
- Text To Speech

What is Text to Speech? (2024 Update)
Text to Speech Explained: A Deep Dive into Voice AI. Understanding Its Technology, Applications, and Future

Gone are the days of robotic voices and limited applications. Today's TTS technology is a dynamic fusion of linguistics and digital innovation, offering a bridge to knowledge and entertainment alike. Whether you're navigating a busy lifestyle or facing reading challenges, TTS can help bring words to life for you.
Let’s dive into text-to-speech technology: what it is, how it works, its use cases in everyday life, and how TTS technology integrates with your favorite applications.
Text-to-Speech: Key Terms
What does ‘text-to-speech technology’ mean.
Text-to-speech (TTS) technology converts written text into spoken words and audio files. This tool is increasingly prevalent in our digital world, offering a new way to access written content.
At its core, text-to-speech is a form of speech synthesis. The process involves generating natural-sounding speech from text. It's a complex interplay of linguistic analysis and digital voice modulation.
For instance, when you ask a digital assistant like Siri to read a message, TTS technology is at work, interpreting the text and producing a response that sounds fluid and similar to a human voice.
Why Is Text-to-Speech Technology Becoming So Popular?
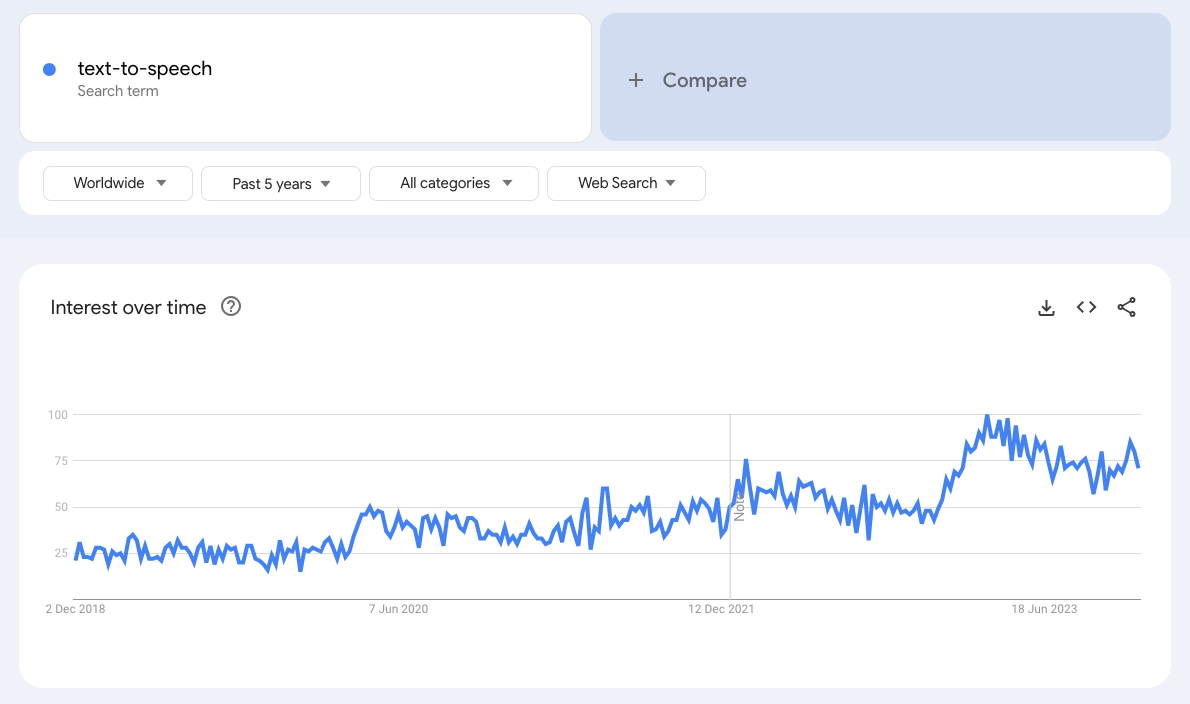
Text-to-speech technology is surging in popularity, with the market set to increase at a CAGR of 30.20% between now and 2029 (growing from $2.06BN in 2021 to $17BN by 2029). What’s more, searches for the term ‘text-to-speech’ have risen dramatically over the past few years as the technology has become more widely available.
This growth is reflective of the increasing integration of TTS in personal and commercial applications, driven by the rising demand for voice-enabled devices and accessibility features.
How Does Text-to-Speech Work?
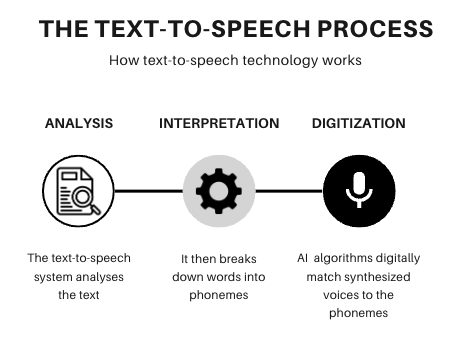
Text-to-speech (TTS) operates on a fundamental premise: converting written language into spoken words. However, the process behind this is intricate.
It starts with analyzing the text. The text-to-speech system breaks down the words into phonemes, the smallest units of sound in a language. This phonetic decoding is crucial for the system to understand how to pronounce different words correctly.
Once the system phonemically interprets the text, the next step involves digitizing this speech. This is where artificial intelligence (AI) plays a significant role. AI algorithms are trained on vast datasets of spoken language, enabling them to generate speech that mimics human tonality and rhythm. This synthesized voice is then matched with the phonemes to produce speech that sounds natural.
Modern TTS systems have advanced significantly, thanks to improvements in AI and machine learning. They can now understand context, manage different languages , and even replicate emotional tones to an extent. This advancement has led to speech outputs that are increasingly human-like, making interactions with digital devices more natural and engaging.
Example of ElevenLabs' Text-to-Speech Voices
How Does Text-to-Speech Technology Increase Accessibility?
By converting text into spoken words, TTS enables better access to written content. This makes content more accessible for individuals with reading difficulties, such as dyslexia, and those with visual impairments.
Users can process information through listening, instead of by reading. Therefore, TTS acts as a bridge to written content, offering an alternative way to access books, documents, and online information.
The quality of the speech output is critical in these applications. High-quality, natural-sounding voices are less straining to listen to and can significantly improve the user experience.
Advancements in TTS technology have led to voices that are more lifelike and less robotic, which is crucial for prolonged listening, as often required in educational settings or daily use.
TTS technology's integration into educational software and e-readers underscores its importance in assistive technology. It not only aids in reading but also in writing, with features like text prediction and speech feedback. These tools empower users, enabling them to engage with written content more confidently and effectively.
What Languages Can Text-to-Speech Technology Handle?
Text-to-speech technology can handle virtually any language, with ElevenLabs’ TTS solution handling 29 of the world’s most popular and widely-spoken languages .
The technology has made significant strides in handling English, which is known for its complexity and nuances. The challenge for TTS systems lies in capturing these subtleties, including varied accents, regional pronunciations, and the language's idiosyncrasies.
However, today’s TTS systems are capable of handling far more than English alone. They can produce high-quality, natural-sounding TTS in various languages, which is a testament to recent advancements in machine learning and artificial intelligence.
Multilingual support in TTS systems is not just about translating text but also about understanding the linguistic characteristics of each language, such as grammar, syntax, and phonetics. The quality of TTS in any language depends on the depth of the dataset it's trained on and the sophistication of the algorithms used.
Which Apps Integrate TTS Technology?
Text-to-speech technology has seamlessly integrated into many of today’s most popular apps. For example, like Alexa. This is a prime example of TTS technology in action.
These devices use TTS to communicate with users, providing information, entertainment, and control over home automation systems through voice commands. The natural-sounding speech output of these devices makes the interaction more engaging and user-friendly.
Similarly, Apple's Siri is another notable application of text-to-speech technology. As an integral part of iOS devices, Siri utilizes TTS to interact with users in a conversational manner. Whether it's setting reminders, answering queries, or providing directions, Siri's ability to convert text-based information into spoken words enhances the user experience.
The widespread integration of TTS in operating systems and devices reflects its growing importance in our daily lives. It's not just a tool for reading text—it's becoming an essential interface for interacting with technology.
From smartphones to smart homes, TTS is enhancing the way we access information and control our devices, making technology more accessible and convenient for everyone.
The Future of Text-to-Speech Technology
The future of text-to-speech (TTS) technology is poised for exciting advancements, driven by ongoing innovations in artificial intelligence (AI) and machine learning. These developments promise to enhance the naturalness and versatility of TTS systems, broadening their applications in our daily lives.
One key area of evolution is the use of advanced AI algorithms. These algorithms are becoming more adept at understanding context, emotion, and subtle language nuances, enabling TTS systems to deliver more expressive and emotionally resonant speech. Such improvements will make interactions with AI assistants and other voice-based technologies more engaging and human-like.
Another significant frontier is the development of application programming interfaces ( APIs ). These APIs allow for easy integration of TTS technology into a wide range of applications, from educational tools to customer service chatbots. This integration capability is vital for customizing TTS solutions to meet specific needs, making the technology more versatile and accessible to developers and end-users.
The integration of TTS into virtual reality (VR) and augmented reality (AR) environments is also an area ripe for exploration. In these immersive spaces, TTS can provide audio cues and narration, enhancing the user experience and making these technologies more accessible to those with visual impairments.
Final Thoughts
Text-to-speech technology has come a long way from its early, robotic-sounding iterations to its current state, where it closely mimics natural human speech. Its impact extends across various sectors, from improving accessibility for those with reading difficulties to enhancing user experience in consumer technology.
As TTS technology continues to evolve, its integration into our daily lives becomes more profound. Its potential goes beyond just reading text aloud—it's about creating more inclusive, efficient, and engaging ways to interact with information and technology. The advancements in AI and machine learning will further refine TTS, making it an even more integral part of our digital future.
In summary, text-to-speech technology is not just a feature of our digital landscape; it's becoming a cornerstone of how we interact with and access information. Its continuous evolution will undoubtedly open new possibilities for accessibility, convenience, and user engagement in the years to come.
How has text-to-speech technology evolved over time?
Text-to-speech technology has evolved significantly from its early days of robotic and monotone outputs. Today, it employs advanced artificial intelligence and machine learning algorithms, enabling it to produce natural-sounding, expressive speech. This evolution has made TTS more user-friendly and versatile, enhancing its application in various fields like education, entertainment, and accessibility.
Can text-to-speech technology effectively replicate emotional speech tones?
Modern text-to-speech systems have made great strides in replicating emotional tones in speech. While still a developing area, these systems use AI to understand the context and inject appropriate emotional inflections, such as excitement, calmness, or urgency. However, replicating the full range of human emotions with precision remains a challenging and ongoing endeavor in AI development.
Is text-to-speech technology limited to certain types of text or formats?
Text-to-speech technology is versatile and can work with a wide range of text types and formats, including digital text from websites, eBooks, and documents. Advanced TTS systems can even handle complex text structures and formats, interpreting and converting them into speech that is coherent and contextually accurate.
How is text-to-speech technology being used in educational settings?
In education, text-to-speech technology is used to support diverse learning needs. It aids students with reading challenges, like dyslexia, and those with visual impairments. TTS enables them to access educational materials through auditory means, facilitating learning and participation. Additionally, it's used in language learning apps and e-learning platforms to provide clear pronunciation examples and make learning more interactive.
What are the potential future developments in text-to-speech technology?
The future of text-to-speech technology includes further improvements in naturalness and expressiveness of speech, better context and emotion understanding, and integration with emerging technologies like augmented reality (AR) and virtual reality (VR). Additionally, we might see advancements in personalized speech patterns, allowing TTS systems to adapt to individual user preferences and speaking styles, enhancing the overall user experience.
Try ElevenLabs today
A Beginner's Guide to Text to Speech

Imagine if you could hear your eBooks out loud. Or, your devices engaging in a conversation with you, responding to your queries, and providing assistance as if you were chatting with a human assistant. That’s the magic of text to speech!
Text to speech isn’t just about transforming written text into spoken words. It represents a transformative bridge between accessibility, convenience, and inclusivity.
Beyond the convenience of having books, webpages, and other written content read aloud, text to speech empowers individuals with visual impairments to access written information in a way that was previously impossible. For those with dyslexia or other reading disabilities, it offers an alternative means to absorb information effortlessly. Moreover, in an increasingly digital and interconnected world, where multitasking has become the norm, these tools enable users to consume content hands-free while engaged in other activities like driving or exercising.
In this blog, we’ll unravel the past, present, and future of text to speech technology together. But, before that……
Table of Contents
What is text to speech, how does text to speech work, the vocoder: the 101 of tts technology, concatenative tts: improvements and building blocks, parametric tts: adding more flexibility, deep neural network (dnn) approach: bringing ai to text to speech, rule-based systems, machine learning, neural networks, accessibility for all, learning and multitasking, productivity in the corporate world, ai text to speech software.
In essence, text to speech is a technology that converts written text into spoken language. It synthesizes speech from written input, allowing users to listen to text content instead of reading it. TTS systems leverage AI and machine learning algorithms to analyze the text and apply linguistic rules, pronunciation dictionaries, and prosody models to generate natural-sounding speech output.
Text to speech can be thought of as a puzzle-building process. You start by inputting text into the software. This text is then broken down into linguistic elements such as words, sentences, and paragraphs to convert them into sound. This sound is known as a phoneme .
The software then begins the assembly process, known as synthesis, piecing together these phonemes to form complete words and sentences.
Finally, the assembled sounds are transformed into a pre-recorded, human-like voiceover. And voila! You’ve successfully converted your text into a voice that sounds natural and realistic.

A Brief History on Text to Speech Technology
The genesis of TTS technology dates back to the 18th and 19th centuries when the earliest attempts were made to create devices capable of mimicking human speech.
The first significant breakthrough came in the mid-20th century with the development of the Vocoder, the pioneering TTS model by John Larry Kelly Jr. and Louis Gerstman.
Introduced around 1961 at Bell Labs, the Vocoder utilized a computer to synthesize the song “Daisy Bell,” offering the world its first glimpse into electronic speech synthesis . Despite the technological breakthrough, the voice generated by the Vocoder was still quite robotic and far from the naturalness of human speech.
Then came one of the early advancements in TTS technology, concatenative TTS in the 1970s. This approach involved amassing a database of short sound samples, which were then manipulated and merged to generate specific sound sequences. The result was audible and intelligible verbal sentences, significantly improving TTS technology.
With further advancements in statistical machine learning, parametric speech synthesis emerged. Unlike Concatenative TTS, which works with fixed sound sequences, parametric TTS utilizes generative models. These models were trained on specific distributions of recorded sound parameters, allowing the TTS to reproduce artificial speech that sounded like an original voice recording. The outcome was a reduced data footprint and increased vocal expression and accent flexibility.
Today’s modern text to speech systems rely on deep neural networks (DNN) to automate smoothing and parameter generation tasks. DNN employs a layered hierarchical framework to transform linguistic text input into its final speech output, mimicking human speech creation. This approach has rapidly become the dominant force in the TTS generation, paving the way for machine-read audiobooks and virtual influencers.
Exploring Different Text to Speech Methodologies
TTS technology has evolved through various stages of development, from the early phonetic synthesizers to modern neural network-based systems. Let’s break them down one by one.
Much like following a recipe while cooking, a ‘Rule-based System’ has a set of instructions (or rules) that it follows in a specific order. These linguistic rules and algorithms are predefined and the system executes actions based on these rules to generate speech output accurately.
These rules define how each phoneme should be pronounced, considering factors such as word structure, syllable stress, and surrounding context. However, there can be exceptions, such as:
Rule-based systems are rigid and can only operate within predefined rules, making them incapable of learning from new data or adapting to unforeseen situations.
As the number of rules increases, the system becomes complex and more demanding to manage, potentially leading to conflicts or inefficiencies.
Moreover, creating and maintaining these rules can be time-consuming.
To address these limitations of rule-based systems, more advanced techniques like machine learning and neural networks have been developed.
Machine learning is like learning to cook by trial and error. Instead of following a fixed recipe, you try different combinations of ingredients and cooking methods and learn from the results.
Machine learning involves training algorithms to recognize patterns and make predictions based on data. In the context of TTS, ML algorithms can be trained on large datasets of text and corresponding speech samples. By analyzing these datasets, ML models learn the relationships between written text and spoken language, allowing them to generate more natural and expressive speech output.
In short, a machine learning model is like a chef who has “tasted” thousands of dishes (read: words and their pronunciations). It learns the patterns and uses this knowledge to “cook up” speech from written text.
Finally, Neural networks are like having a team of chefs in the kitchen. Each chef specializes in a different part of the meal, working together to create the final dish. A neural network learns the mapping between written text and speech features directly from data. They process sequential input (text) and generate sequential output (speech) by leveraging multiple layers of interconnected neurons. Neural network-based TTS models can capture complex patterns in language and produce highly natural and expressive speech output. The result is a realistic, closer-to-human voice.
Benefits of Text to Speech Apps
The advantages of text to speech extend far beyond the confines of conventional text. Join us as we explore the possibilities and advantages of TTS:
TTS is like a personal translator that converts written words into audible speech, making information accessible to those who might otherwise be unable to read it due to visual impairments or dyslexia. Some TTS tools highlight words being spoken, too.
Think of TTS as your personal storyteller. It can read aloud your favorite books, study materials, and more while you multitask, do chores, commute, or just relax. This makes learning more flexible and allows for effective multitasking.
In the corporate world, TTS is like a personal assistant who can read your emails, reports, or any text-based information while you’re occupied with other tasks. It allows you to consume information ‘on-the-go’ and stay updated, enhancing productivity and efficiency.
Today's TTS landscape is bustling with many different TTS tools that harnesses the power of artificial intelligence to transform text into lifelike speech, unlocking a multitude of applications across various industries and domains. From virtual assistants and chatbots to accessibility tools and language learning platforms, these web based tools find extensive utility in a wide range of applications.
Among the various TTS options available, Murf stands out, given its wide range of realistic AI voices , language and accent variety, easy-to-use studio, customization options, and additional voice-related features.
Murf Studio is like a personal narrator that brings your text to life, offering a selection of over 120 high-quality voices across multiple languages and accents. Murf's voices also support a host of customizations, including pitch, speed, pause, emphasis , voice style, and pronunciation . Users can tweak and modify these features to make the AI voice sound the way they want.
Serving as a video maker, Murf allows you to upload images, videos and even presentations to its platform and generate voiceover complementing the visual and sync the two together to create engaging audiovisual content.
Having Murf is like having a professional voice actor and editor by your side, always available and ready to perform adding depth and interest to your content.
In addition to text to speech, Murf also supports voice cloning, AI translation and AI dubbing , making it a one-stop-shop for all voice related applications and content, be it podcasts, videos, audiobooks, ads, YouTube videos or presentations. Try Murf's free trial today to witness the magic of creating voiceovers in seconds.

What Does the Future Hold for Text to Speech?
The future of TTS has so much potential and it’s getting better every day. Here are some amazing developments that are happening with this technology:
Advancements in Neural TTS: Remember those robotic voices that sounded like they had a cold? Well, forget about them. With neural TTS , we will now have computer-generated voices that sound almost human-like. They can talk like we do, with the right tone, pitch, and emphasis. It’s like having a real conversation with a machine. Neural TTS uses deep neural networks to learn from human speech data and generate natural human-like speech from text.
Emotional TTS: Speaking words clearly is not enough; you also need to express emotions. That’s what emotional TTS technology can do. It can add emotions like happiness, sadness, or anger to computer-generated speech, making it more expressive and engaging. Emotional TTS can help create more immersive and realistic experiences for listeners, and used in applications like games, podcasts or even short films.
Singing TTS: Who doesn’t love singing? Well, now you can sing with TTS too! This technology has fantastic potential for the music industry, as it can create original songs, covers, or parodies. Singing TTS can also be used for entertainment, education, or personalization.
As you can see, TTS technology is not just fleeting trend, but a revolution. It is changing the way we communicate, learn, create, and entertain. It is opening new possibilities and opportunities for everyone. It is the future of voice tech!
What is text to speech, and how does it work?
Text to speech is an assistive technology that reads digital text aloud. It converts text into audio by breaking down the input text into phonemes and synthesizing it to form complete words and sentences.
Who benefits from text to speech?
Text to speech can be a beneficial tool for individuals who have reading difficulties, such as those with visual impairments or dyslexia. It’s also advantageous for students, enabling them to listen to their study materials while performing other tasks. Furthermore, it can boost efficiency in the business environment by vocalizing emails, reports, or any text-based data.
How is AI used in text to speech?
Leveraging machine learning algorithms, AI enhances the precision and fluency of synthesized speech. The sophistication of AI-generated voices is continually advancing, providing a diverse array of tones and accents. This progress results in speech output that sounds increasingly natural.
Which algorithm is used in text to speech?
Modern TTS systems use neural TTS, which is a type of TTS that uses deep neural networks to generate speech from text. Neural TTS can produce more natural and human-like voices than traditional TTS methods, which rely on concatenating pre-recorded speech segments or synthesizing speech from acoustic parameters.
What are the applications of text to audio?
Text to speech applications range from elearning modules to audiobooks to podcasts, explainer videos, product demos, advertisements, commercials, and more.
Where is text to speech used?
TTS is compatible with almost all digital devices, such as computers, smartphones, and tablets. It can vocalize various text files, including documents from Word and even online web pages and articles. TTS can also be used in customer service, healthcare, marketing, video production, and more.
What are some of the best text to speech software?
Murf, NaturalReader, Amazon Polly, Play.ht, Voice Dream Reader, Balabolka, and Microsoft Read Aloud are some of the leading text to speech software.
You should also read:

10 Best Free Text to Speech Software of 2024

8 Essential Features Every Good Text to Speech Software Must Have

The Art of Text to Speech Emphasis
A guide to text-to-speech, the popular accessibility feature that lets your computer, phone, or tablet read to you
- Text-to-speech (TTS) is a popular feature that lets your computer or phone read text aloud to you.
- Text-to-speech is commonly used as an accessibility feature to help people who have trouble reading on-screen text, but it's also convenient for those who want to be read to.
- You can find text-to-speech features in many places today, including ebook readers, word processors, internet browsers, and more.
- Visit Business Insider's Tech Reference library for more stories .
Text-to-speech , sometimes abbreviated as TTS, is a feature on your computer or phone that reads on-screen text aloud to you.
Depending on how it's used, text-to-speech can be a convenience feature, or an accessibility feature that helps people who need additional assistance to hear text that's printed on-screen.
Though TTS systems rely on a computerized voice speaking to you, in recent years these voices have become much more natural sounding. Many modern TTS voices are almost indistinguishable from humans, and some even incorporate natural human inflections to make them sound more lifelike.
The most common uses of text-to-speech
Text-to-speech has become so ubiquitous that many people encounter it every day, often without even realizing it. Here are some of the most common examples of TTS in use today.
Smart speakers and virtual assistants
The place we see text-to-speech most often is with smart assistants, like Amazon's Alexa and Apple's Siri.
When you ask these assistants a question, they read to you from a predetermined library of words and phrases. These systems couldn't function without TTS technology.
Ebook Readers
Most popular ebook readers, including all new Kindle Fire devices, have a text-to-speech option. This also includes online readers, like the Internet Archive.
When buying an ebook for your Kindle Fire, you can check whether or not it can be read aloud by looking for the "Text-to-Speech: Enabled" label on its details page before you buy it.
Mapping software
Mapping and navigation apps like Google Maps and Apple Maps are designed to automatically read turn-by-turn directions aloud using text-to-speech technology.
Word processors
Some word processors have the ability to read contents aloud. Microsoft Word, for example, has a "Read Aloud" feature in the "Review" menu. When you select it, Word will read the current document aloud.
Google Docs has its own text-to-speech functions, but you'll need an add-on to use them .
Computer and phone operating systems
No matter what type of computer or smartphone you have, it has accessibility features that can read on-screen elements to you.
In Windows, you can turn on Narrator in the "Ease of Access" settings menu, while Mac users can enable VoiceOver using the "Accessibility" panel.
iPhone users can find VoiceOver in the Accessibility section of Settings. Android users can download a host of TTS apps, or enable the built-in Google Text-to-Speech app through the "Language & Input" menu.
Related coverage from Tech Reference :
How to use text-to-speech on discord, and have the desktop app read your messages aloud, how to use google text-to-speech on your android phone to hear text instead of reading it, how to activate voice controls on your android device, and make google searches or open apps with your voice, how to turn narrator on or off on a windows 10 computer, for an accessibility feature that reads text aloud, how to enable led flash notifications on your iphone, for visual notifications using accessibility features.
- Main content
What’s the Meaning of Text to Speech? The Definitive Guide to TTS
From having content read aloud to smart speakers and voicebots, synthetic speech is everywhere. Learn the meaning of text to speech, plus why TTS matters to businesses.
- Accessibility
- Assistive Technology
- ReadSpeaker News
- Text To Speech
- Voice Branding

Voice technology is changing the way we interact with our devices.
Siri points out your next turn in an unfamiliar town. Google Assistant scours the internet for directions on grilling salmon, and reads them to you while you work. The AI voicebot at the other end of the customer service line gets you results, without waiting or push-button menus. Call it the age of conversational computing—and the computer’s end of these conversations comes courtesy of a digital technology called text to speech, or TTS for short.
But TTS isn’t just for fancy new voice computing applications. For years it’s been used as an accessibility tool; as educational technology (edtech); and as an audio alternative to reading. Over half of U.S. adults have listened to audiobooks, and TTS helped make those experiences possible. All these examples just scratch the surface of what TTS can do, but the details of the technology remain unfamiliar to many.
In this article, we’ll answer the question, “What is TTS?” Then we’ll discuss how individuals and businesses use synthetic voice tools, before concluding with a brief history of the technology.
Table of Contents
Introducing Text to Speech: The Meaning and Science of TTS
Who uses tts understanding tts use cases.
- TTS Technology for Business
- Free TTS Converters Vs. a Professional TTS Service
- Types of TTS Technology, Then and Now
Your definitive introduction to TTS technology starts with a fundamental question:
What is TTS? In other words, what does TTS mean?
Text-to-speech technology is software that takes text as an input and produces audible speech as an output. In other words, it goes from text to speech, making TTS one of the more aptly named technologies of the digital revolution. The software that turns text into speech goes by many names: text-to-speech converter, TTS engine, TTS tool. They all mean the same.
Regardless of what you call it, a full TTS system needs at least two components: the software that predicts the best possible pronunciation of any given text, and a program that produces voice sound waves; that’s called a vocoder.
Text to speech is a multidisciplinary field, requiring detailed knowledge in a variety of sciences. If you wanted to build a TTS system from scratch, you’d have to study the following subjects:
- Linguistics, the scientific study of language. In order to synthesize coherent speech, TTS systems need a way to recognize how written language is pronounced by a human speaker. That requires knowledge of linguistics, down to the level of the phoneme—the units of sound that, combined, make up speech, such as the /c/ sound in cat. To achieve truly lifelike TTS, the system also needs to predict appropriate prosody—that includes elements of speech beyond the phoneme, such as stresses, pauses, and intonation.
- Audio signal processing, the creation and manipulation of digital representations of sound. Audio (speech) signals are electronic representations of sound waves. The speech signal is represented digitally as a sequence of numbers. In the context of TTS, speech scientists use different feature representations that describe discrete aspects of the speech signal, making it possible to train AI models to generate new speech.
- Artificial intelligence, especially deep learning, a type of machine learning that uses a computing architecture called a deep neural network (DNN). A neural network is a computational model inspired by the human brain. It’s made up of complex webs of processors, each of which performs a processing task before sending its output to another processor. A trained DNN learns the best processing pathway to achieve accurate results. This model packs a lot of computing power, making it ideal for handling the huge number of variables required for high-quality speech synthesis.
The speech scientists at ReadSpeaker conduct research and practice in all these fields, continually pushing TTS technology forward. The TTS development team produces lifelike TTS voices for brands, organizations, and application developers, allowing companies to set themselves apart across the Internet of Voice, whether that’s embedded on a smartphone, through smart speakers, or on a voice-enabled mobile app. In fact, TTS voices are emerging in an ever-expanding range of devices, and for a growing number of uses (and users).
People with visual and reading impairments were the early adopters of TTS. It makes sense: TTS eases the internet experience for the 1 out of 5 people who have dyslexia. It also helps low literacy readers and people with learning disabilities by removing the stress of reading and presenting information in an optimal format. We’re progressing toward a more accessible internet of the future, and TTS is an essential part of that movement.
Already, many forward-minded content owners and publishers offer TTS solutions to make the web a place for all. Businesses and buildings are required to provide entryways for wheelchair users and those with limited mobility. Shouldn’t the internet be accessible for everyone, too? Yet, as technology evolves, so have the uses and the users of TTS.
Here are just a few of the populations benefitting from TTS technology already:
1. Students

Every student learns differently. An individual may prefer lessons presented visually, aurally, or through hands-on experience. Many learners retain information best when they see and hear it at once. This is called bimodal learning.
A popular education framework called Universal Design for Learning (UDL) recommends bimodal learning to help every student be successful. Teachers of all grade levels who promote UDL use a combination of auditory, visual, and kinesthetic techniques with the help of technology and adaptable lesson plans.
Even if you identify as a kinesthetic or visual learner, science says adding an auditory method may help you retain information. And if nothing else, TTS makes proofreading a lot more manageable.
2. Readers on the Go
When you want to catch up on the news, podcasts and audiobooks only take you so far. So, if there’s an in-depth profile in The New Yorker or a longform article from The Guardian that you want to read, TTS can read it to you. That frees you up to drive, exercise, or clean at the same time. Or you may just prefer listening over reading.
3. Multitaskers
The shortcuts TTS can provide are endless—from reading recipes while you cook to dictating instruction manuals when assembling furniture. The only limit to how much it can help is your own imagination.
4. Mature Readers
Understandably, older adults may want to avoid straining their eyes to read the tiny text on a smartphone. Text to speech can alleviate this issue, making online content easy to consume regardless of your skill with technology or the state of your vision.
5. Younger Generations
Offer technology to young people, and they’re likely to use it—whether it’s strictly “necessary” for them or not. In 2022, 70% of 18 to -25-year-old consumers turned on subtitles while viewing video content “most of the time,” not because they had hearing impairments, but because it was convenient. And so many Tik Tok users took advantage of the app’s TTS feature that rival Instagram rolled out their TTS in 2021.
Meanwhile, a survey of college undergraduates found that only 5% of respondents had a disability necessitating the use of assistive technology—but at least 18% of the students considered each technology “necessary.” The point is, Generation Z uses TTS not just as an accessibility tool, but as a preference.
6. Readers With Visual Impairments or Light Sensitivity
Older adults aren’t the only ones who want to avoid straining their eyes on screens. Many people have mild visual impairments or suffer from sensitivity to light. Think of people with chronic migraines, for instance. Thanks to TTS, these users can be more productive on days when staring at screens seems like a pain too much to bear.
In fact, medical studies show that exposure to light at night, particularly blue light from screens, has adverse health effects. It not only disrupts our biological clocks, but it may increase the risk of cancer, diabetes, heart disease, and obesity rates. Text to speech offers users a safer way to consume written content, without staring at a screen.
7. Foreign Language Students
Studies show that listening to a different language aids students in learning the new dialect. Text to speech can help with that. ReadSpeaker is an international TTS software company, featuring over 50 languages and more than 150 voices, all based on native speakers.
With ReadSpeaker, foreign language students can get a feel for pronunciation, cadence, and accents. One feature that’s especially helpful in this regard is the ability to have words highlighted as they’re read aloud, which can help students feel confident in their pronunciation of new vocabulary.
8. Multilingual Readers
New generations raised in multilingual households may understand their parent’s language, but they may not feel fluent enough to read, write, or speak it. This is common in many communities, where the home language is not studied in school. For second and third generations who want to maintain or strengthen their bonds to their mother lands, ReadSpeaker can make articles, newspapers, and other literature accessible and understandable through speech.
9. People With Severe Speech Impairments
A speech-generating device (SGD), also known as a voice output communication aid (VOCA), is useful for those who have severe speech impairments and who would otherwise not be able to communicate verbally. Grouped under the term “augmentative and alternative communication (AAC),” SGDs and VOCAs can now be integrated into mobile devices such as smartphones.
Stephen Hawking, who suffered from ALS, and also renowned film critic Roger Ebert were among the most well-known users of SGDs using TTS technology.
So, who uses TTS? Many people, for many different reasons. And if you’re looking for a way to solve today’s business challenges, TTS may be the technology you need.
To learn more about ReadSpeaker’s TTS services, check out our FAQ.

Exploring TTS Use Cases
When ReadSpeaker first began synthesizing speech in 1999, TTS was primarily used as an accessibility tool. Text to speech makes written content across platforms available to people with visual impairments, low literacy, cognitive disabilities, and other barriers to access. And while accessibility remains a core value of ReadSpeaker’s solutions, the rise of voice computing has led to an ever-growing range of applications for TTS across devices, especially in business.
Here are just a few of the powerful corporate use cases for TTS in today’s voice-first world:

- Conversational interactive voice response (IVR) systems, as in customer service call centers
- Voice commerce applications, such as shopping on an Amazon Alexa device
- Voice guidance and navigation tools, like GPS mapping apps
- Smart home devices and other voice-enabled Internet of Things (IoT) tools
- Independent virtual assistants like Apple’s Siri, but for your own brand
- Experiential marketing and advertising solutions, like interactive voice ads on music streaming services or branded smart speaker apps
- Video game development, with dynamic runtime TTS for accessibility features, scene prototyping, and AI non-player characters
- Training and marketing videos that allow creators to change voice-overs without tracking down original voice talent for ongoing recording sessions
- Public transportation systems, including passenger information systems, self-service kiosks, and customer service voicebots
- Fintech, such as virtual banking assistants
- Media production, from podcasts to audiobooks to voiceovers
It’s easy to make a business case for TTS in any of these areas. Text to speech can unlock powerful customer experiences, which translate into rapid returns on your technology investment.
Of course, there are plenty of TTS converters. Why pay for something you can get for free? It turns out there are lots of reasons. Let’s explore just a few.

Free TTS Converters: Why You Should Avoid Them Altogether
If you’re using TTS to meet business goals, a free text-to-speech converter probably isn’t the best choice. That’s true for any of the use cases we discussed in the previous section, but it’s equally true for any commercial project.
How do you know if your project counts as “commercial?”
Just ask one question: Does the offering make you money? If the answer is yes, it’s commercial, and requires a similarly commercial approach to synthesizing speech. That could be adding TTS to a voice-controlled device, building a voicebot, or even adding voice overs to YouTube videos, if they’re ad-supported.
Here’s why commercial users can’t rely on free TTS—and why they should depend on a proven TTS provider like ReadSpeaker, which has been at the forefront of the industry for more than two decades.
1. Professional TTS protects against legal problems.
Most free TTS converters don’t grant commercial licenses. Even if they do, you can’t be sure they have permission from everyone in the voice’s custody chain—a line of stakeholders that stretches all the way back to the recording booth. You see, TTS voices aren’t just lines of code; they all start with a voice actor, whose speech recordings are used to create the synthetic TTS voice that reads your text aloud.
Voice actors have contracts that give them certain rights over how their voices are used, and those rights can create serious liabilities for TTS users, even years down the line. For a high-profile example, just look at TikTok. When the social media app rolled out its TTS feature, it quickly went viral—until Bev Standing, the voice actor from whom the TTS voice was sourced, sued for unlicensed use of her voice. TikTok settled with Standing for an undisclosed amount in 2021.
ReadSpeaker grants commercial licenses and creates all its voices in-house. That allows us to control permissions from the voice actor through to the end user, with documentation at every step of the way.
2. Paid TTS companies provide higher-quality audio.
Professional TTS voices sound better. At ReadSpeaker, we create advanced TTS voices with proprietary deep neural networks, and our team of speech scientists focus on the pronunciation accuracy of every voice before rollout. The result is natural, lifelike machine speech that leads to a measurably better user experience.
But the quality of the TTS voice itself isn’t the only consideration in great-sounding synthetic speech. There’s also the quality of the sound signal itself. ReadSpeaker’s TTS engines allow users to control bit rate and frequency, balancing sound fidelity with bandwidth requirements for each specific use case. That’s an option that’s rarely available from free online TTS converters.
3. Free TTS services are more prone to mispronunciation.
Language is full of tricky pronunciation problems, particularly for computers. How can a TTS engine differentiate between “lead,” as in to lead the way, and “lead,” as in a lead pipe? ReadSpeaker’s TTS engines examine the context of the word, looking at the surrounding language and testing it against a database of common usages. That allows the software to choose the accurate pronunciation in most circumstances. Free TTS converters are unlikely to include an advanced feature like this.
Then there are proper names, industry jargon, new acronyms, and more. ReadSpeaker’s speech scientists continually update a central pronunciation dictionary to keep our products’ speech accurate. Users themselves can create their own TTS pronunciation dictionaries, spelling correct pronunciation phonetically in a simple process with a complicated name: orthographic transcription. That allows commercial users to avoid embarrassments like voicebots that mispronounce their own company names, key industry terms, and more.
Commercial TTS With Custom AI Voices From ReadSpeaker
If you’re concerned about any of these issues, a free TTS converter probably isn’t for you. But there’s another reason companies should choose an established TTS leader like ReadSpeaker: to preserve your brand in voice channels.
A custom TTS voice creates a consistent customer experience across channels, strengthening relationships over time.
A unique TTS voice also differentiates your brand from other companies. Lots of brands use Amazon’s Alexa voice on their smart speaker apps; that makes users think of Amazon, not the brand. Free TTS voices—and most paid ones—may speak for any number of users, including, perhaps, your competitors. An original branded TTS voice sets you apart. Think of it as a sonic logo.
Want to learn more about custom TTS voices and the benefits of this advanced technology? Contact ReadSpeaker today.
So far, we’ve covered a general explanation of TTS, introduced a few common TTS users, and discussed the technology’s implications for business. But no introduction to voice technology is complete without a quick history lesson—or a rundown of the major categories of synthetic speech.

TTS Then and Now
Mechanical attempts at synthetic speech date back to the 18th century. Electrical synthetic speech has been around since Homer Dudley’s Voder of the 1930s. But the first system to go straight from text to speech in the English language arrived in 1968, and was designed by Noriko Umeda and a team from Japan’s Electrotechnical Laboratory.
Since then, researchers have come up with a cascade of new TTS technologies, each of which operates in its own distinct way. Here’s a brief overview of the dominant forms of TTS, past and present, from the earliest experiments to the latest AI capabilities.
Formant Synthesis and Articulatory Synthesis
Early TTS systems used rule-based technologies such as formant synthesis and articulatory synthesis, which achieved a similar result through slightly different strategies. Pioneering researchers recorded a speaker and extracted acoustic features from that recorded speech—formants, defining qualities of speech sounds, in formant synthesis, and manner of articulation (nasal, plosive, vowel, etc.) in articulatory synthesis. Then they’d program rules that recreated those parameters with a digital audio signal.
This TTS was quite robotic; these approaches necessarily abstract away a lot of the variation you’ll find in human speech—things like pitch variation and stresses—because they only allow programmers to write rules for a few parameters at a time. But formant synthesis isn’t just a historical novelty: it’s still used in the open-source TTS synthesizer eSpeak NG, which synthesizes speech for NVDA, one of the leading free screen readers for Windows.
Diphone Synthesis
The next big development in TTS technology is called diphone synthesis, which researchers initiated in the 1970s and was still in popular usage around the turn of the millennium. Diphone synthesis creates machine speech by blending diphones, single-unit combinations of phonemes and the transitions from one phoneme to the next: not just the /c/ in the word cat, but the /c/ plus half of the following /ae/ sound. Researchers record between 3,000 and 5,000 individual diphones, which the system sews together into a coherent utterance.
Diphone synthesis TTS technology also includes software models that predict the duration and pitch of each diphone for the given input. With these two systems layered on one another, the system pastes diphone signals together, then processes the signal to correct pitch and duration. The end result is more natural-sounding synthetic speech than formant synthesis creates—but it’s still far from perfect, and listeners can easily differentiate a human speaker from this synthetic speech.
Unit Selection Synthesis
By the 1990s, a new form of TTS technology was taking over: unit selection synthesis, which is still ideal for low-footprint TTS engines today. Where diphone synthesis added appropriate duration and pitch through a second processing system, unit selection synthesis omits that step: It starts with a large database of recorded speech—around 20 hours or more—and selects the sound fragments that already have the duration and pitch the text input requires for natural-sounding speech.
Unit selection synthesis provides human-like speech without a lot of signal modification, but it’s still identifiably artificial. Meanwhile, throughout all these decades of development, computer processing power and available data storage were making rapid gains. The stage was set for the next era in TTS technology, which, like so much of our current era of computing, relies on artificial intelligence to perform incredible feats of prediction.
Neural Synthesis
Remember the deep neural networks we mentioned earlier? That’s the technology that drives today’s advances in TTS technology, and it’s key to the lifelike results that are now possible. Like its predecessors, neural TTS starts with voice recordings. That’s one input. The other is text, the written script your source voice talent used to create those recordings. Feed these inputs into a deep neural network and it will learn the best possible mapping between one bit of text and the associated acoustic features.
Once the model is trained, it will be able to predict realistic sound for new texts: With a trained neural TTS model—along with a vocoder trained on the same data—the system can produce speech that’s remarkably similar to the source voice talent’s when exposed to virtually any new text. That similarity between source and output is why neural TTS is sometimes called “ voice cloning. ”
There are all sorts of signal processing tricks you can use to alter the resulting synthetic voice so that it’s not exactly like the source speaker; the key fact to remember is that the best AI-generated TTS voices still start with a human speaker—and TTS technology is only getting more human. Current research is leading to TTS voices that speak with emotional expression, single voices in multiple languages, and ever more lifelike audio quality. Explore the languages and voices available with ReadSpeaker TTS.
The science of TTS continues to advance (and ReadSpeaker’s speech scientists are helping to push it forward). That means there’s always more to learn about TTS—but hopefully we’ve covered the basic text-to-speech meaning and then some in this article. And if you still have questions, follow the links below.

ReadSpeaker’s industry-leading voice expertise leveraged by leading Italian newspaper to enhance the reader experience Milan, Italy. – 19 October, 2023 – ReadSpeaker, the most trusted,…

Accessibility overlays have gotten a lot of bad press, much of it deserved. So what can you do to improve web accessibility? Find out here.

The loss of the AccessText Network has the higher education industry scrambling. Get the story, plus some tips for coping, here.
- ReadSpeaker webReader
- ReadSpeaker docReader
- ReadSpeaker TextAid
- Assessments
- Text to Speech for K12
- Higher Education
- Corporate Learning
- Learning Management Systems
- Custom Text-To-Speech (TTS) Voices
- Voice Cloning Software
- Text-To-Speech (TTS) Voices
- ReadSpeaker speechMaker Desktop
- ReadSpeaker speechMaker
- ReadSpeaker speechCloud API
- ReadSpeaker speechEngine SAPI
- ReadSpeaker speechServer
- ReadSpeaker speechServer MRCP
- ReadSpeaker speechEngine SDK
- ReadSpeaker speechEngine SDK Embedded
- Automotive Applications
- Conversational AI
- Entertainment
- Experiential Marketing
- Guidance & Navigation
- Smart Home Devices
- Transportation
- Virtual Assistant Persona
- Voice Commerce
- Customer Stories & e-Books
- About ReadSpeaker
- TTS Languages and Voices
- The Top 10 Benefits of Text to Speech for Businesses
- Learning Library
- e-Learning Voices: Text to Speech or Voice Actors?
- TTS Talks & Webinars
Make your products more engaging with our voice solutions.
- Solutions ReadSpeaker Online ReadSpeaker webReader ReadSpeaker docReader ReadSpeaker TextAid ReadSpeaker Learning Education Assessments Text to Speech for K12 Higher Education Corporate Learning Learning Management Systems ReadSpeaker Enterprise AI Voice Generator Custom Text-To-Speech (TTS) Voices Voice Cloning Software Text-To-Speech (TTS) Voices ReadSpeaker speechCloud API ReadSpeaker speechEngine SAPI ReadSpeaker speechServer ReadSpeaker speechServer MRCP ReadSpeaker speechEngine SDK ReadSpeaker speechEngine SDK Embedded
- Applications Accessibility Automotive Applications Conversational AI Education Entertainment Experiential Marketing Fintech Gaming Government Guidance & Navigation Healthcare Media Publishing Smart Home Devices Transportation Virtual Assistant Persona Voice Commerce
- Resources Resources TTS Languages and Voices Learning Library TTS Talks and Webinars About ReadSpeaker Careers Support Blog The Top 10 Benefits of Text to Speech for Businesses e-Learning Voices: Text to Speech or Voice Actors?
- Get started
Search on ReadSpeaker.com ...
All languages.
- Norsk Bokmål
- Latviešu valoda

The 7 Best Text-to-Speech Apps for Android
Text-to-speech is a handy feature on your Android phone even if you don't have a disability. These text-to-speech apps take it to the next level.
Every Android user should keep a text-to-speech app handy. You don't need to have a vision impairment to enjoy the benefits. For example, they'll let you listen to the news on your morning commute, catch up with new text messages in bed, or even enjoy your favorite eBooks without looking at the screen.
But which Android text-to-speech apps are the best? Keep reading to find out.
1. Android's Native Text-to-Speech Feature
Android has lots of accessibility tools that make a phone easier to use. One of the tools is a native text-to-speech function. The feature has fewer customizable settings than some of its competitors, but you can adjust the speech rate and pitch and install additional languages.
To change the text-to-speech settings, head to Settings > Accessibility > Text-to-speech output .
Android's text-to-speech feature automatically works with other Google apps that offer a read-aloud feature. For all other apps, you'll need to enable Select to Speak in Android's settings menu, which you'll find at Settings > Accessibility > Select to Speak . To use it, select text in any app and choose Speak from the popup menu.
If you only want basic text-to-speech functionality, you can stop here. The other options are only worth exploring if you need more features.
2. Voice Aloud Reader
Voice Aloud Reader is easy to use and supports a few different ways of reading text. If the app from which you want to read text has a share feature, just send the content to Voice Aloud Reader using the native Android Share menu . This also works for on-screen items that have their own share buttons, like tweets and Facebook posts.
Similarly, if the text you want to read is selectable, you can use the Share button in the popup context menu.
The app also works with URLs. Just paste the site's (or article's) address into Voice Aloud Reader, and it will automatically parse and read the relevant text for you. It's intelligent enough to strip out the menus and other junk. You can even add text files (like DOC and PDF) directly into the app; it can open the files and read their contents.
Download: Voice Aloud Reader (Free)
3. Narrator's Voice
Narrator's Voice offers something a bit different. The usual features are here: it is an app that reads text from apps, the web, messages, and other sources.
However, the app also has a fun side. You can add various sound effects to the speech synthesis, such as echo, reverb, gargle, and choir. It features a wide selection of voices to choose from. Some tech favorites like Cortana and Siri are present, as are some of the developer's own creations like "Steven" and "Pink Sheep" (don't ask).
Additionally, Narrator's Voice lets you add your own text, which it will then run through its synthesizer. It makes the app a great way to add a voiceover to video narrations, slideshow presentations, and more. You can even save your audio output file as an MP3, store it offline, and share it with friends.
An in-app purchase removes the ads.
Download: Narrator's Voice (Free, in-app purchases available)
Talk takes a more minimal approach than Voice Aloud Reader and Narrator's Voice, but it is still one of the best free text-to-speech apps for Android. The app can import web pages directly from your phone's browser or read the text from other third-party apps. You can export all the audio files and save them offline in the WAV format.
It's important to note that Talk Free relies on your phone's pre-existing text-to-speech (TTS) engine to work. Most Android devices will already have Google's engine installed. If you have deleted your phone's TTS engine, you can re-download Speech Recognition & Synthesis free from the Play Store.
The benefit of using Google's TTS engine is its support for lots of languages. If Google offers the language, Talk can generally work with it.
Download: Talk (Free)
T2S is a text-to-speech app that offers one of the most modern interfaces out of the apps we've discussed so far.
The app's standout feature is the presence of a simple built-in web browser. It's not going to win any awards for the number of features it offers, but it lets you easily listen to web pages without worrying about copying and pasting URLs or using the Share menu.
T2S's copy-to-speak feature is also worth mentioning. It shows an on-screen popup button whenever you copy text into other apps. Pressing the button will make the app start reading the copied text instantly. As with the other apps on this list, T2S lets you save your audio readouts and share them with other people. The pro version removes ads.
Download: T2S (Free, in-app purchases available)
6. NaturalReader
With AI being all the buzz, we ought to include an AI-powered solution to this list. NaturalReader offers almost 150 AI voices in different languages and over 25 dialects so that you can customize your text-to-speech experience to your liking.
The app can run in the background, so you can use other apps while listening to content. Moreover, it supports over 20 document formats, including PDF, DOCX, and eBook formats.
Other than the usual text-to-speech features, you can also use NaturalReader to detect and read text from images. This feature can come in super handy if you deal with a lot of scanned documents.
This feature is not perfect yet, but it works. If you're not satisfied with the built-in image-to-text functionality, you can convert images to text using OCR apps and then use NaturalReader for text-to-speech.
Download: NaturalReader (Free, in-app purchases available)
We'll leave you with a slightly left-field choice: Pocket. You probably already know it as one of the best apps to save articles to read later when you're offline.
You may not know, however, that Pocket also has a text-to-speech reader. The feature supports multiple voices and languages and includes adjustable pitch and speed. It even supports background playback, meaning you can keep listening while you use other apps.
Because the text-to-speech reader is one of Pocket's native features, it's great when you want to listen to some long-form content on a journey when you are without the internet. Obviously, if you want to listen to text from all your apps, this isn't the right choice for you.
Download: Pocket (Free, premium version available)
The Top Text-to-Voice Apps
Hopefully, you now appreciate the benefits of keeping a text-to-speech app installed on your Android device. Once you become more familiar with their use, you'll start to rely on the apps a lot more. Don't believe us? Try a couple, stick with them for a week or two, and thank us later!
There's also an opposite way of communicating with your Android device, that is, speech-to-text. Such apps are particularly great for note-taking.

Speech Recognition & Synthesis

About this app
Data safety.

Ratings and reviews

- Flag inappropriate

- Show review history
What's new
App support, more by google llc.

Similar apps

- Contact Sales

What is speech-to-text?

Speech-to-text, or automatic speech recognition (ASR), technology has been around for a while, but it is only recently that it has gained widespread adoption. ASR allows users to speak commands and control their devices using their voice, making it a popular choice for virtual assistants, captioning and transcription, customer service, education, medical documentation, and legal documentation. According to Forrester's survey , many information workers in North America and Europe use voice commands on their smartphones at least occasionally, with the most common use being texting (56%), searching (46%), and navigation/directions (40%). However, there are still challenges that need to be addressed in order for this technology to reach its full potential.
In this article, we will explore the different methods of speech-to-text and how it is used in various applications, including transcription services, voice recognition software, and accessibility tools. We'll also take a look at the future of speech-to-text and see how this technology is likely to continue to improve and expand in the coming years. So, let's dive in and see what makes speech-to-text such a powerful tool for businesses and individuals alike.
How speech-to-text technology works
Speech-to-text technology is a type of natural language processing (NLP) that converts spoken words into written text. It is used in a variety of applications, including voice assistants, transcription services, and accessibility tools. Here is a more detailed explanation of how speech-to-text technology works:
Sound conversion
The first challenge in speech-to-text technology is that sound is analog, while computers can only understand digital inputs. To convert sound into a digital format that computers can understand, a microphone is used. The microphone converts sound waves into an electrical current, which is then converted into voltage and read by a computer.
Frequency isolation
The next step in the process is to isolate individual frequencies from the sound input. This is done using a technique called Fast Fourier Transform (FFT), which converts the sound input into a spectrogram. A spectrogram is a visual representation of sound, with time on the X-axis, frequencies on the Y-axis, and intensity represented by brightness.

Phoneme recognition
It’s the process of identifying the basic building blocks of speech, known as phonemes. This is a crucial step in speech-to-text technology because phonemes are the foundation upon which words are built. There are several different approaches to phoneme recognition, including statistical models like the hidden Markov model and machine learning systems like neural networks.
Neural networks are a type of machine learning system that is made up of interconnected nodes that can adjust their weights based on feedback. A neural network consists of layers of nodes that are organized into an input layer, an output layer, and one or more hidden layers. The input layer receives data, the hidden layers perform transformations on the data, and the output layer produces the final result. Every time the neural network receives feedback, it adjusts the weights of the connections between the nodes to improve its performance.
One advantage of neural networks is that they can adapt to large variations in speech, such as different accents and mispronunciations. However, they do require a large amount of data to be set up and trained, which may be a limitation for some applications. In contrast, statistical models like the hidden Markov model are less data-hungry, but they are unable to adapt to large variations in speech. As a result, it is common to use both types of models in speech-to-text technology, with the hidden Markov model being used to handle basic phoneme recognition and the neural network handling more complex tasks.
Word analysis
It’s the process of analyzing the sequence of phonemes that make up a word in order to identify the intended meaning. This is done using either a language or an acoustic model.
The language model takes into account the context of the word, as well as the frequency of different phoneme combinations in the language being used. For example, in English, the phoneme "m" is never followed by an "s." Therefore, if the language model encounters the sequence "ms," it will consider it to be an error and attempt to correct it based on the context and the likelihood of different phoneme combinations.
The language model is an important part of speech-to-text technology because it allows the system to understand the meaning of words and sentences. By analyzing the sequence of phonemes and taking into account the context, the language model can determine the intended meaning of spoken words and produce the corresponding written text.
The acoustic model is a statistical model that maps the acoustic features of speech to the corresponding words or phonemes. The acoustic model is trained on a large dataset of audio recordings and the corresponding transcriptions, and it uses this data to learn the patterns and features that are characteristic of the language being used.
During the STT process, the audio input is analyzed by the acoustic model, which produces a sequence of probability scores for each possible word or phoneme. The sequence of scores is then fed into a language model, which takes into account the context and the likelihood of different word combinations to produce the final transcription.
There are several different types of acoustic models, including hidden Markov models (HMMs) and deep neural networks (DNNs). HMMs are statistical model that consists of states and corresponding evidence, and they are commonly used for speech recognition because they are computationally efficient and relatively easy to train. DNNs are a type of machine learning model that consists of layers of interconnected nodes, and they are able to adapt to large variations in speech. DNNs are more data-hungry and require more computational resources to train, but they tend to perform better than HMMs on many speech recognition tasks.
Which model is better or more common for a given language depends on a variety of factors, including the complexity of the language, the amount of data available for training, and the resources available for training and running the model. In general, DNNs tend to perform better on a wide range of tasks, but they may not be the best choice for all languages or situations.
Final transcript
Text output is the final step in converting spoken words or text from one language to another using speech-to-text technology. It involves displaying the translated text on a screen or saving it to a file.
What are STT APIs and their advantages?
API (Application Programming Interface) is a set of rules and protocols that allows different software systems to communicate with each other. In the context of speech-to-text applications, an API is a set of programming instructions that allows developers to access and use the STT capabilities of a service or platform in their own applications.
There are several different types of voice recognition APIs available, including cloud-based APIs and on-premises APIs. Cloud-based APIs are hosted by a third-party provider and accessed over the internet, while on-premises APIs are installed on a local server and accessed within an organization's network.
Speech-to-text APIs offer plenty of advantages for individuals and businesses:
Increased productivity : Allows users to input text quickly and efficiently using their voice, rather than typing on a keyboard or touchpad. This can save time and increase productivity, especially for tasks that involve a lot of text input.
Improved accessibility : Can be used to provide accessibility features such as live captions and subtitles, which can be helpful for individuals with hearing impairments or learning disabilities.
Enhanced customer experience : Speech-to-text applications can provide various manipulations with recognized and transcribed text, for example, summarization . By getting a quick summary of customer feedback businesses can identify common issues, for example.
Greater flexibility : STT APIs can be accessed from any device with an internet connection, allowing users to input text using their voice from anywhere.
Cost savings : One of the major benefits for businesses is cost savings. By automating text input tasks, businesses can reduce or eliminate the need for manual transcription services, which can be costly and time-consuming. Additionally, it can help businesses streamline their processes and increase efficiency.
Improved accuracy : Advanced natural language processing algorithms have a high level of accuracy in transcribing spoken words, which can help reduce errors and improve the quality of the resulting text.
Best speech-to-text API applications
There are many speech-to-text (STT) application programming interfaces (APIs) available on the market, and the best one for you will depend on your specific needs and preferences. Here are some popular STT APIs that are widely used and well-regarded by experts:
- Google Cloud Speech-to-Text API : Use a powerful API to convert speeches into texts accurately with the help of Google Cloud’s Speech-to-Text solution known for its high accuracy and wide range of customization options. It offers an excellent user experience by transcribing your speech with accurate captions.
- IBM Watson Speech to Text API : IBM Watson Speech to Text offers AI-powered transcription and speech recognition solutions. It enables accurate and fast speech recognition in different languages for various use cases, such as customer self-service, speech analytics, agent assistance, and more.
- Microsoft Azure Speech Services : Use a powerful API to convert speeches into texts accurately with the help of Google Cloud’s Speech-to-Text solution. It offers an excellent user experience by transcribing your speech with accurate captions. It also helps improve your services through the insights taken and transcribed from your customer interactions.
- Amazon Transcribe : Amazon Transcribe is a big cloud-based automatic speech recognition platform developed specifically to convert audio to text for apps. It is available for use on a variety of platforms, including Windows, Mac, and mobile devices.
- OneAI is a language AI service that offers product-ready APIs and pre-trained models for developers. It allows developers to access speech-to-text and audio-intelligence capabilities in a single API call, enabling them to process audio and video into structured data for various purposes such as generating summaries and transcripts, and detecting sentiments and topics.
Use cases of speech-to-text applications
There are many potential use cases for speech-to-text technology. Some of the most common use cases include:
Automated dictation
If you're a content creator, writer, or anyone who needs to type long-form text, STT APIs can be a huge help. You can dictate your words and produce written text, saving time and effort.
Voice control
Speech-to-text can be used to enable voice control of various applications, such as virtual assistants or smart home devices. By issuing voice commands, users can easily interact with these devices and perform a wide range of tasks without having to type or use other input methods.
Medical transcription
In the medical field, this technology can be used to transcribe medical reports, notes, and other documents. This can help to reduce the workload for medical professionals and improve the accuracy of patient records
Translation
You can translate spoken words into different languages, which can be particularly useful for people who are traveling or working with people who speak different languages.
Voice biometrics
It’s the process of verifying the identity of a user based on their voice and also can be a task for voice recognition applications. This can be used to enable secure authentication for applications such as banking or online services.
Students with learning disabilities or language barriers can use the benefits of STT applications by getting real-time transcriptions of lectures or other educational materials. This can make learning more accessible and inclusive for all students.
Emotion recognition
Speech-to-text can also be used to analyze certain vocal characteristics to determine what emotion the speaker is feeling. Paired with sentiment analysis, this can reveal how someone feels about a product or service.
Limitations and future of speech-to-text
Like all technology, speech-to-text technology has its limitations. Some of the main limitations include:
Accurate transcription relies on clear speech : voice recognition systems are more likely to produce accurate transcriptions when the spoken words are clear and easily understood. If the speech is distorted or difficult to understand, the accuracy of the transcription may suffer.
Accents and dialects : Voice recognition systems are typically trained on a particular accent or dialect of a language. If the speaker has a different accent or dialect, the accuracy of the transcription may be lower.
Problems with context understanding : STT systems may struggle to understand the context in which words are being used, which can lead to incorrect transcriptions or translations.
Significant computing resources are required : Developing and maintaining voice recognition systems can be resource-intensive, as they require large amounts of data and computing power to train and operate.
Despite these limitations, the future of this technology looks bright. The speech-to-text industry has seen significant growth in recent years, with the global market value expected to reach $28.1 billion by 2027. The increased demand for this technology has led to the development of advanced capabilities such as punctuation, speaker diarization, global language packs, and entity formatting. One major breakthrough in the industry is the introduction of self-supervised learning, which allows STT engines to learn from unstructured data on the internet, giving them access to a wider range of voices and dialects and reducing the need for human supervision.
Universal availability will make ASR accessible to everyone, while the collaboration between humans and machines will allow for the organic learning of new words and speech styles. Finally, responsible AI principles will ensure that ASR operates without bias.
Speech-to-text technology has come a long way in recent years, and its capabilities continue to expand with the development of self-supervised learning and the integration of natural language understanding (NLU) . These advancements have enabled speech-to-text systems to learn from a wide range of unstructured data and improve their accuracy in a variety of languages and accents. As a result, STT technology is being utilized in an increasingly diverse range of industries, from healthcare and finance to communications and customer service.
OneAI creates 93% accurate speech-to-text transcriptions and suggests a wide range of Language Skills (use-case ready, vertically pre-trained models) like summarization , proofreading , sentiment analysis , and many more. Just check our Language Studio and pick those which will increase the efficiency of your business.
TURN YOUR C o NTENT INTO A GPT AGENT

Revoicer AI 17+
Voice changer clone, islam temirbek, designed for ipad.
- 4.7 • 3 Ratings
Screenshots
Description.
Experience the extraordinary with Revoicer AI, the groundbreaking text-to-speech app revolutionizing communication. Unlock the future of voiceovers with our cutting-edge cloning technology, seamlessly transforming your voice into captivating narratives. From written words to compelling spoken stories, our Text2Speech Magic offers unmatched clarity and emotion, elevating your message like never before. Don't miss out on the forefront of voice technology! Download Revoicer AI, developed by Eleven Labs, and embark on a journey of text-to-speech mastery, voice cloning, dictation, and beyond. Elevate your voice with Revoicer AI – where your words come alive and explore new horizons in the world of TTS and voiceovers!
Version 1.0.1
App Version 1.0.1 is Out We're excited to bring you the latest update with new features, improvements, and bug fixes.
Ratings and Reviews
App privacy.
The developer, Islam Temirbek , indicated that the app’s privacy practices may include handling of data as described below. For more information, see the developer’s privacy policy .
Data Not Collected
The developer does not collect any data from this app.
Privacy practices may vary, for example, based on the features you use or your age. Learn More
Information
English, Arabic, Bulgarian, Croatian, Czech, Danish, Dutch, Filipino, Finnish, French, German, Greek, Hindi, Indonesian, Italian, Japanese, Korean, Malay, Polish, Portuguese, Romanian, Russian, Simplified Chinese, Slovak, Spanish, Swedish, Tamil, Turkish, Ukrainian
- Developer Website
- App Support
- Privacy Policy
You Might Also Like
Echo Voice AI - Voice Clone
AI Voice Generator - AI Speech
AI Text To Speech: Voice Over
AI Voice Generator: VoiceKit
ShopList :Shared shopping list
T-Speech: Text to Speech
Search form
New: System Informer (Apr 21, 2024), Platform 29.4 (Apr 10, 2024) 1,000+ portable packages , 1.1 billion downloads Please donate today
Balabolka Portable 2.15.0.869 (text-to-speech on demand) Released

Balabolka is packaged with permission from the publisher
Update automatically or install from the portable app store in the PortableApps.com Platform .

Learn more about Balabolka...
PortableApps.com Installer / PortableApps.com Format
Balabolka Portable is packaged in a PortableApps.com Installer so it will automatically detect an existing PortableApps.com installation when your drive is plugged in. It supports upgrades by installing right over an existing copy, preserving all settings. And it's in PortableApps.com Format, so it automatically works with the PortableApps.com Platform including the Menu and Backup Utility.
Balabolka Portable is available for immediate download from the Balabolka Portable homepage . Get it today!
Story Topic:
- Freeware Release
- Log in or register to post comments
Please Help Support Us
- Create new account
- Request new password
Latest Releases & News
- App Releases & News...
- Just New Apps...
Join Our Community
Partner with PortableApps.com
- Hardware providers - Custom platform and apps
- Software publishers - Make your apps portable
- Contact us for details
About PortableApps.com
- In The News
- What Portable Means
How does Speechify work?
Table of contents.
How does Speechify work? Read this article to learn more about how Speechify works, its main features, and how it compares to similar TTS apps.
Speechify is a text to speech software with growing popularity. It was founded by Cliff Weitzman, a person with dyslexia who wanted to aid others with reading disabilities. However, apart from helping people with dyslexia and ADHD, today, Speechify offers additional features that will help you read faster and more efficiently.
This Speechify review will tell you more about its main features and explain how to use them.
A complete guide to Speechify
Before introducing Speechify’s main features, it’s worth explaining what text to speech means. Text to speech (TTS) is a speech synthesis technology that converts text into sounds that imitate the human voice. It’s a valuable tool used by many individuals who work in different fields of work, as well as for students, people with disabilities, and even children.
Speechify is one of the best TTS apps on the market today, and now you’ll see why.
Unparalleled text to speech service
For many, Speechify is considered an unparalleled text to speech app because of its functionality and outstanding features that allow you to do more than you can imagine.
In addition to transforming text into speech, Speechify allows you to convert text into audio files in MP3 and WAV formats. You can use these high-quality natural-sounding voices as a voiceover in your content.
If you want to change the reading speed for the ultimate listening experience, Speechify allows you to do that.
You can increase the speed up to five times, depending on your listening skills and preference. Listening to your text in less time will increase productivity and help you achieve more. You can also skip specific sentences or select a part of the audio.
Speechify also comes with various high-quality text to speech voices. You can choose between different English accents or automatically translate the text into over 30 languages.
Lastly, Speechify’s API allows users to make their content more accessible to dyslexics and others struggling with reading. You can add it to your apps and your websites.
Speechify as a Google Chrome extension
If you frequently use TTS to listen to text on your desktop, you can install its Google Chrome extension . This way, you can read entire web pages, Google docs, emails, and files in multiple formats.
By clicking on the small box in the corner of your screen, you will access settings and the play button. The Chrome extension allows you to read any web page you want, and you can even save the whole page as a document in your Speechify library.
On the Chrome extension, you have the option to skip certain elements in your text, such as brackets, URLs, citations, etc. This isn’t available on the mobile app yet, but the mobile version has its own benefits, which are mentioned in the next section.
The user-favorite Speechify mobile app
Speechify TTS is also available as an app on iOS (iPhone and iPad) and Android mobile devices. You can install it by simply going to the App Store or Google Play and clicking “Install.”
The Speechify mobile app is an excellent tool for listening to text on the go. You can even scan documents with your camera or take a photo and listen to the text on the screenshot offline.
One thing that isn’t available on the Chrome extension is the ability to edit your text. However, the mobile app lets you delete unnecessary sentences and paragraphs directly from the app.
Get started with Speechify today
If you’re tired of reading, try out Speechify today for free. You can install it on any device in just a few steps. Apart from English, you can choose from over 30 other languages, including Portuguese, Spanish , and German .
Go to Speechify.com , check out the pricing details, and try the Premium version immediately, or use the free trial first.
Is Speechify worth the money?
Thanks to Speechify’s free trial, you can see whether it’s worth the money for yourself. However, note that the free trial doesn’t include everything Speechify has to offer.
By signing up for Speechify Premium, you can access more features that will further improve your listening experience, make you more productive, and enable you to devote more time to your loved ones.
With the Premium version, you also unlock premium voices, which include some celebrity voices like Gwyneth Paltrow or Snoop Dogg.
Can I use Speechify without paying?
If you want to try Speechify before you decide to purchase a subscription, you can do so by signing up for the free version. The free plan lasts three days, during which time you’ll be able to familiarize yourself with the Speechify app. You can cancel on day two if you change your mind, but if you decide to continue using the service, you check the pricing and start your monthly subscriptions immediately.
What are the benefits of Speechify?
Speechify is used by people of different ages and professions. It’s an excellent tool for proofreading, increasing productivity, listening on the go, and spending less time staring at the screen.
You can also use its audio files as a voiceover in your projects and make your content more accessible to a broader audience.
What if I want to cancel my account?
Speechify users can cancel their subscriptions at any time. The cancellation will only apply to future charges, and you’ll be able to use Speechify Premium features until the first upcoming billing date.
Canceling can be done by going to the profile icon in the top right corner of the display, tapping “Payments & Subscriptions,” and then clicking “Subscriptions.” Next, select Speechify from the list and click “Cancel Subscription.”
What is the difference between Speechify and other text to speech apps?
There are other text to speech software, but what makes Speechify unique is its ability to turn images from physical books into audio files. In addition, Speechify has the option to instantly translate text into over 50 languages, which is not found in other similar apps.
- Previous How to Create Great Product Demo Videos
- Next Video merger

Tyler Weitzman
Tyler Weitzman is the Co-Founder, Head of Artificial Intelligence & President at Speechify, the #1 text-to-speech app in the world, totaling over 100,000 5-star reviews. Weitzman is a graduate of Stanford University, where he received a BS in mathematics and a MS in Computer Science in the Artificial Intelligence track. He has been selected by Inc. Magazine as a Top 50 Entrepreneur, and he has been featured in Business Insider, TechCrunch, LifeHacker, CBS, among other publications. Weitzman’s Masters degree research focused on artificial intelligence and text-to-speech, where his final paper was titled: “CloneBot: Personalized Dialogue-Response Predictions.”
Recent Blogs

AI Speech Recognition: Everything You Should Know

AI Speech to Text: Revolutionizing Transcription

Real-Time AI Dubbing with Voice Preservation
How to Add Voice Over to Video: A Step-by-Step Guide

Voice Simulator & Content Creation with AI-Generated Voices

Convert Audio and Video to Text: Transcription Has Never Been Easier.

How to Record Voice Overs Properly Over Gameplay: Everything You Need to Know

Voicemail Greeting Generator: The New Way to Engage Callers
How to Avoid AI Voice Scams

Character AI Voices: Revolutionizing Audio Content with Advanced Technology
Best AI Voices for Video Games
How to Monetize YouTube Channels with AI Voices
Multilingual Voice API: Bridging Communication Gaps in a Diverse World

Resemble.AI vs ElevenLabs: A Comprehensive Comparison
Apps to Read PDFs on Mobile and Desktop
How to Convert a PDF to an Audiobook: A Step-by-Step Guide
AI for Translation: Bridging Language Barriers
IVR Conversion Tool: A Comprehensive Guide for Healthcare Providers
Best AI Speech to Speech Tools
AI Voice Recorder: Everything You Need to Know
The Best Multilingual AI Speech Models
Program that will Read PDF Aloud: Yes it Exists
How to Convert Your Emails to an Audiobook: A Step-by-Step Tutorial
How to Convert iOS Files to an Audiobook
How to Convert Google Docs to an Audiobook
How to Convert Word Docs to an Audiobook
Alternatives to Deepgram Text to Speech API
Is Text to Speech HSA Eligible?
Can You Use an HSA for Speech Therapy?
Surprising HSA-Eligible Items

Speechify text to speech helps you save time
Popular blogs, the best celebrity voice generators in 2024.
YouTube Text to Speech: Elevating Your Video Content with Speechify
The 7 best alternatives to synthesia.io, everything you need to know about text to speech on tiktok.
The 10 best text-to-speech apps for Android
How to convert a pdf to speech.
The top girl voice changers
How to use siri text to speech.
Obama text to speech
Robot voice generators: the futuristic frontier of audio creation, pdf read aloud: free & paid options.
Alternatives to FakeYou text to speech
All about deepfake voices.
TikTok voice generator
Text to speech GoAnimate
The best celebrity text to speech voice generators, pdf audio reader, how to get text to speech indian voices, elevating your anime experience with anime voice generators.
Only available on iPhone and iPad
To access our catalog of 100,000+ audiobooks, you need to use an iOS device.
Coming to Android soon...
Join the waitlist
Enter your email and we will notify you as soon as Speechify Audiobooks is available for you.
You’ve been added to the waitlist. We will notify you as soon as Speechify Audiobooks is available for you.
Donald Trump trial day 5 recap: Lawyers make opening plays in sweeping hush money case
NEW YORK — The heart of former President Donald Trump 's New York hush money trial, overseen by Judge Juan Merchan , kicked off on Monday with opening statements and witness testimony.
Matthew Colangelo delivered the opening argument for the prosecution, alleging that the former president's actions were "election fraud, pure and simple." Trump's attorney, Todd Blanche, criticized accounts from Trump's former lawyer Michael Cohen and porn star Stormy Daniels , telling the jury "There's nothing wrong with trying to influence an election."
Jurors are deciding whether Trump falsified business records to cover up a hush money payment from Cohen to Daniels.
Trump authorized the payment in order to keep Daniels from hurting his 2016 presidential campaign by going public with her story that the pair had sex, according to the prosecutors. Trump denies Daniels' claim and has pleaded not guilty.
David Pecker , the former head of the National Enquirer’s parent company, was the first witness called to the stand in the case. He's expected to face further questions about how the company routinely paid for scandalous stories that it didn’t publish, under what others called a “catch-and-kill” strategy.
Prep for the polls: See who is running for president and compare where they stand on key issues in our Voter Guide
Catch up with USA TODAY's live updates from inside and outside the Manhattan courthouse:
Donald Trump insists payments were ‘legal expense’ rather than attempt to affect 2016 campaign
After a morning of opening arguments by prosecutors and defense lawyers in Donald Trump’s hush money trial, the former president gave his own eight-minute summary to reporters in the hallway outside the courtroom.
Trump is charged with falsifying business records to pay hush money to silence women before the 2016 election. But he insisted that his payments to his former lawyer, Michael Cohen, were correctly marked as legal expenses rather than what prosecutors contend were a reimbursement for the $130,000 paid to porn actress Stormy Daniels.
Trump said Cohen was imprisoned for other charges dealing with taxi medallions and tax fraud. But Cohen also pleaded guilty to a campaign finance violation for the payment to Daniels. Trump repeated that Manhattan District Attorney Alvin Bragg’s predecessor and federal prosecutors investigated him and declined to prosecute.
“This is what I got indicted for?” Trump asked. “It’s very unfair.
– Bart Jansen
Donald Trump exits courtroom after day 5 of hush money trial
Donald Trump exited the courtroom at 12:43 p.m. ET. Proceedings will resume Tuesday with arguments over whether Trump has violated Judge Juan Merchan's gag order.
Those will be held in the morning outside the presence of the jury. Jurors have been instructed that proceedings involving them will start at 11:30 a.m. ET on Tuesday, and will end at 2 p.m. ET in light of the Passover holiday.
– Aysha Bagchi
What is ‘catch-and-kill’?
The National Enquirer, a tabloid, routinely paid sources for stories and sometimes refused to publish them, under what prosecutors and witnesses in the Donald Trump hush money trial called a “catch-and-kill” strategy.
The publication’s parent company, American Media Inc., denied a catch-and-kill policy after The Wall Street Journal revealed a $150,000 payment to Karen McDougal, a former Playboy model who claimed a year-long affair with Trump, without ever publishing the story.
But instead, the company put her picture on a couple of magazine covers and had her write a few fitness columns.
AMI later acknowledged spending more than was routine to block McDougal’s story because the company expected to be reimbursed by Trump. The silencing of derogatory stories before the 2016 election is at the heart of Manhattan District Attorney Alvin Bragg’s charges against Trump that he falsified business records to pay hush money.
Lawyers, Judge Juan Merchan talk over lingering trial issues
Although jurors have left for the day, lawyers and the judge are continuing to discuss trial issues, including instructions the judge should give when lawyers introduce newspaper articles later in trial. Trump lawyer Emil Bove also raised concerns about "hearsay" coming into trial that's tied to Dylan Howard, a former editor of The National Enquirer who is unable to travel and come to the trial, according to earlier testimony.
"Hearsay" is a technical legal term referring to statements that were made outside a courtroom but are introduced in court in order to prove the truth of what was said. Such statements are prohibited unless they fall into specific exceptions.
Jurors excused for rest of day
Judge Juan Merchan said proceedings would need to wrap up for the rest of the day. He earlier said they would need to end by 12:30 p.m. ET for an alternate juror's emergency appointment over a toothache. The jurors have exited the courtroom. The lawyers have approached Merchan's bench for a private conversation.
Prosecutor asks Pecker about former National Enquirer editor, 'juicy stories '
Prosecutor Joshua Steinglass asked Pecker about Dylan Howard, who was once the editor of The National Enquirer. Howard now lives in Australia and has a health condition that prevents him from traveling, to the best of Pecker's knowledge, Pecker said. Pecker confirmed Howard would run "juicy stories" by Pecker.
Donald Trump listening intently to David Pecker testimony
Donald Trump has his arms on the table in front of him and is leaning his body forward slightly as he faces David Pecker directly.
Why is David Pecker tied to Donald Trump's hush money case? Publisher says he had 'final say' as former head of tabloid publisher
Pecker is describing his responsibilities when he was chairman, president, and CEO of American Media Inc. or "AMI," which owns The National Enquirer and other publications. He worked there from 1999 to 2020.
Pecker described having say over what would get published, including approving expenditures. He confirmed prosecutor Joshua Steinglass' statement that he would have "final say" over whether to publish an article involving a famous person.
David Pecker called to the stand
We have gotten our first witness in the case: David Pecker, a tabloid publisher. Prosecutors have alleged Pecker was a key member of a "catch-and-kill" conspiracy involving Donald Trump to prevent stories that could hurt his 2016 presidential campaign from becoming public.
Donald Trump returns to courtroom
Donald Trump returned to the courtroom at 12:01 p.m. ET, trailed by members of his defense team. Judge Juan Merchan just asked for jurors to be brought into the courtroom.
Judge Juan Merchan enters courtroom
Juan Merchan re-entered the courtroom at about noon ET. Prosecutors are also in the courtroom. We are waiting for Trump and his defense team to return.
Trump leaves the courtroom
Trump exited the courtroom at about 11:50 a.m. ET for a short break in proceedings.
Trump lawyer ends opening statement
Trump lawyer Todd Blanche ended his opening statement by telling the jurors to "use your common sense." He added: "We're New Yorkers."
Blanche reminded jurors they promised to put aside any views they have about Trump and decide the case based on the evidence presented in the trial. If they do that, there will be a "very swift" not guilty verdict for Trump, Blanche claimed.
Trump lawyer and prosecutors argue over Cohen's alleged lies
Trump lawyer Todd Blanche began telling jurors that Michael Cohen has lied multiple times under oath . But prosecutors objected and there was just a private conversation at the judge's bench. "The objection is sustained," Judge Juan Merchan said.
Blanche then told jurors they will learn Cohen has pleaded guilty to lying under oath. There was no objection – Merchan appears to be allowing that statement to the jurors.
Cohen pleaded guilty to lying to Congress in 2018.
Michael Cohen 'has a goal, an obsession, with getting Trump,' lawyer for Trump says
Todd Blanche in his opening statement has been focusing on Michael Cohen, a potentially key witness for prosecutors.
Michael Cohen "has misrepresented key conversations, where the only witness who was present for the conversation was Mr. Cohen and allegedly President Trump," Blanche told the jurors.
"He has a goal, an obsession, with getting Trump, and you're going to hear that," Blanche added. "I submit to you that he cannot be trusted."
Trump's lawyer says Stormy Daniels' claims are "false" in dramatic moment
Whether Stormy Daniels and Donald Trump actually had sex may be beside the point in this case, which deals with whether Trump falsified business records to cover up an attempt to unlawfully interfere with the 2016 election through the hush money payment to Daniels.
But Trump lawyer Todd Blanche still took his time in emphasizing Trump denies Daniels' claim. Paying Daniels for her agreement to not publicly spread "false – false – claims" about Trump isn't illegal, Blanche told the jurors.
Trump lawyer : 'There's nothing wrong with trying to influence an election. It's called democracy.'
"There's nothing wrong with trying to influence an election. It's called democracy," Trump lawyer Todd Blanche told the jurors. Blanche added that prosecutors have put a "sinister" spin on this, as if it's a crime, but jurors will learn it's not.
Defense lawyer denies Donald Trump was reimbursing Michael Cohen for Stormy Daniels hush money
Donald Trump's defense is beginning to take shape. Trump lawyer Todd Blanche said a series of payments Trump sent to Michael Cohen weren't payback for Cohen paying porn star Stormy Daniels hush money.
That contradicts prosecutors, who say they were reimbursement payments. Blanche said Cohen was Trump's personal attorney. According to prosecutors, Trump falsely labeled his checks to Cohen as being for legal services.
Trump is now looking over in direction of jurors and lawyer
Donald Trump largely looked forward as prosecutor Matthew Colangelo delivered an opening statement to Trump's right, in the direction of the jurors who are also to Trump's right.
Now that Trump lawyer Todd Blanche is addressing jurors, the presumptive Republican presidential nominee has turned his body and face toward his right, facing the jurors often and sometimes turning his head to see Blanche, who is standing both to Trump's right and slightly behind him.
'He's a husband. He's a father. He's a person': Trump lawyer addresses jurors
Trump lawyer Todd Blanche said his team will refer to Trump as "President Trump" throughout the trial out of respect for the office he held. Blanche added about his client: "He's also a man. He's a husband. He's a father. He's a person, just like you and just like me."
'President Trump is innocent': Trump lawyer begins opening statement
"President Trump is innocent," Trump's defense lawyer said to begin his opening statement on behalf of the former president.
Prosecution ends opening statement in Trump hush money case
Prosecutor Matthew Colangelo ended his opening statement by alleging Donald Trump is guilty of 34 counts of falsifying business records.
Michael Cohen's testimony will be 'backed up by Donald Trump's own words ,' prosecutor says
Prosecutor Matthew Colangelo told jurors Michael Cohen's testimony in the trial will be backed up by a paper trail that includes phone logs and business documents. It will be "backed up by Donald Trump's own words on tape, in social media posts, in his own books, and in video of his own speeches," Colangelo added.
Will the jury be sequestered in the Trump trial?
No. While Merchan has cautioned the media to refrain from reporting on some personally identifiable attributes of jurors , he has not decided to sequester the jury.
During Trump's defamation trial earlier this year, the jury was sequestered from the public during breaks and transported to the courthouse by the U.S. Marshals Service, according to the Associated Press .
– Kinsey Crowley
Trump not looking at prosecutor during prosecutor's opening
Prosecutor Matthew Colangelo is standing at a lectern to the right and slightly behind former President Donald Trump. The lectern is facing the jurors on the right side of the courtroom. Trump has been looking forward through most of the statement, rather than at Colangelo or the jury.
Trump has a screen in front of him that shows live video feeds of the proceedings from different vantage points. He has shaken his head at least once so far during the prosecution's opening. He has also leaned over to communicate with his lawyer, Todd Blanche, at least twice.
Prosecutor: 'It was election fraud, pure and simple.'
Prosecutor Matthew Colangelo described the alleged scheme to buy porn star Stormy Daniels' story for $130,000 in order to keep it from American voters: "It was election fraud, pure and simple," Colangelo alleged.
Prosecutors describe flurries of calls surrounding release of scandalous stories
Years before Donald Trump’s trial, FBI investigators uncovered flurries of calls between his personal lawyer, Michael Cohen, and National Enquirer executives when scandalous stories were breaking.
One cluster of calls happened Oct. 8, 2016, the day after The Washington Post released the now-infamous "Access Hollywood" tape, while negotiations were under way to buy the silence of porn actress Stormy Daniels.
Cohen called David Pecker, CEO of the National Enquirer’s parent company, briefly at 7:39 p.m. and again four minutes later. Then Cohen got a call from Dylan Howard, the company’s chief content officer. After conferring with a Trump spokesperson, Cohen got a call from Pecker and then called Trump. Cohen got two more calls from Howard at 8:39 p.m. and 8:57 p.m.
Another group of calls erupted Nov. 4, 2016, before The Wall Street Journal reported the National Enquirer paid Karen McDougal, a former Playboy model, for her story about the affair and never published it.
Jurors hear Stormy Daniels' story of affair with Donald Trump
Prosecutor Matthew Colangelo is now describing to jurors the effort to buy the rights to porn star Stormy Daniels' story of an affair with Trump (Trump denies her story).
Cohen sent a $130,000 payment to Daniels' lawyer to kill the story before the 2016 election, Colangelo says. "Cohen made that payment at Donald Trump's direction and for his benefit," he tells the jurors.
Donald Trump asks 'So what do we gotta pay for this, 150?' on tape, prosecutor says
Prosecutor Matthew Colangelo told jurors about a recorded conversation in which Cohen and Trump are discussing McDougal's story. He said the jurors will hear Trump in his own voice on the tape saying, "So what do we gotta pay for this, 150?"
Cohen recorded the conversation to show David Pecker that Trump planned to pay him back for buying McDougal's story, Colangelo said.
Playboy model's catch-and-kill story
Prosecutor Matthew Colangelo is describing a "catch-and-kill" effort to secure the story of former Playboy model Karen McDougal, who said she had an affair with Trump – a claim Trump denies.
Pecker agreed to have his company pay McDougal $150,000 to keep her quiet. The core reason for the payment was to keep the story from hurting Trump's presidential campaign, Colangelo said.
Who is Matthew Colangelo, the prosecutor starting off opening arguments?
Matthew Colangelo, who is starting off the prosecution’s opening arguments, joined the Manhattan District Attorney’s Office in December 2022 after serving as a senior official at the Justice Department in Washington.
Colangelo, who was the former acting Associate Attorney General at DOJ, specialized in housing & tenant protection, labor & worker protection and white-collar investigations at the DA’s office.
“Matthew Colangelo brings a wealth of economic justice experience combined with complex white-collar investigations, and he has the sound judgment and integrity needed to pursue justice against powerful people and institutions when they abuse their power,” DA Alvin Bragg said at the time.
– Josh Meyer
Prosecutor describes three-pronged conspiracy to interfere with 2016 election
Prosecutor Matthew Colangelo described to jurors a meeting between Donald Trump, his former lawyer Michael Cohen, and a tabloid publisher, David Pecker. The three agreed to a three-pronged conspiracy to interfere with the 2016 presidential election, Colangelo said:
- Pecker would be the campaign's "eyes and ears," reporting potentially harmful information to Cohen, who would work to keep it quiet. Colangelo described this as the "core" of the conspiracy.
- Pecker would publish flattering stories about Trump.
- Pecker would use his publications to attack Trump's political opponents.
'This case is about a criminal conspiracy and a cover-up': Opening statements begin in Trump's hush money trial
"This case is about a criminal conspiracy and a cover-up," said Matthew Colangelo, in beginning his opening statement for the prosecution.
Colangelo continued by telling jurors that Trump orchestrated a criminal scheme to interfere with the 2016 presidential election, and covered it up by lying in his New York business records "over and over and over again."
If Trump testifies, prosecutors can inform jurors of Trump civil fraud case, E. Jean Carroll defamation trial
Before jurors entered the courtroom, Judge Juan Merchan said that, should Trump testify, prosecutors would be able to inform jurors that Trump was found liable for violating state law by fraudulently inflating the value of his assets. That determination ties to his civil fraud case, in which Trump is appealing a $454 million judgment against him.
Merchan also said prosecutors could inform jurors that Trump was found liable for defaming New York writer E. Jean Carroll, even though Merchan didn't indicate they can inform jurors about Trump's liability for sexually abusing Carroll.
Merchan also said prosecutors can inform jurors that Trump was found to have violated a gag order twice in his civil fraud case. And prosecutors will be allowed to inform jurors of an agreement that the Trump Foundation would be dissolved as a result of an investigation into self-dealing transactions.
If Trump testifies and prosecutors seek to introduce those determinations, jurors will be instructed to only consider the determinations when it comes to evaluating Trump's credibility.
Jurors not permitted to speak to others about the case
Judge Juan Merchan instructed the jurors that they are not permitted to speak with others about the case because only they are authorized to decide the case.
Jurors instructed on how to approach deliberations at end of trial
Judge Juan Merchan is giving jurors extensive instructions on the trial and their role within it. He tells them not to be influenced by stereotypes or implicit biases, including when it comes to political affiliation.
Who is Stormy Daniels?
Stormy Daniels , born Stephanie Clifford, is an adult film star.
Daniels claims she had an affair with Trump in 2006, months after Melania Trump gave birth to Barron Trump. Michael Cohen paid her $130,000 to stay quiet about the alleged affair ahead of the 2016 presidential election.
Daniels sued to cancel the non-disclosure agreement signed 11 days before the election, which was dismissed in 2020 She also sued Trump for defamation in 2018 over some of his tweets, but that lawsuit was also thrown out.
What is Trump on trial for?
Trump has pleaded not guilty to charges that he falsified business records to cover up a hush money payment to porn star Stormy Daniels that was designed to unlawfully interfere in the 2016 presidential election.
The payment was made by former Trump lawyer Michael Cohen and violated federal campaign finance laws, according to prosecutors. They say Trump authorized the payment to help his presidential campaign, and falsified records to cover up the checks he sent to reimburse Cohen for the hush money.
– Aysha Bagchi
Will the Trump trial be televised or live streamed?
New York court rules state that audio-visual coverage of trials is not permitted unless a representative of the news media submits an application and the judge allows it, which has not happened for this trial.
– Kinsey Crowley & Aysha Bagchi
Judge indicates prosecutors can't tell jurors about E. Jean Carroll sexual abuse case
Before the jurors entered, Judge Juan Merchan ruled that prosecutors will be able to inform jurors of six legal determinations against Trump if he chooses to testify. However, Merchan didn't mention a jury's determination in a civil case that Trump sexually abused New York writer E. Jean Carroll, indicating that determination won't be allowed in the criminal case. Trump denies Carroll's claim.
Jurors enter the courtroom
The jurors entered the courtroom at about 9:55 a.m. ET. Judge Merchan is instructing them on how things will unfold, including his plan to give them introductory instructions that will last about 30 minutes.
Trump Media stock price
At open on April 22, Trump Media & Technology Group Corp share price fell to $35, down 3.79% from previous close
Donald Trump attacks officials over hush money trial without offering proof
Donald Trump sharply criticized the Manhattan District Attorney’s Office on Monday morning as opening arguments were set to get underway, telling reporters that the hush money case against him amounts to unfair election “interference.”
“Everybody knows it,” Trump said outside of court, claiming that the trial is preventing him from being on the campaign trail.”
“Fortunately, the poll numbers are very good. They've been going up because people understand what's going on. It's a witch hunt and it's a shame. And it comes out of Washington,” Trump said, without offering any proof.
There is no indication that anyone in Washington, including the Biden administration, has played any role in the first criminal prosecution of Trump on charges of paying hush money to two women just before the 2016 election who claimed to have had sex with him.
Who is Judge Juan Merchan? What to know as Donald Trump's hush money trial continues
Judge Juan Merchan is presiding over the first criminal trial of a former president in U.S. history. Donald Trump has been charged with 34 counts of falsifying business records to cover up the hush money payments issued to Stormy Daniels .
Merchan has been a felony judge for 15 years .
Before that, Merchan served as an assistant attorney general for Nassau County, on suburban Long Island, and in the Manhattan district attorney’s office for five years.
He received his bachelor’s degree is from Baruch College and his law degree is from Hofstra University.
– Kinsey Crowley and Bart Jansen
Juror #9 will remain in trial despite expressing concern over media
Judge Merchan announced that Juror #9, who expressed concern about continuing due to media attention, will remain in the trial. Merchan just met with the juror outside the courtroom. – Aysha Bagchi
Juror expressed concern about continuing due to media attention
A juror called the court expressing concern about attending the trial due to media attention, but the juror is here today, Judge Juan Merchan said. Merchan and members from each legal team are currently meeting with the juror outside the courtroom.
Court to end early at 12:30 p.m. ET due to alternate juror toothache
Judge Merchan announced court will be ending at 12:30 p.m. ET today because an alternate juror needs to get to an emergency appointment due to a toothache. Court was already scheduled to end early at 2 p.m. ET today and tomorrow for the Passover holiday.
Judge Merchan enters the courtroom
Judge Juan Merchan entered the courtroom at 9:31 a.m. ET.
Trump enters the courtroom
Former President Donald Trump entered the courtroom at 9:26 a.m. ET.– Aysha Bagchi
What happens if Trump is found guilty? Will he go to prison?
If Donald Trump is convicted on all counts in his New York criminal hush money trial that started last week, he could theoretically face more than a decade in prison.
But most legal experts who spoke to USA TODAY said such a dramatic outcome is unlikely. Instead, he would likely be sentenced to something between probation and four years in prison.
And he would probably still be out, free to campaign for president as the presumptive or actual 2024 Republican nominee, while his all-but-certain appeal was pending.
Donald Trump enters NY courthouse
Donald Trump has entered the Manhattan courthouse as the second week of his hush money trial begins
What is hush money?
Hush money is a wide-ranging term used to refer to paying someone to not speak publicly about an issue. It's not necessarily illegal, so why is Donald Trump in court over a hush money case?
The former president isn’t actually charged with making a $130,000 payment to porn actress Stormy Daniels in exchange for a non-disclosure agreement. Instead, he's accused of falsifying business records to hide the payment.
Manhattan District Attorney Alvin Bragg described the payments to Daniels and another woman, former Playboy model Karen McDougal , as part of a “catch-and-kill” strategy to prevent the women from telling their stories. But the criminal charges are that Trump falsified his company’s business records to conceal the payments.
Who are Donald Trump's lawyers?
Trump's defense team is led by Todd Blanche and Susan Necheles .
Blanche was a federal prosecutor for nine years in the Southern District of New York, which includes Manhattan. As a prominent white-collar defense lawyer he has defended Trump advisor Boris Epshteyn and Trump’s former campaign chairman, Paul Manafort.
Necheles is ranked among the top criminal defense lawyers in New York by the legal rating and head-hunting firm Chambers and Partners. She was also a former counsel to Venero Mangano , the former Genovese crime family underboss known as Benny Eggs..
– Josh Meyer
Is the Trump trial being televised?
No, the trial won't be televised or available to watch online or aired on TV.
New York court rules state that audio-visual coverage of trials is not permitted unless a representative of the news media submits an application and the judge allows it.
Records show an application was submitted to cover the arraignment, but not the trial. Judge Juan Merchan rejected the request to televise the arraignment.
– Kinsey Crowley and Aysha Bagchi
Who is Karen McDougal?
Karen McDougal indirectly received a hush money payment in 2016 after claiming to have an affair with Donald Trump. Cohen funneled the money through the National Enquirer under a "catch and kill" approach , paying the tabloid to buy rights to her story and prevent her from telling anyone else about it.
The National Enquirer, owned by American Media Inc., was fined $187,500 by the Federal Election Commission for paying McDougal $150,000 for exclusive rights to her story with the intent of influencing the election. McDougal also sued the company . She has since spoken out about her affair with Trump , saying it lasted for 10 months starting in 2006.
How long will Trump's trial last?
Donald Trump's hush money trial that begins Monday in Manhattan could last as long as eight weeks.
It is the first time a former president has been criminally charged, although Trump has now also been charged in three other criminal cases in other jurisdictions for attempting to overturn the 2020 election and hoarding classified documents after leaving office.
In New York, the presumptive Republican presidential nominee faces 34 felony counts of falsifying business records for allegedly disguising hush money payments issued to porn star Stormy Daniels. He has pleaded not guilty.
– Aysha Bagchi and Kinsey Crowley
What time does trial start today?
Proceedings in Donald Trump's hush money trial are expected to begin at 9:30 a.m. local time in New York.
– Marina Pitofsky
Who is David Pecker? Here's what to know about the first witness in Donald Trump's trial
David Pecker , the former head of the National Enquirer’s parent company, is expected to be the first witness in Donald Trump’s hush money trial about how the company routinely paid for scandalous stories that it didn’t publish, under what others called a “catch-and-kill” strategy.
Pecker was president and CEO of American Media Inc. (AMI) in August 2015, when he met with Trump and his personal lawyer, Michael Cohen, to “help deal with negative stories about Trump” by purchasing them and not publishing them, according to a Federal Election Commission agreement with the company.
After a lawyer for Karen McDougal, a former Playboy model who claimed an affair with Trump, contacted the company, Pecker and Dylan Howard, the company’s vice president and chief content officer, notified Cohen, according to the FEC agreement.
In August 2016, the company McDougal $150,000 for her life story, including about any relationship with “any then-married man” and then didn’t publish the story, according to the FEC agreement.
Wonder what it would be like to watch the Trump trial? Graphics take you inside courtroom.
Opening statements are expected to start at 9:30 a.m. today at Donald Trump's criminal trial. The former president ffaces 34 counts of falsifying business records in connection with a payment of $130,000 in hush money to an adult film actress ahead of his 2016 presidential campaign.
But where is the trial? Who are the key players? Go deeper with USA TODAY's graphics team:
More: Wonder what it would be like to watch the Trump trial? Graphics take you inside courtroom.
Trump's $175 million appeal bond under scrutiny
While the hush money trial is underway Monday morning, Judge Arthur Engoron will be hearing arguments in a courthouse next door over whether Trump's $175 million appeal bond passes muster in his New York civil fraud case.
The bond, if accepted by Engoron, will prevent New York Attorney General Letitia James from seizing Trump's assets while his appeal over the $454 million judgment against him is pending. James is arguing that Trump hasn't demonstrated he provided enough collateral to truly back up the bond, which was provided by Knight Specialty Insurance Company.
The Knight company is owned by self-proclaimed Trump supporter and California billionaire Don Hankey .
An appeal bond functions as a guarantee that a judgment will be paid once the appeal is over, at least in the amount of the bond. A New York appeals court allowed Trump and his co-defendants to post just $175 million, instead of the full $464 million judgment they face – all but $10 million of which Trump faces personally.
- Santa Barbara County
- San Luis Obispo County
- Ventura County
- U.S. / World
- Crime and Safety
- What’s Right
- News Channel 3 Investigates
- Local Forecast
- Interactive Radar
- SkyCam Network
- Full Election Results
- Election Coverage
- High School Sports
- College Sports
- More Sports
- Friday Football Focus
- News Channel 3-12 Livestream
- Livestream Special Coverage
- Morning News Guest Segments
- Events Calendar
- Entertainment
- Health Connections
- 805 Professionals
- Work For Us
- 805 Careers
- Advertise with Us
- Closed Captioning
- Download Our Apps
- EEO Public File Report
- FCC Public File
- How to find News Channel 12
- Public File Help
- Jobs and Internships
- Meet the Team
- Newsletters/Alerts
- TV Listings
Modi accused of hate speech for calling Muslims ‘infiltrators’ at a rally days into India’s election
By KRUTIKA PATHI Associated Press
NEW DELHI (AP) — India’s main opposition party accused Prime Minister Narendra Modi of using hate speech after he called Muslims “infiltrators” — some of his most incendiary rhetoric to date about the minority faith in a campaign rally days after the country began its weekslong general election.
At the rally on Sunday in the western state of Rajasthan, Modi said that when the Congress party was in government, “they said Muslims have the first right over the country’s resources.” If it returns to power, the party “will gather all your wealth and distribute it among those who have more children,” he said as the crowd applauded.
“They will distribute it among infiltrators,” he continued, saying, “Do you think your hard-earned money should be given to infiltrators?”
Abhishek Manu Singhvi, a spokesperson for Congress, called the prime minister’s remarks “deeply, deeply objectionable” and said the party on Monday had sought action from the Election Commission of India, which oversees the six-week voting period . The first votes were cast Friday.
The remarks sparked fierce criticism for peddling anti-Muslim tropes, and for breaking election rules which bar candidates from engaging in any activity that aggravates religious tensions. The Election Commission of India’s model code of conduct forbids candidates to “appeal to caste or communal feelings” to secure votes.
Asaduddin Owaidi, a Muslim lawmaker and president of the All India Majlis-e-Ittehad-ul-Muslimeen party, said on Sunday: “Modi today called Muslims infiltrators and people with many children. Since 2002 till this day, the only Modi guarantee has been to abuse Muslims and get votes.”
Critics of Modi — an avowed Hindu nationalist — say India’s tradition of diversity and secularism has come under attack since his party won power in 2014 and returned for a second term in 2019. They accuse Modi’s BJP of fostering religious intolerance and sometimes even violence. The party denies the accusation and say their policies benefit all Indians.
But rights groups say that attacks against minorities has become more brazen under Modi. Muslims have been lynched by Hindu mobs over allegations of eating beef or smuggling cows, an animal considered holy to Hindus. Muslim businesses have been boycotted, their homes and businesses have been bulldozed and places of worship set on fire . Some open calls have been made for their genocide .
Modi’s remarks on Sunday were based on a 2006 statement by then-Prime Minister Manmohan Singh of the Congress party. Singh said that India’s lower-castes, tribes, women and, “in particular the Muslim minority” were empowered to share in the country’s development equally.
“They must have the first claim on resources,” Singh had said. A day later, his office clarified that Singh was referring to all of the disadvantaged groups.
Modi and his Hindu nationalist Bharatiya Janata Party are expected to win, according to most surveys. The results come out on June 4.
The Congress party’s president, Mallikarjun Kharge, described Modi’s comments as “hate speech.” “In the history of India, no prime minister has lowered the dignity of his post as much as Modi has,” Kharge wrote on social media platform X.
In its petition to the election commission, the party said that Modi and the BJP have repeatedly used religion, religious symbols and sentiments in their election campaign with impunity. “These actions have been further bolstered by the commission’s inaction in penalising the prime minister and the BJP for their blatant violations of electoral laws,” it said.
The commission’s code of conduct is not legally binding on its own, but it can issue notices and suspend campaigners for a certain amount of time over violations.
“We decline comment,” a spokesperson for the commission told the Press Trust of India news agency on Monday.
In his speech, Modi also referred to a Hindu nationalist myth that Muslims were overtaking the Hindu population by having more children. Hindus comprise 80% of India’s 1.4 billion population, while the country’s 200 million Muslims make up 14%. Official data shows that fertility rates among Muslims have dropped the fastest among religious groups in recent decades, from 4.4 in 1992-93 to 2.3 between 2019-21, just a bit higher than Hindus at 1.94.
Modi’s BJP has previously referred to Muslims as infiltrators and cast them as illegal migrants who crossed into India from Bangladesh and Pakistan. Several states run by the BJP have also made laws that restrict interfaith marriage, citing the myth of “ love jihad ,” an unproven conspiracy theory that claims Muslim men use marriage to convert Hindu women.
Through it all, Modi has maintained a conspicuous silence, which critics say has emboldened some of his most extreme supporters and enabled more hate speech against Muslims.
Jump to comments ↓
The Associated Press
News Channel 3-12 is committed to providing a forum for civil and constructive conversation.
Please keep your comments respectful and relevant. You can review our Community Guidelines by clicking here
If you would like to share a story idea, please submit it here .
IMAGES
VIDEO
COMMENTS
Text-to-speech (TTS) technology reads aloud digital text — the words on computers, smartphones, and tablets. TTS can help people who struggle with reading. There are TTS tools available for nearly every digital device. Text-to-speech (TTS) is a type of assistive technology that reads digital text aloud. It's sometimes called "read aloud ...
Text-to-speech apps: Kids can also download TTS apps on smartphones and digital tablets. These apps often have special features like text highlighting in different colors and OCR. Some examples include Voice Dream Reader, Claro ScanPen and Office Lens. Chrome tools: Chrome is a relatively new platform with several TTS tools. These include Read ...
Cliff Weitzman is a dyslexia advocate and the CEO and founder of Speechify, the #1 text-to-speech app in the world, totaling over 100,000 5-star reviews and ranking first place in the App Store for the News & Magazines category. In 2017, Weitzman was named to the Forbes 30 under 30 list for his work making the internet more accessible to people ...
Text-to-Speech: Key Terms. A form of speech synthesis that converts written text into spoken words. It involves generating natural-sounding speech from digital text. The artificial production of human speech. In the context of TTS, it refers to the process of generating spoken language by a computer.
They process sequential input (text) and generate sequential output (speech) by leveraging multiple layers of interconnected neurons. Neural network-based TTS models can capture complex patterns in language and produce highly natural and expressive speech output. The result is a realistic, closer-to-human voice.
See It. The free app TTSMaker is the best text-to-speech app I can find for running in a browser. Just copy your text and paste it into the box, fill out the captcha, click Convert to Speech and ...
Android users can download a host of TTS apps, or enable the built-in Google Text-to-Speech app through the "Language & Input" menu. Related coverage from Tech Reference :
Google Text-to-Speech. Google Text-to-Speech is an intuitive text-to-speech engine that supports a wide range of languages and voices. Users can adjust the speech rate and pitch to suit their preferences. It also seamlessly integrates with other Google applications and services.
Text-to-speech technology is software that takes text as an input and produces audible speech as an output. In other words, it goes from text to speech, making TTS one of the more aptly named technologies of the digital revolution. The software that turns text into speech goes by many names: text-to-speech converter, TTS engine, TTS tool.
1. Initially, the system performs text analysis, dissecting sentences and words to understand their structure and meaning. 2. This is followed by linguistic processing, where the text is converted ...
Text-to-speech (TTS) is a very popular assistive technology in which a computer or tablet reads the words on the screen out loud to the user. This technology is popular among students who have difficulties with reading, especially those who struggle with decoding.By presenting the words auditorily, the student can focus on the meaning of words instead of spending all their brain power trying ...
Voice Aloud Reader. Voice Aloud Reader offers 40 different languages in a variety of natural voices. Due to its relative accuracy and speed, this text-to-speech app boasts an average rating of 4.5 stars from 6,500 reviews on the App store and 4.3 stars out of 122,000 reviews on Google play.
TTS meaning is "text-to-speech". It can be a program, application, software, inbuilt feature, or online tool that transfers a written text into a voiceover. Each service works in its own way. For example, Google text-to-speech feature voices websites, some electronic books have an inbuilt TTS function to turn books into audio, and the TikTok ...
An in-app purchase removes the ads. Download: Narrator's Voice (Free, in-app purchases available) 4. Talk. Talk takes a more minimal approach than Voice Aloud Reader and Narrator's Voice, but it is still one of the best free text-to-speech apps for Android.
Text to speech (TTS) is a natural language modeling process that requires changing units of text into units of speech for audio presentation. This is the opposite of speech to text, where a technology takes in spoken words and tries to accurately record them as text. Text to speech is now common in technologies that seek to render audio output ...
1. Speechify. If you are looking for an exceptional text-to-speech app that can handle multiple text formats, then you need to try Speechify. From articles to web pages, TXT to PDF files, Speechify's text-to-speech app, and browser extension simplifies converting text to audio.
To use Google Speech-to-Text functionality on your Android device, go to Settings > Apps & notifications > Default apps > Assist App. Select Speech Recognition and Synthesis from Google as your preferred voice input engine. Speech Services powers applications to read the text on your screen aloud. For example, it can be used by: To use Google ...
Text to speech (TTS) is a technology that converts text into spoken audio. It can read aloud PDFs, websites, and books using natural AI voices. Text-to-speech (TTS) technology can be helpful for anyone who needs to access written content in an auditory format, and it can provide a more inclusive and accessible way of communication for many ...
Screenshots. Predictable is a multi-award winning text-to-speech app for people with conditions such as ALS/MND, autism, cerebral palsy, Down's syndrome, and more. It uses smart word prediction technology to make speaking and typing easier and more efficient. The app allows users to save frequently used phrases and offers 26 multilingual options.
Speech-to-text technology is a type of natural language processing (NLP) that converts spoken words into written text. It is used in a variety of applications, including voice assistants, transcription services, and accessibility tools. Here is a more detailed explanation of how speech-to-text technology works:
Speech technology -- a broad field that has existed for decades -- is evolving quickly, thanks largely to the advent of AI. No longer is the field primarily about speech recognition and the accuracy of speech-to-text transcription. Underpinned by AI, speech-to-text today has been automated to the point where real-time transcription is good enough for most business use cases.
A Text-to-Speech (TTS) app is a software application that converts written text into spoken words. Users can input text into the app, and it will generate corresponding speech output, which can be played through speakers or headphones. - Convert any text into audio with Text to speech feature using TTS (Text To Speech) Functionality.
Speech AI is a branch of artificial intelligence that focuses on enabling computers to understand, interpret, and generate human speech. This involves two primary components: speech recognition and speech synthesis. Speech recognition is the process of converting spoken words into text, while speech synthesis, commonly known as text-to-speech ...
Experience the extraordinary with Revoicer AI, the groundbreaking text-to-speech app revolutionizing communication. Unlock the future of voiceovers with our cutting-edge cloning technology, seamlessly transforming your voice into captivating narratives. From written words to compelling spoken stories, our Text2Speech Magic offers unmatched ...
Update automatically or install from the portable app store in the PortableApps.com Platform. Features. Balabolka is a Text-To-Speech (TTS) program. All computer voices installed on your system are available to Balabolka. The on-screen text can be saved as a WAV, MP3, MP4, OGG or WMA file.
WASHINGTON, April 21 (Reuters) - TikTok on Sunday repeated its free-speech concerns about a bill passed by the House of Representatives that would ban the popular social media app in the U.S. if ...
Tap Album. Tap the three dot menu. Tap Edit Name. Confirm new album name. From there, everyone in the chat can view, add, delete and download pictures and videos from the album. To locate the album at any time, tap on your group chat name then tap Media. This feature will be rolling out over the coming weeks.
Text to speech (TTS) is a speech synthesis technology that converts text into sounds that imitate the human voice. It's a valuable tool used by many individuals who work in different fields of work, as well as for students, people with disabilities, and even children. Speechify is one of the best TTS apps on the market today, and now you'll ...
1:29. NEW YORK — The heart of former President Donald Trump 's New York hush money trial kicks off Monday with opening statements. Last week, 12 jurors were selected to decide if Trump falsified ...
NEW DELHI (AP) — India's main opposition party is accusing Prime Minister Narendra Modi of hate speech after he called Muslims "infiltrators" and used some of his most incendiary rhetoric ...