _0\) measures how much variability already exists in variant representation before the cell selection. Theoretically, each variant would have around the same number of cells at the initial time point. However, due to the imbalance during the variant library generation process and the cell culture of the initial population that might already be under selection, we sometimes see a wide dispersion of counts across variants. To estimate this dispersion, we fit a Dirichlet-Multinomial distribution under the assumption that the variants in the cell pool at the initial time point should have equal proportions.
The distribution and the structure of the underlying true functional score across variants are controlled by the rest of the summary statistics. We make a few assumptions here. First, the functional score distribution of mutants across positions (or a row in the heatmap (Fig. 4 A)) is different, but within the mutant group, the mutants are independent and identically distributed (or exchangeable). We estimate the mutant group by hierarchical clustering with distance defined by empirical Jenson-Shannon Divergence and record its proportion \(\hat{\varvec{p}}\) . Second, each variant belongs to the neutral hypothesis (score close to 0, similar to synonymous mutations) or the alternative hypothesis (away from 0, different from synonymous mutations). The number of the variant group can be 1–3 (neutral, GOF, and LOF) based on the number of modes in the marginal functional score distribution, and the variants within a variant group are exchangeable. We estimate the borderline of the variant group by Gaussian mixture clustering and fit the distribution parameter \(\hat{\varvec{\theta }}\) . Finally, we assume that the positions are independent. While this is a simplifying assumption, to consider the relationship between positions, we would need to incorporate additional assumptions about the functional region of the protein. As a result, we treat the positions as exchangeable and model the proportion of variant group identity (neutral, GOF, LOF) in each mutant group by a Dirichlet distribution with parameter \(\hat{\varvec{\alpha }}\) .
To simulate the sequencing count from the summary statistics, we use a generative model that mimics the experiment process and is completely different from the Rosace inference model for fair benchmarking. We first draw the functional score of each variant \(\beta _v\) from the structure described in the summary statistics and the ones in the neutral group are set to be 0. Then, we map the functional score to its latent functional parameters: the cell growth rate in the growth screen. Next, we generate the cell count at a particular time point \(N_{v,t,r}\) by the cell count at the previous time point \(N_{v,t-1,r}\) and the latent functional parameters. Finally, the sequencing count is generated from a Dirichlet-Multinomial distribution with the summarized dispersion parameter and the cell count.
The simulation result shows that the simulated functional score distribution is comparable to the real experimental data (Fig. 4 C). We also demonstrate that the simulation is not particularly favorable to models containing positional information such as Rosace . From Fig. 4 E, we observe that in the simulation, the positional-level score is not as widespread as the real data. In addition, the positions with extreme scores (very positive scores in the OCT1 dataset) have reduced standard deviation in the real data, but not in the simulation (Additional file 1: Figs. S18d, S19d, S20d). As a result, we would expect the performance of Rosace to be better in real data than in the simulation.
Testing Rosace false discovery control with Rosette simulation
To test the performance of Rosace , we generate simulated data using Rosette from two distinctive growth-based assays: the transporter OCT1 data where LOF variants are positively selected [ 10 ] and the kinase MET data where LOF variants are negatively selected [ 11 ]. We further included the result of a saturation genome editing dataset CARD11 [ 14 ] in Additional file 1: Figs. S17-23. The OCT1 DMS screen measures the impact of variants on cytotoxic drug SM73 uptake mediated by the transporter OCT1. If a mutation causes the transporter protein to have decreased activity, the cells in the pool will import less substrate and thus die more slowly than wide-type or those with synonymous mutations, so the LOF variants would be positively selected. In the MET DMS screen, the kinase drives proliferation and cell growth in the BA/F3 mammalian cell line in the absence of IL-3 (interleukin-3) withdrawal. If the variant protein fails to function, the cells will die faster than the wild-type cells, so the LOF variants will be negatively selected. Both data sets have a clear separation of two modes in the functional score distribution (neutral and LOF) (Additional file 1: Figs. S18a, S19a). We benchmark Rosace with Enrich2 , mutscan(edgeR) , mutscan(limma) , and the naïve method in scenarios where we use 1 or all 3 of replicates and 1 or all 3 of selection rounds. DiMSum is benchmarked when there is only one round of selection because it is not designed to handle multiple rounds. Each scenario is repeated 10 times. The results of all methods show similar correlations with the latent growth rates (Additional file 1: Fig. S21), and thus, for benchmarking purposes, we focus on hypothesis testing.
We compare methods from a variant ranking point of view, comparing methods in terms of the number of false discoveries for any given number of variants selected to be LOF. This is because Rosace is a Bayesian framework that uses lfsr instead of p -values as the metric for variant selection and it is hard to translate lfsr to FDR for a hard threshold. Variants are ranked by adjusted p -values or lfsr (ascending). Methods that perform well will rank the truly LOF variants in the simulation ahead of non-LOF variants. In an ideal scenario with no noise, we would expect the line of ranked variants by FDR to be flat at 0 and slowly rise after all LOF variants are called. The results in Fig. 5 show that even though the position assumption is violated in the Rosette simulation, Rosace is robust enough to maintain a relatively low FDR in all simulation conditions.

Benchmark of false discovery control on Rosette simulation. Variants are ranked by hypothesis testing (adjusted p-values or lfsr ). The false discovery rate at each rank is computed as the proportion of neutral variants assuming all the variants till the rank cutoff are called significant. R is the number of replicates and T is the number of selection rounds. MET data is used for negative selection and OCT1 data for positive selection. Ideally, the line would be flat at 0 until the rank where all variants with true effects are discovered. (DiMSum can only process two time points and thus is disadvantaged in experiments with more than two time points, or one selection round)
Testing Rosace power with Rosette simulation
Next, we investigate the sensitivity of benchmarking methods at different FDR or lfsr cutoff. It is important to keep in mind that Rosace uses raw lfsr from the sampling result while all other methods use the Benjamini-Hochberg Procedure to control the false discovery rate. As a result, the cutoff for Rosace is on a different scale.
Rosace is the only method that displays high sensitivity in all conditions with a low false discovery rate. In the case of one selection round and three replicates ( \(T = 1\) and \(R = 3\) ), mutscan(edgeR) and mutscan(limma) do not have the power to detect any significant variants with the FDR threshold at 0.1. The same scenario occurs with DiMSum at negative selection and the naïve method at \(T = 3\) and \(R = 1\) (Fig. 6 ). The naïve method in general has very low power, while Enrich2 has a very inflated FDR.

Benchmark of sensitivity versus FDR. The upper row is simulated from a modified version of Rosette simulation to favor position-informed models. The bottom row is the results from standard Rosette . Circles, triangles, squares, and crosses represent LOF variant selection at adjusted p-values or lfsr of 0.001, 0.01, 0.05, and 0.10, respectively. Variants with the opposite sign of selection are then excluded. Ideally, for all methods besides Rosace , each symbol would lie directly above the corresponding symbol on the x-axis indicating true FDR. For Rosace , lfsr has no direct translation to FDR so the cutoff represented by the shape is theoretically on a different scale. (DiMSum can only process two time points, and thus is disadvantaged in experiments with more than two time points, or one selection round)
We benchmark Rosace on both Rosette simulations, which inherently violate the position assumption, and a modified version of Rosette that favors the position-informed model. We show that model misspecification does increase the false discovery rate of Rosace , but Rosace is robust enough to outperform all other methods (except for DiMSum with \(T = 1\) and \(R = 3\) and positive selection) even when the position assumption is strongly violated (Fig. 6 ).
One of Rosace ’s contributions is accounting for positional information in DMS analysis. The model assumes the prior information that variants on the same position have similar functional effects, resulting in higher sensitivity and better FDR. Furthermore, Rosace is also capable of incorporating other types of prior information on the similarity of variants.
Despite the value of positional information in statistical inference as demonstrated in this paper, it is unclear how multiple random mutations should be position-labeled. In this case, simple position heuristics are often unsatisfying, and one might argue that a position scalar should not cluster the variants in random mutagenesis experiments with large-scale in-frame insertion and deletion, such as those on viruses. These types of experiments are not the focus of this paper, but are still very important and require careful future research.
Another critique of Rosace is the extent of bias we introduce into the score inference through position-prior information. While it is certainly possible to introduce a large bias, Rosace was developed to be a robust model ensuring near-unbiased inference or prediction even when assumptions are not precisely complied with or even violated. We demonstrate the robustness of Rosace through our data simulation framework, Rosette . The generative procedures of Rosette explicitly violate the prior assumptions made by Rosace , but even with Rosette ’s data, Rosace can learn important information. We also show that the position-level shrinkage is not strong using real data, further manifesting the robustness of Rosace .
The development of DMS simulation frameworks such as Rosette can also drive experimental design. For example, to select the best number of time points and replicates with regard to the trade-off between statistical robustness and costs of the experiment, an experimentalist can conduct a pilot experiment and use its data to infer summary statistics through Rosette . Rosette will then generate simulations close to a real experiment. Experimentalists can find the optimal tool for data analysis given an experimental design by applying candidate tools to the simulation data. Similarly, given a data analysis framework, experimentalists can choose from multiple experiment designs by using Rosace to simulate all those experiments and observe if any designs have enough power to detect most of the LOF or GOF variants with a low false discovery rate.
This paper only applies our tool to growth screens, one of several functional phenotyping methods possible by DMS techniques. Another possibility is the binding experiment, where a portion of cells are selected at each time point. In this case, the expectation of functional scores computed by Rosace is a log transformation of the variant’s selection proportion [ 18 ], and one could potentially use Rosace for DMS analysis as in Enrich2 . The third method is fluorescently activated cell sorting (FACS-seq)—a branch of literature uses binned FACS-seq screens to sort the variant libraries based on protein phenotypes. Since the experiment has multiple bins, one can potentially capture the distributional change of molecular properties beyond mean shifting [ 8 , 10 , 19 , 33 ]. Although of different design, FACS-seq-based screens can also be analyzed using a framework similar to Rosace . Building such frameworks incorporating prior information for experiments beyond growth screens enables the community to exploit a wider range of experimental data.
As the function of a protein is rarely one-dimensional, one can measure multiple phenotypes of a variant in a set of experiments [ 10 , 16 , 34 ]. For example, the OCT1 data mentioned earlier [ 10 ] measures both the transporter surface expression from a FACS-seq screen and drug cytotoxicity with a growth screen. Multi-phenotype DMS experiments also call for analysis frameworks to accommodate multidimensional outcomes by modeling the interaction or the correlation of phenotypes of each variant. One successful attempt models the causal biophysical mechanism of protein folding and binding [ 35 ], and there are many more protein properties other than those two. A unifying framework for the multi-phenotype analysis remains unsolved and challenging. One needs to account for different experimental designs to directly compare scores between phenotypes, and carefully select inferred features most relevant to the scientific questions, requiring both efforts from the experimental and computational side. Nevertheless, we believe that the multi-phenotype analysis will eventually guide us to develop better mechanistic or probabilistic models for how mutations drive proteins in evolution, how they lead to malfunction and diseases, and how to better engineer new proteins.
Conclusions
We present Rosace , a Bayesian framework for analyzing growth-based deep mutational scanning data. In addition, we develop Rosette , a simulation framework that recapitulates the properties of actual DMS experiments, but relies on an orthogonal data generation process from Rosace . From both simulation and real data analysis, we show that Rosace has better FDR control and higher sensitivity compared to existing methods and that it provides reliable estimates for downstream analyses.
Pipeline: raw read to sequencing count
To facilitate the broader adoption of the Rosace framework for DMS experiments, we have developed a sequencing pipeline for short-read-based experiments using Snakemake which we dub Dumpling [ 36 ]. This pipeline handles directly sequenced single-variant libraries containing synonymous, missense, nonsense, and multi-length indel mutations, going from raw reads to final scores and quality control metrics. Raw sequencing data in the form of fastq files is first obtained as demultiplexed paired-end files. The user then defines the experimental architecture using a csv file defining the conditions, replicates, and time points corresponding to each file, which is parsed along with a configuration file. The reads are processed for quality and contaminants using BBDuk, and then the paired reads are error-corrected using BBMerge. The cleaned reads are then mapped onto the reference sequence using BBMap [ 37 ]. Variants in the resulting SAM file are called and counted using the AnalyzeSaturationMutagenesis tool in GATK v4 [ 38 ]. This tool provides a direct count of the number of times each distinct genotype is detected in an experiment. We generate various QC metrics throughout the process and combine them using MultiQC for an easy-to-read final overview [ 39 ].
Due to the degeneracy of indel alignments, the genotyping of codon-level deletions sometimes does not hew to the reading frame due to leftwise alignment. Additionally, due to errors in oligo synthesis, assembly, during in vivo passaging or during sequencing, some genotypes that were not designed as part of the library may be introduced. A fundamental assumption of DMS is the independence of individual variants, and so to reduce noise and eliminate error, our pipeline removes those that were not part of our planned design before analysis, as well as renames variants to be consistent at the amino acid level, before exporting the variant counts in a format for Rosace .
Pre-processing of sequencing count
In a growth DMS screen with V variants, we define v to be the variant index. A function p ( v ) maps the variant v to its position label. T indicates the number of selection rounds and index t is an integer ranging from 0 to T . A total of R replicates are measured, with r as the replicate index. We denote \(c_{v,t,r}\) the raw sequencing count of cells with variant v at time point t in replicate r .
In addition, “mutant” refers to substitution with one of the 20 amino acids, insertion of an amino acid, or deletion. Thus, a variant is uniquely identified by its mutant and the position where the mutant occurs ( p ( v )).
The default pre-processing pipeline of Rosace includes four steps: variant filtering, count imputation, count normalization, and replicate integration. First, variants with more than 50% of missing count data are filtered out in each replicate. Then, variants with a few missing data (less than 50%) are imputed using either the K-nearest neighbor averaging ( K = 10) or filled with 0. Next, imputed raw counts are log-transformed with added pseudo-count 1/2 and normalized by the wild-type cells or the sum of sequencing counts for synonymous mutations. This step, which is proposed by Enrich2 , allows for the computed functional score of wild-type cells to be approximately 0. Additionally, the counts for each variant before selection are aligned to be 0 for simple prior specification of the intercept.
Previous papers suggest the usage of other methods such as total-count normalization when the wild-type is incorrectly estimated or subject to high levels of error [ 18 , 20 ]. We include this in Rosace as an option. Finally, replicates in the same experiment are joined together for the input of the hierarchical model. If a variant is dropped out in some but not all replicates, Rosace imputes the missing replicate data with the mean of the other replicates.
Rosace : hierarchical model and functional score inference
Rosace assumes that the aligned counts are generated by the following time-dependent linear function. Let \(\beta _v\) be the defined functional score or slope, \(b_v\) be the intercept, and \(\epsilon _{g(v)}\) be the error term. The core of Rosace is a linear regression:
where g ( v ) maps the variant v to its mean group—the grouping method will be explained below.
p ( v ) is the function that maps a variant v to its amino acid position. If the information of variants’ mutation types is given, Rosace will assign synonymous variants to many artificial “control” positions. The number of synonymous variants per control position is determined by the maximum number of non-synonymous variants per position. Assigning synonymous variants to control positions incorporates the extra information while not giving too strong a shrinkage to synonymous variants (Additional file 1: Figs. S2-S4). In addition, we regroup positions with fewer than 10 variants together to avoid having too few variants in a position. For example, if the DMS screen has fewer than 10 mutants per position, adjacent positions will be grouped to form one position label. Also, the position of a continuous indel variant is labeled as a mutation of the leftmost amino acid residue (e.g., an insertion between positions 99 and 100 is labeled as position 99 and a deletion of positions 100 through 110 is labeled as position 100).
We assume that the variants at the same position are more likely to share similar functional effects. Thus, we build the layer above \(\beta _v\) using position-level parameters \(\phi _{p(v)}\) and \(\sigma _{p(v)}\) .
The mean and precision parameters are given a weakly informative normal prior and variance parameters are given weakly informative inverse-gamma distribution.
We further cluster the variant into mean groups of 25 based on its value of mean count across time points and replicates. The mapping between the variant and its mean group is denoted as g ( v ). Thus, we model the mean-variance relationship by assuming variants with a lower mean are expected to have higher error terms in the linear regression and vice versa.
Stan [ 40 ] is used in Rosace for Bayesian inference over our model. We use the default inference method, the No-U-Turn sampler (NUTS), a variant of the Hamiltonian Monte Carlo (HMC) algorithm. Compared to other widely used Monte Carlo samplers, for example, the Metropolis-Hastings algorithm, HMC has reduced correlation between successive samples, resulting in fewer samples reaching a similar level of accuracy [ 41 ]. NUTS further improves HMC by automatically determining the number of steps in each iteration of HMC sampling to more efficiently sample from the posterior [ 42 ].
The lower bound of the number of mutants per position index \(|\{v|p(v)=i\}|\) (10) and the size of the variant’s mean group \(g_p\) (25) can be changed.
Rosette : the OCT1 and MET datasets
We use the following datasets as input of the Rosette simulation: the OCT1 dataset by Yee et al. [ 10 ] as an example of positive selection and the MET dataset by Estevam et al . [ 11 ] as an example of negative selection. Specifically, we use replicate 2 of the cytotoxicity selection screen in the OCT1 dataset for both score distribution and raw count dispersion. For the MET dataset, we select the experiment with IL-3 withdrawal under wild-type genetic background (without exon 14 skipping). Raw counts are extracted from replicate 1 but the scores are calculated from all three replicates because of the frequent dropouts at the initial time point.
The sequencing reads and the resulting sequencing counts are processed in the default pipeline described in the previous method sections. Scores are then computed using simple linear regression (the naïve method). The naïve method is used as the Rosette input because we are trying to learn the global distribution of the scores instead of identifying individual variants and, while uncalibrated, naïve estimates are unbiased.
Rosette : summary statistics from real data
Summary statistics inferred by Rosette can be categorized into two types: one for the dispersion of sequencing counts and the other for the dispersion of score distribution.
First, we estimate dispersion \(\eta\) in the sequencing count. We assume the sequencing count at time point 0 reflects the true variant library before selection. Since the functional scores of synonymous variants are approximately 0, the proportion of synonymous mutations in the population should approximately be the same after selection. Let the set of indices of synonymous mutations be \(\textbf{v}_s = \{v_{s1}, v_{s2}, \dots \}\) . The count of each synonymous mutation at time point t is \(\textbf{c}_{\textbf{v}_s, t} = (c_{v_{s1}, t}, c_{v_{s2}, t}, \dots )\) . The model we use to fit \(\eta\) is thus
from which we find the maximum likelihood estimation \(\hat{\eta }\) .
Dispersion of the initial variant library \(\eta _0\) is estimated similarly by fitting a Dirichlet-Multinomial distribution on the sequencing counts of the initial time point assuming that in an ideal experiment, the proportion of each variant in the library should be the same. Similar to above, the indices of all mutations are \(\textbf{v} = \{1, 2, \dots , V\}\) , and the count of each mutation at time point 0 is \(\textbf{c}_{\textbf{v}, 0} = (c_{1, 0}, c_{2, 0}, \dots , c_{V, 0})\) . From the following model
we can again find the maximum likelihood of the variant library dispersion \(\hat{\eta _0}\) . Notice that \(\hat{\eta }_0\) is usually much smaller than \(\hat{\eta }\) (i.e. more overdispersed) because \(\hat{\eta }_0\) contains both the dispersion of the variant library as well as the sequencing step.
To characterize the distribution of functional scores, we first cluster mutants into groups, as mutants often have different properties and exert different influences on protein function. We calculate the empirical Jensen-Shannon divergence (JSD) to measure the distance between two mutants, using bins of 0.1 to find the empirical probability density function. Ideally, a clustering scheme should produce a grouping that reflects the inherent properties of an amino acid that are independent of position. Thus, we are more concerned with the general shape of the distribution than the similarity between paired observations. It leads to our preference for JSD over Euclidean distance as the clustering metric. To cluster mutants into four mutant groups \(g_{m} = \{1, 2, 3, 4\}\) , we use hierarchical clustering (“hclust” function with complete linkage method in R), and we record the proportions \(\widehat{\varvec{p}}\) to simulate any number of mutants in the simulation (the number of mutant groups can also be changed). The underlying assumption is that mutants in each mutant group are very similar and can be treated as interchangeable. We define \(f_1(v)\) as the function that maps a variant to its corresponding mutant group \(g_{m}\) .
Then, we cluster the variants into different variant groups. In the case of our examples, the shape is not unimodal but bimodal. The OCT1 screen has a LOF mode on the right (positive selection) and the MET screen has a LOF mode on the left (negative selection). While it is possible to observe both GOF and LOF variants, we observed in our datasets that GOF variants are so rare that they do not constitute a mode on the mixed distribution, resulting in a bimodal distribution. To cluster the non-synonymous variants into groups \(g_{v}\) , we use the Gaussian Mixture model with two mixtures for our examples to decide the cutoff of the groups, and we fit the Gaussian distribution for each variant group again to learn the parameters of the distribution. The synonymous variants have their own group labeled as control. Let \(f_2(v)\) denote the function that maps a variant to its corresponding variant group \(g_{v}\) . The result of the simulation shows that even the synonymous mutations with scores close to 0 can have large negative effects due to random dropout. Thus, we later set the effect of the control and the neutral group to be constant 0 and still observe a similar distribution as seen in the real data. For each variant, we have one of the models below, depending on whether the variant results in LOF or has no effects:
We use \(\widehat{\varvec{\theta }}\) to denote the collection of estimated distributional parameters for all variant groups.
Finally, we define the number of variants in each variant group at each position
For each position p , we can thus find the count of variants belonging to any mutant-variant group \(\varvec{o}_{p} \in \textbf{N}^{\Vert g_m \Vert \Vert g_v \Vert }\) . Treating each position as an observation, we fit a Dirichlet distribution to characterize the distribution of variant group identities among mutants at any position:
The final summary statistics are \(\hat{\eta }\) , \(\hat{\eta _0}\) , \(\hat{\varvec{p}}\) , \(\hat{\varvec{\theta }}\) , and \(\hat{\varvec{\alpha }}\) . We also need T , the number of selection rounds, to map \(\beta _v\) into the latent functional parameter \(\mu _v\) in growth screens.
Rosette : data generative model
We simulate as the real experiment the same number of mutants M , the number of positions P , and the number of variants V ( \(M \times P\) ). The important hyperparameters that need to be specified are the average number of reads per variant D (100, also referred to as the sequencing depth), initial cell population count \(P_0\) (200 V ), and wild-type doubling rate \(\delta\) between time points ( \(-2\) or 2). One also needs to specify the number of replicates R and selection rounds T .
The simulation largely consists of two major steps: (1) generating latent growth rates \(\mu _v\) and (2) generating cell counts \(N_{v,t,r}\) and sequencing counts \(c_{v,t,r}\) .
In step 1, the mutant group and variant group labeling of each variant is first generated. Specifically, we assign a mutant to the mutant group \(g_m\) by the proportion \(\hat{\varvec{p}}\) and then assign a variant to the variant group \(g_v\) by drawing \(\varvec{o}_p\) from Dirichlet distribution with parameter \(\hat{\varvec{\alpha }}\) (Eq. 10 ). Using \(\hat{\varvec{\theta }}\) , we randomly generate \(\beta _v\) for each variant based on its \(g_v\) (Eq. 8 ). The mapping between \(\beta _v\) and \(\mu _v\) requires an understanding of the generative model, so it will be defined after we present the cell growth model.
In step 2, the starting cell population \(N_{v,r,0}\) is drawn from a Dirichlet-Multinomial distribution using \(\hat{\eta }_0\) and we assume that replicates are biological replicates:
where \(P_0\) is the total cell population. The cells are growing exponentially and we determine the cell count by a Poisson distribution
where \(\Delta t\) is the pseudo-passing time. It differs from index t and will be defined in the next paragraph. Similar to how we define \(\textbf{c}_{\textbf{v}, t, r}\) , we define the true cell count of each variant at time point t and replicate r to be \(\textbf{N}_{\textbf{v}, t, r} = (N_{1, t, r}, \dots , N_{V, t, r})\) . The sequencing count for each variant is
where D is the sequencing depth per variant. Empirically, we can set input \(\hat{\eta }\) and \(\hat{\eta }_0\) slightly higher than the estimated summary statistics. This is because the estimated values encompass all the noises in the experiment, while the true values only represent the noise from the sequencing step.
To find the mapping between \(\beta _v\) and \(\mu _v\) , we define \(\delta\) to be the wild-type doubling rate and naturally compute \(\Delta t:= \frac{\delta \log 2}{\mu _{wt}}\) , the pseudo-passing time in each round. Then we can compute the expectation of \(\beta _v\) with the linear regression model. For simplicity, we omit the replicate index r and assume r is fixed in the next set of equations.
The final mapping between simulated \(\beta _v\) and \(\mu _v\) is then described in the following
with \(\mu _{wt}\) set to be \(\text {sgn}(\delta )\) .
Modified Rosette that favors position-informed models
In the original, position-agnostic version of Rosette , a \(\Vert g_m \Vert \Vert g_v \Vert\) -dimensional vector is drawn from the same Dirichlet distribution for each position. The vector can be regarded as a quota for each mutant-variant group. Variants at each position are assigned their mutant-variant group according to the quota. As a result, at one position, variants from all variant groups (neutral, LOF, and GOF) would exist, and this violates the assumption in Rosace that variants at one position would have similar functional effects (strong LOF and GOF variants are very unlikely to be at the same position). To show that Rosace could indeed take advantage of the position information when it exists in the data, we create a modified version of Rosette where variants at one position could only belong to one variant group. Specifically, a position can have either neutral, LOF, or GOF variants, but not a mixture among any variant groups.
Benchmarking
The naïve method (simple linear regression) is conducted by the “lm” function in R on processed data. For each variant, normalized counts are regressed against time. Raw two-sided p -values are computed from t -statistics given by the “lm” function. It is then corrected using the Benjamini-Hochberg Procedure to adjust the p -values.
For Enrich2 , we use the built-in variant filtering and wild-type (“wt”) normalization. All analyses use a random-effect model as presented in the paper. When there is more than one selection round, we use weighted linear regression. Otherwise, a simple ratio test is performed. The resulting p -values are adjusted using the Benjamini-Hochberg Procedure.
DiMSum requires the variant labeling to be DNA sequences. As a result, we have to generate dummy sequences. It is applied to all simulations with one selection round with the default settings. The z -statistics are computed using the variant’s mean estimate over the estimated standard deviation and the adjusted p -value is computed from the z -score with Benjamini-Hochberg procedure. DiMSum only processes data with one selection round (two time points) and thus may be disadvantaged when analyzing datasets with multiple selection rounds.
mutscan is an end-to-end pipeline that requires the input to be sequencing reads. Conversely, Rosette only generates sequencing counts, which can be calculated from sequencing reads but cannot be used to recover sequencing reads. To facilitate benchmarking, we use a SummarizedExperiment object to feed the Rosette output to their function “calculateRelativeFC,” which does take sequencing counts as input. We benchmark both mutscan(edgeR) and mutscan(limma) with default normalization and hyperparameters as provided in the function. We use the “logFC_shrunk” and “FDR” columns in mutscan(edgeR) output and the “logFC” and “adj.P.Val” columns in mutscan(limma) output.
We run Rosace with position information of variants and labeling of synonymous mutations. However, Rosace is a Bayesian framework so it does not compute FDR like the frequentist methods above. All Rosace power/FDR calculations are done under the Bayesian local false sign rate ( lfsr ) setting [ 28 ]. As a result, in the simulation, we present the rank-FDR curve and the FDR-Sensitivity curve as the metrics instead of setting an identical or different hard threshold on FDR and lfsr . In the real data benchmarking, both the FDR and lfsr thresholds are set to be 0.05.
Rosace without position label is denoted as Rosace (nopos) in the Additional file 1: Figs. S5–S15, S19–S23, and S25. It removes the position layer in Fig. 2 C and keeps only the variant and replicate layer. The test statistics and model evaluation are presented identically as the full Rosace model.
Availability of data and materials
Rosace is implemented as an R package and is distributed on GitHub ( https://github.com/pimentellab/rosace ), under the MIT open-source license. The package also includes functions for Rosette simulation. An archived version of Rosace is available on Zenodo [ 43 ].
The integrated sequencing pipeline for short-read-based experiments is available on GitHub ( https://github.com/odcambc/dumpling ).
Scripts and pre-processed public datasets used to perform data analysis and generate figures for the paper are uploaded on GitHub as well ( https://github.com/roserao/rosace-paper-script ).
The protein datasets we used are as follows: OCT1 [ 10 ], MET [ 11 ], CARD11 [ 14 ], MSH2 [ 12 ], BRCA1 [ 13 ], BRCA1-RING [ 23 ], and Cohesin [ 29 ]. OCT1 and MET are available on NIH NCBI BioProject with accession codes PRJNA980726 and PRJNA993160 . CARD11, BRCA1, and Cohesin are available as supplementary files to their respective publications. MSH2 is available on Gene Expression Omnibus with accession code GSE162130 . BRCA1-RING is available on MaveDB with accession code mavedb:00000003-a-1 .
The benchmarking datasets are EVE [ 31 ] ( evemodel.org ), ClinVar [ 30 ] ( gnomad.broadinstitute.org ), and AlphaMissense [ 32 ] ( alphamissense.hegelab.org ).
Fowler DM, Stephany JJ, Fields S. Measuring the activity of protein variants on a large scale using deep mutational scanning. Nat Protoc. 2014;9(9):2267–84. https://doi.org/10.1038/nprot.2014.153 .
Article CAS PubMed PubMed Central Google Scholar
Fowler DM, Fields S. Deep mutational scanning: a new style of protein science. Nature Methods. 2014;11(8):801–7. https://doi.org/10.1038/nmeth.3027 .
Araya CL, Fowler DM. Deep mutational scanning: assessing protein function on a massive scale. Trends Biotechnol. 2011;29(9):435–42. https://doi.org/10.1016/j.tibtech.2011.04.003 .
Tabet D, Parikh V, Mali P, Roth FP, Claussnitzer M. Scalable functional assays for the interpretation of human genetic variation. Annu Rev Genet. 2022;56(1):441–65. https://doi.org/10.1146/annurev-genet-072920-032107 .
Article CAS PubMed Google Scholar
Stein A, Fowler DM, Hartmann-Petersen R, Lindorff-Larsen K. Biophysical and mechanistic models for disease-causing protein variants. Trends Biochem Sci. 2019;44(7):575–88. https://doi.org/10.1016/j.tibs.2019.01.003 .
Romero PA, Tran TM, Abate AR. Dissecting enzyme function with microfluidic-based deep mutational scanning. Proc Natl Acad Sci USA. 2015;112:7159–64. https://doi.org/10.1073/PNAS.1422285112 .
Chen JZ, Fowler DM, Tokuriki N. Comprehensive exploration of the translocation, stability and substrate recognition requirements in vim-2 lactamase. eLife. 2020;9:1–31.
Article CAS Google Scholar
Matreyek KA, Starita LM, Stephany JJ, Martin B, Chiasson MA, Gray VE, et al. Multiplex assessment of protein variant abundance by massively parallel sequencing. Nat Genet. 2018;50(6):874–82. https://doi.org/10.1038/s41588-018-0122-z .
Leander M, Liu Z, Cui Q, Raman S. Deep mutational scanning and machine learning reveal structural and molecular rules governing allosteric hotspots in homologous proteins. eLife. 2022;11. https://doi.org/10.7554/ELIFE.79932 .
Yee SW, Macdonald C, Mitrovic D, Zhou X, Koleske ML, Yang J, et al. The full spectrum of OCT1 (SLC22A1) mutations bridges transporter biophysics to drug pharmacogenomics. bioRxiv. 2023. https://doi.org/10.1101/2023.06.06.543963 .
Estevam GO, Linossi EM, Macdonald CB, Espinoza CA, Michaud JM, Coyote-Maestas W, et al. Conserved regulatory motifs in the juxtamembrane domain and kinase N-lobe revealed through deep mutational scanning of the MET receptor tyrosine kinase domain. eLife. 2023. https://doi.org/10.7554/elife.91619.1 .
Jia X, Burugula BB, Chen V, Lemons RM, Jayakody S, Maksutova M, et al. Massively parallel functional testing of MSH2 missense variants conferring Lynch syndrome risk. Am J Hum Genet. 2021;108:163–75. https://doi.org/10.1016/J.AJHG.2020.12.003 .
Findlay GM, Daza RM, Martin B, Zhang MD, Leith AP, Gasperini M, et al. Accurate classification of BRCA1 variants with saturation genome editing. Nature. 2018;562(7726):217–22. https://doi.org/10.1038/s41586-018-0461-z .
Meitlis I, Allenspach EJ, Bauman BM, Phan IQ, Dabbah G, Schmitt EG, et al. Multiplexed functional assessment of genetic variants in CARD11. Am J Hum Genet. 2020;107:1029–43. https://doi.org/10.1016/J.AJHG.2020.10.015 .
Flynn JM, Rossouw A, Cote-Hammarlof P, Fragata I, Mavor D, Hollins C III, et al. Comprehensive fitness maps of Hsp90 show widespread environmental dependence. eLife. 2020;9:e53810. https://doi.org/10.7554/eLife.53810 .
Article PubMed PubMed Central Google Scholar
Steinberg B, Ostermeier M. Shifting fitness and epistatic landscapes reflect trade-offs along an evolutionary pathway. J Mol Biol. 2016;428(13):2730–43. https://doi.org/10.1016/j.jmb.2016.04.033 .
Fowler DM, Araya CL, Fleishman SJ, Kellogg EH, Stephany JJ, Baker D, et al. High-resolution mapping of protein sequence-function relationships. Nat Methods. 2010;7(9):741–6. https://doi.org/10.1038/nmeth.1492 .
Rubin AF, Gelman H, Lucas N, Bajjalieh SM, Papenfuss AT, Speed TP, et al. A statistical framework for analyzing deep mutational scanning data. Genome Biol. 2017;18:1–15. https://doi.org/10.1186/S13059-017-1272-5/FIGURES/7 .
Article Google Scholar
Coyote-Maestas W, Nedrud D, He Y, Schmidt D. Determinants of trafficking, conduction, and disease within a K + channel revealed through multiparametric deep mutational scanning. eLife. 2022;11:e76903. https://doi.org/10.7554/eLife.76903 .
Faure AJ, Schmiedel JM, Baeza-Centurion P, Lehner B. DiMSum: An error model and pipeline for analyzing deep mutational scanning data and diagnosing common experimental pathologies. Genome Biol. 2020;21:1–23. https://doi.org/10.1186/S13059-020-02091-3/TABLES/2 .
Bloom JD. Software for the analysis and visualization of deep mutational scanning data. BMC Bioinformatics. 2015;16:1–13. https://doi.org/10.1186/S12859-015-0590-4/FIGURES/6 .
Bank C, Hietpas RT, Wong A, Bolon DN, Jensen JD. A Bayesian MCMC approach to assess the complete distribution of fitness effects of new mutations: Uncovering the potential for adaptive walks in challenging environments. Genetics. 2014;196:841–52. https://doi.org/10.1534/GENETICS.113.156190/-/DC1 .
Starita LM, Young DL, Islam M, Kitzman JO, Gullingsrud J, Hause RJ, et al. Massively parallel functional analysis of BRCA1 RING domain variants. Genetics. 2015;200(2):413–22. https://doi.org/10.1534/genetics.115.175802 .
Soneson C, Bendel AM, Diss G, Stadler MB. mutscan-a flexible R package for efficient end-to-end analysis of multiplexed assays of variant effect data. Genome Biol. 2023;12(24):1–22. https://doi.org/10.1186/S13059-023-02967-0/FIGURES/6 .
Eddy SR. Accelerated Profile HMM Searches. PLOS Comput Biol. 2011;7(10):1–16. https://doi.org/10.1371/journal.pcbi.1002195 .
Robinson MD, McCarthy DJ, Smyth GK. edgeR: a Bioconductor package for differential expression analysis of digital gene expression data. Bioinformatics. 2009;26(1):139–40. https://doi.org/10.1093/bioinformatics/btp616 .
Love MI, Huber W, Anders S. Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2. Genome Biol. 2014;15:1–21.
Stephens M. False discovery rates: a new deal. Biostatistics. 2017;18:275–94. https://doi.org/10.1093/BIOSTATISTICS/KXW041 .
Article PubMed Google Scholar
Kowalsky CA, Whitehead TA. Determination of binding affinity upon mutation for type I dockerin-cohesin complexes from C lostridium thermocellum and C lostridium cellulolyticum using deep sequencing. Proteins Struct Funct Bioinforma. 2016;84(12):1914–28.
Landrum MJ, Lee JM, Benson M, Brown GR, Chao C, Chitipiralla S, et al. ClinVar: improving access to variant interpretations and supporting evidence. Nucleic Acids Res. 2018;46(D1):D1062–7.
Frazer J, Notin P, Dias M, Gomez A, Min JK, Brock K, et al. Disease variant prediction with deep generative models of evolutionary data. Nature. 2021;599(7883):91–5.
Cheng J, Novati G, Pan J, Bycroft C, Žemgulytė A, Applebaum T, et al. Accurate proteome-wide missense variant effect prediction with AlphaMissense. Science. 2023;381(6664):eadg7492.
Starr TN, Greaney AJ, Hilton SK, Ellis D, Crawford KHD, Dingens AS, et al. Deep mutational scanning of SARS-CoV-2 receptor binding domain reveals constraints on folding and ACE2 binding. Cell. 2020;182:1295-1310.e20. https://doi.org/10.1016/J.CELL.2020.08.012 .
Stiffler M, Hekstra D, Ranganathan R. Evolvability as a function of purifying selection in TEM-1 beta-lactamase. Cell. 2015;160(5):882–892. Publisher Copyright: © 2015 Elsevier Inc. https://doi.org/10.1016/j.cell.2015.01.035 .
Faure AJ, Domingo J, Schmiedel JM, Hidalgo-Carcedo C, Diss G, Lehner B. Mapping the energetic and allosteric landscapes of protein binding domains. Nature. 2022;604(7904):175–83. https://doi.org/10.1038/s41586-022-04586-4 .
Mölder F, Jablonski KP, Letcher B, Hall MB, Tomkins-Tinch CH, Sochat V, et al. Sustainable data analysis with Snakemake. F1000Research. 2021;10:33. https://f1000research.com/articles/10-33/v2 .
Bushnell B. BBTools software package. 2014. https://sourceforge.net/projects/bbmap . Accessed 11 June 2021.
Van der Auwera GA, O’Connor BD. Genomics in the cloud: using Docker, GATK, and WDL in Terra. Sebastopol: O’Reilly Media; 2020.
Ewels P, Magnusson M, Lundin S, Käller M. MultiQC: summarize analysis results for multiple tools and samples in a single report. Bioinformatics. 2016;32(19):3047–8. https://doi.org/10.1093/bioinformatics/btw354 .
Stan Development Team. RStan: the R interface to Stan. 2023. R package version 2.21.8. https://mc-stan.org/ . Accessed 22 May 2024.
Betancourt M. A conceptual introduction to Hamiltonian Monte Carlo. arXiv preprint arXiv:1701.02434. 2017. https://arxiv.org/abs/1701.02434 .
Hoffman MD, Gelman A. The No-U-Turn sampler: adaptively setting path lengths in Hamiltonian Monte Carlo. J Mach Learn Res. 2014;15(47):1593–623.
Google Scholar
Rao J. pimentellab/rosace. 2023. Zenodo. https://doi.org/10.5281/zenodo.10814911 .
Download references
Review history
The review history is available as Additional file 2.
Peer review information
Andrew Cosgrove was the primary editor of this article and managed its editorial process and peer review in collaboration with the rest of the editorial team.
Author information
Ruiqi Xin and Christian Macdonald contributed equally to this work.
Authors and Affiliations
Department of Computer Science, UCLA, Los Angeles, CA, USA
Jingyou Rao & Harold Pimentel
Computational and Systems Biology Interdepartmental Program, UCLA, Los Angeles, CA, USA
Department of Bioengineering and Therapeutic Sciences, UCSF, San Francisco, CA, USA
Christian Macdonald, Matthew K. Howard, Gabriella O. Estevam, Sook Wah Yee, James S. Fraser & Willow Coyote-Maestas
Tetrad Graduate Program, UCSF, San Francisco, CA, USA
Matthew K. Howard & Gabriella O. Estevam
Department of Pharmaceutical Chemistry, UCSF, San Francisco, CA, USA
Matthew K. Howard
Department of Mathematics, Baruch College, CUNY, New York, NY, USA
Mingsen Wang
Quantitative Biosciences Institute, UCSF, San Francisco, CA, USA
James S. Fraser & Willow Coyote-Maestas
Department of Computational Medicine, David Geffen School of Medicine, UCLA, Los Angeles, CA, USA
Harold Pimentel
Department of Human Genetics, David Geffen School of Medicine, UCLA, Los Angeles, CA, USA
You can also search for this author in PubMed Google Scholar
Contributions
JR, CM, WCM, and HP jointly conceived the project. JR and HP developed the statistical model and the simulation framework. JR, MW, and RX wrote the software and its support. JR performed the data analysis and benchmarking. CM wrote the sequencing pipeline. SWY and CM performed the OCT1 experiment and GOE performed the MET experiment. JR and HP wrote the manuscript with input from MW, CM, WCM, MH, and JSF. All authors read and approved the final manuscript.
Corresponding authors
Correspondence to Willow Coyote-Maestas or Harold Pimentel .
Ethics declarations
Ethics approval and consent to participate.
Not applicable.
Competing interests
JSF has consulted for Octant Bio, a company that develops multiplexed assays of variant effects. The other authors declare that they have no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1: supplementary figures and tables., additional file 2: review history., rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Rao, J., Xin, R., Macdonald, C. et al. Rosace : a robust deep mutational scanning analysis framework employing position and mean-variance shrinkage. Genome Biol 25 , 138 (2024). https://doi.org/10.1186/s13059-024-03279-7
Download citation
Received : 31 October 2023
Accepted : 14 May 2024
Published : 24 May 2024
DOI : https://doi.org/10.1186/s13059-024-03279-7
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
Genome Biology
ISSN: 1474-760X
- Submission enquiries: [email protected]
- General enquiries: [email protected]
- Open access
- Published: 21 May 2024
The mediating role of perceived social support on the relationship between lack of occupational coping self-efficacy and implicit absenteeism among intensive care unit nurses: a multicenter cross‑sectional study
- Qin Lin 1 na1 ,
- Mengxue Fu 2 na1 ,
- Kun Sun 3 ,
- Linfeng Liu 4 ,
- Pei Chen 1 ,
- Ling Li 1 ,
- Yanping Niu 1 &
- Jijun Wu 5
BMC Health Services Research volume 24 , Article number: 653 ( 2024 ) Cite this article
115 Accesses
Metrics details
Implicit absenteeism is very common among nurses. Poor perceived social support of intensive care unit nurses has a negative impact on their mental and physical health. There is evidence that lack of occupational coping self-efficacy can promote implicit absenteeism; however, the relationship between lack of occupational coping self-efficacy in perceived social support and implicit absenteeism of intensive care unit nurses is unclear. Therefore, this study aimed to evaluate the role of perceived social support between lack of occupational coping self-efficacy and implicit absenteeism of intensive care unit nurses, and to provide reliable evidence to the management of clinical nurses.
A cross-sectional study of 517 intensive care unit nurses in 10 tertiary hospitals in Sichuan province, China was conducted, of which 474 were valid questionnaires with a valid recovery rate of 91.6%. The survey tools included the Chinese version of Implicit Absenteeism Scale, the Chinese version of Perceived Social Support Scale, the Chinese version of Occupational Coping Self-Efficacy Scale and the Sociodemographic characteristics. Descriptive analysis and Pearson correlation analysis were performed using SPSS version 22.0, while the mediating effects were performed using AMOS version 24.0.
The average of intensive care unit nurses had a total implicit absenteeism score of (16.87 ± 3.98), in this study, the median of intensive care unit nurses’ implicit absenteeism score was 17, there were 210 intensive care unit nurses with low implicit absenteeism (44.3%) and 264 ICU nurses with high implicit absenteeism (55.7%). A total perceived social support score of (62.87 ± 11.61), and a total lack of occupational coping self-efficacy score of (22.78 ± 5.98). The results of Pearson correlation analysis showed that implicit absenteeism was negatively correlated with perceived social support ( r = -0.260, P < 0.001) and positively correlated with lack of occupational coping self-efficacy ( r = 0.414, P < 0.001). In addition, we found that perceived social support plays a mediating role in lack of occupational coping self-efficacy and implicit absenteeism [ β = 0.049, 95% CI of (0.002, 0.101)].
Conclusions
Intensive care unit nurses had a high level of implicit absenteeism with a moderate level of perceived social support and lack of occupational coping self-efficacy. Nursing managers should pay attention to the nurses those who were within low levels of social support and negative coping strategies, and take measures to reduce intensive care unit nurses’ professional stress, minimize implicit absenteeism.
Peer Review reports
Intensive care unit (ICU) nurses play a critical role in providing round-the-clock care to critically ill patients. However, the nature of their work can be stressful and demanding, resulting in physical and emotional challenges. The COVID-19 pandemic has further exacerbated these challenges, leading to negative outcomes for ICU nurses [ 1 ]. These challenges can take a toll on the physical and emotional well-being of ICU nurses, leading to negative outcomes such as low self-efficacy and implicit absenteeism [ 2 ]. The impact of the COVID-19 pandemic on the mental health of ICU nurses has been highlighted in recent research, with studies reporting high levels of anxiety, depression, and post-traumatic stress disorder among ICU nurses [ 3 ]. ICU nurses during the COVID-19 pandemic have been dealing with elevated levels of stress and emotional exhaustion [ 4 ]. The constant exposure to critically ill patients, the fear of personal infection, and the emotional toll of witnessing high mortality rates have contributed to increased psychological distress among ICU nurses [ 5 ]. Research suggests that during the COVID-19 pandemic, social support has become even more crucial for the mental health and well-being of healthcare professionals. A study found that perceived social support was inversely associated with anxiety and depression among healthcare workers during the pandemic [ 6 ]. In addition to the direct impact on mental health, the increased workload and exposure to infectious patients during the COVID-19 pandemic may exacerbate existing issues related to job satisfaction and burnout among ICU nurses. A study by Labrague and de Los Santos revealed that high levels of stress and workload significantly contributed to burnout among healthcare workers during the pandemic [ 7 ]. Besides, implicit absenteeism among ICU nurses poses a critical challenge within the broader framework of health systems and infrastructure, significantly affecting patient care, exacerbating workforce shortages, and contributing to systemic inefficiencies. ICU nurses are already in short supply, and implicit absenteeism contributes to workforce shortages. Emotionally disengaged nurses are more likely to experience burnout and turnover, leading to increased strain on the remaining staff and further exacerbating staffing shortages in critical care settings [ 8 ]. Implicit absenteeism can compromise patient safety and the quality of care provided in ICU. High levels of emotional disengagement may lead to decreased vigilance, diminished responsiveness to patient needs, and an increased likelihood of medical errors [ 9 ]. Therefore, it is important to explore strategies to support the mental health and well-being of ICU nurses during and after the COVID-19 pandemic.
Self-efficacy refers to an individual’s belief in their ability to perform a specific task or achieve a goal, and it plays a critical role in how individuals approach and cope with challenging situations. ICU nurses often face highly stressful and complex work environments, which characterized by high acuity patient care, time-sensitive decision-making, and emotional intensity. Firstly, the nature of ICU nursing involves caring for critically ill patients with complex medical conditions, ICU nurses are required to monitor vital signs, administer intricate treatments, and respond rapidly to dynamic patient situations [ 10 ]. This high acuity patient care demands a heightened level of attention and can lead to chronic stress and fatigue. Secondly, ICU nurses face constant time pressures and are often required to make swift, critical decisions, the need for quick and accurate responses to changing patient conditions adds a layer of stress to their work environment. This time-sensitive decision-making is inherent to ICU nursing and contributes to the overall complexity of their role [ 11 ]. Thirdly, ICU nurses regularly witness suffering, mortality, and family distress, the emotional intensity of providing care in life-threatening situations can lead to moral distress and emotional exhaustion. The burden of managing these emotions can have lasting effects on the mental health and well-being of ICU nurses [ 12 ]. Therefore, ICU nurse self-efficacy is an important area of research as it can affect job performance and job satisfaction. One study found that higher levels of self-efficacy were associated with greater job satisfaction and lower levels of emotional exhaustion among ICU nurses [ 13 ]. Another study suggested that ICU nurses with higher self-efficacy were more likely to engage in proactive coping behaviors, which in turn were associated with lower levels of emotional exhaustion [ 14 ].
Research has shown that social support is a critical factor in promoting the well-being of ICU nurses. Studies have found that social support from colleagues and supervisors is associated with lower levels of stress and burnout in ICU nurses [ 15 ]. In addition, social support from family and friends has been found to be important in buffering the negative effects of job stress on mental health in ICU nurses [ 16 ]. One study found that perceived social support from colleagues was positively associated with job satisfaction and negatively associated with emotional exhaustion among ICU nurses [ 17 ]. Another study found that social support from supervisors was positively associated with job satisfaction and negatively associated with turnover intention among ICU nurses [ 18 ]. Despite the recognized importance of social support for ICU nurses, more research is needed to fully understand the specific mechanisms through which social support operates and to develop effective interventions to support ICU nurses in the workplace.
Implicit absenteeism refers to a state where employees may be physically present at work but are emotionally or mentally disengaged, resulting in decreased job performance and overall contribution to the workplace [ 19 ]. While this term may not be widely used in the literature, the concept aligns with the broader understanding of presenteeism, which involves employees being on the job but not fully engaged or productive [ 20 ]. It is a more subtle form of employee disengagement than explicit absenteeism, such as calling in sick or taking time off. Implicit absenteeism is often associated with mental health conditions such as stress, burnout, and emotional exhaustion. Employees experiencing these mental health challenges may find it difficult to fully engage in their work, leading to a state of absenteeism despite being physically present [ 21 ]. Chronic health conditions can also contribute to implicit absenteeism, as employees dealing with physical health issues may struggle to fully engage in their tasks. This may manifest as reduced productivity, lack of focus, and an overall decline in job performance [ 22 ]. Implicit absenteeism can also impact nurses’ performance in the workplace, such as reduced patient interaction, reduced awareness of occupational protection, and lack of participation in professional development [ 23 , 24 , 25 ]. Research has suggested a negative relationship between nurse burnout, a concept closely related to implicit absenteeism, and job performance. For instance, a study by Van Bogaert et al. found that nurse burnout was significantly associated with lower perceived performance in various dimensions, including clinical care, teamwork, and job satisfaction [ 26 ]. One study found that high levels of job stress and low job control were associated with increased levels of implicit absenteeism among ICU nurses. The study suggested that interventions aimed at reducing job stress and increasing job control could be effective in reducing implicit absenteeism in this population [ 27 ]. Moreover, another study found that perceived organizational support was negatively associated with implicit absenteeism in ICU nurses. The study suggested that providing ICU nurses with a supportive work environment, such as opportunities for professional development and recognition, could reduce the occurrence of implicit absenteeism [ 28 ]. Moreover, a study on Chinese ICU nurses showed that implicit absenteeism were negatively correlated with perceived social support ( r =-0.390, P < 0.05) and positively correlated with lack of occupational coping self-efficacy ( r = 0.478, P < 0.05) [ 29 ]. The Job Demand-Resource (JD-R) Model is a theoretical framework in occupational and organizational psychology that was developed to understand the impact of job characteristics on employee well-being and performance. The model was initially proposed by Arnold Bakker and Evangelia Demerouti in the early 2000s [ 30 ]. The JD-R Model is widely used to investigate the factors that contribute to employee engagement, burnout, and overall job satisfaction. This model suggests that job resources, including social support, can buffer the impact of job demands on employee well-being and performance. Based on the above-mentioned literature reviews, this study puts forward the following hypotheses: First, lack of occupational coping self-efficacy is related to the implicit absenteeism of ICU nurses (H1). Second, lack of occupational coping self-efficacy is correlated with perceived social support of ICU nurses (H2). Third, perceived social support is correlated with the implicit absenteeism of ICU nurses (H3). Finally, perceived social support plays a mediating role in the relationship between lack of occupational coping self-efficacy, and implicit absenteeism (H4). By investigating the specific mechanisms through which social support operates, and the impact of the COVID-19 pandemic on ICU nurses, this study can provide important insights into interventions aimed at improving the well-being and job performance of ICU nurses.
Study design and ethics
A cross-sectional study was conducted in March 2022 using a convenience sampling method to select ICU nurses from 10 tertiary hospitals of 5 cities in Sichuan province, China. This study was conducted in accordance with the Helsinki Declaration. The study protocol was approved by the Ethics Committee of People’s Hospital of Deyang (2021-04-056-K01). The questionnaires remain anonymous, the first page of the online questionnaire is the informed consent form, participants indicate their agreement to participate in the survey by clicking the “Agree” option in the online assessment, all data collected are confidential and all participants had informed consent.
Participants
A total of 517 questionnaires were issued and collected. 43 questionnaires were excluded due to evident patterns in the responses across various questionnaire items, and the surveys from the same hospital exhibited noticeable similarities. After eliminating 43 invalid questionnaires, 474 valid questionnaires were received, with a valid recovery rate of 91.6%.
The eligibility criteria were as follows: (1) registered nurses, (2) more than 12 months of ICU nursing experience, (3) willing to participate in the survey. The exclusion criteria were as follows: (1) training nurses or rotating nurses, (2) not working in the hospital during the survey period, such as long-term sick leave or maternity leave.
Survey tools
Sociodemographic characteristics.
Sociodemographic characteristics included age, gender, marital status, educational background, professional title, management position, working experience in ICU, employment form, turnover intention, physical pain, occupational stress, night shift experience and workplace violence.
The Chinese version of implicit absenteeism scale
The scale was developed by Koopman et al. [ 31 ] and translated and revised in to Chinese by Zhao Fang [ 32 ]. First, Zhao Fang and others translated, back-translated, and culturally adapted the scale. Subsequently, they conducted a survey on 935 staff members to validate the reliability and validity of the scale. The results indicated that the Cronbach’s α coefficients for each dimension of the scale ranged from 0.76 to 0.90. The structural validity revealed two latent factors, namely, work constraints and work vigor, with a cumulative variance contribution rate of 81.01%. The reliability and validity of the scale were deemed satisfactory. In another study, Liu Jia-wen et al. employed the same scale to conduct a questionnaire survey on 150 emergency department nurses in Nanchang, China, from September to October 2020 [ 33 ]. The Cronbach’s α coefficient for the scale was found to be 0.71, indicating good reliability. This scale consists of 6 items and the scale is used to estimate the employee productivity loss caused by the implicit absenteeism with a specific health status in the past month. This scale is based on a 5-point Likert scale, ranging from “completely disagree” to “completely agree”. The score for each item ranges from 1 to 5, and the total score ranges from 6 to 30, with higher scores indicating higher levels of productivity loss due to health status and the less effective attendance.
The Chinese version of perceived social support scale
The scale was developed by Zimet et al. [ 34 ] and translated and revised in to Chinese by Jiang Qian-jin [ 35 ]. In December 2019, Xiang Feng-ming and others employed this scale to conduct a questionnaire survey on 182 novice nurses in Wenzhou, China. The results showed that the Cronbach’s α coefficients for the overall scale and each dimension were 0.856, 0.803, 0.851, and 0.866, respectively [ 36 ]. The scale was used to measure perceived social support of ICU nurses. This scale consists of 3 dimensions and 12 items: 4 items for family support, 4 items for friends support, 4 items for other support. This scale is based on a 7-point Likert scale, 1 point stand for very disagree and 7 points stand for very agree. The total score ranges from 12 to 84, with higher scores indicating higher levels of perceived social support. The Cronbach’s alpha coefficient of this scale 0.90.
The Chinese version of occupational coping self-efficacy scale
The Chinese version of Occupational Coping Self-Efficacy Scale was used to measure the lack of occupational coping self-efficacy of ICU nurses. The scale was developed by Pisanti et al. [ 37 ] and translated and revised in to Chinese by Zhai Yan-xue [ 38 ]. First, Zhai Yan-xue organized researchers to translate and back-translate the scale. Subsequently, cultural adaptation was conducted by three experienced experts. Following this, modifications were made based on a preliminary survey of 50 nurses. Finally, a survey was conducted on 1172 nurses from five public hospitals to validate the reliability and validity of the scale. The results indicated a Cronbach’s α coefficient of 0.882, a test-retest reliability of 0.991, I-CVI of 0.833 ∼ 1.000, S-CVI/UA of 0.889 and S-CVI/Ave of 0.981, demonstrating good reliability and validity of the scale [ 38 ]. This scale consists of 2 dimensions and 9 items: 6 items for professional burden, 3 items for difficulties in getting along with each other. This scale is based on a 5-point Likert scale, 1 point means “strongly disagree”, 5 points means “strongly agree”, and the total score ranges from 9 to 45, with higher scores indicating lower levels of occupational coping self-efficacy, means that the lack of occupational coping self-efficacy. The Cronbach’s alpha coefficient of this scale was 0.88, and the Cronbach’s alpha coefficients of the subscales were 0.79 and 0.87.
Data collection
We contacted the head nurses of ICU departments in 10 tertiary hospitals of 5 cities in Sichuan province, and distributed the online links of questionnaires to them to finish the survey. Voluntary and anonymity principle, inclusion and exclusion criteria were indicated on the first page of the online questionnaire. If ICU nurses clicked on the online link and submitted the questionnaire, it was informed consent by default. We set all answers must be filled out before submission. And two researchers checked the questionnaires to ensure the validity and integrity of the survey.
Data analysis
This study used SPSS version 22.0 and AMOS version 24.0 (IBM, Armonk, NY, USA) for statistical analysis of the data. Firstly, descriptive analysis was used to describe the sociodemographic characteristics and main variables of ICU nurses. Count data were expressed as percentage (%). Measurement data were expressed as (mean ± standard deviation), in addition, independent samples t-test and one-way ANOVA were used for comparison between groups. Pearson correlation analysis was performed to analysis the correlation of social support, lack of occupational coping self-efficacy and implicit absenteeism. Besides, we used lack of occupational coping self-efficacy as the independent variable and implicit absenteeism as the dependent variable to examine the mediating role of social support. In this study, we take α = 0.05 as the test standard.
Sociodemographic characteristics of ICU nurses
As detailed in Table 1 , a total of 474 ICU nurses were included in this study with a mean age of 32.19 years (range 21 to 56) and a mean year of ICU working experience of 8.07 years (range 1 to 36). Most of the ICU nurses were female (91.8%) and married (58.0%). In terms of educational background, 77.8% of ICU nurses have a bachelor’s degree. Besides, 82.7% of ICU nurses were in the authorized strength and contract system. Nearly 18% of ICU nurses were are experiencing physical pain. About 35% of ICU nurses admitted that they have high level occupational stress. In addition, 34.5% of ICU nurses have experienced workplace violence.
There were significant differences in the marital status, professional title, management position, working experience in ICU, turnover intention, physical pain, occupational stress, night shift experience and workplace violence between ICU nurses with high and low implicit absenteeism (all P < 0.05). And no significant differences were found in the in the gender, age, educational background and employment form between ICU nurses with high and low implicit absenteeism (all P > 0.05).
Scores of implicit absenteeism scale, perceived social support scale and occupational coping self-efficacy scale
As shown in Table 2 , the average of ICU nurses had a total implicit absenteeism score of (16.87 ± 3.98), indicating that ICU nurses had a high level of implicit absenteeism.
Previous research [ 39 ] has reported that more than half of nurses have implicit absenteeism and take the median of nurses’ implicit absenteeism score as the cut-off point to differentiate the high and low implicit absenteeism. In this study, the median of ICU nurses’ implicit absenteeism score was 17. Therefore, there were 210 ICU nurses with low implicit absenteeism (44.3%) and 264 ICU nurses with high implicit absenteeism (55.7%).
In addition, a total perceived social support score of (62.87 ± 11.61), indicating that ICU nurses had a moderate level of perceived social support, and a total lack of occupational coping self-efficacy score of (22.78 ± 5.98), indicating that ICU nurses had a moderate level of lack of occupational coping self-efficacy. The detailed information is shown in Table 3 .
Analysis of the correlation between implicit absenteeism, perceived social support and lack of occupational coping self-efficacy
The results of Pearson correlation analysis showed that implicit absenteeism was negatively correlated with perceived social support ( r = -0.260, P < 0.001) and positively correlated with lack of occupational coping self-efficacy ( r = 0.414, P < 0.001), Table 4 .
Mediating effect of perceived social support between lack of occupational coping self-efficacy and implicit absenteeism in ICU nurses
Figure 1 ; Table 5 show the Structural Equation Model results. The standardized model paths are shown in Fig. 1 . The direct effect, indirect effect, and total effect are shown in Table 5 . The standardized model had a good model fit with the data (Table 6 ).
As shown in Table 5 , lack of occupational coping self-efficacy ( β = 0.404, for total effect) had significant positive relationships with implicit absenteeism. The results also indicated that the indirect effect ( β = 0.049) of lack of occupational coping self-efficacy on implicit absenteeism was significant as well as its direct effect on perceived social support ( β = -0.420). These findings show that higher occupational coping self-efficacy was related to lower implicit absenteeism and higher perceived social support, and that perceived social support partially mediated the relationship between lack of occupational coping self-efficacy and implicit absenteeism due to significant direct and indirect paths.

The mediating effect model of perceived social support between lack of occupational coping self-efficacy and implicit absenteeism in ICU nurses
Nursing workforce is critical in delivering quality care to patients in healthcare settings. However, absenteeism among nurses has become a significant concern for healthcare organizations globally. The phenomenon of nurse’s implicit absenteeism has been extensively studied in both China and other countries. A study found that the prevalence of nurse’s implicit absenteeism was 11.7% in China, and the factors influencing implicit absenteeism included age, working experience, and job satisfaction [40]. Similarly, a study conducted in Saudi Arabia reported that 24.7% of nurses experienced implicit absenteeism, with workload and job stress being the significant predictors [ 41 ]. Moreover, research conducted in the United States (US) and Europe also highlighted the problem of implicit absenteeism among nurses. A study in the US found that implicit absenteeism was associated with burnout, job dissatisfaction, and intention to leave the profession [ 42 ]. In addition, a study reported that implicit absenteeism was associated with workload, job demands, and role ambiguity [ 43 ]. Our study showed that the implicit absenteeism score of ICU nurses was (16.87 ± 3.98), which was similar to implicit absenteeism score of (17.25 ± 3.51) for ICU nurses in another study in China [ 44 ]. Similar research conclusions are also found in 200 ICU nurses from tertiary comprehensive hospitals in Beijing, where their implicit absenteeism score was (16.65 ± 4.69) [ 45 ]. This implies that ICU nurses in China generally experience implicit absenteeism, a result deserving attention from nursing managers. Analyzing this, it may be attributed to the global shortage of nursing personnel, where ICU nurses face a similar shortage of human resources. Given that ICU patients are often critically ill with rapidly changing conditions, the tasks of ICU nurses are less substitutable, making them prone to implicit absenteeism. Additionally, in the ICU team nursing model, team members taking sick leave may increase the workload for other members. Based on a sense of responsibility to colleagues, many tend to choose implicit absenteeism. Hence, healthcare organizations must develop strategies to manage and reduce implicit absenteeism among nurses to ensure quality patient care.
In recent years, research on perceived social support among ICU nurses has gained attention both in China and abroad. Perceived social support is the belief that one has access to individuals, groups, or networks that provide assistance and care in times of need [ 46 ]. ICU nurses are exposed to various stressors such as heavy workloads, long working hours, and critically ill patients, which can lead to emotional exhaustion, burnout, and turnover intention [ 47 ]. Therefore, perceived social support is crucial for their psychological well-being and job satisfaction. In China, several studies have investigated perceived social support among ICU nurses. For example, a study found that ICU nurses perceived low social support from their colleagues and supervisors, which was negatively associated with their job satisfaction [ 48 ]. Another study showed that ICU nurses who perceived high social support had lower levels of burnout and higher levels of work engagement [ 49 ]. Similarly, a study conducted in the Netherlands revealed that ICU nurses who perceived high social support from their colleagues had lower levels of emotional exhaustion and turnover intention [ 50 ]. Another study found that perceived social support from family and friends was positively associated with job satisfaction and negatively associated with emotional exhaustion among ICU nurses [ 51 ]. In this study, the perceived social support score of ICU nurses was (62.87 ± 11.61) points, which is lower than that of the research of Wu Peng [ 52 ] and Wang Li-jiao [ 53 ], indicating that nurses’ perceived social support had a moderate level in China. This suggests that the level of social support among ICU nurses in China is generally low. Previous research suggests a close correlation between nurses’ professional identity, job performance, and social support levels. Nurses who receive good support from family, friends, and other social networks often can maintain both physical and mental health, smoothly handle job responsibilities, accomplish tasks successfully, and experience higher job satisfaction [ 52 , 54 ]. With nurses being recognized as a high-risk profession, the social support received by nurses has been widely studied in the field of nursing human resources management. Concerningly, the level of social support for nurses in China and globally is not high. Our nurses are currently experiencing significant work pressure and physical fatigue, making it challenging for them to fully engage in their work. Therefore, it is important for healthcare organizations to develop interventions that enhance social support among ICU nurses to promote their well-being and reduce turnover intention. Overall, it is important for healthcare organizations to develop interventions that enhance social support among ICU nurses to promote their well-being and reduce turnover intention.
Occupational coping self-efficacy refers to an individual’s belief in their ability to effectively manage job-related stressors and challenges [ 55 ]. It is a crucial factor for promoting nurses’ occupational growth and sense of occupational benefit, as well as improving patient outcomes. Studies have shown that ICU nurses have relatively low levels of occupational coping self-efficacy. For example, a study found that ICU nurses with higher levels of occupational coping self-efficacy reported lower levels of emotional exhaustion and depersonalization, and higher levels of personal accomplishment [ 56 ]. A study also found that occupational coping self-efficacy was positively associated with job satisfaction among ICU nurses in China [ 57 ]. Another study found that occupational coping self-efficacy was positively associated with job satisfaction and negatively associated with burnout among ICU nurses in Taiwan [ 58 ]. In addition, a study showed that ICU nurses in Saudi Arabia with higher levels of occupational coping self-efficacy reported lower levels of emotional exhaustion and higher levels of personal accomplishment [ 59 ].
The results of this study suggest that the total score of lack of occupational coping self-efficacy was (22.78 ± 5.98). This result suggests that the self-efficacy levels of the majority of ICU nurses in China need improvement. The findings of this study are consistent with a previous survey on the self-efficacy of ICU nurses in China [ 60 ], and compared to other clinical nurses in China, ICU nurses exhibit lower levels of self-efficacy [ 61 – 62 ]. Additionally, when compared to professions such as secondary school teachers and pilots [ 63 – 64 ], ICU nurses seem to experience more widespread lower self-efficacy levels. In China, most ICU nurses work an average of more than 8 h per day. Under the prolonged work pressures, ICU nurses have less time available for interpersonal relationships, family activities, rest, and sleep. Therefore, this may lead to occupational burnout, lower self-efficacy among ICU nurses, and potentially trigger work-family conflicts. The above results provide clear evidence indicating that nursing managers should pay closer attention to the self-efficacy levels of ICU nurses in the future, as it is closely associated with the professional development of ICU nurses.
Our correlation results show that implicit absenteeism of ICU nurses was negatively correlated with perceived social support and its various dimensions ( r =-0.212 ∼ -0.260, P <0.01). The lower the perceived social support, the higher the implicit absenteeism. The results of this study indicate a negative correlation between support from family and implicit absenteeism among ICU nurses, consistent with previous research [ 65 ]. Family support not only ensures the maintenance of a positive mood for ICU nurses but also contributes to their physical well-being and active engagement in work. Furthermore, support from friends is negatively correlated with implicit absenteeism among ICU nurses. Friends support allow ICU nurses to feel embraced, understood, and assisted from the outside, enabling them to confront life and work challenges positively and facilitating the completion of work tasks [ 66 ]. Lastly, support from other sources is negatively correlated with implicit absenteeism among ICU nurses. According to reports [ 29 ], having more organizational support enables nurses to better immerse themselves in their work, where their personal values are fully reflected in patient care. This leads to a more positive response to work and reduces the impact of compromised health productivity to a lower level. In contrast, implicit absenteeism of ICU nurses was positively correlated with lack of occupational coping self-efficacy and its various dimensions ( r = 0.379 ∼ 0.414, P <0.01). The higher the occupational coping self-efficacy, the lower the implicit absenteeism. These findings suggest that both perceived social support and lack of occupational coping self-efficacy are important factors in predicting implicit absenteeism among ICU nurses. Given the findings, it is important for healthcare organizations to prioritize interventions that can help to increase perceived social support and occupational coping self-efficacy among ICU nurses. For example, providing opportunities for social support, such as peer mentoring or support groups, can help to reduce feelings of isolation and increase job satisfaction [ 67 ]. Additionally, training programs that focus on developing coping skills and self-efficacy can help nurses to better manage the demands of their job and feel more confident in their abilities [ 68 ]. Here are some feasible approaches that healthcare organizations can consider to improve ICU nurses’ perceived social support. Firstly, establishing peer mentoring programs where experienced ICU nurses provide support and guidance to newer or less experienced colleagues. Encouraging regular interactions and check-ins to foster a sense of camaraderie and mutual support. secondly, creating support groups within the ICU setting, where nurses can share experiences, discuss challenges, and provide emotional support to each other. Facilitating group discussions led by mental health professionals to address common stressors and coping strategies. Thirdly, providing training on effective communication skills to enhance interpersonal relationships among ICU team members. Emphasizing active listening and empathy to create a supportive environment. The above strategies for social support are among colleagues within the ICU setting. ICU nurses’ social support from family and friends are different with colleagues support and may implement distinct strategies recognizing the unique dynamics of each relationship. For support from family and friends, interventions could involve educational sessions for family and friends to understand the demands and stressors specific to ICU nursing, encouraging open communication channels between nurses and their loved ones, and providing resources for family support. This might include counseling services or support groups for family and friends of ICU nurses. In addition, the healthcare organizations can improve the occupational coping self-efficacy of ICU nurses through the following measures. First of all, conducting workshops focused on enhancing specific coping skills, such as time management, stress reduction techniques, and conflict resolution. Encouraging ongoing professional development to build a sense of competence. Besides, implementing recognition programs to acknowledge the hard work and dedication of ICU nurses. Providing regular feedback and appreciation for their contributions to patient care. Finally, organizing team-building activities to foster a positive work environment and strengthen teamwork among ICU staff. Creating a culture that values collaboration and mutual support. Furthermore, the relationship between social support, self-efficacy, and absenteeism due to physical health is a complex interplay influenced by various factors. On the one hand, social support, whether from colleagues, friends, or family, can act as a buffer against ICU nurses’ stress. Lower stress levels are associated with improved physical health and a reduced likelihood of needing time off due to health issues. On the other hand, social support networks can provide practical assistance, such as help with ICU nurses’ childcare or transportation, which may mitigate the impact of physical health issues on absenteeism. Having a reliable support system may reduce the need for extended time off for health-related issues. Self-efficacy is associated with absenteeism due to physical health, which is reflected in the following aspects. First, high self-efficacy is associated with a greater likelihood of adopting and maintaining healthy behaviors, such as regular exercise and a balanced diet. Healthy lifestyles contribute to overall well-being and can reduce ICU nurses’ risk of absenteeism due to physical health issues. next, individuals with high self-efficacy often possess effective coping mechanisms to manage pain, discomfort, or chronic conditions. The ability of ICU nurses’ to cope with health challenges may reduce the severity and duration of illnesses, potentially minimizing absenteeism.
The results of our mediating role analysis show that ICU nurses’ the lack of occupational coping self-efficacy had a direct positive predictive influence on their implicit absenteeism and that perceived social support had a partial mediating effect between lack of occupational coping self-efficacy and implicit absenteeism. The higher the level of occupational coping self-efficacy, the better the perceived social support and the lower the implicit absenteeism. The reasons for this relationship may be as follows: firstly, as the level of perceived social support increases, ICU nurses are more likely to feel external support from family, friends, and other sources, which can be utilized to effectively solve their problems or difficulties [ 69 ]. Secondly, higher levels of perceived social support can help ICU nurses to redefine difficult situations and strengthen their ability to regulate feelings of distrust, anxiety, and fear, thereby enhancing their positive attitudes towards handling difficulties and reducing implicit absenteeism [ 70 ]. In addition, a higher level of occupational self-efficacy enables ICU nurses to have a correct understanding of the challenges they face at work, form positive professional identities and values, and increase their confidence in dealing with difficulties [ 71 ]. In the practice environments of many hospitals in China, issues such as workload overload, poor working conditions, and lack of adequate compensation may exist [ 72 ]. The working environment in the ICU is often characterized by its enclosed nature, and the workload is frequently higher than in other departments. This may explain why many ICU nurses may develop lower self-efficacy and lack social support. Social support has the potential to uplift the work enthusiasm and professional spirit of ICU nurses, fostering a positive professional attitude and encouraging them to contribute to patient health and the development of medical institutions. However, as observed in this study, when experiencing lower self-efficacy, ICU nurses exhibit compromised health productivity, refrain from making additional efforts for the medical institution, and develop a negative attitude towards their work. If the social support for ICU nurses diminishes due to lower self-efficacy, it is unsurprising that their sense of mission as “health guardians” diminishes as well, meaning ICU nurses may no longer see serving the health of patients as their mission. As mentioned in the Conservation of Resources theory, when ICU nurses lose their resources (similar to losing social support in this study), they may experience varying degrees of psychological stress and lose confidence in the organization. With increased separation, psychological or physical issues may arise, such as ICU nurses being physically unwilling to engage in work, emotionally reluctant to integrate into the work team, cognitively becoming less active, and concealing their feelings and thoughts, all of which signify the occurrence of implicit absenteeism. Moreover, it can further impact the attitudes, behaviors, and beliefs of ICU nurses towards their profession, negatively affecting professional identity and a sense of professional mission. Therefore, hospital nursing managers need to pay closer attention to the current status of self-efficacy and social support among ICU nurses, strengthening their professional attitudes from aspects of organizational support, colleague support, and material support to promote healthy practices in their profession.
On November 29th, 2021, the General Office of the People’s Government of Sichuan Province issued the Implementation Plan for Promoting the High-quality Development of Public Hospitals in Sichuan Province, which emphasized the reform of personnel management system and the increase of nurses’ equipment, so that the overall ratio of doctors to nurses in public hospitals gradually reached about 1: 2. In addition, the salary distribution system should be reformed to encourage the internal distribution of hospitals to be tilted towards high-risk and high-intensity posts. The above policies and programs provide strong external social support for ICU nurses. Identifying institutional gaps and proposing improvements to support the workforce involves a comprehensive examination of existing policies, practices, and organizational structures. Common gaps include limited mental health support with suggestions for comprehensive programs and manager training, inadequate work-life balance policies calling for flexible arrangements and clear remote work options, a lack of professional development opportunities necessitating ongoing training, mentorship programs, and support for continuous learning, and insufficient diversity and inclusion initiatives requiring diversity training, committees, and regular assessments. Other gaps encompass poor communication channels, suggesting enhancements to internal communication strategies and regular town hall meetings, limited health and wellness programs requiring initiatives addressing physical and mental health, and inadequate remote work infrastructure, calling for technology investment and clear policies. Additionally, the absence of recognition and rewards programs underscores the need for implementation alongside leadership training, regular employee surveys, clear career progression paths, encouragement of peer support networks, and continuous evaluation and adaptation of workplace policies for ongoing improvement. Addressing these gaps and implementing improvements necessitates a collaborative effort from leadership, human resources, and employees, emphasizing ongoing assessment, communication, and a genuine commitment to workforce well-being and development.
Limitations and recommendations
This research has some limitations that need to be acknowledged. Firstly, this study is a cross-sectional design, which cannot determine the causal relationship between variables.
Secondly, this study employed a convenience sampling method to select participants, which may result in meaningful differences in various sociodemographic categories. These differences among the population could limit the generalizability of the results to a broader population, introduce bias to the sample, and potentially act as confounding variables affecting the relationship between the independent and dependent variables. Therefore, in future research, efforts to enhance the representativeness of the sample will be a focus of our endeavors. Finally, this study was conducted during the COVID-19 pandemic, which may have led to higher levels of implicit absenteeism and lower levels of occupational coping self-efficacy being measured.
Despite these limitations, this study can provide valuable information for future research. For example, this study describes the occurrence of implicit absenteeism among ICU nurses from the perspectives of social support and self-efficacy and establishes a structural equation model, making the study of implicit absenteeism more comprehensive and richer. Additionally, this study confirms the mediating role of perceived social support in the relationship between lack of occupational coping self-efficacy and implicit absenteeism among ICU nurses, suggesting that increasing perceived social support and occupational coping self-efficacy can reduce implicit absenteeism, decrease negative emotions and psychological stress, improve ICU nurses’ job satisfaction and promote their mental health.
The results of this study indicate that there is a high prevalence of implicit absenteeism among ICU nurses, with 55.7% of ICU nurses evaluated as having a high level of implicit absenteeism and 44.3% evaluated as having a low level of implicit absenteeism. In addition, implicit absenteeism among ICU nurses is negatively correlated with perceived social support and positively correlated with lack of occupational coping self-efficacy. Perceived social support plays a significant mediating role between lack of occupational coping self-efficacy and implicit absenteeism among ICU nurses. In future departmental management, ICU managers need to pay attention to nurses with low levels of social support and negative coping strategies, and take measures such as providing peer support, forming work groups, and arranging work tasks reasonably to reduce nurses’ professional stress, minimize implicit absenteeism, and promote the development of high-quality nursing teams.
Data availability
All data generated or analyzed during this study are included in this published article.
Cai H, Tu B, Ma J, Chen L, Fu L, Jiang Y. Psychological impact and coping strategies of frontline medical staff in Hunan between January and March 2020 during the outbreak of coronavirus disease 2019 (COVID19) in Hubei, China. Med Sci Monit. 2020;26:e924171.
CAS PubMed PubMed Central Google Scholar
Hu D, Kong Y, Li W, Han Q, Zhang X, Zhu L-X, Zhu S-H. Frontline nurses’ burnout, anxiety, depression, and fear statuses and their associated factors during the COVID-19 outbreak in Wuhan, China: a large-scale cross-sectional study. E Clin Med. 2020;24:100424.
Google Scholar
Sasangohar F, Jones SL, Masud FN, Vahidy FS, Kash BA. Provider burnout and fatigue during the COVID-19 pandemic: lessons learned from a high-volume intensive care unit. Anesth Analg. 2020;1:106–11.
Article Google Scholar
Greenberg N, Docherty M, Gnanapragasam S, Wessely S. Managing mental health challenges faced by healthcare workers during covid-19 pandemic. BMJ. 2020;368:1211.
Morgantini LA, Naha U, Wang H, Francavilla S, Acar Ö, Flores JM, Cénat JM. Factors contributing to healthcare professional burnout during the COVID-19 pandemic: a rapid turnaround global survey. PLoS ONE. 2020;159:e0238217.
Pappa S, Ntella V, Giannakas T, Giannakoulis VG, Papoutsi E, Katsaounou P. Prevalence of depression, anxiety, and insomnia among healthcare workers during the COVID-19 pandemic: a systematic review and meta-analysis. Brain Behav Immun. 2020;88:901–7.
Article CAS PubMed PubMed Central Google Scholar
Labrague LJ, de Los Santos J. COVID-19 anxiety among front-line nurses: predictive role of organisational support, personal resilience and social support. J Nurs Manage. 2020;7:1653–61.
Aiken LH, Sloane DM, Bruyneel L, Van den Heede K, Griffiths P, Busse R, Diomidous M, Kinnunen J, Kózka M, Lesaffre E, McHugh MD. Nurse staffing and education and hospital mortality in nine European countries: a retrospective observational study. Lancet. 2014;9931:1824–30.
Kutney-Lee A, Germack H, Hatfield L, Kelly MS, Maguire MP, Dierkes A, Del Guidice MM, Aiken LH. Nurse engagement in shared governance and patient and nurse outcomes. J Nurs Admini. 2016;11:605.
Poncet MC, Toullic P, Papazian L, Kentish-Barnes N, Timsit JF, Pochard F, Chevret S, Schlemmer B, Azoulay E. Burnout syndrome in critical care nursing staff. Am J Respirat Crit Care Med. 2007;7:698–704.
Gillespie BM, Chaboyer W, Wallis M, Grimbeek P. Resilience in the operating room: developing and testing of a resilience model. J Adv Nurs. 2007;4:427–38.
Mealer M, Burnham EL, Goode CJ, Rothbaum B, Moss M. The prevalence and impact of post traumatic stress disorder and burnout syndrome in nurses. Depress Anxiety. 2009;12:1118–26.
Jang H, Kim Y, Lee SA, Kim J. The relationship between self-efficacy and job satisfaction among intensive care unit nurses: the mediating effect of emotional exhaustion. J Clin Nurs, 2021; 3–4: 522–30.
Wang J, Liu L, Liu X, Wang L, Wang J. The mediating role of proactive coping in the relationship between self-efficacy and emotional exhaustion among intensive care nurses. J Clin Nurs. 2020;9–10:1621–29.
Zhang C, Zou P, Zhang Y, Liu X, Wang J. Work stress, social support, and burnout among Chinese nurses. J Nurs Manage. 2020;1:186–94.
Zhang Y, Liu X, Wang J, Sun L. Effect of social support on mental health in Chinese intensive care unit nurses: a cross-sectional survey study. BMJ Open. 2019;5:e027375.
Mosadeghrad AM, Ferlie E, Rosenberg D. A study of the relationship between job satisfaction, organizational commitment and turnover intention among hospital employees. Health Serv Manag re, 2016; 1–2: 74–80.
Liu Y, Li Z, Li J. The relationship between supervisory social support and turnover intention among intensive care nurses: a moderated mediation model. Int J Nurs Sci. 2020;2:167–72.
Jin Y, Bi Q, Song G, Wu J, Ding H. Psychological coherence, inclusive leadership and implicit absenteeism in obstetrics and gynecology nurses: a multi-site survey. BMC Psychiatry. 2022;1:1–10.
Zhang Y, Lei S, Chen L, Yang F. Influence of job demands on implicit absenteeism in Chinese nurses: mediating effects of work-family conflict and job embeddedness. Front Psychol. 2023;14:1265710.
Article PubMed PubMed Central Google Scholar
Demerouti E, Le Blanc PM, Bakker AB, Schaufeli WB, Hox J. Present but sick: a three-wave study on job demands, presenteeism and burnout. Career Dev Int. 2009;1:50–68.
Johns G. Presenteeism in the workplace: a review and research agenda. J Organ Behav. 2010;4:519–42.
Li M-L, Zhong W-J. Study on the relationship between nurses’ hidden absence and patients’ safety attitude. Evidence-based Nurs. 2022;12:1698–702.
Zhu S-S, Lu J-Y. The mediating role of hospital safety atmosphere between nurses’ hidden absence and occupational protective behavior. Gen Nurs. 2022;31:4347–50.
Jin Y, Song G-Q, Ding H, Bi Q-Q. The mediating effect of psychological consistency on inclusive leadership and implicit absence of nurses in obstetrics and gynecology. J Nurs Sci. 2022;17:66–8.
Van Bogaert P, Clarke S, Roelant E, Meulemans H, Van de Heyning P. Impacts of unit-level nurse practice environment and burnout on nurse‐reported outcomes: a multilevel modelling approach. J Clin Nurs. 2010;11–12:1664–74.
Liu Y, Wu Y, Wang J, Han Y. Implicit absenteeism in intensive care unit nurses: a cross-sectional survey. J Nurs Manage. 2021;1:27–34.
Zhu X, You L-M, Zheng J, Liu K, Fang J-B, Hou S-X. Predictors of implicit absenteeism in intensive care unit nurses: a cross-sectional survey. J Adv Nurs. 2019;7:1599–609.
Liu X-L, Jia P, Wen X-X, Huang X-H, Wu J-J. Analysis on the current situation and influencing factors of recessive absence of ICU nurses in China. J Nurs. 2022;16:1–5.
CAS Google Scholar
Demerouti E, Bakker AB, Nachreiner F, Schaufeli WB. The job demands-resources model of burnout. J Appl Psychol. 2001;3:499.
Koopman C, Pelletier KR, Murray JF, Sharda CE, Berger ML, Turpin RS, Hackleman P, Gibson P, Holmes DM, Bendel T. Stanford presenteeism scale: health status and employee productivity. J Occup Environ Med. 2002;1:14–20.
Zhao F, Dai J-M, Yan S-Y, Yang P-D, Fu H. Reliability and validity of the Chinese version of the Health Productivity Impairment Scale (SPS-6). Chin J Occup Health Occup Dis. 2010;9:679–82.
Liu J-W, Xie Z-Q, Yu Y-Z, Wu S-L, Zhang B-Z, Yang Z. Study on the influencing factors of nurses’ recessive absence in emergency department of third-class first-class hospitals in Nanchang. Occup Heal. 2023;2:198–202.
Zimet GD, Powell SS, Farley GK, Werkman S, Berkoff KA. Psychometric characteristics of the multidimensional scale of perceived social support. J Pers Assess. 1990;3–4:610–17.
Jiang Q-J. Perceived Social Support Scale. China Behav Med Sci. 2001;10:41–3.
Xiang F-M, Zhang D-Y, Zhou J, Hu X-L. Understanding the mediating effect of social support between emotional stability and career flexibility of junior nurses. Nurs Rehabil. 2021;5:7–11.
Pisanti R, Lombardo C, Lucidi F, Lazzari D, Bertini M. Development and validation of a brief occupational coping self-efficacy questionnaire for nurses. J Adv Nurs. 2008;2:238–47.
Zhai Y-X, Chai X-Y, Liu K, Meng L-D. Study on the sinicization, reliability and validity of nurses’ professional coping self-efficacy scale. Mod Prev Med. 2021;3:423–26.
Zhang Y-T, Liu R-Y, Jiao X-P. The correlation between caring ability, job burnout and nursing lack of nurses in oncology department. Nurs Res. 2021;11:4–7.
Li L, Zhou J, Yao Y, Wang J, Liu C. Factors associated with implicit absence among nurses in China: a cross-sectional survey. BMC Nurs. 2021;1:1–9.
Al Aameri RF, AlShammari H, AlHosaini R, AlShareef NA, AlZamil F, AlHamdan A, AlShammari A. Prevalence and factors associated with implicit absence among nurses in Saudi Arabia. J Nurs Manage. 2020;7:1696–702.
Moscato SR, Miller JA, Logsdon TR, Weinert CR, Chlan LL. Nurse perceptions and missed nursing care in the intensive care unit. Am J Crit Care. 2020;3:188–97.
Heinen MM, van Achterberg T, Schwendimann R, Zander B, Matthews A, Kózka M. Nurses’ early exit Study Group. Nurses’ intention to leave their profession: a cross sectional observational study in 10 European countries. BMJ Open. 2013;2:e002148.
Liang X-Z, Sun Y-B, You W, Yang S-N, Wang M-X, Hao F-F, Liu W-J. Correlation between ICU nurses’ job burnout and implicit absenteeism. Chin Nurs Manage. 2017;7:933–7.
Sun X-M, Bao J, Xu J, Liu F-Y, Zhu L-H, Shen Y-L. Correlation between psychological capital and implicit absenteeism of ICU nurses. J Nurs. 2019;7:70–3.
Hu Y-L, Zhang Y-Q. The influence of work pressure, psychological resilience and perceived social support on empathic fatigue of nurses in assisted reproduction department. J Shanghai Jiaotong Univ (Medical Edition). 2021;12:1565–71.
Li Y, Meng X-B, Zhu G-F. The influence of empowerment psychological model on ICU nurses’ job burnout and coping style. China J Health Psycho. 2022;12:1817–21.
Zhang Y, Wang W, Wang J. Perceived social support and job satisfaction among intensive care unit nurses in China: a cross-sectional study. Int J Nurs Sci. 2021;1:107–11.
Li X, Cao L, Zhang J. The impact of perceived social support on burnout among ICU nurses: a cross-sectional study. BMC Nurs. 2020;1:1–7.
Oosterholt R, Van Der Ark A, Schreurs K. Social support, job demands, and job resources as predictors of turnover intention and emotional exhaustion among ICU nurses. J Nurs Manage. 2018;7:824–32.
Gagné M, Moisan J, Lavigne GL. Perceived social support, job satisfaction, and emotional exhaustion among intensive care unit nurses: a cross-sectional study. Intens Crit Care Nur. 2019;50:21–7.
Wu P, Liang Y-M, Bai H, Ma S-Y. The mediating role of work values in nurses’ understanding of the impact of social support on work performance. Chin Nurs Educ. 2020;8:739–42.
Wang L-J, Liu Y-L. Study on the relationship between self-sympathy and social support of junior ICU nurses. China Contin Med Educ. 2018;3:34–6.
Duan Jiejing D, Shaobo Z, Qiongrui Z, Xiaojuan. Meng Xiaojing, Mei Jie. Status and correlation analysis of professional identity and job burnout of nurses in health management disciplines in Henan Province. Chin J Health Manage. 2023;11:842–47.
Dai W, Ye H-F, Xu X-R, Liu Q-Y. The mediating role of emotional intelligence and professional coping self-efficacy between transition shock and feedback seeking behavior of new nurses. Military Nurs. 2023;2:42–5.
Zhang Y, Liu W, Liu H, Zhang Y. The mediating role of burnout in the relationship between occupational coping self-efficacy and quality of life among intensive care unit nurses. J Adv Nurs. 2021;1:341–50.
Yang X, Wang C, Liu J, Zhang J. The mediating role of burnout in the relationship between occupational coping self-efficacy and job satisfaction among intensive care unit nurses. J Nurs Manage. 2021;2:192–9.
Wang L, Wu J, Wang C, Liu Y. Occupational coping self-efficacy and its relationship with job satisfaction and burnout among nurses in intensive care units. J Nurs Manage. 2020;2:360–7.
Alharthy A, Alqahtani M, Alshamrani H. Occupational Coping Self-Efficacy and its relationship with burnout among Intensive Care Unit nurses in Saudi Arabia. Nurs Rep. 2020;3:102–10.
Xu J-J, Zhang C, Ma T-Y, Lan J, Zhang X. Analysis of the mediating effect of work resources between ICU nurses’ self-efficacy and job remodeling behavior. Chin J Mod Nurs. 2023;15:2011–16.
Liu X-Q. Study on the correlation between job stressors and self-efficacy, resilience and job burnout of nurses in operating room. J Clin Nurs. 2023;5:59–62.
Feng Z-W, Wang Y-H, Jing W, Zhang X, Li Q-Q. The mediating effect of psychological capital of oncology nurses between self-efficacy and innovation ability. Evidence-based Nurs. 2023;18:3367–70.
Li J, Zhan X. The relationship between teaching quality and job satisfaction of middle school teachers: the mediating role of self-efficacy-an empirical analysis based on TALIS2018. J High Contin Educ. 2023;6:50–7.
Wang Y-Q, Ma W-T. The influence of pilot’s driving skills, flying style and self-efficacy on safety performance. China Saf Prod Sci Technol. 2023;11:180–7.
Liu Z-F, Chen C, Yan X-T, Wu J-J, Long L. Understanding the chain intermediary role of social support and career coping self-efficacy between transformational leadership and recessive absenteeism of nurses. Guangxi Med. 2023;17:2157–62.
Ren W, Chen L, Liu S, Zhao Z-M, Cai W-Z. Investigation and analysis on the current situation and influencing factors of pediatric nurses. J Nurs Sci. 2019;20:64–7.
Gu T-P, Wang R, Gong J-W, Jing X. The mediating role of organizational support between nurses’ personality advantage and professional happiness. Chin Nurs Manage. 2022;12:1872–6.
Zhou Y, Guo X, Yin H. A structural equation model of the relationship among occupational stress, coping styles, and mental health of pediatric nurses in China: a cross-sectional study. BMC Psychiatry. 2022;1:416.
Wu L-F, Chen C-K, Chen T-Y, Chen L-C, Kuo H-P. The effect of perceived social support on burnout among ICU nurses in Taiwan. J Nurs Manage. 2019;5:928–34.
Wang Y, Zhang L, Li X, Li Y. The mediating role of occupational self-efficacy in the relationship between social support and burnout among intensive care nurses. J Adv Nurs. 2020;12:3283–93.
Zhang L, Jiang H, Li Y, Wei Q, Li X. The relationship between occupational coping self-efficacy and burnout among intensive care unit nurses in China: a cross-sectional study. Int J Nurs Pract. 2020;6:e12870.
He Q, Wang J, Guo Y, Li J. Study on the influence of nursing working environment and occupational delayed gratification on nurses’ innovative behavior. J Nur Adm. 2023;9:711–6.
Download references
Acknowledgements
We strongly acknowledged the 517 ICU nurses who participated in the study.
This work was supported by Popularization and application project of Sichuan Provincial Health and Wellness Committee (Grant Number 19PJ042) and Sichuan Hospital Management and Development Research Center Project (Grant Number SCYG2019-33).
Author information
Qin Lin and Mengxue Fu contributed equally to this work.
Authors and Affiliations
Shulan International Medical College, Zhejiang Shuren University, Hangzhou, 310000, China
Qin Lin, Pei Chen, Ling Li & Yanping Niu
Department of Rehabilitation, People’s Hospital of Jianyang, Jianyang, 641400, China
Intensive Care Unit, West China Hospital, Sichuan University, Chengdu, 610044, China
Department of Scientific Research, Sichuan Nursing Vocational College, Chengdu, 610100, China
Linfeng Liu
Department of Cardiology, People’s Hospital of Deyang, Deyang, 618099, China
You can also search for this author in PubMed Google Scholar
Contributions
Q L, MX F, K S and L L designed and conducted research, Q L, MX F, LF L and P C contributed equally to the research analysis and interpretation of the data and drafting. K S, YP N and JJ W contributed to distribute and withdrew the questionnaires. P C, YP N and L L contributed to provide guidance from the perspective of statistics. JJ W supervised the project and contributed to conception of the research and critical revision of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Correspondence to Jijun Wu .
Ethics declarations
Ethics approval and consent to participate.
This study was approved by the Ethics Committee of People’s Hospital of Deyang (2021-04-056-K01). All methods were carried out in accordance with the Declaration of Helsinki. Informed consent was obtained from all participants.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Material 1
Rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Lin, Q., Fu, M., Sun, K. et al. The mediating role of perceived social support on the relationship between lack of occupational coping self-efficacy and implicit absenteeism among intensive care unit nurses: a multicenter cross‑sectional study. BMC Health Serv Res 24 , 653 (2024). https://doi.org/10.1186/s12913-024-11084-y
Download citation
Received : 15 September 2023
Accepted : 07 May 2024
Published : 21 May 2024
DOI : https://doi.org/10.1186/s12913-024-11084-y
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Perceived social support
- Lack of occupational coping self-efficacy
- Implicit absenteeism
- Intensive care unit
BMC Health Services Research
ISSN: 1472-6963
- General enquiries: [email protected]
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 13 May 2024
Long-term weight loss effects of semaglutide in obesity without diabetes in the SELECT trial
- Donna H. Ryan 1 ,
- Ildiko Lingvay ORCID: orcid.org/0000-0001-7006-7401 2 ,
- John Deanfield 3 ,
- Steven E. Kahn 4 ,
- Eric Barros ORCID: orcid.org/0000-0001-6613-4181 5 ,
- Bartolome Burguera 6 ,
- Helen M. Colhoun ORCID: orcid.org/0000-0002-8345-3288 7 ,
- Cintia Cercato ORCID: orcid.org/0000-0002-6181-4951 8 ,
- Dror Dicker 9 ,
- Deborah B. Horn 10 ,
- G. Kees Hovingh 5 ,
- Ole Kleist Jeppesen 5 ,
- Alexander Kokkinos 11 ,
- A. Michael Lincoff ORCID: orcid.org/0000-0001-8175-2121 12 ,
- Sebastian M. Meyhöfer 13 ,
- Tugce Kalayci Oral 5 ,
- Jorge Plutzky ORCID: orcid.org/0000-0002-7194-9876 14 ,
- André P. van Beek ORCID: orcid.org/0000-0002-0335-8177 15 ,
- John P. H. Wilding ORCID: orcid.org/0000-0003-2839-8404 16 &
- Robert F. Kushner 17
Nature Medicine ( 2024 ) Cite this article
41k Accesses
3 Citations
2411 Altmetric
Metrics details
- Health care
- Medical research
In the SELECT cardiovascular outcomes trial, semaglutide showed a 20% reduction in major adverse cardiovascular events in 17,604 adults with preexisting cardiovascular disease, overweight or obesity, without diabetes. Here in this prespecified analysis, we examined effects of semaglutide on weight and anthropometric outcomes, safety and tolerability by baseline body mass index (BMI). In patients treated with semaglutide, weight loss continued over 65 weeks and was sustained for up to 4 years. At 208 weeks, semaglutide was associated with mean reduction in weight (−10.2%), waist circumference (−7.7 cm) and waist-to-height ratio (−6.9%) versus placebo (−1.5%, −1.3 cm and −1.0%, respectively; P < 0.0001 for all comparisons versus placebo). Clinically meaningful weight loss occurred in both sexes and all races, body sizes and regions. Semaglutide was associated with fewer serious adverse events. For each BMI category (<30, 30 to <35, 35 to <40 and ≥40 kg m − 2 ) there were lower rates (events per 100 years of observation) of serious adverse events with semaglutide (43.23, 43.54, 51.07 and 47.06 for semaglutide and 50.48, 49.66, 52.73 and 60.85 for placebo). Semaglutide was associated with increased rates of trial product discontinuation. Discontinuations increased as BMI class decreased. In SELECT, at 208 weeks, semaglutide produced clinically significant weight loss and improvements in anthropometric measurements versus placebo. Weight loss was sustained over 4 years. ClinicalTrials.gov identifier: NCT03574597 .
Similar content being viewed by others

Effects of a personalized nutrition program on cardiometabolic health: a randomized controlled trial

Two-year effects of semaglutide in adults with overweight or obesity: the STEP 5 trial

What is the pipeline for future medications for obesity?
The worldwide obesity prevalence, defined by body mass index (BMI) ≥30 kg m − 2 , has nearly tripled since 1975 (ref. 1 ). BMI is a good surveillance measure for population changes over time, given its strong correlation with body fat amount on a population level, but it may not accurately indicate the amount or location of body fat at the individual level 2 . In fact, the World Health Organization defines clinical obesity as ‘abnormal or excessive fat accumulation that may impair health’ 1 . Excess abnormal body fat, especially visceral adiposity and ectopic fat, is a driver of cardiovascular (CV) disease (CVD) 3 , 4 , 5 , and contributes to the global chronic disease burden of diabetes, chronic kidney disease, cancer and other chronic conditions 6 , 7 .
Remediating the adverse health effects of excess abnormal body fat through weight loss is a priority in addressing the global chronic disease burden. Improvements in CV risk factors, glycemia and quality-of-life measures including personal well-being and physical functioning generally begin with modest weight loss of 5%, whereas greater weight loss is associated with more improvement in these measures 8 , 9 , 10 . Producing and sustaining durable and clinically significant weight loss with lifestyle intervention alone has been challenging 11 . However, weight-management medications that modify appetite can make attaining and sustaining clinically meaningful weight loss of ≥10% more likely 12 . Recently, weight-management medications, particularly those comprising glucagon-like peptide-1 receptor agonists, that help people achieve greater and more sustainable weight loss have been developed 13 . Once-weekly subcutaneous semaglutide 2.4 mg, a glucagon-like peptide-1 receptor agonist, is approved for chronic weight management 14 , 15 , 16 and at doses of up to 2.0 mg is approved for type 2 diabetes treatment 17 , 18 , 19 . In patients with type 2 diabetes and high CV risk, semaglutide at doses of 0.5 mg and 1.0 mg has been shown to significantly lower the risk of CV events 20 . The SELECT trial (Semaglutide Effects on Heart Disease and Stroke in Patients with Overweight or Obesity) studied patients with established CVD and overweight or obesity but without diabetes. In SELECT, semaglutide was associated with a 20% reduction in major adverse CV events (hazard ratio 0.80, 95% confidence interval (CI) 0.72 to 0.90; P < 0.001) 21 . Data derived from the SELECT trial offer the opportunity to evaluate the weight loss efficacy, in a geographically and racially diverse population, of semaglutide compared with placebo over 208 weeks when both are given in addition to standard-of-care recommendations for secondary CVD prevention (but without a focus on targeting weight loss). Furthermore, the data allow examination of changes in anthropometric measures such as BMI, waist circumference (WC) and waist-to-height ratio (WHtR) as surrogates for body fat amount and location 22 , 23 . The diverse population can also be evaluated for changes in sex- and race-specific ‘cutoff points’ for BMI and WC, which have been identified as anthropometric measures that predict cardiometabolic risk 8 , 22 , 23 .
This prespecified analysis of the SELECT trial investigated weight loss and changes in anthropometric indices in patients with established CVD and overweight or obesity without diabetes, who met inclusion and exclusion criteria, within a range of baseline categories for glycemia, renal function and body anthropometric measures.
Study population
The SELECT study enrolled 17,604 patients (72.3% male) from 41 countries between October 2018 and March 2021, with a mean (s.d.) age of 61.6 (8.9) years and BMI of 33.3 (5.0) kg m − 2 (ref. 21 ). The baseline characteristics of the population have been reported 24 . Supplementary Table 1 outlines SELECT patients according to baseline BMI categories. Of note, in the lower BMI categories (<30 kg m − 2 (overweight) and 30 to <35 kg m − 2 (class I obesity)), the proportion of Asian individuals was higher (14.5% and 7.4%, respectively) compared with the proportion of Asian individuals in the higher BMI categories (BMI 35 to <40 kg m − 2 (class II obesity; 3.8%) and ≥40 kg m − 2 (class III obesity; 2.2%), respectively). As the BMI categories increased, the proportion of women was higher: in the class III BMI category, 45.5% were female, compared with 20.8%, 25.7% and 33.0% in the overweight, class I and class II categories, respectively. Lower BMI categories were associated with a higher proportion of patients with normoglycemia and glycated hemoglobin <5.7%. Although the proportions of patients with high cholesterol and history of smoking were similar across BMI categories, the proportion of patients with high-sensitivity C-reactive protein ≥2.0 mg dl −1 increased as the BMI category increased. A high-sensitivity C-reactive protein >2.0 mg dl −1 was present in 36.4% of patients in the overweight BMI category, with a progressive increase to 43.3%, 57.3% and 72.0% for patients in the class I, II and III obesity categories, respectively.
Weight and anthropometric outcomes
Percentage weight loss.
The average percentage weight-loss trajectories with semaglutide and placebo over 4 years of observation are shown in Fig. 1a (ref. 21 ). For those in the semaglutide group, the weight-loss trajectory continued to week 65 and then was sustained for the study period through week 208 (−10.2% for the semaglutide group, −1.5% for the placebo group; treatment difference −8.7%; 95% CI −9.42 to −7.88; P < 0.0001). To estimate the treatment effect while on medication, we performed a first on-treatment analysis (observation period until the first time being off treatment for >35 days). At week 208, mean weight loss in the semaglutide group analyzed as first on-treatment was −11.7% compared with −1.5% for the placebo group (Fig. 1b ; treatment difference −10.2%; 95% CI −11.0 to −9.42; P < 0.0001).

a , b , Observed data from the in-trial period ( a ) and first on-treatment ( b ). The symbols are the observed means, and error bars are ±s.e.m. Numbers shown below each panel represent the number of patients contributing to the means. Analysis of covariance with treatment and baseline values was used to estimate the treatment difference. Exact P values are 1.323762 × 10 −94 and 9.80035 × 10 −100 for a and b , respectively. P values are two-sided and are not adjusted for multiplicity. ETD, estimated treatment difference; sema, semaglutide.
Categorical weight loss and individual body weight change
Among in-trial (intention-to-treat principle) patients at week 104, weight loss of ≥5%, ≥10%, ≥15%, ≥20% and ≥25% was achieved by 67.8%, 44.2%, 22.9%, 11.0% and 4.9%, respectively, of those treated with semaglutide compared with 21.3%, 6.9%, 1.7%, 0.6% and 0.1% of those receiving placebo (Fig. 2a ). Individual weight changes at 104 weeks for the in-trial populations for semaglutide and placebo are depicted in Fig. 2b and Fig. 2c , respectively. These waterfall plots show the variation in weight-loss response that occurs with semaglutide and placebo and show that weight loss is more prominent with semaglutide than placebo.

a , Categorical weight loss from baseline at week 104 for semaglutide and placebo. Data from the in-trial period. Bars depict the proportion (%) of patients receiving semaglutide or placebo who achieved ≥5%, ≥10%, ≥15%, ≥20% and ≥25% weight loss. b , c , Percentage change in body weight for individual patients from baseline to week 104 for semaglutide ( b ) and placebo ( c ). Each patient’s percentage change in body weight is plotted as a single bar.
Change in WC
WC change from baseline to 104 weeks has been reported previously in the primary outcome paper 21 . The trajectory of WC change mirrored that of the change in body weight. At week 208, average reduction in WC was −7.7 cm with semaglutide versus −1.3 cm with placebo, with a treatment difference of −6.4 cm (95% CI −7.18 to −5.61; P < 0.0001) 21 .
WC cutoff points
We analyzed achievement of sex- and race-specific cutoff points for WC by BMI <35 kg m − 2 or ≥35 kg m − 2 , because for BMI >35 kg m − 2 , WC is more difficult technically and, thus, less accurate as a risk predictor 4 , 25 , 26 . Within the SELECT population with BMI <35 kg m − 2 at baseline, 15.0% and 14.3% of the semaglutide and placebo groups, respectively, were below the sex- and race-specific WC cutoff points. At week 104, 41.2% fell below the sex- and race-specific cutoff points for the semaglutide group, compared with only 18.0% for the placebo group (Fig. 3 ).

WC cutoff points; Asian women <80 cm, non-Asian women <88 cm, Asian men <88 cm, non-Asian men <102 cm.
Waist-to-height ratio
At baseline, mean WHtR was 0.66 for the study population. The lowest tertile of the SELECT population at baseline had a mean WHtR <0.62, which is higher than the cutoff point of 0.5 used to indicate increased cardiometabolic risk 27 , suggesting that the trial population had high WCs. At week 208, in the group randomized to semaglutide, there was a relative reduction of 6.9% in WHtR compared with 1.0% in placebo (treatment difference −5.87% points; 95% CI −6.56 to −5.17; P < 0.0001).
BMI category change
At week 104, 52.4% of patients treated with semaglutide achieved improvement in BMI category compared with 15.7% of those receiving placebo. Proportions of patients in the BMI categories at baseline and week 104 are shown in Fig. 4 , which depicts in-trial patients receiving semaglutide and placebo. The BMI category change reflects the superior weight loss with semaglutide, which resulted in fewer patients being in the higher BMI categories after 104 weeks. In the semaglutide group, 12.0% of patients achieved a BMI <25 kg m − 2 , which is considered the healthy BMI category, compared with 1.2% for placebo; per study inclusion criteria, no patients were in this category at baseline. The proportion of patients with obesity (BMI ≥30 kg m − 2 ) fell from 71.0% to 43.3% in the semaglutide group versus 71.9% to 67.9% in the placebo group.

In the semaglutide group, 12.0% of patients achieved normal weight status at week 104 (from 0% at baseline), compared with 1.2% (from 0% at baseline) for placebo. BMI classes: healthy (BMI <25 kg m − 2 ), overweight (25 to <30 kg m − 2 ), class I obesity (30 to <35 kg m − 2 ), class II obesity (35 to <40 kg m − 2 ) and class III obesity (BMI ≥40 kg m − 2 ).
Weight and anthropometric outcomes by subgroups
The forest plot illustrated in Fig. 5 displays mean body weight percentage change from baseline to week 104 for semaglutide relative to placebo in prespecified subgroups. Similar relationships are depicted for WC changes in prespecified subgroups shown in Extended Data Fig. 1 . The effect of semaglutide (versus placebo) on mean percentage body weight loss as well as reduction in WC was found to be heterogeneous across several population subgroups. Women had a greater difference in mean weight loss with semaglutide versus placebo (−11.1% (95% CI −11.56 to −10.66) versus −7.5% in men (95% CI −7.78 to −7.23); P < 0.0001). There was a linear relationship between age category and degree of mean weight loss, with younger age being associated with progressively greater mean weight loss, but the actual mean difference by age group is small. Similarly, BMI category had small, although statistically significant, associations. Those with WHtR less than the median experienced slightly lower mean body weight change than those above the median, with estimated treatment differences −8.04% (95% CI −8.37 to −7.70) and −8.99% (95% CI −9.33 to −8.65), respectively ( P < 0.0001). Patients from Asia and of Asian race experienced slightly lower mean weight loss (estimated treatment difference with semaglutide for Asian race −7.27% (95% CI −8.09 to −6.46; P = 0.0147) and for Asia −7.30 (95% CI −7.97 to −6.62; P = 0.0016)). There was no difference in weight loss with semaglutide associated with ethnicity (estimated treatment difference for Hispanic −8.53% (95% CI −9.28 to −7.76) or non-Hispanic −8.52% (95% CI −8.77 to 8.26); P = 0.9769), glycemic status (estimated treatment difference for prediabetes −8.53% (95% CI −8.83 to −8.24) or normoglycemia −8.48% (95% CI −8.88 to −8.07; P = 0.8188) or renal function (estimated treatment difference for estimated glomerular filtration rate (eGFR) <60 or ≥60 ml min −1 1.73 m − 2 being −8.50% (95% CI −9.23 to −7.76) and −8.52% (95% CI −8.77 to −8.26), respectively ( P = 0.9519)).

Data from the in-trial period. N = 17,604. P values represent test of no interaction effect. P values are two-sided and are not adjusted for multiplicity. The dots show estimated treatment differences, and the error bars show 95% CIs. Details of the statistical models are available in Methods . ETD, estimated treatment difference; HbA1c, glycated hemoglobin; MI, myocardial infarction; PAD, peripheral artery disease; sema, semaglutide.
Safety and tolerability according to baseline BMI category
We reported in the primary outcome of the SELECT trial that adverse events (AEs) leading to permanent discontinuation of the trial product occurred in 1,461 patients (16.6%) in the semaglutide group and 718 patients (8.2%) in the placebo group ( P < 0.001) 21 . For this analysis, we evaluated the cumulative incidence of AEs leading to trial product discontinuation by treatment assignment and by BMI category (Fig. 6 ). For this analysis, with death modeled as a competing risk, we tracked the proportion of in-trial patients for whom drug was withdrawn or interrupted for the first time (Fig. 6 , left) or cumulative discontinuations (Fig. 6 , right). Both panels of Fig. 6 depict a graded increase in the proportion discontinuing semaglutide, but not placebo. For lower BMI classes, discontinuation rates are higher in the semaglutide group but not the placebo group.

Data are in-trial from the full analysis set. sema, semaglutide.
We reported in the primary SELECT analysis that serious adverse events (SAEs) were reported by 2,941 patients (33.4%) in the semaglutide arm and by 3,204 patients (36.4%) in the placebo arm ( P < 0.001) 21 . For this study, we analyzed SAE rates by person-years of treatment exposure for BMI classes (<30 kg m − 2 , 30 to <35 kg m − 2 , 35 to <40 kg m − 2 , and ≥40 kg m − 2 ) and provide these data in Supplementary Table 2 . We also provide an analysis of the most common categories of SAEs. Semaglutide was associated with lower SAEs, primarily driven by CV event and infections. Within each obesity class (<30 kg m − 2 , 30 to <35 kg m − 2 , 35 to <40 kg m − 2 , and ≥40 kg m − 2 ), there were fewer SAEs in the group receiving semaglutide compared with placebo. Rates (events per 100 years of observation) of SAEs were 43.23, 43.54, 51.07 and 47.06 for semaglutide and 50.48, 49.66, 52.73 and 60.85 for placebo, with no evidence of heterogeneity. There was no detectable difference in hepatobiliary or gastrointestinal SAEs comparing semaglutide with placebo in any of the four BMI classes we evaluated.
The analyses of weight effects of the SELECT study presented here reveal that patients assigned to once-weekly subcutaneous semaglutide 2.4 mg lost significantly more weight than those receiving placebo. The weight-loss trajectory with semaglutide occurred over 65 weeks and was sustained up to 4 years. Likewise, there were similar improvements in the semaglutide group for anthropometrics (WC and WHtR). The weight loss was associated with a greater proportion of patients receiving semaglutide achieving improvement in BMI category, healthy BMI (<25 kg m − 2 ) and falling below the WC cutoff point above which increased cardiometabolic risk for the sex and race is greater 22 , 23 . Furthermore, both sexes, all races, all body sizes and those from all geographic regions were able to achieve clinically meaningful weight loss. There was no evidence of increased SAEs based on BMI categories, although lower BMI category was associated with increased rates of trial product discontinuation, probably reflecting exposure to a higher level of drug in lower BMI categories. These data, representing the longest clinical trial of the effects of semaglutide versus placebo on weight, establish the safety and durability of semaglutide effects on weight loss and maintenance in a geographically and racially diverse population of adult men and women with overweight and obesity but not diabetes. The implications of weight loss of this degree in such a diverse population suggests that it may be possible to impact the public health burden of the multiple morbidities associated with obesity. Although our trial focused on CV events, many chronic diseases would benefit from effective weight management 28 .
There were variations in the weight-loss response. Individual changes in body weight with semaglutide and placebo were striking; still, 67.8% achieved 5% or more weight loss and 44.2% achieved 10% weight loss with semaglutide at 2 years, compared with 21.3% and 6.9%, respectively, for those receiving placebo. Our first on-treatment analysis demonstrated that those on-drug lost more weight than those in-trial, confirming the effect of drug exposure. With semaglutide, lower BMI was associated with less percentage weight loss, and women lost more weight on average than men (−11.1% versus −7.5% treatment difference from placebo); however, in all cases, clinically meaningful mean weight loss was achieved. Although Asian patients lost less weight on average than patients of other races (−7.3% more than placebo), Asian patients were more likely to be in the lowest BMI category (<30 kg m − 2 ), which is known to be associated with less weight loss, as discussed below. Clinically meaningful weight loss was evident in the semaglutide group within a broad range of baseline categories for glycemia and body anthropometrics. Interestingly, at 2 years, a significant proportion of the semaglutide-treated group fell below the sex- and race-specific WC cutoff points, especially in those with BMI <35 kg m − 2 , and a notable proportion (12.0%) fell below the BMI cutoff point of 25 kg m − 2 , which is deemed a healthy BMI in those without unintentional weight loss. As more robust weight loss is possible with newer medications, achieving and maintaining these cutoff point targets may become important benchmarks for tracking responses.
The overall safety profile did not reveal any new signals from prior studies, and there were no BMI category-related associations with AE reporting. The analysis did reveal that tolerability may differ among specific BMI classes, since more discontinuations occurred with semaglutide among lower BMI classes. Potential contributors may include a possibility of higher drug exposure in lower BMI classes, although other explanations, including differences in motivation and cultural mores regarding body size, cannot be excluded.
Is the weight loss in SELECT less than expected based on prior studies with the drug? In STEP 1, a large phase 3 study of once-weekly subcutaneous semaglutide 2.4 mg in individuals without diabetes but with BMI >30 kg m − 2 or 27 kg m − 2 with at least one obesity-related comorbidity, the mean weight loss was −14.9% at week 68, compared with −2.4% with placebo 14 . Several reasons may explain the observation that the mean treatment difference was −12.5% in STEP 1 and −8.7% in SELECT. First, SELECT was designed as a CV outcomes trial and not a weight-loss trial, and weight loss was only a supportive secondary endpoint in the trial design. Patients in STEP 1 were desirous of weight loss as a reason for study participation and received structured lifestyle intervention (which included a −500 kcal per day diet with 150 min per week of physical activity). In the SELECT trial, patients did not enroll for the specific purpose of weight loss and received standard of care covering management of CV risk factors, including medical treatment and healthy lifestyle counseling, but without a specific focus on weight loss. Second, the respective study populations were quite different, with STEP 1 including a younger, healthier population with more women (73.1% of the semaglutide arm in STEP 1 versus 27.7% in SELECT) and higher mean BMI (37.8 kg m − 2 versus 33.3 kg m − 2 , respectively) 14 , 21 . Third, major differences existed between the respective trial protocols. Patients in the semaglutide treatment arm of STEP 1 were more likely to be exposed to the medication at the full dose of 2.4 mg than those in SELECT. In SELECT, investigators were allowed to slow, decrease or pause treatment. By 104 weeks, approximately 77% of SELECT patients on dose were receiving the target semaglutide 2.4 mg weekly dose, which is lower than the corresponding proportion of patients in STEP 1 (89.6% were receiving the target dose at week 68) 14 , 21 . Indeed, in our first on-treatment analysis at week 208, weight loss was greater (−11.7% for semaglutide) compared with the in-trial analysis (−10.2% for semaglutide). Taken together, all these issues make less weight loss an expected finding in SELECT, compared with STEP 1.
The SELECT study has some limitations. First, SELECT was not a primary prevention trial, and the data should not be extrapolated to all individuals with overweight and obesity to prevent major adverse CV events. Although the data set is rich in numbers and diversity, it does not have the numbers of individuals in racial subgroups that may have revealed potential differential effects. SELECT also did not include individuals who have excess abnormal body fat but a BMI <27 kg m − 2 . Not all individuals with increased CV risk have BMI ≥27 kg m − 2 . Thus, the study did not include Asian patients who qualify for treatment with obesity medications at lower BMI and WC cutoff points according to guidelines in their countries 29 . We observed that Asian patients were less likely to be in the higher BMI categories of SELECT and that the population of those with BMI <30 kg m − 2 had a higher percentage of Asian race. Asian individuals would probably benefit from weight loss and medication approaches undertaken at lower BMI levels in the secondary prevention of CVD. Future studies should evaluate CV risk reduction in Asian individuals with high CV risk and BMI <27 kg m − 2 . Another limitation is the lack of information on body composition, beyond the anthropometric measures we used. It would be meaningful to have quantitation of fat mass, lean mass and muscle mass, especially given the wide range of body size in the SELECT population.
An interesting observation from this SELECT weight loss data is that when BMI is ≤30 kg m − 2 , weight loss on a percentage basis is less than that observed across higher classes of BMI severity. Furthermore, as BMI exceeds 30 kg m − 2 , weight loss amounts are more similar for class I, II and III obesity. This was also observed in Look AHEAD, a lifestyle intervention study for weight loss 30 . The proportion (percentage) of weight loss seems to be less, on average, in the BMI <30 kg m − 2 category relative to higher BMI categories, despite their receiving of the same treatment and even potentially higher exposure to the drug for weight loss 30 . Weight loss cannot continue indefinitely. There is a plateau of weight that occurs after weight loss with all treatments for weight management. This plateau has been termed the ‘set point’ or ‘settling point’, a body weight that is in harmony with the genetic and environmental determinants of body weight and adiposity 31 . Perhaps persons with BMI <30 kg m − 2 are closer to their settling point and have less weight to lose to reach it. Furthermore, the cardiometabolic benefits of weight loss are driven by reduction in the abnormal ectopic and visceral depots of fat, not by reduction of subcutaneous fat stores in the hips and thighs. The phenotype of cardiometabolic disease but lower BMI (<30 kg m − 2 ) may be one where reduction of excess abnormal and dysfunctional body fat does not require as much body mass reduction to achieve health improvement. We suspect this may be the case and suggest further studies to explore this aspect of weight-loss physiology.
In conclusion, this analysis of the SELECT study supports the broad use of once-weekly subcutaneous semaglutide 2.4 mg as an aid to CV event reduction in individuals with overweight or obesity without diabetes but with preexisting CVD. Semaglutide 2.4 mg safely and effectively produced clinically significant weight loss in all subgroups based on age, sex, race, glycemia, renal function and anthropometric categories. Furthermore, the weight loss was sustained over 4 years during the trial.
Trial design and participants
The current work complies with all relevant ethical regulations and reports a prespecified analysis of the randomized, double-blind, placebo-controlled SELECT trial ( NCT03574597 ), details of which have been reported in papers describing study design and rationale 32 , baseline characteristics 24 and the primary outcome 21 . SELECT evaluated once-weekly subcutaneous semaglutide 2.4 mg versus placebo to reduce the risk of major adverse cardiac events (a composite endpoint comprising CV death, nonfatal myocardial infarction or nonfatal stroke) in individuals with established CVD and overweight or obesity, without diabetes. The protocol for SELECT was approved by national and institutional regulatory and ethical authorities in each participating country. All patients provided written informed consent before beginning any trial-specific activity. Eligible patients were aged ≥45 years, with a BMI of ≥27 kg m − 2 and established CVD defined as at least one of the following: prior myocardial infarction, prior ischemic or hemorrhagic stroke, or symptomatic peripheral artery disease. Additional inclusion and exclusion criteria can be found elsewhere 32 .
Human participants research
The trial protocol was designed by the trial sponsor, Novo Nordisk, and the academic Steering Committee. A global expert panel of physician leaders in participating countries advised on regional operational issues. National and institutional regulatory and ethical authorities approved the protocol, and all patients provided written informed consent.
Study intervention and patient management
Patients were randomly assigned in a double-blind manner and 1:1 ratio to receive once-weekly subcutaneous semaglutide 2.4 mg or placebo. The starting dose was 0.24 mg once weekly, with dose increases every 4 weeks (to doses of 0.5, 1.0, 1.7 and 2.4 mg per week) until the target dose of 2.4 mg was reached after 16 weeks. Patients who were unable to tolerate dose escalation due to AEs could be managed by extension of dose-escalation intervals, treatment pauses or maintenance at doses below the 2.4 mg per week target dose. Investigators were allowed to reduce the dose of study product if tolerability issues arose. Investigators were provided with guidelines for, and encouraged to follow, evidence-based recommendations for medical treatment and lifestyle counseling to optimize management of underlying CVD as part of the standard of care. The lifestyle counseling was not targeted at weight loss. Additional intervention descriptions are available 32 .
Sex, race, body weight, height and WC measurements
Sex and race were self-reported. Body weight was measured without shoes and only wearing light clothing; it was measured on a digital scale and recorded in kilograms or pounds (one decimal with a precision of 0.1 kg or lb), with preference for using the same scale throughout the trial. The scale was calibrated yearly as a minimum unless the manufacturer certified that calibration of the weight scales was valid for the lifetime of the scale. Height was measured without shoes in centimeters or inches (one decimal with a precision of 0.1 cm or inches). At screening, BMI was calculated by the electronic case report form. WC was defined as the abdominal circumference located midway between the lower rib margin and the iliac crest. Measures were obtained in a standing position with a nonstretchable measuring tape and to the nearest centimeter or inch. The patient was asked to breathe normally. The tape touched the skin but did not compress soft tissue, and twists in the tape were avoided.
The following endpoints relevant to this paper were assessed at randomization (week 0) to years 2, 3 and 4: change in body weight (%); proportion achieving weight loss ≥5%, ≥10%, ≥15% and ≥20%; change in WC (cm); and percentage change in WHtR (cm cm −1 ). Improvement in BMI category (defined as being in a lower BMI class) was assessed at week 104 compared with baseline according to BMI classes: healthy (BMI <25 kg m − 2 ), overweight (25 to <30 kg m − 2 ), class I obesity (30 to <35 kg m − 2 ), class II obesity (35 to <40 kg m − 2 ) and class III obesity (≥40 kg m − 2 ). The proportions of individuals with BMI <35 or ≥35 kg m − 2 who achieved sex- and race-specific cutoff points for WC (indicating increased metabolic risk) were evaluated at week 104. The WC cutoff points were as follows: Asian women <80 cm, non-Asian women <88 cm, Asian men <88 cm and non-Asian men <102 cm.
Overall, 97.1% of the semaglutide group and 96.8% of the placebo group completed the trial. During the study, 30.6% of those assigned to semaglutide did not complete drug treatment, compared with 27.0% for placebo.
Statistical analysis
The statistical analyses for the in-trial period were based on the intention-to-treat principle and included all randomized patients irrespective of adherence to semaglutide or placebo or changes to background medications. Continuous endpoints were analyzed using an analysis of covariance model with treatment as a fixed factor and baseline value of the endpoint as a covariate. Missing data at the landmark visit, for example, week 104, were imputed using a multiple imputation model and done separately for each treatment arm and included baseline value as a covariate and fit to patients having an observed data point (irrespective of adherence to randomized treatment) at week 104. The fit model is used to impute values for all patients with missing data at week 104 to create 500 complete data sets. Rubin’s rules were used to combine the results. Estimated means are provided with s.e.m., and estimated treatment differences are provided with 95% CI. Binary endpoints were analyzed using logistic regression with treatment and baseline value as a covariate, where missing data were imputed by first using multiple imputation as described above and then categorizing the imputed data according to the endpoint, for example, body weight percentage change at week 104 of <0%. Subgroup analyses for continuous and binary endpoints also included the subgroup and interaction between treatment and subgroup as fixed factors. Because some patients in both arms continued to be followed but were off treatment, we also analyzed weight loss by first on-treatment group (observation period until first time being off treatment for >35 days) to assess a more realistic picture of weight loss in those adhering to treatment. CIs were not adjusted for multiplicity and should therefore not be used to infer definitive treatment effects. All statistical analyses were performed with SAS software, version 9.4 TS1M5 (SAS Institute).
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
Data will be shared with bona fide researchers who submit a research proposal approved by the independent review board. Individual patient data will be shared in data sets in a deidentified and anonymized format. Information about data access request proposals can be found at https://www.novonordisk-trials.com/ .
Obesity and overweight. World Health Organization https://www.who.int/news-room/fact-sheets/detail/obesity-and-overweight (2021).
Cornier, M. A. et al. Assessing adiposity: a scientific statement from the American Heart Association. Circulation 124 , 1996–2019 (2011).
Article PubMed Google Scholar
Afshin, A. et al. Health effects of overweight and obesity in 195 countries over 25 years. N. Engl. J. Med. 377 , 13–27 (2017).
Jensen, M. D. et al. 2013 AHA/ACC/TOS guideline for the management of overweight and obesity in adults: a report of the American College of Cardiology/American Heart Association Task Force on Practice Guidelines and The Obesity Society. J. Am. Coll. Cardiol. 63 , 2985–3023 (2014).
Poirier, P. et al. Obesity and cardiovascular disease: pathophysiology, evaluation, and effect of weight loss: an update of the 1997 American Heart Association Scientific Statement on Obesity and Heart Disease from the Obesity Committee of the Council on Nutrition, Physical Activity, and Metabolism. Circulation 113 , 898–918 (2006).
Dai, H. et al. The global burden of disease attributable to high body mass index in 195 countries and territories, 1990–2017: an analysis of the Global Burden of Disease Study. PLoS Med. 17 , e1003198 (2020).
Article PubMed PubMed Central Google Scholar
Ndumele, C. E. et al. Cardiovascular–kidney–metabolic health: a presidential advisory from the American Heart Association. Circulation 148 , 1606–1635 (2023).
Garvey, W. T. et al. American Association of Clinical Endocrinologists and American College of Endocrinology comprehensive clinical practice guidelines for medical care of patients with obesity. Endocr. Pr. 22 , 1–203 (2016).
Article Google Scholar
Ryan, D. H. & Yockey, S. R. Weight loss and improvement in comorbidity: differences at 5%, 10%, 15%, and over. Curr. Obes. Rep. 6 , 187–194 (2017).
Wing, R. R. et al. Benefits of modest weight loss in improving cardiovascular risk factors in overweight and obese individuals with type 2 diabetes. Diabetes Care 34 , 1481–1486 (2011).
Article CAS PubMed PubMed Central Google Scholar
Wadden, T. A., Tronieri, J. S. & Butryn, M. L. Lifestyle modification approaches for the treatment of obesity in adults. Am. Psychol. 75 , 235–251 (2020).
Tchang, B. G. et al. Pharmacologic treatment of overweight and obesity in adults. in (eds. Feingold, K. R. et al.) Endotext https://www.ncbi.nlm.nih.gov/books/NBK279038/ (MDText.com, 2000).
Müller, T. D., Blüher, M., Tschöp, M. H. & DiMarchi, R. D. Anti-obesity drug discovery: advances and challenges. Nat. Rev. Drug Discov. 21 , 201–223 (2022).
Wilding, J. P. H. et al. Once-weekly semaglutide in adults with overweight or obesity. N. Engl. J. Med. 384 , 989–1002 (2021).
Article CAS PubMed Google Scholar
Wegovy (semaglutide) summary of product characteristics. European Medicines Agency https://www.ema.europa.eu/en/documents/product-information/wegovy-epar-product-information_en.pdf (2023).
WEGOVY (semaglutide) prescribing information. Food and Drug Administration https://www.accessdata.fda.gov/drugsatfda_docs/label/2023/215256s007lbl.pdf (2023).
Sorli, C. et al. Efficacy and safety of once-weekly semaglutide monotherapy versus placebo in patients with type 2 diabetes (SUSTAIN 1): a double-blind, randomised, placebo-controlled, parallel-group, multinational, multicentre phase 3a trial. Lancet Diabetes Endocrinol. 5 , 251–260 (2017).
Ozempic (semaglutide) summary of product characteristics. European Medicines Agency https://www.ema.europa.eu/en/documents/product-information/ozempic-epar-product-information_en.pdf (2023).
OZEMPIC (semaglutide) prescribing information. Food and Drug Administration https://www.accessdata.fda.gov/drugsatfda_docs/label/2017/209637lbl.pdf (2017).
Marso, S. P. et al. Semaglutide and cardiovascular outcomes in patients with type 2 diabetes. N. Engl. J. Med. 375 , 1834–1844 (2016).
Lincoff, A. M. et al. Semaglutide and cardiovascular outcomes in obesity without diabetes. N. Engl. J. Med. 389 , 2221–2232 (2023).
Ross, R. et al. Waist circumference as a vital sign in clinical practice: a consensus statement from the IAS and ICCR Working Group on Visceral Obesity. Nat. Rev. Endocrinol. 16 , 177–189 (2020).
Snijder, M. B., van Dam, R. M., Visser, M. & Seidell, J. C. What aspects of body fat are particularly hazardous and how do we measure them? Int. J. Epidemiol. 35 , 83–92 (2006).
Lingvay, I. et al. Semaglutide for cardiovascular event reduction in people with overweight or obesity: SELECT study baseline characteristics. Obesity 31 , 111–122 (2023).
Basset, J. The Asia-Pacific perspective: redefining obesity and its treatment. International Diabetes Institute, World Health Organization Regional Office for the Western Pacific, International Association for the Study of Obesity & International Obesity Task Force https://www.vepachedu.org/TSJ/BMI-Guidelines.pdf (2000).
Hu, F. in Obesity Epidemiology (ed. Hu, F.) 53–83 (Oxford University Press, 2008).
Browning, L. M., Hsieh, S. D. & Ashwell, M. A systematic review of waist-to-height ratio as a screening tool for the prediction of cardiovascular disease and diabetes: 0·5 could be a suitable global boundary value. Nutr. Res. Rev. 23 , 247–269 (2010).
Sattar, N. et al. Treating chronic diseases without tackling excess adiposity promotes multimorbidity. Lancet Diabetes Endocrinol. 11 , 58–62 (2023).
Obesity classification. World Obesity https://www.worldobesity.org/about/about-obesity/obesity-classification (2022).
Unick, J. L. et al. Effectiveness of lifestyle interventions for individuals with severe obesity and type 2 diabetes: results from the Look AHEAD trial. Diabetes Care 34 , 2152–2157 (2011).
Speakman, J. R. et al. Set points, settling points and some alternative models: theoretical options to understand how genes and environments combine to regulate body adiposity. Dis. Model. Mech. 4 , 733–745 (2011).
Ryan, D. H. et al. Semaglutide effects on cardiovascular outcomes in people with overweight or obesity (SELECT) rationale and design. Am. Heart J. 229 , 61–69 (2020).
Download references
Acknowledgements
Editorial support was provided by Richard Ogilvy-Stewart of Apollo, OPEN Health Communications, and funded by Novo Nordisk A/S, in accordance with Good Publication Practice guidelines ( www.ismpp.org/gpp-2022 ).
Author information
Authors and affiliations.
Pennington Biomedical Research Center, Baton Rouge, LA, USA
Donna H. Ryan
Department of Internal Medicine/Endocrinology and Peter O’ Donnell Jr. School of Public Health, University of Texas Southwestern Medical Center, Dallas, TX, USA
Ildiko Lingvay
Institute of Cardiovascular Science, University College London, London, UK
John Deanfield
VA Puget Sound Health Care System and University of Washington, Seattle, WA, USA
Steven E. Kahn
Novo Nordisk A/S, Søborg, Denmark
Eric Barros, G. Kees Hovingh, Ole Kleist Jeppesen & Tugce Kalayci Oral
Endocrinology and Metabolism Institute, Cleveland Clinic, Cleveland, OH, USA
Bartolome Burguera
Institute of Genetics and Cancer, University of Edinburgh, Edinburgh, UK
Helen M. Colhoun
Obesity Unit, Department of Endocrinology, Hospital das Clínicas, University of São Paulo, São Paulo, Brazil
Cintia Cercato
Internal Medicine Department D, Hasharon Hospital-Rabin Medical Center, Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel
Dror Dicker
Center for Obesity Medicine and Metabolic Performance, Department of Surgery, University of Texas McGovern Medical School, Houston, TX, USA
Deborah B. Horn
First Department of Propaedeutic Internal Medicine, School of Medicine, National and Kapodistrian University of Athens, Athens, Greece
Alexander Kokkinos
Department of Cardiovascular Medicine, Cleveland Clinic, and Cleveland Clinic Lerner College of Medicine of Case Western Reserve University, Cleveland, OH, USA
A. Michael Lincoff
Institute of Endocrinology & Diabetes, University of Lübeck, Lübeck, Germany
Sebastian M. Meyhöfer
Cardiovascular Division, Brigham and Women’s Hospital, Harvard Medical School, Boston, MA, USA
Jorge Plutzky
University of Groningen, University Medical Center Groningen, Department of Endocrinology, Groningen, the Netherlands
André P. van Beek
Department of Cardiovascular and Metabolic Medicine, University of Liverpool, Liverpool, UK
John P. H. Wilding
Northwestern University Feinberg School of Medicine, Chicago, IL, USA
Robert F. Kushner
You can also search for this author in PubMed Google Scholar
Contributions
D.H.R., I.L. and S.E.K. contributed to the study design. D.B.H., I.L., D.D., A.K., S.M.M., A.P.v.B., C.C. and J.P.H.W. were study investigators. D.B.H., I.L., D.D., A.K., S.M.M., A.P.v.B., C.C. and J.P.H.W. enrolled patients. D.H.R. was responsible for data analysis and manuscript preparation. All authors contributed to data interpretation, review, revisions and final approval of the manuscript.
Corresponding author
Correspondence to Donna H. Ryan .
Ethics declarations
Competing interests.
D.H.R. declares having received consulting honoraria from Altimmune, Amgen, Biohaven, Boehringer Ingelheim, Calibrate, Carmot Therapeutics, CinRx, Eli Lilly, Epitomee, Gila Therapeutics, IFA Celtics, Novo Nordisk, Pfizer, Rhythm, Scientific Intake, Wondr Health and Zealand Pharma; she declares she received stock options from Calibrate, Epitomee, Scientific Intake and Xeno Bioscience. I.L. declares having received research funding (paid to institution) from Novo Nordisk, Sanofi, Mylan and Boehringer Ingelheim. I.L. received advisory/consulting fees and/or other support from Altimmune, AstraZeneca, Bayer, Biomea, Boehringer Ingelheim, Carmot Therapeutics, Cytoki Pharma, Eli Lilly, Intercept, Janssen/Johnson & Johnson, Mannkind, Mediflix, Merck, Metsera, Novo Nordisk, Pharmaventures, Pfizer, Regeneron, Sanofi, Shionogi, Structure Therapeutics, Target RWE, Terns Pharmaceuticals, The Comm Group, Valeritas, WebMD and Zealand Pharma. J.D. declares having received consulting honoraria from Amgen, Boehringer Ingelheim, Merck, Pfizer, Aegerion, Novartis, Sanofi, Takeda, Novo Nordisk and Bayer, and research grants from British Heart Foundation, MRC (UK), NIHR, PHE, MSD, Pfizer, Aegerion, Colgate and Roche. S.E.K. declares having received consulting honoraria from ANI Pharmaceuticals, Boehringer Ingelheim, Eli Lilly, Merck, Novo Nordisk and Oramed, and stock options from AltPep. B.B. declares having received honoraria related to participation on this trial and has no financial conflicts related to this publication. H.M.C. declares being a stockholder and serving on an advisory panel for Bayer; receiving research grants from Chief Scientist Office, Diabetes UK, European Commission, IQVIA, Juvenile Diabetes Research Foundation and Medical Research Council; serving on an advisory board and speaker’s bureau for Novo Nordisk; and holding stock in Roche Pharmaceuticals. C.C. declares having received consulting honoraria from Novo Nordisk, Eli Lilly, Merck, Brace Pharma and Eurofarma. D.D. declares having received consulting honoraria from Novo Nordisk, Eli Lilly, Boehringer Ingelheim and AstraZeneca, and received research grants through his affiliation from Novo Nordisk, Eli Lilly, Boehringer Ingelheim and Rhythm. D.B.H. declares having received research grants through her academic affiliation from Novo Nordisk and Eli Lilly, and advisory/consulting honoraria from Novo Nordisk, Eli Lilly and Gelesis. A.K. declares having received research grants through his affiliation from Novo Nordisk and Pharmaserve Lilly, and consulting honoraria from Pharmaserve Lilly, Sanofi-Aventis, Novo Nordisk, MSD, AstraZeneca, ELPEN Pharma, Boehringer Ingelheim, Galenica Pharma, Epsilon Health and WinMedica. A.M.L. declares having received honoraria from Novo Nordisk, Eli Lilly, Akebia Therapeutics, Ardelyx, Becton Dickinson, Endologix, FibroGen, GSK, Medtronic, Neovasc, Provention Bio, ReCor, BrainStorm Cell Therapeutics, Alnylam and Intarcia for consulting activities, and research funding to his institution from AbbVie, Esperion, AstraZeneca, CSL Behring, Novartis and Eli Lilly. S.M.M. declares having received consulting honoraria from Amgen, AstraZeneca, Bayer, Boehringer Ingelheim, Daichii-Sankyo, esanum, Gilead, Ipsen, Eli Lilly, Novartis, Novo Nordisk, Sandoz and Sanofi; he declares he received research grants from AstraZeneca, Eli Lilly and Novo Nordisk. J.P. declares having received consulting honoraria from Altimmune, Amgen, Esperion, Merck, MJH Life Sciences, Novartis and Novo Nordisk; he has received a grant, paid to his institution, from Boehringer Ingelheim and holds the position of Director, Preventive Cardiology, at Brigham and Women’s Hospital. A.P.v.B. is contracted via the University of Groningen (no personal payment) to undertake consultancy for Novo Nordisk, Eli Lilly and Boehringer Ingelheim. J.P.H.W. is contracted via the University of Liverpool (no personal payment) to undertake consultancy for Altimmune, AstraZeneca, Boehringer Ingelheim, Cytoki, Eli Lilly, Napp, Novo Nordisk, Menarini, Pfizer, Rhythm Pharmaceuticals, Sanofi, Saniona, Tern Pharmaceuticals, Shionogi and Ysopia. J.P.H.W. also declares personal honoraria/lecture fees from AstraZeneca, Boehringer Ingelheim, Medscape, Napp, Menarini, Novo Nordisk and Rhythm. R.F.K. declares having received consulting honoraria from Novo Nordisk, Weight Watchers, Eli Lilly, Boehringer Ingelheim, Pfizer, Structure and Altimmune. E.B., G.K.H., O.K.J. and T.K.O. are employees of Novo Nordisk A/S.
Peer review
Peer review information.
Nature Medicine thanks Christiana Kartsonaki, Peter Rossing, Naveed Sattar and Vikas Sridhar for their contribution to the peer review of this work. Primary Handling Editor: Sonia Muliyil, in collaboration with the Nature Medicine team.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended data fig. 1 effect of semaglutide treatment or placebo on waist circumference from baseline to week 104 by subgroups..
Data from the in-trial period. N = 17,604. P values represent test of no interaction effect. P values are two-sided and not adjusted for multiplicity. The dots show estimated treatment differences and the error bars show 95% confidence intervals. Details of the statistical models are available in Methods . BMI, body mass index; CI, confidence interval; CV, cardiovascular; CVD, cardiovascular disease; eGFR, estimated glomerular filtration rate; ETD, estimated treatment difference; HbA1c, glycated hemoglobin; MI, myocardial infarction; PAD, peripheral artery disease; sema, semaglutide.
Supplementary information
Reporting summary, supplementary tables 1 and 2.
Supplementary Table 1. Baseline characteristics by BMI class. Data are represented as number and percentage of patients. Renal function categories were based on the eGFR as per Chronic Kidney Disease Epidemiology Collaboration. Albuminuria categories were based on UACR. Smoking was defined as smoking at least one cigarette or equivalent daily. The category ‘Other’ for CV inclusion criteria includes patients where it is unknown if the patient fulfilled only one or several criteria and patients who were randomized in error and did not fulfill any criteria. Supplementary Table 2. SAEs according to baseline BMI category. P value: two-sided P value from Fisher’s exact test for test of no difference.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Ryan, D.H., Lingvay, I., Deanfield, J. et al. Long-term weight loss effects of semaglutide in obesity without diabetes in the SELECT trial. Nat Med (2024). https://doi.org/10.1038/s41591-024-02996-7
Download citation
Received : 01 March 2024
Accepted : 12 April 2024
Published : 13 May 2024
DOI : https://doi.org/10.1038/s41591-024-02996-7
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.

- Open access
- Published: 23 May 2024
The effect of replacing sedentary behavior with different intensities of physical activity on depression and anxiety in Chinese university students: an isotemporal substitution model
- Yulan Zhou 1 ,
- Zan Huang 1 ,
- Yanjie Liu 1 &
- Dongao Liu 2
BMC Public Health volume 24 , Article number: 1388 ( 2024 ) Cite this article
49 Accesses
Metrics details
Previous research has suggested that engaging in regular physical activity (PA) can help to reduce symptoms of depression and anxiety in university students. However, there is a lack of evidence regarding the impact of reducing sedentary behavior (SB) and increasing light-intensity PA (LPA) on these symptoms. This study aims to address this gap by using isotemporal substitution (IS) models to explore how substituting SB with LPA or moderate-to-vigorous PA (MVPA) affects depression and anxiety symptoms among university students.
The study recruited 318 university students with a mean age of 21.13 years. Accelerometers were used to objectively measure the time spent on SB, LPA, and MVPA, while depression and anxiety symptoms were assessed using the Center for Epidemiologic Studies Depression Scale (CES-D) and the Self-rating Anxiety Scale (SAS). IS models using multivariable linear regression were employed to estimate the associations between different behaviors and depression and anxiety symptoms when 30 min of one behavior was substituted with another.
In the single-activity model, less SB (β = 0.321, 95% CI: 0.089, 1.297) and more MVPA (β = −0.142, 95% CI: −1.496, − 0.071) were found to be significantly and negatively associated with depression scores, while less SB (β = 0.343, 95% CI: 0.057, 1.014), LPA (β = 0.132, 95% CI: 0.049, 1.023), and more MVPA (β = −0.077, 95% CI: −1.446, − 0.052) were significantly and negatively correlated with anxiety scores. The IS analysis revealed that substituting 30 min of SB with LPA (β = −0.202, 95% CI: −1.371, − 0.146) or MVPA (β = −0.308, 95% CI: −0.970, − 0.073) was associated with improvements in depressive symptoms. Substituting 30 min of SB with MVPA (β = −0.147, 95% CI: −1.863, − 0.034) was associated with reduced anxiety symptoms.
Replacing 30 min of SB with MVPA may alleviate depression and anxiety symptoms in university students. Further research is needed to explore the long-term effects of PA interventions on the mental health disorders of this population.
Peer Review reports
The World Health Organization (WHO) estimates that people worldwide will be affected by mental health disorders at some point in their lives. Around one billion people currently suffer from such conditions, placing mental health disorders among the leading causes of disease burden and disability worldwide [ 1 ]. Furthermore, individuals with moderate to severe mental health disorders have a reduced life expectancy of 10–20 years and a 2–3 times higher risk of mortality compared to the general population [ 2 ]. Depression and anxiety are globally prevalent mental health disorders and increased by a massive 25% in the first year of the COVID-19 pandemic [ 1 ]. Both disorders are negative emotions and often co-occur, with 62% of adults with anxiety experiencing depressive episodes as well [ 3 ]. The pressures of academics, interpersonal interactions, and employment make university students particularly vulnerable to mental health disorders, including depression and anxiety [ 4 ]. Consequently, the annual detection rate of these conditions among university students is on the rise globally [ 5 ]. A survey conducted in China has revealed that a significant number of university students are at high risk of developing depression and anxiety. Specifically, 6.6% of students face a high risk of depression, while 5.4% exhibit severe anxiety disorders [ 6 ]. The presence of depression and anxiety during university can persist into adulthood and adversely affect many aspects of personal life, such as personal relationships, academic performance, and work productivity [ 7 ]. It is essential to address the mental health needs of university students who experience depression and anxiety.
Research has shown that engaging in regular physical activity (PA) can provide numerous health benefits for university students, including a reduced risk of depression and anxiety [ 8 , 9 ]. Studies have found a strong connection between moderate-to-vigorous PA (MVPA) and lower levels of both depression and anxiety symptoms in this population. Two recent systematic reviews, which encompassed evidence from prospective cohort studies and intervention studies, have converged on the conclusion that engaging in regular MVPA is linked to a reduction in depressive and anxiety symptoms [ 10 , 11 ]. Moreover, while the relationship between light-intensity PA (LPA) and sedentary behavior (SB) with depression and anxiety is not entirely conclusive, some studies have found links between these factors [ 12 , 13 ]. Given the health-promoting relationship between PA and health, public health organizations worldwide encourage individuals to “sit less and move more” [ 14 , 15 ]. However, individuals are limited in the amount of time they can engage in PA each day, and changes in the duration of one behavior inevitably led to compensatory changes in the duration of other behaviors. Therefore, a more comprehensive approach should be used to explore the combined effects of different intensities of PA and SB on health outcomes [ 16 ].
The Isotemporal Substitution (IS) Model as suggested by Mekary et al. [ 17 ] simultaneously simulates the specific activity being performed and the specific behavior being replaced in an equal time-exchange manner. The model controls for the confounding effect of total activity time and the heterogeneity of participation or substitution activities. Thus, one can estimate associations between theoretically substituting one type of PA for others and health outcomes. Several recent studies have explored the associations of SB, LPA, and MVPA with symptoms of depression and anxiety in older adults using the IS modeling method. For example, two cross-sectional studies have shown that reallocating 30 min of SB with an equal amount of either LPA or MVPA is significantly associated with a reduced risk of developing depression symptoms among older adults [ 18 , 19 ]. The studies by Dillon et al. [ 20 ] and Tully et al. [ 21 ] demonstrated that reallocating 30 min of SB with LPA or MVPA was associated with improved anxiety symptoms among older adult. In a study by Chao et al. [ 22 ], Chinese university students experienced a noteworthy reduction in anxiety symptoms by replacing 15 min of SB with LPA. Nonetheless, the impact of substituting SB with various intensities of PA on depression among university students remains an area that requires further exploration. Moreover, unlike depression, anxiety often presents with distinct physiological symptoms such as a racing heart, muscle tension, sweaty palms, and dry mouth [ 23 ]. Given these distinctions, it becomes imperative to explore whether the substitution relationship between various activity behaviors differs in its effects on depression and anxiety among university students.
Therefore, this study aimed to investigate the cross-sectional associations between SB, LPA, and MVPA with depression and anxiety among university students, and to explore the difference in the effects of replacing 30 min of SB with different intensity PA (LPA and MVPA) on depression and anxiety among university students. The outcomes of this study hold the potential to enrich our comprehension of the intricate connection between PA and the prevalence of depression and anxiety among university students. Furthermore, they offer valuable practical insights that can inform the development of effective interventions aimed at promoting PA and mitigating these mental health disorders within this population.
Participants and data collection
For this study, participants were university students recruited via a convenience-based sampling method. Recruitment efforts were concentrated on one sizable public university in each of the regions: Hubei Province, Zhejiang Province, and Shanghai, China. A multistage cluster sampling approach was employed to select participants. In the first stage, one college (e.g., Humanities, social sciences, engineering, and information sciences) was chosen from each of the selected universities. Following that, two classes were selected from each of the selected colleges. To be eligible for participation in the study, individuals needed to meet the following criteria: They had to be full-time university students between the ages of 18 and 25 years old. Participants who reported any physical or mental condition that would hinder their ability to engage in PA were excluded from the study. Ethical approval from the Ethics Committee of Zhejiang Normal University was obtained before the commencement of data collection for our study. Informed consent was obtained from all participants before they completed the questionnaire. To ensure confidentiality, participants were assigned a unique identification number and all data collected were kept secure and anonymous. Participants were informed that they could withdraw from the study at any time without penalty. The study’s required number of participants was estimated using G*Power 3.1 software, considering a 5% maximum tolerable error and a power of 0.8. The estimated number of subjects needed was 343. To accommodate potential losses such as dropouts and hardware failures, this number was increased by 20%. Therefore, a total of 463 university students from 6 classes were invited to participate in the survey. Ten students declined to cooperate with the survey, and an additional seven students were excluded due to recent psychological dysfunction, defined as having received a psychological disorder diagnosis within the past 6 months. Consequently, a total of 446 students actively participated in this study. An initial inspection of the raw data showed that 104 participants did not provide valid accelerometry data (at least 10 h of wear per day was considered one valid day, and at least one valid weekend day and two valid weekdays), and a further 24 participants did not provide valid survey data for the outcome variables. Thus, the study included a total of 318 participants, with 107 from Hubei Province, 93 from Zhejiang Province, and 118 from Shanghai.
Data collection took place during the middle of the Fall semester, spanning from October to December 2022. The primary author, alongside two research assistants who were postgraduates specializing in physical education, conducted the data collection. Participants were equipped with accelerometers and instructed to maintain their regular daily routines during the monitoring period. To ensure adherence, the research assistants made daily visits to the universities in the mornings to remind students to wear the accelerometers. To ensure the collection of data for a complete seven days, students were instructed to return the accelerometers after eight days. Subsequently, all participants were requested to complete a self-administered questionnaire in a classroom environment. This questionnaire covered various socio-demographic factors (e.g., age and gender), lifestyle aspects (e.g., alcohol consumption and smoking habits), sleep patterns, and details regarding mental health disorders. Throughout this process, the research assistants were present to offer support to the participants and ensure order in the classrooms.
Measurements
Sedentary behavior and physical activity.
SB, LPA, and MVPA were measured using the triaxial accelerometer (ActiGraph wGT3X-BT). The technical reliability and validity of the accelerometer device have been described elsewhere [ 24 ]. Participants were instructed to wear the accelerometers on their right hipbone for at least seven consecutive days and only remove it for sleeping and water-based activities (e.g., swimming and bathing). The accelerometer started recording data at 0:00 a.m. on the second day of distribution and continued until the researcher retrieved it at the end of the eighth day. After the test was conducted, data were extracted using Actilife 6.5 software and then collapsed into a specific time interval (epoch), for example, a 60 s epoch. The inclusion criteria of wearing the accelerometer for at least one valid weekend day and two valid weekdays, with at least 10 h per day of wear, helps to ensure that the data is representative of the participants’ typical PA levels [ 25 ]. Non-wear time was defined as a period of at least consecutive 60 min during which the accelerometer recorded 0 counts per minute (cpm) [ 26 ]. Activity counts were classified using a set of cut points to calculate the intensity and amount of SB, LPA, and MVPA. SB was classified as < 100 cpm, LPA was 100–1952 cpm, and MVPA was > 1952 cpm [ 27 ].
Depression and anxiety
The Center for Epidemiologic Studies Depression (CES-D) 20-item symptom scale was used to assess symptoms of depression [ 28 ]. The CES-D is a widely used and well-established measure for assessing symptoms of depression in research studies [ 29 ]. Participants were asked to report how often over the past week they have experienced each of the 20 symptoms associated with depression such as restless sleep, poor appetite, and feeling lonely. The score of each item ranges from 0 (rarely or none of the time) to 3 (most or all of the time). The total score ranged from 0 to 60, with higher scores indicative of higher levels of depressive symptoms. A score of 16 points or more is indicative of depression in this assessment [ 30 ]. The reliability of the CES-D in this study, as indicated by a Cronbach’s alpha coefficient of 0.865, is well above the acceptable threshold of 0.70, indicating that the scale is consistent in measuring symptoms of depression.
The Self-rating Anxiety Scale (SAS), which was compiled by Zung et al. [ 31 ] was employed in this study to allow university students to self-report anxiety symptoms, which can provide insight into the subjective experience of anxiety. The survey consists of 20-item scale and covers a range of potential anxiety symptoms, including psychological and somatic symptoms. Each item is score on a four-point Likert scale according to the frequency of the status in the previous week. Participants choose responses ranging from 1 to 4 (1 = no or a little of the time, 2 = some of the time, 3 = good part of the time, 4 = most of the time or all the time) with summed scores ranging from 20 to 80. Higher scores indicate a higher level of anxiety symptoms. A cut-off value of 50 for the total score was established to indicate the presence of anxiety symptoms [ 7 ]. This scale has been shown to have good reliability and validity in a variety of populations [ 32 ]. In this study, the internal consistency of the scale was also found to be high, with a Cronbach’s alpha coefficient of 0.782, indicating that the scale is reliable in measuring this construct in the study population.
Covariates were selected based on previous studies and included socio-demographic characteristics (i.e., weight, height, age, gender, years of university, and residential background), lifestyle aspects (i.e., alcohol consumption and smoking information), and sleep pattern [ 33 ]. Participants were asked to report their socio-demographic and lifestyle information through questionnaires. The Pittsburgh sleep quality index (PSQI) questionnaire were used to assess students’ sleep patterns [ 34 ]. The researchers also calculated the participants’ body mass index (BMI) using their reported weight and height (weight in kilograms divided by height in meters squared).
Data analysis
Statistical analyses were performed using IBM SPSS Statistics, Version 26.0 for Windows and the level of significance was set at P < 0.05. Descriptive statistics like frequencies, percentages, means, and standard deviations were used to summarize the data. Categorical variables like gender, drinking alcohol, and smoking status were presented as frequencies and percentages. Continuous variables like age and BMI were presented as means and standard deviations. Person correlations were used to assess the associations among SB, LPA, MVPA, and mental health disorders. Three multiple linear regression models including a single-activity, a partition, and an IS models were utilized to examine the relationship between SB, LPA, and MVPA with both depression and anxiety. Prior to conducting the analysis using three distinct linear regression models, it was ensured that there existed linear relationships between SB, LPA, MVPA, and the scores for depression and anxiety. Additionally, it was confirmed that there was no evidence of multicollinearity among the independent variables. In current study, we focused on modeling the effects of reallocating 30 min from one behavior to another. This approach was chosen for its practicality, especially considering that in China, university students tend to be generally physically inactive [ 30 ]. Reallocating 30 min is a more feasible and realistic scenario than longer durations. In addition, previous studies among adults have interpreted the association between replacing of 30 min with different activity intensities and mental health disorder [ 18 , 19 , 20 , 21 ]. We chose the replacing 30 min in the present study to improve the interpretability of the results. SB, LPA, and MVPA were standardized using 30 min as a unit for activity in analyses.
First, a series of single-activity models were computed to investigate the independent associations between each behavior (i.e., SB, LPA, MVPA) and mental health disorder (i.e., depression, anxiety), adjusted for covariates that are known to be associated with both activity and mental health disorder (e.g., age, gender, smoking status, and alcohol consumption). One type of single activity model (in the case of SB) is shown as follows: Mental health disorder = (β1) SB + (β5) covariates.
Second, partition models were used to estimate the effects of increasing each behavior on mental health disorder while holding the duration of each of the other behavior variables constant. Partition model represents the effects of adding, not substituting an activity type because total wear time is excluded in the model (thus is not held constant). Partition models were expressed as: Mental health disorder = (β1) SB + (β2) LPA + (β3) MVPA + (β5) covariates.
Finally, IS models were applied to explore the effects of reallocating time between SB, LPA, and MVPA on indicators of mental health disorder. IS models estimate the effects of replacing time spent engaging in one behavior with another behavior for the same amount of time, while holding total time constant. The following equation describes the effects of replacing 30 min of SB with 30 min of LPA (β2), or MVPA (β3): Mental health disorder = (β2) LPA + (β3) MVPA + (β4) total wear time + (β5) covariates. β1-β5 are the coefficients of respective activities or covariates.
Descriptive characteristics of study sample
Table 1 shows the characteristics of study participants. The study included a final sample of 318 participants, of which 127 (39.9%) were male and 191 (60.1%) were female. The mean age was 21.13 (SD = 3.53) years. The mean BMI and total PSQI score were 19.48 (SD = 1.03) and 6.93 (SD = 2.13), respectively. On average, participants wore accelerometers for 823.89 (SD = 111.75) minutes/day. The mean proportion of SB, LPA, and MVPA time to total accelerometer wearing time were 72.5%, 21.5%, and 6.0%, respectively. Participants reported an average score of 13.85 (SD = 8.21) for depressive symptoms, with 17.3% of participants falling into the category of experiencing depressive symptoms (a total score of CES-D ≥ 16). In terms of anxiety symptoms, the mean score was 39.03 (SD = 6.20), and 26.1% of the sample met the criteria for anxiety symptoms (a total score of SAS ≥ 50). The correlation among SB, LPA, MVPA, and mental health problems presented in the supplemental Table 1 .
Effects of reallocating time between the different intensities of PA and SB on depression symptoms
Table 2 displays single-activity, partition, and IS models for the relationship between different intensities of PA, SB, and university students’ scores of depressive symptoms. In the single-activity models, SB time tended to be significantly and positively associated with depression scores (β = 0.321, 95% CI: 0.089 to 1.297), whereas MVPA was significantly and negatively associated with scores of depressive symptoms (β = −0.142, 95% CI: −1.496 to − 0.071). In the partition models, increasing SB by 30 min while holding the other variables constant was associated with a significant increase in depression scores among university students (β = 0.326, 95% CI: 0.098 to 1.315). In the IS models, replacing 30 min/day of SB with LPA (β = −0.202, 95% CI: −1.371 to − 0.146) and MVPA (β = −0.308, 95% CI: −0.970 to − 0.073) resulted in a significant decrease in depression scores.
Effects of reallocating time between the different intensities of PA and SB on anxiety symptoms
Table 3 presents the results for the single-activity, partition, and IS models adjusted for covariates. The single-activity model shows that higher levels of both SB (β = 0.343, 95% CI: 0.057 to 1.014) and LPA (β = 0.132, 95% CI: 0.049 to 1.023) were significantly associated with higher anxiety scores. Conversely, a higher level of MVPA was associated with a lower anxiety score (β = −0.077, 95% CI: −1.446 to − 0.052). The partition model showed that increasing SB by 30 min was associated with higher symptoms of anxiety (β = 0.325, 95% CI: 0.085 to 0.983). The IS model demonstrated that a 30 min unit of SB replaced with MVPA was significantly and negatively associated with anxiety scores (β = −0.147, 95% CI: −1.863 to − 0.034). No statistically significant change in scores of anxiety symptoms was observed when SB was substituted by LPA (β = −0.095, 95% CI: −0.982 to 0.281).
In the current study, the prevalence rates of depression and anxiety among university students were determined to be 17.3% and 26.1%, respectively. These findings align with surveys conducted among university students in various other countries [ 35 , 36 ]. This highlights that depression and anxiety are major mental health concerns not confined to Chinese students but prevalent among university students worldwide [ 37 , 38 ]. Furthermore, university students face unique challenges in terms of PA and SB. They often have demanding schedules and spend long periods of time sitting in lectures or studying. A comprehensive body of evidence has found PA to reduce depression and anxiety in both clinical and non-clinical populations [ 39 , 40 ]. However, the beneficial effects of LPA and MVPA, as well as the impact of substituting SB with light activity or MVPA on mental health disorders, are less known. The IS model is likely to show more accurate results of associations of SB and PA with mental health disorders, since it takes the finite amount of time in a day into account, allowing for estimating the effect of replacing one type of PA with another. This study demonstrated the usefulness of the IS model approach in examining the relationship between PA and mental health disorders in Chinese university students. By estimating the effects of substituting SB with different intensities of PA, the study found that replacing 30 min of SB with MVPA was associated with decreased depression and anxiety scores. Additionally, replacing 30 min of SB with LPA was associated with lower depression scores.
The available evidence, specifically within the domain of IS modeling, is notably limited when it comes to addressing depressive symptoms among university students in comparison to studies conducted on other age demographics. Consistent with two cross-sectional studies among older adults [ 18 , 19 ], the current study found a significant decrease in depressive symptoms when 30 min of SB was substituted with LPA or MVPA. These results suggest that the benefits of PA on depressive symptoms are not limited to older adults and can also be observed in younger populations. A larger number of intervention studies have also confirmed that PA can significantly reduce depressive symptoms [ 41 ]. Multiple mechanisms of action have been proposed to explain associations between PA and depressive symptoms. Depression is a negative mood that can be impacts how people think, feel, and go about daily activities. Typical symptoms of depression include sadness, emptiness, hopelessness, feeling of worth-lessness, and loss of interest in activities [ 42 , 43 ]. Compared with SB, LPA or MVPA can increase the production and release of mood-related neurotransmitters such as serotonin and endorphins, which can help promote pleasure and positive feeling, thereby alleviating depressive symptoms [ 44 , 45 ]. In addition, participation in PA can lead to improved social relationships and increased social support, which can help reduce psychological stress and improve depressive symptoms [ 46 , 47 ]. Our study further revealed that compared to replacing 30 min of SB with LPA (− 0.202), a more substantial benefit was observed when replacing 30 min of SB with MVPA (− 0.308) concerning depressive symptoms in university students. A recent systematic review of IS studies also demonstrated that the strongest association with health outcomes is observed when time is reallocated from SB to MVPA [ 48 ]. These results imply that university students who spent most of their day sedentary (72.5%) should be encouraged to sit less and move more for a range of health benefits, including improvements in mental and cardiovascular health and reduced risk of chronic diseases. Furthermore, incorporating reduced SB and increased MVPA into daily life may be a more effective strategy for improving depressive symptoms in university students.
The findings derived from this study emphasized the positive consequences of replacing 30 min of SB with MVPA in mitigating anxiety among university students. Conversely, there was no observable effect when substituting 30 min of SB with LPA, marking a distinction from the ameliorative impact of LPA on depression. Anxiety is characterized as a distinct, unpleasant emotional state or condition encompassing apprehension, tension, worry, and physiological arousal [ 49 ]. It is essential to note that anxiety and depression represent two distinct and valid constructs that frequently occur simultaneously. Alternatively, they could be regarded as different expressions of the same underlying vulnerability [ 23 ]. In the model formulated by Clark et al. [ 50 ] symptoms of depression and anxiety are classified into three subtypes: negative affectivity, positive affectivity, and physiological hyperarousal. Negative affectivity is linked to both depression and anxiety. The deficiency in positive affectivity is hypothesized to be solely connected to depression, while physiological hyperarousal is suggested to be specific to anxiety. Consequently, consistent with the approach for addressing depression, substituting SB with PA holds promise for ameliorating the negative emotional dimensions of both depression and anxiety. This is believed to occur through the modulation of neuroplasticity and the reduction of inflammation [ 47 , 51 ]. However, it’s worth noting that LPA may not be as effective in attenuating the physiological hyperarousal associated with anxiety. In contrast, engaging in a moderate or high level of PA has the potential to induce relaxation in the central nervous response and decrease the sensitivity of physiological arousal tied to anxiety, ultimately resulting in a reduction in anxiety [ 52 ]. Moreover, PA serves as a valuable form of distraction from the daily stressors that individuals encounter. Conversely, engaging in LPA may curtail students’ ability to divert their attention away from the stress-inducing factors of everyday life, leading to an escalation in the severity of anxiety symptoms [ 53 ].
Consistent with the established literature, current study provided further evidence that replacing SB with either LPA or MVPA yielded favorable effects on the depressive symptoms of participants [ 18 , 19 ]. However, it’s important to emphasize that our investigate did not uncover any beneficial effects of LPA substituting SB on anxiety among university students. This outcome stands in contrast to the findings of studies conducted by Dillon et al. [ 20 ] and Chao et al. [ 22 ]. The inconsistent findings may be related to the use of different measures of physical behavior in these studies. Dillon et al. [ 20 ] used objective measures of physical behavior, the GENEActiv. This accelerometer measures acceleration at the wrist, while the ActiGraph, which used in present study, measures acceleration of the body at the hip. The movement or acceleration of the body differs significantly at these two positions and thus affect the comparability of the current findings to previous research. In an investigation led by Chao et al. [ 22 ], the central focus was on examining the connection between self-reported PA and anxiety among college students. It’s worth noting that when PA levels are assessed using self-reported measurement tools, there is a tendency for individuals to overestimate their activity levels [ 54 ]. This could offer an explanation for why previous research often demonstrated positive associations between LPA and anxiety, while our current study did not. Additionally, it is important to consider the context of LPA when examining its relationship with anxiety. Different contexts of LPA may have different effects on anxiety levels due to factors such as the level of mental stimulation they provide and the social context in which they are performed [ 55 ]. For example, household and occupational LPA may reduce anxiety by providing a sense of accomplishment and control, while transport LPA may be associated with anxiety due to the stress and time pressure involved [ 56 ]. The single model of this study also demonstrated that a more time spent in LPA was associated with higher anxiety scores. It is premature to entirely negate the potential effects of replacing SB with LPA. To gain a more thorough understanding of whether and to what extent LPA can be beneficial for the mental health of university students, additional research utilizing comprehensive measurement tools is essential.
Given the escalating prominence of depression and anxiety as significant public health concerns, it is paramount that we pinpoint cost-effective strategies to address these challenges. Our findings indicate that replacing 30 min of SB with LPA (β = −0.202, 95% CI: −1.371, − 0.146) or MVPA ((β = −0.308, 95% CI: −0.970, − 0.073) significantly improved depression symptoms, while only 30 min of MVPA (β = −0.147, 95% CI: −1.863, − 0.034) substitution for SB was effective in reducing anxiety symptoms among university students. Although the relatively small β coefficients and wide confidence intervals may indicate that the actual effect size is insufficient to confidently assert that such behavior substitution has a substantive improvement in university students’ depression and anxiety symptoms, the findings offer insights into optimizing PA implementation and highlight the challenges one may encounter in making such changes. For university students who are relatively physically robust, targeting substituting SB with MVPA may be a more feasible, attractive, or realistic behavior change to target in the first instance. However, for students who are not used to regular PA, attempting to switch from SB to MVPA may be too daunting and overwhelming. Encouraging students to find PA that they enjoy and can easily incorporate into their daily routine is key. Embarking on the journey with smaller, realistic goals can be instrumental in building both confidence and motivation. Following this, it is prudent to undergo exercise testing to tailor a PA program that aligns with these goals, preventing an initial overexertion. The use of an activity diary is strongly encouraged, and documenting daily life PA can enhance students’ commitment to the PA program. Finally, maintaining social connections, whether with parents or classmates, while engaging in PA can be a valuable factor in facilitating students’ achievement or maintenance of this new behavior [ 57 , 58 ]. Furthermore, Ministries of Education and Health should place a strong emphasis on heightening public health awareness concerning the pivotal role of MVPA for individuals with mental health disorders. They should offer guidance on indispensable preventive measures for university students who are beginning to adopt a lifestyle of physical inactivity. Additionally, these ministries should actively adopt and implement effective policies and interventions related to these pertinent issues.
There are several potential limitations presents in this study. First, due to its cross-sectional design, the study cannot establish causal associations, and there remains the potential for confounding by unmeasured covariates. Second, the IS method merely indicated the theoretical effect of substituting one behavior for another, it may not fully encapsulate the complexity and dynamism of behavior changes in everyday life. Third, the use of accelerometers fails to capture certain types of activities (e.g., swimming, cycling) and the placement of the device (hipbone vs. wrist) may affect data accuracy. Fourth, depression and anxiety outcomes were self-reported. In spite of self-reported measures are more cost effective and convenient, there is a possibility of social expectation bias as respondents may conceal their true situation. Finally, since all the participants were restricted to three provinces in China, representation of the general population is limited. Future research should address these limitations to provide a more comprehensive understanding of the relationship between time-use compositions and mental health disorders in the university students.
This study revealed that substituting 30 min of SB with LPA or MVPA significantly improved depression symptoms in university students. Greater benefits were observed when shifting SB to MVPA. Moreover, substituting 30 min of SB with MVPA was associated with reduced anxiety symptoms. These findings contribute valuable and novel information to our comprehension of how various intensities of PA impact mental health disorders. Future research should delve into the potential of PA as a cost-effective and readily accessible strategy to alleviate the burden of mental health disorders among university students.
Data availability
The datasets used and/or analyzed during the present study are available from the Y. Zhou ([email protected]) on reasonable request.
Abbreviations
Sedentary Behavior
Light-intensity Physical Activity
Moderate-to-Vigorous Physical Activity
Isotemporal Substitution
Body Mass Index
Center for Epidemiologic Studies Depression Scale
Self-rating Anxiety Scale
Counts Per Minute
Pittsburgh Sleep Quality Index
World Health Organization. World mental health report: Transforming mental health for all. WHO Web site. https://www.who.int/teams/mental-health-and-substance-use/world-mental-health-report , Accessed 8 June 2023.
World Health Organization. Management of Physical Health conditions in adults with severe Mental disorders. Geneva: WHO; 2018.
Google Scholar
World Health Organization. Investing in treatment for depression and anxiety leads to fourfold return. WHO Web site. https://www.who.int/news/item/13-04-2016-investing-in-treatment-for-depression-and-anxiety-leads-to-fourfold-return , Accessed 16 February 2023.
Gao W, Ping S, Liu X. Gender differences in depression, anxiety, and stress among college students: a longitudinal study from China. J Affect Disord. 2020;263:292–300.
Article PubMed Google Scholar
Lei XY, Xiao LM, Liu YN, Liu YM. Prevalence of depression among Chinese university students: a Meta-analysis. PLoS ONE. 2016;11(4):e0153454.
Article PubMed PubMed Central Google Scholar
Gao C, Sun Y, Zhang F, Zhou F, Dong C, Ke Z, et al. Prevalence and correlates of lifestyle behavior, anxiety and depression in Chinese college freshman: a cross-sectional survey. Int J Nurs Sci. 2021;8:347–53.
PubMed PubMed Central Google Scholar
Bu H, He A, Gong N, Huang L, Liang K, Kastelic K, et al. Optimal movement behaviors: correlates and associations with anxiety symptoms among Chinese university students. BMC Public Health. 2021;21:2052–63.
Shimamoto H, Suwa M, Mizuno K. Relationships between Depression, Daily Physical Activity, Physical Fitness, and Daytime Sleepiness among Japanese University students. Int J Environ Res Public Health. 2021;18:8036.
Herbert C. Enhancing Mental Health, well-being and active lifestyles of University students by means of physical activity and Exercise Research Programs. Front Public Health. 2022;10:849093.
U.S. Department of Health and Human Services. Part F. Chapter 3: Brain Health. 2018. Retrieved from health.gov/paguidelines/second-edition/report/pdf/PAG_Advisory_Committee_Report.pdf .
Rebar A, Stanton R, Geard D, Short C, Duncan MJ, Vandelanotte C. A meta-meta-analysis of the effect of physical activity on depression and anxiety in non-clinical adult populations. Health Psychol Rev. 2015;9:366–78.
Felez-Nobrega M, Bort-Roig J, Briones L, Sanchez-Niubo A, Koyanagi A, Puigoriol E, et al. Self-reported and activPALTM-monitored physical activity and sedentary behaviour in college students: not all sitting behaviours are linked to perceived stress and anxiety. J Sports Sci. 2020;38:1566–74.
Tashiro T, Maeda N, Tsutsumi S, Komiya M, Arima S, Mizuta R, et al. Association between sedentary behavior and depression among Japanese medical students during the COVID-19 pandemic: a cross-sectional online survey. BMC Psychiatry. 2022;22:348–57.
Article CAS PubMed PubMed Central Google Scholar
Piercy KL, Troiano RP, Ballard RM, Carlson SA, Fulton JE, Galuska DA, et al. The physical activity guidelines for americans. J Am Med Assoc. 2018;320:2020–8.
Article Google Scholar
Department of Health and Social Care. UK Chief Medical officers’ physical activity guidelines. London, UK: Department of Health and Social Care; 2019.
Prochaska JO. Multiple health behavior research represents the future of preventive medicine. Prev Med. 2008;46:281–5.
Mekary RA, Willett WC, Hu FB, Ding EL. Isotemporal substitution paradigm for physical activity epidemiology and weight change. Am J Epidemiol. 2009;170:519–27.
Yasunaga A, Shibata A, Ishii K, Koohsari MJ, Oka K. Cross-sectional associations of sedentary behaviour and physical activity on depression in Japanese older adults: an isotemporal substitution approach. BMJ open. 2018;8:e022282.
Wei J, Xie L, Song S, Wang T, Li C. Isotemporal substitution modeling on sedentary behaviors and physical activity with depressive symptoms among older adults in the U.S.: the national health and nutrition examination survey, 2007–2016. J Affect Disord. 2019;257:257–62.
Dillon CB, Mcmahon E, O’Regan G, Perry IJ. Associations between physical behaviour patterns and levels of depressive symptoms, anxiety and well-being in middle-aged adults: a cross-sectional study using isotemporal substitution models. BMJ open. 2018;8:e018978.
Tully MA, Mcmullan I, Blackburn NE, Wilson JJ, Bunting B, Smith L, et al. Sedentary behavior, physical activity, and mental health in older adults: an isotemporal substitution model. Scand J Med Sci Sports. 2020;30:1957–65.
Chao L, Ma R, Jiang W. Movement behaviours and anxiety symptoms in Chinese college students: a compositional data analysis. Front Psychol. 2022;13:952728.
Dieleman GC, van der Ende J, Verhulst FC, Huizink AC. Perceived and physiological arousal during a stress task: can they differentiate between anxiety and depression? Psychoneuroendocrinology. 2010;35:1223–34.
Ohkawara K, Oshima Y, Hikihara Y, Ishikawa-Takata K, Tabata I, Tanaka S. Real-time estimation of daily physical activity intensity by a triaxial accelerometer and a gravity-removal classification algorithm. Br J Nutr. 2011;105:1681–91.
Article CAS PubMed Google Scholar
Anderson CB, Hagstromer M, Yngve A. Validation of the PDPAR as an adolescent diary: Effect of accelerometer cut points. Med Sci Sports Exerc. 2005;37:1224–30.
Troiano RP, Berrigan D, Dodd KW, Masse LC, Tilert T, McDowell M. Physical activity in the United States measured by accelerometer. Med Sci Sports Exerc. 2008;40:181–8.
Freedson PS, Melanson E, Sirard J. Calibration of the computer science and applications, Inc. accelerometer. Med Sci Sports Exerc. 1997;29:777–81.
Radloff LS. The CES-D scale: a self-report depression scale for research in the general population. Appl Psychol Meas. 1977;1:385–401.
Li HCW, Chung OKJ, Ho KY. Center for epidemiologic studies depression scale for children: psychometric testing of the Chinese version. J Adv Nurs. 2010;66:2582–91.
Wu X, Tao S, Zhang Y, Zhang S, Tao F. Low physical activity and high screen time can increase the risks of mental health problems and poor sleep quality among Chinese college students. PLoS ONE. 2015;10:e0119607.
Zung WW. A rating instrument for anxiety disorders. Psychosomatics. 1971;12:371–9.
Fu B, Yan P, Yin H, Zhu S, Liu Q, Liu Y, et al. Psychometric properties of the Chinese version of the infertility self-efficacy scale. Int J Nurs Sci. 2016;3:259–67.
Gao C, Sun Y, Zhang F, Sun H. Prevalence and correlates of lifestyle behavior, anxiety and depression in Chinese college freshman: a cross-sectional survey. Int J Nurs Sci. 2021;8:347–53.
Buysse DJ, Reynolds CF, Monk TH, Berman SR, Kupfer DJ. The Pittsburgh sleep quality index: a new instrument for psychiatric practice and research. Psychiatry Res. 1989;28:193–213.
Eunmi L, Yujeong K. Effect of university students’ sedentary behavior on stress, anxiety, and depression. Perspect Psychiatr Care. 2019;55:164–9.
Usher W, Curran C. Predicting Australia’s university students’ mental health status. Health Promot Int. 2019;34:312–22.
Auerbach RP, Mortier P, Bruffaerts R, Alonso J, Benjet C, Cuijpers P, et al. World Health Organization Journal pre-proof world mental health surveys international college student project (WMH-ICS): prevalence and distribution of mental disorders. J Am Acad Child Adolesc Psychiatry. 2018;57:S297.
Bull FC, Al-Ansari SS, Biddle S, Borodulin K, Willumsen JF. World Health Organization 2020 guidelines on physical activity and sedentary behaviour. Br J Sports Med. 2020;54:1451–62.
Rebar AL, Stanton R, Geard D, Short C, Duncan MJ, Vandelanotte C. A meta-meta-analysis of the effect of physical activity on depression and anxiety in non-clinical adult populations. Health Psychol Rev. 2015;9:366–78.
Jones TL, Sandler CX, Spence RR, Hayes SC. Physical activity and exercise in women with ovarian cancer: a systematic review. Gynecol Oncol. 2020;158:803–11.
Josefsson T, Lindwall M, Archer T. Physical exercise intervention in depressive disorders. Meta-analysis and systematic review. Scand J Med Sci Sports. 2014;24:259–72.
Paul G. Overcoming Depression: a step-by-step Approach to gaining control over depression. USA: Oxford University Press; 2001.
National Institute of Mental Health. Depression Basics. NIMH Web site. https://www.nimh.nih.gov/sites/default/files/documents/health/publications/depression/21-mh-8079-depression_0.pdf , Accessed 25 May 2023.
Archer T, Josefsson T, Lindwall M. Effects of physical exercise on depressive symptoms and biomarkers in depression. CNS Neurol Disord: Drug Targets. 2014;13:1640–53.
Kandola A, Ashdown-Franks G, Hendrikse J, Sabiston CM, Stubbs B. Physical activity and depression: towards understanding the antidepressant mechanisms of physical activity. Neurosci Biobehav Rev. 2019;107:525–39.
Dimeo F, Bauer M, Varahram I, Proest G, Halter U. Benefits from aerobic exercise in patients with major depression: a pilot study. Br Assoc Sport Med. 2001;35:114–7.
Article CAS Google Scholar
Paggi ME, Jopp D, Hertzog C. The importance of leisure activities in the relationship between physical health and well-being in a life span sample. Gerontol. 2016;62:450–8.
Jozo G, Dorothea D, Garcia BE, Nipun S, Adrian B, Timothy O, et al. Health outcomes associated with reallocations of time between sleep, sedentary behaviour, and physical activity: a systematic scoping review of isotemporal substitution studies. Int J Behav Nutr Phys Act. 2018;15:69–137.
Spielberger CD, Reheiser EC. Assessment of emotions: anxiety, anger, depression, and curiosity. Appl Psychol: Health Well-Being. 2009;1:271–302.
Clark LA, Watson D. Tripartite model of anxiety and depression: psychometric evidence and taxonomic implications. J Abnorm Psychol. 1991;100:316–36.
Biddle SJH. Emotion, mood and physical activity. London: Routhledge & Kegan Paul; 2000.
Xiang MQ, Tan XM, Sun J, Yang HY, Zhao XP, Liu L, et al. Relationship of physical activity with anxiety and depression symptoms in Chinese college students during the COVID-19 outbreak. Front Psychol. 2020;11:582436.
Edwards MK, Loprinzi PD. Experimentally increasing sedentary behavior results in increased anxiety in an active young adult population. J Affect Disord. 2016;204:166–73.
Ogonowska-Slodownik A, Morgulec-Adamowicz N, Geigle PR, Kalbarczyk M, Kosmol A. Objective and self-reported assessment of physical activity of women over 60 years old. Ageing Int. 2022;47:307–20.
White RL, Babic MJ, Parker PD, Lubans DR, Astell-Burt T, Lonsdale C. Domain-specific physical activity and mental health: a meta-analysis. Am J Prev Med. 2017;52:653–66.
Zhang X, Mao F, Wu L, Zhang G, Huang Y, Chen Q, et al. Associations of physical activity, sedentary behavior and sleep duration with anxiety symptoms during pregnancy: an isotemporal substitution model. J Affect Disord. 2022;300:137–44.
Ströhle A. Physical activity, exercise, depression and anxiety disorders. J Neural Transm. 2009;116:777–84.
Stubbs B, Koyanagi A, Hallgren M, Firth J, Richards J, Schuch F, et al. Physical activity and anxiety: a perspective from the World Health Survey. J Affect Disord. 2017;208:545–52.
Download references
Acknowledgements
We would like to thank the team who have collaborated in data collection and to all the students and the teachers for their participation.
This study was supported by Zhejiang Federation of Humanities and Social Sciences Circles (No. 2023N014).
Author information
Authors and affiliations.
College of Physical Education and Health Sciences, Zhejiang Normal University, Jinhua, Zhejiang, 321004, China
Yulan Zhou, Zan Huang & Yanjie Liu
Physical Education Department, Shanghai University of Finance and Economics, Shanghai, 200433, China
You can also search for this author in PubMed Google Scholar
Contributions
YZ originated the research idea and wrote the manuscript. DL contributed to data analysis and writing the manuscript. ZH and YL contributed to collecting data. All authors read and approved the final manuscript.
Corresponding author
Correspondence to Dongao Liu .
Ethics declarations
Ethics approval and consent to participate.
The study was approved by the Ethics Review Board of the Zhejiang Normal University with ethics code ZSRT2022102. The written informed consent was obtained from all participants.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Material 1
Rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Zhou, Y., Huang, Z., Liu, Y. et al. The effect of replacing sedentary behavior with different intensities of physical activity on depression and anxiety in Chinese university students: an isotemporal substitution model. BMC Public Health 24 , 1388 (2024). https://doi.org/10.1186/s12889-024-18914-y
Download citation
Received : 28 September 2023
Accepted : 21 May 2024
Published : 23 May 2024
DOI : https://doi.org/10.1186/s12889-024-18914-y
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Physical activity
- University students
BMC Public Health
ISSN: 1471-2458
- General enquiries: [email protected]
A .gov website belongs to an official government organization in the United States.
A lock ( ) or https:// means you've safely connected to the .gov website. Share sensitive information only on official, secure websites.
- About Adverse Childhood Experiences
- Risk and Protective Factors
- Program: Essentials for Childhood: Preventing Adverse Childhood Experiences through Data to Action
- Adverse childhood experiences can have long-term impacts on health, opportunity and well-being.
- Adverse childhood experiences are common and some groups experience them more than others.

What are adverse childhood experiences?
Adverse childhood experiences, or ACEs, are potentially traumatic events that occur in childhood (0-17 years). Examples include: 1
- Experiencing violence, abuse, or neglect.
- Witnessing violence in the home or community.
- Having a family member attempt or die by suicide.
Also included are aspects of the child’s environment that can undermine their sense of safety, stability, and bonding. Examples can include growing up in a household with: 1
- Substance use problems.
- Mental health problems.
- Instability due to parental separation.
- Instability due to household members being in jail or prison.
The examples above are not a complete list of adverse experiences. Many other traumatic experiences could impact health and well-being. This can include not having enough food to eat, experiencing homelessness or unstable housing, or experiencing discrimination. 2 3 4 5 6
Quick facts and stats
ACEs are common. About 64% of adults in the United States reported they had experienced at least one type of ACE before age 18. Nearly one in six (17.3%) adults reported they had experienced four or more types of ACEs. 7
Preventing ACEs could potentially reduce many health conditions. Estimates show up to 1.9 million heart disease cases and 21 million depression cases potentially could have been avoided by preventing ACEs. 1
Some people are at greater risk of experiencing one or more ACEs than others. While all children are at risk of ACEs, numerous studies show inequities in such experiences. These inequalities are linked to the historical, social, and economic environments in which some families live. 5 6 ACEs were highest among females, non-Hispanic American Indian or Alaska Native adults, and adults who are unemployed or unable to work. 7
ACEs are costly. ACEs-related health consequences cost an estimated economic burden of $748 billion annually in Bermuda, Canada, and the United States. 8
ACEs can have lasting effects on health and well-being in childhood and life opportunities well into adulthood. 9 Life opportunities include things like education and job potential. These experiences can increase the risks of injury, sexually transmitted infections, and involvement in sex trafficking. They can also increase risks for maternal and child health problems including teen pregnancy, pregnancy complications, and fetal death. Also included are a range of chronic diseases and leading causes of death, such as cancer, diabetes, heart disease, and suicide. 1 10 11 12 13 14 15 16 17
ACEs and associated social determinants of health, such as living in under-resourced or racially segregated neighborhoods, can cause toxic stress. Toxic stress, or extended or prolonged stress, from ACEs can negatively affect children’s brain development, immune systems, and stress-response systems. These changes can affect children’s attention, decision-making, and learning. 18
Children growing up with toxic stress may have difficulty forming healthy and stable relationships. They may also have unstable work histories as adults and struggle with finances, jobs, and depression throughout life. 18 These effects can also be passed on to their own children. 19 20 21 Some children may face further exposure to toxic stress from historical and ongoing traumas. These historical and ongoing traumas refer to experiences of racial discrimination or the impacts of poverty resulting from limited educational and economic opportunities. 1 6
Adverse childhood experiences can be prevented. Certain factors may increase or decrease the risk of experiencing adverse childhood experiences.
Preventing adverse childhood experiences requires understanding and addressing the factors that put people at risk for or protect them from violence.
Creating safe, stable, nurturing relationships and environments for all children can prevent ACEs and help all children reach their full potential. We all have a role to play.
- Merrick MT, Ford DC, Ports KA, et al. Vital Signs: Estimated Proportion of Adult Health Problems Attributable to Adverse Childhood Experiences and Implications for Prevention — 25 States, 2015–2017. MMWR Morb Mortal Wkly Rep 2019;68:999-1005. DOI: http://dx.doi.org/10.15585/mmwr.mm6844e1 .
- Cain KS, Meyer SC, Cummer E, Patel KK, Casacchia NJ, Montez K, Palakshappa D, Brown CL. Association of Food Insecurity with Mental Health Outcomes in Parents and Children. Science Direct. 2022; 22:7; 1105-1114. DOI: https://doi.org/10.1016/j.acap.2022.04.010 .
- Smith-Grant J, Kilmer G, Brener N, Robin L, Underwood M. Risk Behaviors and Experiences Among Youth Experiencing Homelessness—Youth Risk Behavior Survey, 23 U.S. States and 11 Local School Districts. Journal of Community Health. 2022; 47: 324-333.
- Experiencing discrimination: Early Childhood Adversity, Toxic Stress, and the Impacts of Racism on the Foundations of Health | Annual Review of Public Health https://doi.org/10.1146/annurev-publhealth-090419-101940 .
- Sedlak A, Mettenburg J, Basena M, et al. Fourth national incidence study of child abuse and neglect (NIS-4): Report to Congress. Executive Summary. Washington, DC: U.S. Department of Health an Human Services, Administration for Children and Families.; 2010.
- Font S, Maguire-Jack K. Pathways from childhood abuse and other adversities to adult health risks: The role of adult socioeconomic conditions. Child Abuse Negl. 2016;51:390-399.
- Swedo EA, Aslam MV, Dahlberg LL, et al. Prevalence of Adverse Childhood Experiences Among U.S. Adults — Behavioral Risk Factor Surveillance System, 2011–2020. MMWR Morb Mortal Wkly Rep 2023;72:707–715. DOI: http://dx.doi.org/10.15585/mmwr.mm7226a2 .
- Bellis, MA, et al. Life Course Health Consequences and Associated Annual Costs of Adverse Childhood Experiences Across Europe and North America: A Systematic Review and Meta-Analysis. Lancet Public Health 2019.
- Adverse Childhood Experiences During the COVID-19 Pandemic and Associations with Poor Mental Health and Suicidal Behaviors Among High School Students — Adolescent Behaviors and Experiences Survey, United States, January–June 2021 | MMWR
- Hillis SD, Anda RF, Dube SR, Felitti VJ, Marchbanks PA, Marks JS. The association between adverse childhood experiences and adolescent pregnancy, long-term psychosocial consequences, and fetal death. Pediatrics. 2004 Feb;113(2):320-7.
- Miller ES, Fleming O, Ekpe EE, Grobman WA, Heard-Garris N. Association Between Adverse Childhood Experiences and Adverse Pregnancy Outcomes. Obstetrics & Gynecology . 2021;138(5):770-776. https://doi.org/10.1097/AOG.0000000000004570 .
- Sulaiman S, Premji SS, Tavangar F, et al. Total Adverse Childhood Experiences and Preterm Birth: A Systematic Review. Matern Child Health J . 2021;25(10):1581-1594. https://doi.org/10.1007/s10995-021-03176-6 .
- Ciciolla L, Shreffler KM, Tiemeyer S. Maternal Childhood Adversity as a Risk for Perinatal Complications and NICU Hospitalization. Journal of Pediatric Psychology . 2021;46(7):801-813. https://doi.org/10.1093/jpepsy/jsab027 .
- Mersky JP, Lee CP. Adverse childhood experiences and poor birth outcomes in a diverse, low-income sample. BMC pregnancy and childbirth. 2019;19(1). https://doi.org/10.1186/s12884-019-2560-8 .
- Reid JA, Baglivio MT, Piquero AR, Greenwald MA, Epps N. No youth left behind to human trafficking: Exploring profiles of risk. American journal of orthopsychiatry. 2019;89(6):704.
- Diamond-Welch B, Kosloski AE. Adverse childhood experiences and propensity to participate in the commercialized sex market. Child Abuse & Neglect. 2020 Jun 1;104:104468.
- Shonkoff, J. P., Garner, A. S., Committee on Psychosocial Aspects of Child and Family Health, Committee on Early Childhood, Adoption, and Dependent Care, & Section on Developmental and Behavioral Pediatrics (2012). The lifelong effects of early childhood adversity and toxic stress. Pediatrics, 129(1), e232–e246. https://doi.org/10.1542/peds.2011-2663
- Narayan AJ, Kalstabakken AW, Labella MH, Nerenberg LS, Monn AR, Masten AS. Intergenerational continuity of adverse childhood experiences in homeless families: unpacking exposure to maltreatment versus family dysfunction. Am J Orthopsych. 2017;87(1):3. https://doi.org/10.1037/ort0000133 .
- Schofield TJ, Donnellan MB, Merrick MT, Ports KA, Klevens J, Leeb R. Intergenerational continuity in adverse childhood experiences and rural community environments. Am J Public Health. 2018;108(9):1148-1152. https://doi.org/10.2105/AJPH.2018.304598 .
- Schofield TJ, Lee RD, Merrick MT. Safe, stable, nurturing relationships as a moderator of intergenerational continuity of child maltreatment: a meta-analysis. J Adolesc Health. 2013;53(4 Suppl):S32-38. https://doi.org/10.1016/j.jadohealth.2013.05.004 .
Adverse Childhood Experiences (ACEs)
ACEs can have a tremendous impact on lifelong health and opportunity. CDC works to understand ACEs and prevent them.
IMAGES
VIDEO
COMMENTS
The mean, which is also known as the average, is the total sum of values in a sample divided by the number of values in your sample.[1] For example, to figure out a grade at the end of a course, you calculate the mean of all of your test scores. If you scored a 95%, 90%, 97%, and 92% on tests, your mean test score would be:
The mean tells us that in our sample, participants spent an average of 50 USD on their restaurant bill. Outlier effect on the mean. Outliers are extreme values that differ from most values in the data set. Because all values are used in the calculation of the mean, an outlier can have a dramatic effect on the mean by pulling the mean away from the majority of the values.
The mean is the arithmetic average, and it is probably the measure of central tendency that you are most familiar. Calculating the mean is very simple. You just add up all of the values and divide by the number of observations in your dataset. The calculation of the mean incorporates all values in the data.
Inherent in that choice is the need to identify the specific question being asked and the assumptions associated with the data analysis. The estimate of a "mean" value is an example of a ...
That number, 8.40, is 1 unit of standard deviation. The 68/95/99.7 Rule tells us that standard deviations can be converted to percentages, so that: 68% of scores fall within 1 SD of the mean. 95% of all scores fall within 2 SD of the mean. 99.7% of all scores fall within 3 SD of the mean. For the visual learners, you can put those percentages ...
However, change score analysis has a higher rate of significance than the ANCOVA within both sampling methods. Change score analysis finds significant differences between experimental groups 51.4% of the time when sampling from all-baseline-DBP-levels, and 29.25% of the time when sampling from only hypertensive-at-baseline individuals.
Revised on June 21, 2023. Measures of central tendency help you find the middle, or the average, of a dataset. The 3 most common measures of central tendency are the mode, median, and mean. Mode: the most frequent value. Median: the middle number in an ordered dataset. Mean: the sum of all values divided by the total number of values.
Statistical analysis is an important part of quantitative research. You can use it to test hypotheses and make estimates about populations. ... For example, you can calculate a mean score with quantitative data, but not with categorical data. In a research study, along with measures of your variables of interest, you'll often collect data on ...
Mean: The "average" number; found by adding all data points and dividing by the number of data points. Example: The mean of 4 , 1 , and 7 is ( 4 + 1 + 7) / 3 = 12 / 3 = 4 . Median: The middle number; found by ordering all data points and picking out the one in the middle (or if there are two middle numbers, taking the mean of those two numbers).
Statistical mean is a measure of central tendency and gives us an idea about where the data seems to cluster around. For example, the mean marks obtained by students in a test is required to correctly gauge the performance of a student in that test. If the student scores a low percentage, but is well ahead of the mean, then it means the test is ...
score or a mean-item score. The content of single items (statements) on a Likert scale collectively define, describe, and name the meaning of the construct quantified by the summated score. When reporting research it is appropriate to list the statements that define the unidemensional construct and record
Home Market Research. Mean Scores - tricks and traps. In recent posts, we examined the nature of the data types available to consumer or B2B market researchers including; nominal, ordinal, interval and ratio. The latter two categories allow the user to generate mean score or averages as part of their survey data analysis.
We would like to show you a description here but the site won't allow us.
Mean implies average and it is the sum of a set of data divided by the number of data. Mean can prove to be an effective tool when comparing different sets of data; however this method might be disadvantaged by the impact of extreme values. Mode is the value that appears the most. A given set of data can contain more than one mode, or it can ...
These statistics mean that Carlos's score was 1 standard deviation above the mean whereas Tomoko's score was 0.5 standard deviation above the mean. So, who performed better on the
The mean score statistic is one of the statistics used in the generalized Cochran-Mantel-Haenszel tests . It is applicable when the response levels (columns) are measured at an ordinal scale . If the two variables are independent of each other in all strata, the asymptotic distribution of the mean score statistic is the chi-square distribution ...
Popular answers (1) The higher the mean score the higher the expectation and vice versa. This depends on what is studied.E.g. If mean score for male students in a Mathematics test is less than the ...
Researchers must utilize exploratory data techniques to present findings to a target audience and create appropriate graphs and figures. Researchers can determine if outliers exist, data are missing, and statistical assumptions will be upheld by understanding data. Additionally, it is essential to comprehend these data when describing them in conclusions of a paper, in a meeting with ...
Overview of Rosace framework. Rosace is a Bayesian framework for analyzing growth-based deep mutational scanning data, producing variant-level estimates from sequencing counts. The full (position-aware) method requires as input the raw sequencing counts and the position labels of variants. It outputs the posterior distribution of variants' functional scores, which can be further evaluated to ...
Scores of implicit absenteeism scale, perceived social support scale and occupational coping self-efficacy scale. As shown in Table 2, the average of ICU nurses had a total implicit absenteeism score of (16.87 ± 3.98), indicating that ICU nurses had a high level of implicit absenteeism.. Previous research [] has reported that more than half of nurses have implicit absenteeism and take the ...
A prespecified analysis of the SELECT trial revealed that patients assigned to once-weekly subcutaneous semaglutide 2.4 mg lost significantly more weight than those receiving placebo and showed ...
Abstract. This comparative analysis on the Mean Percentage Scores (MPS) results of senior high school classes for Quarters I, II, and III was a good practice that can be emulated by educators in ...
Previous research has suggested that engaging in regular physical activity (PA) can help to reduce symptoms of depression and anxiety in university students. However, there is a lack of evidence regarding the impact of reducing sedentary behavior (SB) and increasing light-intensity PA (LPA) on these symptoms. This study aims to address this gap by using isotemporal substitution (IS) models to ...
Systematic biases and coarse resolutions are major limitations of current precipitation datasets. Many studies have been conducted for precipitation bias correction and downscaling. However, it is still challenging for the current approaches to handle the complex features of hourly precipitation, resulting in the incapability of reproducing small-scale features, such as extreme events. In this ...
Toxic stress, or extended or prolonged stress, from ACEs can negatively affect children's brain development, immune systems, and stress-response systems. These changes can affect children's attention, decision-making, and learning. 18. Children growing up with toxic stress may have difficulty forming healthy and stable relationships.
To further enhance the precision and the adaptability of path tracking control, and considering that most of the research is focused on front-wheel steering, an adaptive parametric model predictive control (MPC) was proposed for rear-wheel-steering agricultural machinery. Firstly, the kinematic and dynamic models of rear-wheel-steering agricultural machinery were established. Secondly, the ...