- Bipolar Disorder
- Therapy Center
- When To See a Therapist
- Types of Therapy
- Best Online Therapy
- Best Couples Therapy
- Best Family Therapy
- Managing Stress
- Sleep and Dreaming
- Understanding Emotions
- Self-Improvement
- Healthy Relationships
- Student Resources
- Personality Types
- Guided Meditations
- Verywell Mind Insights
- 2024 Verywell Mind 25
- Mental Health in the Classroom
- Editorial Process
- Meet Our Review Board
- Crisis Support

The Definition of Random Assignment According to Psychology
Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
:max_bytes(150000):strip_icc():format(webp)/IMG_9791-89504ab694d54b66bbd72cb84ffb860e.jpg "process of random assignment helps to ensure")
Emily is a board-certified science editor who has worked with top digital publishing brands like Voices for Biodiversity, Study.com, GoodTherapy, Vox, and Verywell.
:max_bytes(150000):strip_icc():format(webp)/Emily-Swaim-1000-0f3197de18f74329aeffb690a177160c.jpg "process of random assignment helps to ensure")
Materio / Getty Images
Random assignment refers to the use of chance procedures in psychology experiments to ensure that each participant has the same opportunity to be assigned to any given group in a study to eliminate any potential bias in the experiment at the outset. Participants are randomly assigned to different groups, such as the treatment group versus the control group. In clinical research, randomized clinical trials are known as the gold standard for meaningful results.
Simple random assignment techniques might involve tactics such as flipping a coin, drawing names out of a hat, rolling dice, or assigning random numbers to a list of participants. It is important to note that random assignment differs from random selection .
While random selection refers to how participants are randomly chosen from a target population as representatives of that population, random assignment refers to how those chosen participants are then assigned to experimental groups.
Random Assignment In Research
To determine if changes in one variable will cause changes in another variable, psychologists must perform an experiment. Random assignment is a critical part of the experimental design that helps ensure the reliability of the study outcomes.
Researchers often begin by forming a testable hypothesis predicting that one variable of interest will have some predictable impact on another variable.
The variable that the experimenters will manipulate in the experiment is known as the independent variable , while the variable that they will then measure for different outcomes is known as the dependent variable. While there are different ways to look at relationships between variables, an experiment is the best way to get a clear idea if there is a cause-and-effect relationship between two or more variables.
Once researchers have formulated a hypothesis, conducted background research, and chosen an experimental design, it is time to find participants for their experiment. How exactly do researchers decide who will be part of an experiment? As mentioned previously, this is often accomplished through something known as random selection.
Random Selection
In order to generalize the results of an experiment to a larger group, it is important to choose a sample that is representative of the qualities found in that population. For example, if the total population is 60% female and 40% male, then the sample should reflect those same percentages.
Choosing a representative sample is often accomplished by randomly picking people from the population to be participants in a study. Random selection means that everyone in the group stands an equal chance of being chosen to minimize any bias. Once a pool of participants has been selected, it is time to assign them to groups.
By randomly assigning the participants into groups, the experimenters can be fairly sure that each group will have the same characteristics before the independent variable is applied.
Participants might be randomly assigned to the control group , which does not receive the treatment in question. The control group may receive a placebo or receive the standard treatment. Participants may also be randomly assigned to the experimental group , which receives the treatment of interest. In larger studies, there can be multiple treatment groups for comparison.
There are simple methods of random assignment, like rolling the die. However, there are more complex techniques that involve random number generators to remove any human error.
There can also be random assignment to groups with pre-established rules or parameters. For example, if you want to have an equal number of men and women in each of your study groups, you might separate your sample into two groups (by sex) before randomly assigning each of those groups into the treatment group and control group.
Random assignment is essential because it increases the likelihood that the groups are the same at the outset. With all characteristics being equal between groups, other than the application of the independent variable, any differences found between group outcomes can be more confidently attributed to the effect of the intervention.
Example of Random Assignment
Imagine that a researcher is interested in learning whether or not drinking caffeinated beverages prior to an exam will improve test performance. After randomly selecting a pool of participants, each person is randomly assigned to either the control group or the experimental group.
The participants in the control group consume a placebo drink prior to the exam that does not contain any caffeine. Those in the experimental group, on the other hand, consume a caffeinated beverage before taking the test.
Participants in both groups then take the test, and the researcher compares the results to determine if the caffeinated beverage had any impact on test performance.
A Word From Verywell
Random assignment plays an important role in the psychology research process. Not only does this process help eliminate possible sources of bias, but it also makes it easier to generalize the results of a tested sample of participants to a larger population.
Random assignment helps ensure that members of each group in the experiment are the same, which means that the groups are also likely more representative of what is present in the larger population of interest. Through the use of this technique, psychology researchers are able to study complex phenomena and contribute to our understanding of the human mind and behavior.
Lin Y, Zhu M, Su Z. The pursuit of balance: An overview of covariate-adaptive randomization techniques in clinical trials . Contemp Clin Trials. 2015;45(Pt A):21-25. doi:10.1016/j.cct.2015.07.011
Sullivan L. Random assignment versus random selection . In: The SAGE Glossary of the Social and Behavioral Sciences. SAGE Publications, Inc.; 2009. doi:10.4135/9781412972024.n2108
Alferes VR. Methods of Randomization in Experimental Design . SAGE Publications, Inc.; 2012. doi:10.4135/9781452270012
Nestor PG, Schutt RK. Research Methods in Psychology: Investigating Human Behavior. (2nd Ed.). SAGE Publications, Inc.; 2015.
By Kendra Cherry, MSEd Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
Random Assignment in Psychology: Definition & Examples
Julia Simkus
Editor at Simply Psychology
BA (Hons) Psychology, Princeton University
Julia Simkus is a graduate of Princeton University with a Bachelor of Arts in Psychology. She is currently studying for a Master's Degree in Counseling for Mental Health and Wellness in September 2023. Julia's research has been published in peer reviewed journals.
Learn about our Editorial Process
Saul Mcleod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
In psychology, random assignment refers to the practice of allocating participants to different experimental groups in a study in a completely unbiased way, ensuring each participant has an equal chance of being assigned to any group.
In experimental research, random assignment, or random placement, organizes participants from your sample into different groups using randomization.
Random assignment uses chance procedures to ensure that each participant has an equal opportunity of being assigned to either a control or experimental group.
The control group does not receive the treatment in question, whereas the experimental group does receive the treatment.
When using random assignment, neither the researcher nor the participant can choose the group to which the participant is assigned. This ensures that any differences between and within the groups are not systematic at the onset of the study.
In a study to test the success of a weight-loss program, investigators randomly assigned a pool of participants to one of two groups.
Group A participants participated in the weight-loss program for 10 weeks and took a class where they learned about the benefits of healthy eating and exercise.
Group B participants read a 200-page book that explains the benefits of weight loss. The investigator randomly assigned participants to one of the two groups.
The researchers found that those who participated in the program and took the class were more likely to lose weight than those in the other group that received only the book.
Importance
Random assignment ensures that each group in the experiment is identical before applying the independent variable.
In experiments , researchers will manipulate an independent variable to assess its effect on a dependent variable, while controlling for other variables. Random assignment increases the likelihood that the treatment groups are the same at the onset of a study.
Thus, any changes that result from the independent variable can be assumed to be a result of the treatment of interest. This is particularly important for eliminating sources of bias and strengthening the internal validity of an experiment.
Random assignment is the best method for inferring a causal relationship between a treatment and an outcome.
Random Selection vs. Random Assignment
Random selection (also called probability sampling or random sampling) is a way of randomly selecting members of a population to be included in your study.
On the other hand, random assignment is a way of sorting the sample participants into control and treatment groups.
Random selection ensures that everyone in the population has an equal chance of being selected for the study. Once the pool of participants has been chosen, experimenters use random assignment to assign participants into groups.
Random assignment is only used in between-subjects experimental designs, while random selection can be used in a variety of study designs.
Random Assignment vs Random Sampling
Random sampling refers to selecting participants from a population so that each individual has an equal chance of being chosen. This method enhances the representativeness of the sample.
Random assignment, on the other hand, is used in experimental designs once participants are selected. It involves allocating these participants to different experimental groups or conditions randomly.
This helps ensure that any differences in results across groups are due to manipulating the independent variable, not preexisting differences among participants.
When to Use Random Assignment
Random assignment is used in experiments with a between-groups or independent measures design.
In these research designs, researchers will manipulate an independent variable to assess its effect on a dependent variable, while controlling for other variables.
There is usually a control group and one or more experimental groups. Random assignment helps ensure that the groups are comparable at the onset of the study.
How to Use Random Assignment
There are a variety of ways to assign participants into study groups randomly. Here are a handful of popular methods:
- Random Number Generator : Give each member of the sample a unique number; use a computer program to randomly generate a number from the list for each group.
- Lottery : Give each member of the sample a unique number. Place all numbers in a hat or bucket and draw numbers at random for each group.
- Flipping a Coin : Flip a coin for each participant to decide if they will be in the control group or experimental group (this method can only be used when you have just two groups)
- Roll a Die : For each number on the list, roll a dice to decide which of the groups they will be in. For example, assume that rolling 1, 2, or 3 places them in a control group and rolling 3, 4, 5 lands them in an experimental group.
When is Random Assignment not used?
- When it is not ethically permissible: Randomization is only ethical if the researcher has no evidence that one treatment is superior to the other or that one treatment might have harmful side effects.
- When answering non-causal questions : If the researcher is just interested in predicting the probability of an event, the causal relationship between the variables is not important and observational designs would be more suitable than random assignment.
- When studying the effect of variables that cannot be manipulated: Some risk factors cannot be manipulated and so it would not make any sense to study them in a randomized trial. For example, we cannot randomly assign participants into categories based on age, gender, or genetic factors.
Drawbacks of Random Assignment
While randomization assures an unbiased assignment of participants to groups, it does not guarantee the equality of these groups. There could still be extraneous variables that differ between groups or group differences that arise from chance. Additionally, there is still an element of luck with random assignments.
Thus, researchers can not produce perfectly equal groups for each specific study. Differences between the treatment group and control group might still exist, and the results of a randomized trial may sometimes be wrong, but this is absolutely okay.
Scientific evidence is a long and continuous process, and the groups will tend to be equal in the long run when data is aggregated in a meta-analysis.
Additionally, external validity (i.e., the extent to which the researcher can use the results of the study to generalize to the larger population) is compromised with random assignment.
Random assignment is challenging to implement outside of controlled laboratory conditions and might not represent what would happen in the real world at the population level.
Random assignment can also be more costly than simple observational studies, where an investigator is just observing events without intervening with the population.
Randomization also can be time-consuming and challenging, especially when participants refuse to receive the assigned treatment or do not adhere to recommendations.
What is the difference between random sampling and random assignment?
Random sampling refers to randomly selecting a sample of participants from a population. Random assignment refers to randomly assigning participants to treatment groups from the selected sample.
Does random assignment increase internal validity?
Yes, random assignment ensures that there are no systematic differences between the participants in each group, enhancing the study’s internal validity .
Does random assignment reduce sampling error?
Yes, with random assignment, participants have an equal chance of being assigned to either a control group or an experimental group, resulting in a sample that is, in theory, representative of the population.
Random assignment does not completely eliminate sampling error because a sample only approximates the population from which it is drawn. However, random sampling is a way to minimize sampling errors.
When is random assignment not possible?
Random assignment is not possible when the experimenters cannot control the treatment or independent variable.
For example, if you want to compare how men and women perform on a test, you cannot randomly assign subjects to these groups.
Participants are not randomly assigned to different groups in this study, but instead assigned based on their characteristics.
Does random assignment eliminate confounding variables?
Yes, random assignment eliminates the influence of any confounding variables on the treatment because it distributes them at random among the study groups. Randomization invalidates any relationship between a confounding variable and the treatment.
Why is random assignment of participants to treatment conditions in an experiment used?
Random assignment is used to ensure that all groups are comparable at the start of a study. This allows researchers to conclude that the outcomes of the study can be attributed to the intervention at hand and to rule out alternative explanations for study results.
Further Reading
- Bogomolnaia, A., & Moulin, H. (2001). A new solution to the random assignment problem . Journal of Economic theory , 100 (2), 295-328.
- Krause, M. S., & Howard, K. I. (2003). What random assignment does and does not do . Journal of Clinical Psychology , 59 (7), 751-766.
Related Articles

Research Methodology
Qualitative Data Coding

What Is a Focus Group?

Cross-Cultural Research Methodology In Psychology

What Is Internal Validity In Research?

Research Methodology , Statistics
What Is Face Validity In Research? Importance & How To Measure

Criterion Validity: Definition & Examples
Chapter 6: Experimental Research
6.2 experimental design, learning objectives.
- Explain the difference between between-subjects and within-subjects experiments, list some of the pros and cons of each approach, and decide which approach to use to answer a particular research question.
- Define random assignment, distinguish it from random sampling, explain its purpose in experimental research, and use some simple strategies to implement it.
- Define what a control condition is, explain its purpose in research on treatment effectiveness, and describe some alternative types of control conditions.
- Define several types of carryover effect, give examples of each, and explain how counterbalancing helps to deal with them.
In this section, we look at some different ways to design an experiment. The primary distinction we will make is between approaches in which each participant experiences one level of the independent variable and approaches in which each participant experiences all levels of the independent variable. The former are called between-subjects experiments and the latter are called within-subjects experiments.
Between-Subjects Experiments
In a between-subjects experiment , each participant is tested in only one condition. For example, a researcher with a sample of 100 college students might assign half of them to write about a traumatic event and the other half write about a neutral event. Or a researcher with a sample of 60 people with severe agoraphobia (fear of open spaces) might assign 20 of them to receive each of three different treatments for that disorder. It is essential in a between-subjects experiment that the researcher assign participants to conditions so that the different groups are, on average, highly similar to each other. Those in a trauma condition and a neutral condition, for example, should include a similar proportion of men and women, and they should have similar average intelligence quotients (IQs), similar average levels of motivation, similar average numbers of health problems, and so on. This is a matter of controlling these extraneous participant variables across conditions so that they do not become confounding variables.
Random Assignment
The primary way that researchers accomplish this kind of control of extraneous variables across conditions is called random assignment , which means using a random process to decide which participants are tested in which conditions. Do not confuse random assignment with random sampling. Random sampling is a method for selecting a sample from a population, and it is rarely used in psychological research. Random assignment is a method for assigning participants in a sample to the different conditions, and it is an important element of all experimental research in psychology and other fields too.
In its strictest sense, random assignment should meet two criteria. One is that each participant has an equal chance of being assigned to each condition (e.g., a 50% chance of being assigned to each of two conditions). The second is that each participant is assigned to a condition independently of other participants. Thus one way to assign participants to two conditions would be to flip a coin for each one. If the coin lands heads, the participant is assigned to Condition A, and if it lands tails, the participant is assigned to Condition B. For three conditions, one could use a computer to generate a random integer from 1 to 3 for each participant. If the integer is 1, the participant is assigned to Condition A; if it is 2, the participant is assigned to Condition B; and if it is 3, the participant is assigned to Condition C. In practice, a full sequence of conditions—one for each participant expected to be in the experiment—is usually created ahead of time, and each new participant is assigned to the next condition in the sequence as he or she is tested. When the procedure is computerized, the computer program often handles the random assignment.
One problem with coin flipping and other strict procedures for random assignment is that they are likely to result in unequal sample sizes in the different conditions. Unequal sample sizes are generally not a serious problem, and you should never throw away data you have already collected to achieve equal sample sizes. However, for a fixed number of participants, it is statistically most efficient to divide them into equal-sized groups. It is standard practice, therefore, to use a kind of modified random assignment that keeps the number of participants in each group as similar as possible. One approach is block randomization . In block randomization, all the conditions occur once in the sequence before any of them is repeated. Then they all occur again before any of them is repeated again. Within each of these “blocks,” the conditions occur in a random order. Again, the sequence of conditions is usually generated before any participants are tested, and each new participant is assigned to the next condition in the sequence. Table 6.2 “Block Randomization Sequence for Assigning Nine Participants to Three Conditions” shows such a sequence for assigning nine participants to three conditions. The Research Randomizer website ( http://www.randomizer.org ) will generate block randomization sequences for any number of participants and conditions. Again, when the procedure is computerized, the computer program often handles the block randomization.
Table 6.2 Block Randomization Sequence for Assigning Nine Participants to Three Conditions
Random assignment is not guaranteed to control all extraneous variables across conditions. It is always possible that just by chance, the participants in one condition might turn out to be substantially older, less tired, more motivated, or less depressed on average than the participants in another condition. However, there are some reasons that this is not a major concern. One is that random assignment works better than one might expect, especially for large samples. Another is that the inferential statistics that researchers use to decide whether a difference between groups reflects a difference in the population takes the “fallibility” of random assignment into account. Yet another reason is that even if random assignment does result in a confounding variable and therefore produces misleading results, this is likely to be detected when the experiment is replicated. The upshot is that random assignment to conditions—although not infallible in terms of controlling extraneous variables—is always considered a strength of a research design.
Treatment and Control Conditions
Between-subjects experiments are often used to determine whether a treatment works. In psychological research, a treatment is any intervention meant to change people’s behavior for the better. This includes psychotherapies and medical treatments for psychological disorders but also interventions designed to improve learning, promote conservation, reduce prejudice, and so on. To determine whether a treatment works, participants are randomly assigned to either a treatment condition , in which they receive the treatment, or a control condition , in which they do not receive the treatment. If participants in the treatment condition end up better off than participants in the control condition—for example, they are less depressed, learn faster, conserve more, express less prejudice—then the researcher can conclude that the treatment works. In research on the effectiveness of psychotherapies and medical treatments, this type of experiment is often called a randomized clinical trial .
There are different types of control conditions. In a no-treatment control condition , participants receive no treatment whatsoever. One problem with this approach, however, is the existence of placebo effects. A placebo is a simulated treatment that lacks any active ingredient or element that should make it effective, and a placebo effect is a positive effect of such a treatment. Many folk remedies that seem to work—such as eating chicken soup for a cold or placing soap under the bedsheets to stop nighttime leg cramps—are probably nothing more than placebos. Although placebo effects are not well understood, they are probably driven primarily by people’s expectations that they will improve. Having the expectation to improve can result in reduced stress, anxiety, and depression, which can alter perceptions and even improve immune system functioning (Price, Finniss, & Benedetti, 2008).
Placebo effects are interesting in their own right (see Note 6.28 “The Powerful Placebo” ), but they also pose a serious problem for researchers who want to determine whether a treatment works. Figure 6.2 “Hypothetical Results From a Study Including Treatment, No-Treatment, and Placebo Conditions” shows some hypothetical results in which participants in a treatment condition improved more on average than participants in a no-treatment control condition. If these conditions (the two leftmost bars in Figure 6.2 “Hypothetical Results From a Study Including Treatment, No-Treatment, and Placebo Conditions” ) were the only conditions in this experiment, however, one could not conclude that the treatment worked. It could be instead that participants in the treatment group improved more because they expected to improve, while those in the no-treatment control condition did not.
Figure 6.2 Hypothetical Results From a Study Including Treatment, No-Treatment, and Placebo Conditions

Fortunately, there are several solutions to this problem. One is to include a placebo control condition , in which participants receive a placebo that looks much like the treatment but lacks the active ingredient or element thought to be responsible for the treatment’s effectiveness. When participants in a treatment condition take a pill, for example, then those in a placebo control condition would take an identical-looking pill that lacks the active ingredient in the treatment (a “sugar pill”). In research on psychotherapy effectiveness, the placebo might involve going to a psychotherapist and talking in an unstructured way about one’s problems. The idea is that if participants in both the treatment and the placebo control groups expect to improve, then any improvement in the treatment group over and above that in the placebo control group must have been caused by the treatment and not by participants’ expectations. This is what is shown by a comparison of the two outer bars in Figure 6.2 “Hypothetical Results From a Study Including Treatment, No-Treatment, and Placebo Conditions” .
Of course, the principle of informed consent requires that participants be told that they will be assigned to either a treatment or a placebo control condition—even though they cannot be told which until the experiment ends. In many cases the participants who had been in the control condition are then offered an opportunity to have the real treatment. An alternative approach is to use a waitlist control condition , in which participants are told that they will receive the treatment but must wait until the participants in the treatment condition have already received it. This allows researchers to compare participants who have received the treatment with participants who are not currently receiving it but who still expect to improve (eventually). A final solution to the problem of placebo effects is to leave out the control condition completely and compare any new treatment with the best available alternative treatment. For example, a new treatment for simple phobia could be compared with standard exposure therapy. Because participants in both conditions receive a treatment, their expectations about improvement should be similar. This approach also makes sense because once there is an effective treatment, the interesting question about a new treatment is not simply “Does it work?” but “Does it work better than what is already available?”
The Powerful Placebo
Many people are not surprised that placebos can have a positive effect on disorders that seem fundamentally psychological, including depression, anxiety, and insomnia. However, placebos can also have a positive effect on disorders that most people think of as fundamentally physiological. These include asthma, ulcers, and warts (Shapiro & Shapiro, 1999). There is even evidence that placebo surgery—also called “sham surgery”—can be as effective as actual surgery.
Medical researcher J. Bruce Moseley and his colleagues conducted a study on the effectiveness of two arthroscopic surgery procedures for osteoarthritis of the knee (Moseley et al., 2002). The control participants in this study were prepped for surgery, received a tranquilizer, and even received three small incisions in their knees. But they did not receive the actual arthroscopic surgical procedure. The surprising result was that all participants improved in terms of both knee pain and function, and the sham surgery group improved just as much as the treatment groups. According to the researchers, “This study provides strong evidence that arthroscopic lavage with or without débridement [the surgical procedures used] is not better than and appears to be equivalent to a placebo procedure in improving knee pain and self-reported function” (p. 85).

Research has shown that patients with osteoarthritis of the knee who receive a “sham surgery” experience reductions in pain and improvement in knee function similar to those of patients who receive a real surgery.
Army Medicine – Surgery – CC BY 2.0.
Within-Subjects Experiments
In a within-subjects experiment , each participant is tested under all conditions. Consider an experiment on the effect of a defendant’s physical attractiveness on judgments of his guilt. Again, in a between-subjects experiment, one group of participants would be shown an attractive defendant and asked to judge his guilt, and another group of participants would be shown an unattractive defendant and asked to judge his guilt. In a within-subjects experiment, however, the same group of participants would judge the guilt of both an attractive and an unattractive defendant.
The primary advantage of this approach is that it provides maximum control of extraneous participant variables. Participants in all conditions have the same mean IQ, same socioeconomic status, same number of siblings, and so on—because they are the very same people. Within-subjects experiments also make it possible to use statistical procedures that remove the effect of these extraneous participant variables on the dependent variable and therefore make the data less “noisy” and the effect of the independent variable easier to detect. We will look more closely at this idea later in the book.
Carryover Effects and Counterbalancing
The primary disadvantage of within-subjects designs is that they can result in carryover effects. A carryover effect is an effect of being tested in one condition on participants’ behavior in later conditions. One type of carryover effect is a practice effect , where participants perform a task better in later conditions because they have had a chance to practice it. Another type is a fatigue effect , where participants perform a task worse in later conditions because they become tired or bored. Being tested in one condition can also change how participants perceive stimuli or interpret their task in later conditions. This is called a context effect . For example, an average-looking defendant might be judged more harshly when participants have just judged an attractive defendant than when they have just judged an unattractive defendant. Within-subjects experiments also make it easier for participants to guess the hypothesis. For example, a participant who is asked to judge the guilt of an attractive defendant and then is asked to judge the guilt of an unattractive defendant is likely to guess that the hypothesis is that defendant attractiveness affects judgments of guilt. This could lead the participant to judge the unattractive defendant more harshly because he thinks this is what he is expected to do. Or it could make participants judge the two defendants similarly in an effort to be “fair.”
Carryover effects can be interesting in their own right. (Does the attractiveness of one person depend on the attractiveness of other people that we have seen recently?) But when they are not the focus of the research, carryover effects can be problematic. Imagine, for example, that participants judge the guilt of an attractive defendant and then judge the guilt of an unattractive defendant. If they judge the unattractive defendant more harshly, this might be because of his unattractiveness. But it could be instead that they judge him more harshly because they are becoming bored or tired. In other words, the order of the conditions is a confounding variable. The attractive condition is always the first condition and the unattractive condition the second. Thus any difference between the conditions in terms of the dependent variable could be caused by the order of the conditions and not the independent variable itself.
There is a solution to the problem of order effects, however, that can be used in many situations. It is counterbalancing , which means testing different participants in different orders. For example, some participants would be tested in the attractive defendant condition followed by the unattractive defendant condition, and others would be tested in the unattractive condition followed by the attractive condition. With three conditions, there would be six different orders (ABC, ACB, BAC, BCA, CAB, and CBA), so some participants would be tested in each of the six orders. With counterbalancing, participants are assigned to orders randomly, using the techniques we have already discussed. Thus random assignment plays an important role in within-subjects designs just as in between-subjects designs. Here, instead of randomly assigning to conditions, they are randomly assigned to different orders of conditions. In fact, it can safely be said that if a study does not involve random assignment in one form or another, it is not an experiment.
There are two ways to think about what counterbalancing accomplishes. One is that it controls the order of conditions so that it is no longer a confounding variable. Instead of the attractive condition always being first and the unattractive condition always being second, the attractive condition comes first for some participants and second for others. Likewise, the unattractive condition comes first for some participants and second for others. Thus any overall difference in the dependent variable between the two conditions cannot have been caused by the order of conditions. A second way to think about what counterbalancing accomplishes is that if there are carryover effects, it makes it possible to detect them. One can analyze the data separately for each order to see whether it had an effect.
When 9 Is “Larger” Than 221
Researcher Michael Birnbaum has argued that the lack of context provided by between-subjects designs is often a bigger problem than the context effects created by within-subjects designs. To demonstrate this, he asked one group of participants to rate how large the number 9 was on a 1-to-10 rating scale and another group to rate how large the number 221 was on the same 1-to-10 rating scale (Birnbaum, 1999). Participants in this between-subjects design gave the number 9 a mean rating of 5.13 and the number 221 a mean rating of 3.10. In other words, they rated 9 as larger than 221! According to Birnbaum, this is because participants spontaneously compared 9 with other one-digit numbers (in which case it is relatively large) and compared 221 with other three-digit numbers (in which case it is relatively small).
Simultaneous Within-Subjects Designs
So far, we have discussed an approach to within-subjects designs in which participants are tested in one condition at a time. There is another approach, however, that is often used when participants make multiple responses in each condition. Imagine, for example, that participants judge the guilt of 10 attractive defendants and 10 unattractive defendants. Instead of having people make judgments about all 10 defendants of one type followed by all 10 defendants of the other type, the researcher could present all 20 defendants in a sequence that mixed the two types. The researcher could then compute each participant’s mean rating for each type of defendant. Or imagine an experiment designed to see whether people with social anxiety disorder remember negative adjectives (e.g., “stupid,” “incompetent”) better than positive ones (e.g., “happy,” “productive”). The researcher could have participants study a single list that includes both kinds of words and then have them try to recall as many words as possible. The researcher could then count the number of each type of word that was recalled. There are many ways to determine the order in which the stimuli are presented, but one common way is to generate a different random order for each participant.
Between-Subjects or Within-Subjects?
Almost every experiment can be conducted using either a between-subjects design or a within-subjects design. This means that researchers must choose between the two approaches based on their relative merits for the particular situation.
Between-subjects experiments have the advantage of being conceptually simpler and requiring less testing time per participant. They also avoid carryover effects without the need for counterbalancing. Within-subjects experiments have the advantage of controlling extraneous participant variables, which generally reduces noise in the data and makes it easier to detect a relationship between the independent and dependent variables.
A good rule of thumb, then, is that if it is possible to conduct a within-subjects experiment (with proper counterbalancing) in the time that is available per participant—and you have no serious concerns about carryover effects—this is probably the best option. If a within-subjects design would be difficult or impossible to carry out, then you should consider a between-subjects design instead. For example, if you were testing participants in a doctor’s waiting room or shoppers in line at a grocery store, you might not have enough time to test each participant in all conditions and therefore would opt for a between-subjects design. Or imagine you were trying to reduce people’s level of prejudice by having them interact with someone of another race. A within-subjects design with counterbalancing would require testing some participants in the treatment condition first and then in a control condition. But if the treatment works and reduces people’s level of prejudice, then they would no longer be suitable for testing in the control condition. This is true for many designs that involve a treatment meant to produce long-term change in participants’ behavior (e.g., studies testing the effectiveness of psychotherapy). Clearly, a between-subjects design would be necessary here.
Remember also that using one type of design does not preclude using the other type in a different study. There is no reason that a researcher could not use both a between-subjects design and a within-subjects design to answer the same research question. In fact, professional researchers often do exactly this.
Key Takeaways
- Experiments can be conducted using either between-subjects or within-subjects designs. Deciding which to use in a particular situation requires careful consideration of the pros and cons of each approach.
- Random assignment to conditions in between-subjects experiments or to orders of conditions in within-subjects experiments is a fundamental element of experimental research. Its purpose is to control extraneous variables so that they do not become confounding variables.
- Experimental research on the effectiveness of a treatment requires both a treatment condition and a control condition, which can be a no-treatment control condition, a placebo control condition, or a waitlist control condition. Experimental treatments can also be compared with the best available alternative.
Discussion: For each of the following topics, list the pros and cons of a between-subjects and within-subjects design and decide which would be better.
- You want to test the relative effectiveness of two training programs for running a marathon.
- Using photographs of people as stimuli, you want to see if smiling people are perceived as more intelligent than people who are not smiling.
- In a field experiment, you want to see if the way a panhandler is dressed (neatly vs. sloppily) affects whether or not passersby give him any money.
- You want to see if concrete nouns (e.g., dog ) are recalled better than abstract nouns (e.g., truth ).
- Discussion: Imagine that an experiment shows that participants who receive psychodynamic therapy for a dog phobia improve more than participants in a no-treatment control group. Explain a fundamental problem with this research design and at least two ways that it might be corrected.
Birnbaum, M. H. (1999). How to show that 9 > 221: Collect judgments in a between-subjects design. Psychological Methods, 4 , 243–249.
Moseley, J. B., O’Malley, K., Petersen, N. J., Menke, T. J., Brody, B. A., Kuykendall, D. H., … Wray, N. P. (2002). A controlled trial of arthroscopic surgery for osteoarthritis of the knee. The New England Journal of Medicine, 347 , 81–88.
Price, D. D., Finniss, D. G., & Benedetti, F. (2008). A comprehensive review of the placebo effect: Recent advances and current thought. Annual Review of Psychology, 59 , 565–590.
Shapiro, A. K., & Shapiro, E. (1999). The powerful placebo: From ancient priest to modern physician . Baltimore, MD: Johns Hopkins University Press.
- Research Methods in Psychology. Provided by : University of Minnesota Libraries Publishing. Located at : http://open.lib.umn.edu/psychologyresearchmethods . License : CC BY-NC-SA: Attribution-NonCommercial-ShareAlike

Privacy Policy
Random Assignment in Psychology (Definition + 40 Examples)
Have you ever wondered how researchers discover new ways to help people learn, make decisions, or overcome challenges? A hidden hero in this adventure of discovery is a method called random assignment, a cornerstone in psychological research that helps scientists uncover the truths about the human mind and behavior.
Random Assignment is a process used in research where each participant has an equal chance of being placed in any group within the study. This technique is essential in experiments as it helps to eliminate biases, ensuring that the different groups being compared are similar in all important aspects.
By doing so, researchers can be confident that any differences observed are likely due to the variable being tested, rather than other factors.
In this article, we’ll explore the intriguing world of random assignment, diving into its history, principles, real-world examples, and the impact it has had on the field of psychology.
History of Random Assignment

Stepping back in time, we delve into the origins of random assignment, which finds its roots in the early 20th century.
The pioneering mind behind this innovative technique was Sir Ronald A. Fisher , a British statistician and biologist. Fisher introduced the concept of random assignment in the 1920s, aiming to improve the quality and reliability of experimental research .
His contributions laid the groundwork for the method's evolution and its widespread adoption in various fields, particularly in psychology.
Fisher’s groundbreaking work on random assignment was motivated by his desire to control for confounding variables – those pesky factors that could muddy the waters of research findings.
By assigning participants to different groups purely by chance, he realized that the influence of these confounding variables could be minimized, paving the way for more accurate and trustworthy results.
Early Studies Utilizing Random Assignment
Following Fisher's initial development, random assignment started to gain traction in the research community. Early studies adopting this methodology focused on a variety of topics, from agriculture (which was Fisher’s primary field of interest) to medicine and psychology.
The approach allowed researchers to draw stronger conclusions from their experiments, bolstering the development of new theories and practices.
One notable early study utilizing random assignment was conducted in the field of educational psychology. Researchers were keen to understand the impact of different teaching methods on student outcomes.
By randomly assigning students to various instructional approaches, they were able to isolate the effects of the teaching methods, leading to valuable insights and recommendations for educators.
Evolution of the Methodology
As the decades rolled on, random assignment continued to evolve and adapt to the changing landscape of research.
Advances in technology introduced new tools and techniques for implementing randomization, such as computerized random number generators, which offered greater precision and ease of use.
The application of random assignment expanded beyond the confines of the laboratory, finding its way into field studies and large-scale surveys.
Researchers across diverse disciplines embraced the methodology, recognizing its potential to enhance the validity of their findings and contribute to the advancement of knowledge.
From its humble beginnings in the early 20th century to its widespread use today, random assignment has proven to be a cornerstone of scientific inquiry.
Its development and evolution have played a pivotal role in shaping the landscape of psychological research, driving discoveries that have improved lives and deepened our understanding of the human experience.
Principles of Random Assignment
Delving into the heart of random assignment, we uncover the theories and principles that form its foundation.
The method is steeped in the basics of probability theory and statistical inference, ensuring that each participant has an equal chance of being placed in any group, thus fostering fair and unbiased results.
Basic Principles of Random Assignment
Understanding the core principles of random assignment is key to grasping its significance in research. There are three principles: equal probability of selection, reduction of bias, and ensuring representativeness.
The first principle, equal probability of selection , ensures that every participant has an identical chance of being assigned to any group in the study. This randomness is crucial as it mitigates the risk of bias and establishes a level playing field.
The second principle focuses on the reduction of bias . Random assignment acts as a safeguard, ensuring that the groups being compared are alike in all essential aspects before the experiment begins.
This similarity between groups allows researchers to attribute any differences observed in the outcomes directly to the independent variable being studied.
Lastly, ensuring representativeness is a vital principle. When participants are assigned randomly, the resulting groups are more likely to be representative of the larger population.
This characteristic is crucial for the generalizability of the study’s findings, allowing researchers to apply their insights broadly.
Theoretical Foundation
The theoretical foundation of random assignment lies in probability theory and statistical inference .
Probability theory deals with the likelihood of different outcomes, providing a mathematical framework for analyzing random phenomena. In the context of random assignment, it helps in ensuring that each participant has an equal chance of being placed in any group.
Statistical inference, on the other hand, allows researchers to draw conclusions about a population based on a sample of data drawn from that population. It is the mechanism through which the results of a study can be generalized to a broader context.
Random assignment enhances the reliability of statistical inferences by reducing biases and ensuring that the sample is representative.
Differentiating Random Assignment from Random Selection
It’s essential to distinguish between random assignment and random selection, as the two terms, while related, have distinct meanings in the realm of research.
Random assignment refers to how participants are placed into different groups in an experiment, aiming to control for confounding variables and help determine causes.
In contrast, random selection pertains to how individuals are chosen to participate in a study. This method is used to ensure that the sample of participants is representative of the larger population, which is vital for the external validity of the research.
While both methods are rooted in randomness and probability, they serve different purposes in the research process.
Understanding the theories, principles, and distinctions of random assignment illuminates its pivotal role in psychological research.
This method, anchored in probability theory and statistical inference, serves as a beacon of reliability, guiding researchers in their quest for knowledge and ensuring that their findings stand the test of validity and applicability.
Methodology of Random Assignment

Implementing random assignment in a study is a meticulous process that involves several crucial steps.
The initial step is participant selection, where individuals are chosen to partake in the study. This stage is critical to ensure that the pool of participants is diverse and representative of the population the study aims to generalize to.
Once the pool of participants has been established, the actual assignment process begins. In this step, each participant is allocated randomly to one of the groups in the study.
Researchers use various tools, such as random number generators or computerized methods, to ensure that this assignment is genuinely random and free from biases.
Monitoring and adjusting form the final step in the implementation of random assignment. Researchers need to continuously observe the groups to ensure that they remain comparable in all essential aspects throughout the study.
If any significant discrepancies arise, adjustments might be necessary to maintain the study’s integrity and validity.
Tools and Techniques Used
The evolution of technology has introduced a variety of tools and techniques to facilitate random assignment.
Random number generators, both manual and computerized, are commonly used to assign participants to different groups. These generators ensure that each individual has an equal chance of being placed in any group, upholding the principle of equal probability of selection.
In addition to random number generators, researchers often use specialized computer software designed for statistical analysis and experimental design.
These software programs offer advanced features that allow for precise and efficient random assignment, minimizing the risk of human error and enhancing the study’s reliability.
Ethical Considerations
The implementation of random assignment is not devoid of ethical considerations. Informed consent is a fundamental ethical principle that researchers must uphold.
Informed consent means that every participant should be fully informed about the nature of the study, the procedures involved, and any potential risks or benefits, ensuring that they voluntarily agree to participate.
Beyond informed consent, researchers must conduct a thorough risk and benefit analysis. The potential benefits of the study should outweigh any risks or harms to the participants.
Safeguarding the well-being of participants is paramount, and any study employing random assignment must adhere to established ethical guidelines and standards.
Conclusion of Methodology
The methodology of random assignment, while seemingly straightforward, is a multifaceted process that demands precision, fairness, and ethical integrity. From participant selection to assignment and monitoring, each step is crucial to ensure the validity of the study’s findings.
The tools and techniques employed, coupled with a steadfast commitment to ethical principles, underscore the significance of random assignment as a cornerstone of robust psychological research.
Benefits of Random Assignment in Psychological Research
The impact and importance of random assignment in psychological research cannot be overstated. It is fundamental for ensuring the study is accurate, allowing the researchers to determine if their study actually caused the results they saw, and making sure the findings can be applied to the real world.
Facilitating Causal Inferences
When participants are randomly assigned to different groups, researchers can be more confident that the observed effects are due to the independent variable being changed, and not other factors.
This ability to determine the cause is called causal inference .
This confidence allows for the drawing of causal relationships, which are foundational for theory development and application in psychology.
Ensuring Internal Validity
One of the foremost impacts of random assignment is its ability to enhance the internal validity of an experiment.
Internal validity refers to the extent to which a researcher can assert that changes in the dependent variable are solely due to manipulations of the independent variable , and not due to confounding variables.
By ensuring that each participant has an equal chance of being in any condition of the experiment, random assignment helps control for participant characteristics that could otherwise complicate the results.
Enhancing Generalizability
Beyond internal validity, random assignment also plays a crucial role in enhancing the generalizability of research findings.
When done correctly, it ensures that the sample groups are representative of the larger population, so can allow researchers to apply their findings more broadly.
This representative nature is essential for the practical application of research, impacting policy, interventions, and psychological therapies.
Limitations of Random Assignment
Potential for implementation issues.
While the principles of random assignment are robust, the method can face implementation issues.
One of the most common problems is logistical constraints. Some studies, due to their nature or the specific population being studied, find it challenging to implement random assignment effectively.
For instance, in educational settings, logistical issues such as class schedules and school policies might stop the random allocation of students to different teaching methods .
Ethical Dilemmas
Random assignment, while methodologically sound, can also present ethical dilemmas.
In some cases, withholding a potentially beneficial treatment from one of the groups of participants can raise serious ethical questions, especially in medical or clinical research where participants' well-being might be directly affected.
Researchers must navigate these ethical waters carefully, balancing the pursuit of knowledge with the well-being of participants.
Generalizability Concerns
Even when implemented correctly, random assignment does not always guarantee generalizable results.
The types of people in the participant pool, the specific context of the study, and the nature of the variables being studied can all influence the extent to which the findings can be applied to the broader population.
Researchers must be cautious in making broad generalizations from studies, even those employing strict random assignment.
Practical and Real-World Limitations
In the real world, many variables cannot be manipulated for ethical or practical reasons, limiting the applicability of random assignment.
For instance, researchers cannot randomly assign individuals to different levels of intelligence, socioeconomic status, or cultural backgrounds.
This limitation necessitates the use of other research designs, such as correlational or observational studies , when exploring relationships involving such variables.
Response to Critiques
In response to these critiques, people in favor of random assignment argue that the method, despite its limitations, remains one of the most reliable ways to establish cause and effect in experimental research.
They acknowledge the challenges and ethical considerations but emphasize the rigorous frameworks in place to address them.
The ongoing discussion around the limitations and critiques of random assignment contributes to the evolution of the method, making sure it is continuously relevant and applicable in psychological research.
While random assignment is a powerful tool in experimental research, it is not without its critiques and limitations. Implementation issues, ethical dilemmas, generalizability concerns, and real-world limitations can pose significant challenges.
However, the continued discourse and refinement around these issues underline the method's enduring significance in the pursuit of knowledge in psychology.
By being careful with how we do things and doing what's right, random assignment stays a really important part of studying how people act and think.
Real-World Applications and Examples

Random assignment has been employed in many studies across various fields of psychology, leading to significant discoveries and advancements.
Here are some real-world applications and examples illustrating the diversity and impact of this method:
- Medicine and Health Psychology: Randomized Controlled Trials (RCTs) are the gold standard in medical research. In these studies, participants are randomly assigned to either the treatment or control group to test the efficacy of new medications or interventions.
- Educational Psychology: Studies in this field have used random assignment to explore the effects of different teaching methods, classroom environments, and educational technologies on student learning and outcomes.
- Cognitive Psychology: Researchers have employed random assignment to investigate various aspects of human cognition, including memory, attention, and problem-solving, leading to a deeper understanding of how the mind works.
- Social Psychology: Random assignment has been instrumental in studying social phenomena, such as conformity, aggression, and prosocial behavior, shedding light on the intricate dynamics of human interaction.
Let's get into some specific examples. You'll need to know one term though, and that is "control group." A control group is a set of participants in a study who do not receive the treatment or intervention being tested , serving as a baseline to compare with the group that does, in order to assess the effectiveness of the treatment.
- Smoking Cessation Study: Researchers used random assignment to put participants into two groups. One group received a new anti-smoking program, while the other did not. This helped determine if the program was effective in helping people quit smoking.
- Math Tutoring Program: A study on students used random assignment to place them into two groups. One group received additional math tutoring, while the other continued with regular classes, to see if the extra help improved their grades.
- Exercise and Mental Health: Adults were randomly assigned to either an exercise group or a control group to study the impact of physical activity on mental health and mood.
- Diet and Weight Loss: A study randomly assigned participants to different diet plans to compare their effectiveness in promoting weight loss and improving health markers.
- Sleep and Learning: Researchers randomly assigned students to either a sleep extension group or a regular sleep group to study the impact of sleep on learning and memory.
- Classroom Seating Arrangement: Teachers used random assignment to place students in different seating arrangements to examine the effect on focus and academic performance.
- Music and Productivity: Employees were randomly assigned to listen to music or work in silence to investigate the effect of music on workplace productivity.
- Medication for ADHD: Children with ADHD were randomly assigned to receive either medication, behavioral therapy, or a placebo to compare treatment effectiveness.
- Mindfulness Meditation for Stress: Adults were randomly assigned to a mindfulness meditation group or a waitlist control group to study the impact on stress levels.
- Video Games and Aggression: A study randomly assigned participants to play either violent or non-violent video games and then measured their aggression levels.
- Online Learning Platforms: Students were randomly assigned to use different online learning platforms to evaluate their effectiveness in enhancing learning outcomes.
- Hand Sanitizers in Schools: Schools were randomly assigned to use hand sanitizers or not to study the impact on student illness and absenteeism.
- Caffeine and Alertness: Participants were randomly assigned to consume caffeinated or decaffeinated beverages to measure the effects on alertness and cognitive performance.
- Green Spaces and Well-being: Neighborhoods were randomly assigned to receive green space interventions to study the impact on residents’ well-being and community connections.
- Pet Therapy for Hospital Patients: Patients were randomly assigned to receive pet therapy or standard care to assess the impact on recovery and mood.
- Yoga for Chronic Pain: Individuals with chronic pain were randomly assigned to a yoga intervention group or a control group to study the effect on pain levels and quality of life.
- Flu Vaccines Effectiveness: Different groups of people were randomly assigned to receive either the flu vaccine or a placebo to determine the vaccine’s effectiveness.
- Reading Strategies for Dyslexia: Children with dyslexia were randomly assigned to different reading intervention strategies to compare their effectiveness.
- Physical Environment and Creativity: Participants were randomly assigned to different room setups to study the impact of physical environment on creative thinking.
- Laughter Therapy for Depression: Individuals with depression were randomly assigned to laughter therapy sessions or control groups to assess the impact on mood.
- Financial Incentives for Exercise: Participants were randomly assigned to receive financial incentives for exercising to study the impact on physical activity levels.
- Art Therapy for Anxiety: Individuals with anxiety were randomly assigned to art therapy sessions or a waitlist control group to measure the effect on anxiety levels.
- Natural Light in Offices: Employees were randomly assigned to workspaces with natural or artificial light to study the impact on productivity and job satisfaction.
- School Start Times and Academic Performance: Schools were randomly assigned different start times to study the effect on student academic performance and well-being.
- Horticulture Therapy for Seniors: Older adults were randomly assigned to participate in horticulture therapy or traditional activities to study the impact on cognitive function and life satisfaction.
- Hydration and Cognitive Function: Participants were randomly assigned to different hydration levels to measure the impact on cognitive function and alertness.
- Intergenerational Programs: Seniors and young people were randomly assigned to intergenerational programs to study the effects on well-being and cross-generational understanding.
- Therapeutic Horseback Riding for Autism: Children with autism were randomly assigned to therapeutic horseback riding or traditional therapy to study the impact on social communication skills.
- Active Commuting and Health: Employees were randomly assigned to active commuting (cycling, walking) or passive commuting to study the effect on physical health.
- Mindful Eating for Weight Management: Individuals were randomly assigned to mindful eating workshops or control groups to study the impact on weight management and eating habits.
- Noise Levels and Learning: Students were randomly assigned to classrooms with different noise levels to study the effect on learning and concentration.
- Bilingual Education Methods: Schools were randomly assigned different bilingual education methods to compare their effectiveness in language acquisition.
- Outdoor Play and Child Development: Children were randomly assigned to different amounts of outdoor playtime to study the impact on physical and cognitive development.
- Social Media Detox: Participants were randomly assigned to a social media detox or regular usage to study the impact on mental health and well-being.
- Therapeutic Writing for Trauma Survivors: Individuals who experienced trauma were randomly assigned to therapeutic writing sessions or control groups to study the impact on psychological well-being.
- Mentoring Programs for At-risk Youth: At-risk youth were randomly assigned to mentoring programs or control groups to assess the impact on academic achievement and behavior.
- Dance Therapy for Parkinson’s Disease: Individuals with Parkinson’s disease were randomly assigned to dance therapy or traditional exercise to study the effect on motor function and quality of life.
- Aquaponics in Schools: Schools were randomly assigned to implement aquaponics programs to study the impact on student engagement and environmental awareness.
- Virtual Reality for Phobia Treatment: Individuals with phobias were randomly assigned to virtual reality exposure therapy or traditional therapy to compare effectiveness.
- Gardening and Mental Health: Participants were randomly assigned to engage in gardening or other leisure activities to study the impact on mental health and stress reduction.
Each of these studies exemplifies how random assignment is utilized in various fields and settings, shedding light on the multitude of ways it can be applied to glean valuable insights and knowledge.
Real-world Impact of Random Assignment

Random assignment is like a key tool in the world of learning about people's minds and behaviors. It’s super important and helps in many different areas of our everyday lives. It helps make better rules, creates new ways to help people, and is used in lots of different fields.
Health and Medicine
In health and medicine, random assignment has helped doctors and scientists make lots of discoveries. It’s a big part of tests that help create new medicines and treatments.
By putting people into different groups by chance, scientists can really see if a medicine works.
This has led to new ways to help people with all sorts of health problems, like diabetes, heart disease, and mental health issues like depression and anxiety.
Schools and education have also learned a lot from random assignment. Researchers have used it to look at different ways of teaching, what kind of classrooms are best, and how technology can help learning.
This knowledge has helped make better school rules, develop what we learn in school, and find the best ways to teach students of all ages and backgrounds.
Workplace and Organizational Behavior
Random assignment helps us understand how people act at work and what makes a workplace good or bad.
Studies have looked at different kinds of workplaces, how bosses should act, and how teams should be put together. This has helped companies make better rules and create places to work that are helpful and make people happy.
Environmental and Social Changes
Random assignment is also used to see how changes in the community and environment affect people. Studies have looked at community projects, changes to the environment, and social programs to see how they help or hurt people’s well-being.
This has led to better community projects, efforts to protect the environment, and programs to help people in society.
Technology and Human Interaction
In our world where technology is always changing, studies with random assignment help us see how tech like social media, virtual reality, and online stuff affect how we act and feel.
This has helped make better and safer technology and rules about using it so that everyone can benefit.
The effects of random assignment go far and wide, way beyond just a science lab. It helps us understand lots of different things, leads to new and improved ways to do things, and really makes a difference in the world around us.
From making healthcare and schools better to creating positive changes in communities and the environment, the real-world impact of random assignment shows just how important it is in helping us learn and make the world a better place.
So, what have we learned? Random assignment is like a super tool in learning about how people think and act. It's like a detective helping us find clues and solve mysteries in many parts of our lives.
From creating new medicines to helping kids learn better in school, and from making workplaces happier to protecting the environment, it’s got a big job!
This method isn’t just something scientists use in labs; it reaches out and touches our everyday lives. It helps make positive changes and teaches us valuable lessons.
Whether we are talking about technology, health, education, or the environment, random assignment is there, working behind the scenes, making things better and safer for all of us.
In the end, the simple act of putting people into groups by chance helps us make big discoveries and improvements. It’s like throwing a small stone into a pond and watching the ripples spread out far and wide.
Thanks to random assignment, we are always learning, growing, and finding new ways to make our world a happier and healthier place for everyone!
Related posts:
- 19+ Experimental Design Examples (Methods + Types)
- Cluster Sampling vs Stratified Sampling
- 41+ White Collar Job Examples (Salary + Path)
- 47+ Blue Collar Job Examples (Salary + Path)
- McDonaldization of Society (Definition + Examples)
Reference this article:
About The Author
Free Personality Test

Free Memory Test

Free IQ Test

PracticalPie.com is a participant in the Amazon Associates Program. As an Amazon Associate we earn from qualifying purchases.
Follow Us On:
Youtube Facebook Instagram X/Twitter
Psychology Resources
Developmental
Personality
Relationships
Psychologists
Serial Killers
Psychology Tests
Personality Quiz
Memory Test
Depression test
Type A/B Personality Test
© PracticalPsychology. All rights reserved
Privacy Policy | Terms of Use
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Chapter 6: Data Collection Strategies
6.1.1 Random Assignation
As previously mentioned, one of the characteristics of a true experiment is that researchers use a random process to decide which participants are tested under which conditions. Random assignation is a powerful research technique that addresses the assumption of pre-test equivalence – that the experimental and control group are equal in all respects before the administration of the independent variable (Palys & Atchison, 2014).
Random assignation is the primary way that researchers attempt to control extraneous variables across conditions. Random assignation is associated with experimental research methods. In its strictest sense, random assignment should meet two criteria. One is that each participant has an equal chance of being assigned to each condition (e.g., a 50% chance of being assigned to each of two conditions). The second is that each participant is assigned to a condition independently of other participants. Thus, one way to assign participants to two conditions would be to flip a coin for each one. If the coin lands on the heads side, the participant is assigned to Condition A, and if it lands on the tails side, the participant is assigned to Condition B. For three conditions, one could use a computer to generate a random integer from 1 to 3 for each participant. If the integer is 1, the participant is assigned to Condition A; if it is 2, the participant is assigned to Condition B; and, if it is 3, the participant is assigned to Condition C. In practice, a full sequence of conditions—one for each participant expected to be in the experiment—is usually created ahead of time, and each new participant is assigned to the next condition in the sequence as he or she is tested.
However, one problem with coin flipping and other strict procedures for random assignment is that they are likely to result in unequal sample sizes in the different conditions. Unequal sample sizes are generally not a serious problem, and you should never throw away data you have already collected to achieve equal sample sizes. However, for a fixed number of participants, it is statistically most efficient to divide them into equal-sized groups. It is standard practice, therefore, to use a kind of modified random assignment that keeps the number of participants in each group as similar as possible.
One approach is block randomization. In block randomization, all the conditions occur once in the sequence before any of them is repeated. Then they all occur again before any of them is repeated again. Within each of these “blocks,” the conditions occur in a random order. Again, the sequence of conditions is usually generated before any participants are tested, and each new participant is assigned to the next condition in the sequence. When the procedure is computerized, the computer program often handles the random assignment, which is obviously much easier. You can also find programs online to help you randomize your random assignation. For example, the Research Randomizer website will generate block randomization sequences for any number of participants and conditions ( Research Randomizer ).
Random assignation is not guaranteed to control all extraneous variables across conditions. It is always possible that, just by chance, the participants in one condition might turn out to be substantially older, less tired, more motivated, or less depressed on average than the participants in another condition. However, there are some reasons that this may not be a major concern. One is that random assignment works better than one might expect, especially for large samples. Another is that the inferential statistics that researchers use to decide whether a difference between groups reflects a difference in the population take the “fallibility” of random assignment into account. Yet another reason is that even if random assignment does result in a confounding variable and therefore produces misleading results, this confound is likely to be detected when the experiment is replicated. The upshot is that random assignment to conditions—although not infallible in terms of controlling extraneous variables—is always considered a strength of a research design. Note: Do not confuse random assignation with random sampling. Random sampling is a method for selecting a sample from a population; we will talk about this in Chapter 7.
Research Methods for the Social Sciences: An Introduction Copyright © 2020 by Valerie Sheppard is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Random Assignment
- Reference work entry
- First Online: 01 January 2020
- pp 4260–4262
- Cite this reference work entry

- Sven Hilbert 3 , 4 , 5
Random assignment defines the assignment of participants of a study to their respective group strictly by chance.
Introduction
Statistical inference is based on the theory of probability, and effects investigated in psychological studies are defined by measures that are treated as random variables. The inference about the probability of a given result with regard to an assumed population and the popular term “significance” are only meaningful and without bias if the measure of interest is really a random variable. To achieve the creation of a random variable in form of a measure derived from a sample of participants, these participants have to be randomly drawn. In an experimental study involving different groups of participants, these participants have to additionally be randomly assigned to one of the groups.
Why Is Random Assignment Crucial for Statistical Inference?
Many psychological investigations, such as clinical treatment studies or neuropsychological training...
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Durable hardcover edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Gigerenzer, G., Swijtink, Z., Porter, T., Daston, L., Beatty, J., & Kruger, L. (1989). The empire of chance: How probability changed science and everyday-life . Cambridge: New York.
Book Google Scholar
Download references
Author information
Authors and affiliations.
Department of Psychology, Psychological Methods and Assessment, Münich, Germany
Sven Hilbert
Faculty of Psychology, Educational Science, and Sport Science, University of Regensburg, Regensburg, Germany
Psychological Methods and Assessment, LMU Munich, Munich, Germany
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Sven Hilbert .
Editor information
Editors and affiliations.
Oakland University, Rochester, MI, USA
Virgil Zeigler-Hill
Todd K. Shackelford
Section Editor information
Humboldt University, Germany, Berlin, Germany
Matthias Ziegler
Rights and permissions
Reprints and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this entry
Cite this entry.
Hilbert, S. (2020). Random Assignment. In: Zeigler-Hill, V., Shackelford, T.K. (eds) Encyclopedia of Personality and Individual Differences. Springer, Cham. https://doi.org/10.1007/978-3-319-24612-3_1343
Download citation
DOI : https://doi.org/10.1007/978-3-319-24612-3_1343
Published : 22 April 2020
Publisher Name : Springer, Cham
Print ISBN : 978-3-319-24610-9
Online ISBN : 978-3-319-24612-3
eBook Packages : Behavioral Science and Psychology Reference Module Humanities and Social Sciences Reference Module Business, Economics and Social Sciences
Share this entry
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
Statistical Thinking: A Simulation Approach to Modeling Uncertainty (UM STAT 216 edition)
3.6 causation and random assignment.
Medical researchers may be interested in showing that a drug helps improve people’s health (the cause of improvement is the drug), while educational researchers may be interested in showing a curricular innovation improves students’ learning (the curricular innovation causes improved learning).
To attribute a causal relationship, there are three criteria a researcher needs to establish:
- Association of the Cause and Effect: There needs to be a association between the cause and effect.
- Timing: The cause needs to happen BEFORE the effect.
- No Plausible Alternative Explanations: ALL other possible explanations for the effect need to be ruled out.
Please read more about each of these criteria at the Web Center for Social Research Methods .
The third criterion can be quite difficult to meet. To rule out ALL other possible explanations for the effect, we want to compare the world with the cause applied to the world without the cause. In practice, we do this by comparing two different groups: a “treatment” group that gets the cause applied to them, and a “control” group that does not. To rule out alternative explanations, the groups need to be “identical” with respect to every possible characteristic (aside from the treatment) that could explain differences. This way the only characteristic that will be different is that the treatment group gets the treatment and the control group doesn’t. If there are differences in the outcome, then it must be attributable to the treatment, because the other possible explanations are ruled out.
So, the key is to make the control and treatment groups “identical” when you are forming them. One thing that makes this task (slightly) easier is that they don’t have to be exactly identical, only probabilistically equivalent . This means, for example, that if you were matching groups on age that you don’t need the two groups to have identical age distributions; they would only need to have roughly the same AVERAGE age. Here roughly means “the average ages should be the same within what we expect because of sampling error.”
Now we just need to create the groups so that they have, on average, the same characteristics … for EVERY POSSIBLE CHARCTERISTIC that could explain differences in the outcome.
It turns out that creating probabilistically equivalent groups is a really difficult problem. One method that works pretty well for doing this is to randomly assign participants to the groups. This works best when you have large sample sizes, but even with small sample sizes random assignment has the advantage of at least removing the systematic bias between the two groups (any differences are due to chance and will probably even out between the groups). As Wikipedia’s page on random assignment points out,
Random assignment of participants helps to ensure that any differences between and within the groups are not systematic at the outset of the experiment. Thus, any differences between groups recorded at the end of the experiment can be more confidently attributed to the experimental procedures or treatment. … Random assignment does not guarantee that the groups are matched or equivalent. The groups may still differ on some preexisting attribute due to chance. The use of random assignment cannot eliminate this possibility, but it greatly reduces it.
We use the term internal validity to describe the degree to which cause-and-effect inferences are accurate and meaningful. Causal attribution is the goal for many researchers. Thus, by using random assignment we have a pretty high degree of evidence for internal validity; we have a much higher belief in causal inferences. Much like evidence used in a court of law, it is useful to think about validity evidence on a continuum. For example, a visualization of the internal validity evidence for a study that employed random assignment in the design might be:

The degree of internal validity evidence is high (in the upper-third). How high depends on other factors such as sample size.
To learn more about random assignment, you can read the following:
- The research report, Random Assignment Evaluation Studies: A Guide for Out-of-School Time Program Practitioners
3.6.1 Example: Does sleep deprivation cause an decrease in performance?
Let’s consider the criteria with respect to the sleep deprivation study we explored in class.
3.6.1.1 Association of cause and effect
First, we ask, Is there an association between the cause and the effect? In the sleep deprivation study, we would ask, “Is sleep deprivation associated with an decrease in performance?”
This is what a hypothesis test helps us answer! If the result is statistically significant , then we have an association between the cause and the effect. If the result is not statistically significant, then there is not sufficient evidence for an association between cause and effect.
In the case of the sleep deprivation experiment, the result was statistically significant, so we can say that sleep deprivation is associated with a decrease in performance.
3.6.1.2 Timing
Second, we ask, Did the cause come before the effect? In the sleep deprivation study, the answer is yes. The participants were sleep deprived before their performance was tested. It may seem like this is a silly question to ask, but as the link above describes, it is not always so clear to establish the timing. Thus, it is important to consider this question any time we are interested in establishing causality.
3.6.1.3 No plausible alternative explanations
Finally, we ask Are there any plausible alternative explanations for the observed effect? In the sleep deprivation study, we would ask, “Are there plausible alternative explanations for the observed difference between the groups, other than sleep deprivation?” Because this is a question about plausibility, human judgment comes into play. Researchers must make an argument about why there are no plausible alternatives. As described above, a strong study design can help to strengthen the argument.
At first, it may seem like there are a lot of plausible alternative explanations for the difference in performance. There are a lot of things that might affect someone’s performance on a visual task! Sleep deprivation is just one of them! For example, artists may be more adept at visual discrimination than other people. This is an example of a potential confounding variable. A confounding variable is a variable that might affect the results, other than the causal variable that we are interested in.
Here’s the thing though. We are not interested in figuring out why any particular person got the score that they did. Instead, we are interested in determining why one group was different from another group. In the sleep deprivation study, the participants were randomly assigned. This means that the there is no systematic difference between the groups, with respect to any confounding variables. Yes—artistic experience is a possible confounding variable, and it may be the reason why two people score differently. BUT: There is no systematic difference between the groups with respect to artistic experience, and so artistic experience is not a plausible explanation as to why the groups would be different. The same can be said for any possible confounding variable. Because the groups were randomly assigned, it is not plausible to say that the groups are different with respect to any confounding variable. Random assignment helps us rule out plausible alternatives.
3.6.1.4 Making a causal claim
Now, let’s see about make a causal claim for the sleep deprivation study:
- Association: There is a statistically significant result, so the cause is associated with the effect
- Timing: The participants were sleep deprived before their performance was measured, so the cause came before the effect
- Plausible alternative explanations: The participants were randomly assigned, so the groups are not systematically different on any confounding variable. The only systematic difference between the groups was sleep deprivation. Thus, there are no plausible alternative explanations for the difference between the groups, other than sleep deprivation
Thus, the internal validity evidence for this study is high, and we can make a causal claim. For the participants in this study, we can say that sleep deprivation caused a decrease in performance.
Key points: Causation and internal validity
To make a cause-and-effect inference, you need to consider three criteria:
- Association of the Cause and Effect: There needs to be a association between the cause and effect. This can be established by a hypothesis test.
Random assignment removes any systematic differences between the groups (other than the treatment), and thus helps to rule out plausible alternative explanations.
Internal validity describes the degree to which cause-and-effect inferences are accurate and meaningful.
Confounding variables are variables that might affect the results, other than the causal variable that we are interested in.
Probabilistic equivalence means that there is not a systematic difference between groups. The groups are the same on average.
How can we make "equivalent" experimental groups?
Random Assignment in Psychology (Intro for Students)

Random assignment is a research procedure used to randomly assign participants to different experimental conditions (or ‘groups’). This introduces the element of chance, ensuring that each participant has an equal likelihood of being placed in any condition group for the study.
It is absolutely essential that the treatment condition and the control condition are the same in all ways except for the variable being manipulated.
Using random assignment to place participants in different conditions helps to achieve this.
It ensures that those conditions are the same in regards to all potential confounding variables and extraneous factors .
Why Researchers Use Random Assignment
Researchers use random assignment to control for confounds in research.
Confounds refer to unwanted and often unaccounted-for variables that might affect the outcome of a study. These confounding variables can skew the results, rendering the experiment unreliable.
For example, below is a study with two groups. Note how there are more ‘red’ individuals in the first group than the second:

There is likely a confounding variable in this experiment explaining why more red people ended up in the treatment condition and less in the control condition. The red people might have self-selected, for example, leading to a skew of them in one group over the other.
Ideally, we’d want a more even distribution, like below:

To achieve better balance in our two conditions, we use randomized sampling.
Fact File: Experiments 101
Random assignment is used in the type of research called the experiment.
An experiment involves manipulating the level of one variable and examining how it affects another variable. These are the independent and dependent variables :
- Independent Variable: The variable manipulated is called the independent variable (IV)
- Dependent Variable: The variable that it is expected to affect is called the dependent variable (DV).
The most basic form of the experiment involves two conditions: the treatment and the control .
- The Treatment Condition: The treatment condition involves the participants being exposed to the IV.
- The Control Condition: The control condition involves the absence of the IV. Therefore, the IV has two levels: zero and some quantity.
Researchers utilize random assignment to determine which participants go into which conditions.
Methods of Random Assignment
There are several procedures that researchers can use to randomly assign participants to different conditions.
1. Random number generator
There are several websites that offer computer-generated random numbers. Simply indicate how many conditions are in the experiment and then click. If there are 4 conditions, the program will randomly generate a number between 1 and 4 each time it is clicked.
2. Flipping a coin
If there are two conditions in an experiment, then the simplest way to implement random assignment is to flip a coin for each participant. Heads means being assigned to the treatment and tails means being assigned to the control (or vice versa).
3. Rolling a die
Rolling a single die is another way to randomly assign participants. If the experiment has three conditions, then numbers 1 and 2 mean being assigned to the control; numbers 3 and 4 mean treatment condition one; and numbers 5 and 6 mean treatment condition two.
4. Condition names in a hat
In some studies, the researcher will write the name of the treatment condition(s) or control on slips of paper and place them in a hat. If there are 4 conditions and 1 control, then there are 5 slips of paper.
The researcher closes their eyes and selects one slip for each participant. That person is then assigned to one of the conditions in the study and that slip of paper is placed back in the hat. Repeat as necessary.
There are other ways of trying to ensure that the groups of participants are equal in all ways with the exception of the IV. However, random assignment is the most often used because it is so effective at reducing confounds.
Read About More Methods and Examples of Random Assignment Here
Potential Confounding Effects
Random assignment is all about minimizing confounding effects.
Here are six types of confounds that can be controlled for using random assignment:
- Individual Differences: Participants in a study will naturally vary in terms of personality, intelligence, mood, prior knowledge, and many other characteristics. If one group happens to have more people with a particular characteristic, this could affect the results. Random assignment ensures that these individual differences are spread out equally among the experimental groups, making it less likely that they will unduly influence the outcome.
- Temporal or Time-Related Confounds: Events or situations that occur at a particular time can influence the outcome of an experiment. For example, a participant might be tested after a stressful event, while another might be tested after a relaxing weekend. Random assignment ensures that such effects are equally distributed among groups, thus controlling for their potential influence.
- Order Effects: If participants are exposed to multiple treatments or tests, the order in which they experience them can influence their responses. Randomly assigning the order of treatments for different participants helps control for this.
- Location or Environmental Confounds: The environment in which the study is conducted can influence the results. One group might be tested in a noisy room, while another might be in a quiet room. Randomly assigning participants to different locations can control for these effects.
- Instrumentation Confounds: These occur when there are variations in the calibration or functioning of measurement instruments across conditions. If one group’s responses are being measured using a slightly different tool or scale, it can introduce a confound. Random assignment can ensure that any such potential inconsistencies in instrumentation are equally distributed among groups.
- Experimenter Effects: Sometimes, the behavior or expectations of the person administering the experiment can unintentionally influence the participants’ behavior or responses. For instance, if an experimenter believes one treatment is superior, they might unconsciously communicate this belief to participants. Randomly assigning experimenters or using a double-blind procedure (where neither the participant nor the experimenter knows the treatment being given) can help control for this.
Random assignment helps balance out these and other potential confounds across groups, ensuring that any observed differences are more likely due to the manipulated independent variable rather than some extraneous factor.
Limitations of the Random Assignment Procedure
Although random assignment is extremely effective at eliminating the presence of participant-related confounds, there are several scenarios in which it cannot be used.
- Ethics: The most obvious scenario is when it would be unethical. For example, if wanting to investigate the effects of emotional abuse on children, it would be unethical to randomly assign children to either received abuse or not. Even if a researcher were to propose such a study, it would not receive approval from the Institutional Review Board (IRB) which oversees research by university faculty.
- Practicality: Other scenarios involve matters of practicality. For example, randomly assigning people to specific types of diet over a 10-year period would be interesting, but it would be highly unlikely that participants would be diligent enough to make the study valid. This is why examining these types of subjects has to be carried out through observational studies . The data is correlational, which is informative, but falls short of the scientist’s ultimate goal of identifying causality.
- Small Sample Size: The smaller the sample size being assigned to conditions, the more likely it is that the two groups will be unequal. For example, if you flip a coin many times in a row then you will notice that sometimes there will be a string of heads or tails that come up consecutively. This means that one condition may have a build-up of participants that share the same characteristics. However, if you continue flipping the coin, over the long-term, there will be a balance of heads and tails. Unfortunately, how large a sample size is necessary has been the subject of considerable debate (Bloom, 2006; Shadish et al., 2002).
“It is well known that larger sample sizes reduce the probability that random assignment will result in conditions that are unequal” (Goldberg, 2019, p. 2).
Applications of Random Assignment
The importance of random assignment has been recognized in a wide range of scientific and applied disciplines (Bloom, 2006).
Random assignment began as a tool in agricultural research by Fisher (1925, 1935). After WWII, it became extensively used in medical research to test the effectiveness of new treatments and pharmaceuticals (Marks, 1997).
Today it is widely used in industrial engineering (Box, Hunter, and Hunter, 2005), educational research (Lindquist, 1953; Ong-Dean et al., 2011)), psychology (Myers, 1972), and social policy studies (Boruch, 1998; Orr, 1999).
One of the biggest obstacles to the validity of an experiment is the confound. If the group of participants in the treatment condition are substantially different from the group in the control condition, then it is impossible to determine if the IV has an affect or if the confound has an effect.
Thankfully, random assignment is highly effective at eliminating confounds that are known and unknown. Because each participant has an equal chance of being placed in each condition, they are equally distributed.
There are several ways of implementing random assignment, including flipping a coin or using a random number generator.
Random assignment has become an essential procedure in research in a wide range of subjects such as psychology, education, and social policy.
Alferes, V. R. (2012). Methods of randomization in experimental design . Sage Publications.
Bloom, H. S. (2008). The core analytics of randomized experiments for social research. The SAGE Handbook of Social Research Methods , 115-133.
Boruch, R. F. (1998). Randomized controlled experiments for evaluation and planning. Handbook of applied social research methods , 161-191.
Box, G. E., Hunter, W. G., & Hunter, J. S. (2005). Design of experiments: Statistics for Experimenters: Design, Innovation and Discovery.
Dehue, T. (1997). Deception, efficiency, and random groups: Psychology and the gradual origination of the random group design. Isis , 88 (4), 653-673.
Fisher, R.A. (1925). Statistical methods for research workers (11th ed. rev.). Oliver and Boyd: Edinburgh.
Fisher, R. A. (1935). The Design of Experiments. Edinburgh: Oliver and Boyd.
Goldberg, M. H. (2019). How often does random assignment fail? Estimates and recommendations. Journal of Environmental Psychology , 66 , 101351.
Jamison, J. C. (2019). The entry of randomized assignment into the social sciences. Journal of Causal Inference , 7 (1), 20170025.
Lindquist, E. F. (1953). Design and analysis of experiments in psychology and education . Boston: Houghton Mifflin Company.
Marks, H. M. (1997). The progress of experiment: Science and therapeutic reform in the United States, 1900-1990 . Cambridge University Press.
Myers, J. L. (1972). Fundamentals of experimental design (2nd ed.). Allyn & Bacon.
Ong-Dean, C., Huie Hofstetter, C., & Strick, B. R. (2011). Challenges and dilemmas in implementing random assignment in educational research. American Journal of Evaluation , 32 (1), 29-49.
Orr, L. L. (1999). Social experiments: Evaluating public programs with experimental methods . Sage.
Shadish, W. R., Cook, T. D., & Campbell, D. T. (2002). Quasi-experiments: interrupted time-series designs. Experimental and quasi-experimental designs for generalized causal inference , 171-205.
Stigler, S. M. (1992). A historical view of statistical concepts in psychology and educational research. American Journal of Education , 101 (1), 60-70.

Dave Cornell (PhD)
Dr. Cornell has worked in education for more than 20 years. His work has involved designing teacher certification for Trinity College in London and in-service training for state governments in the United States. He has trained kindergarten teachers in 8 countries and helped businessmen and women open baby centers and kindergartens in 3 countries.
- Dave Cornell (PhD) https://helpfulprofessor.com/author/dave-cornell-phd/ 25 Positive Punishment Examples
- Dave Cornell (PhD) https://helpfulprofessor.com/author/dave-cornell-phd/ 25 Dissociation Examples (Psychology)
- Dave Cornell (PhD) https://helpfulprofessor.com/author/dave-cornell-phd/ 15 Zone of Proximal Development Examples
- Dave Cornell (PhD) https://helpfulprofessor.com/author/dave-cornell-phd/ Perception Checking: 15 Examples and Definition

Chris Drew (PhD)
This article was peer-reviewed and edited by Chris Drew (PhD). The review process on Helpful Professor involves having a PhD level expert fact check, edit, and contribute to articles. Reviewers ensure all content reflects expert academic consensus and is backed up with reference to academic studies. Dr. Drew has published over 20 academic articles in scholarly journals. He is the former editor of the Journal of Learning Development in Higher Education and holds a PhD in Education from ACU.
- Chris Drew (PhD) #molongui-disabled-link 25 Positive Punishment Examples
- Chris Drew (PhD) #molongui-disabled-link 25 Dissociation Examples (Psychology)
- Chris Drew (PhD) #molongui-disabled-link 15 Zone of Proximal Development Examples
- Chris Drew (PhD) #molongui-disabled-link Perception Checking: 15 Examples and Definition
Leave a Comment Cancel Reply
Your email address will not be published. Required fields are marked *
What Is Random Assignment in Psychology?
Categories Research Methods
Random assignment means that every participant has the same chance of being chosen for the experimental or control group. It involves using procedures that rely on chance to assign participants to groups. Doing this means that every participant in a study has an equal opportunity to be assigned to any group.
For example, in a psychology experiment, participants might be assigned to either a control or experimental group. Some experiments might only have one experimental group, while others may have several treatment variations.
Using random assignment means that each participant has the same chance of being assigned to any of these groups.
Table of Contents
How to Use Random Assignment
So what type of procedures might psychologists utilize for random assignment? Strategies can include:
- Flipping a coin
- Assigning random numbers
- Rolling dice
- Drawing names out of a hat
How Does Random Assignment Work?
A psychology experiment aims to determine if changes in one variable lead to changes in another variable. Researchers will first begin by coming up with a hypothesis. Once researchers have an idea of what they think they might find in a population, they will come up with an experimental design and then recruit participants for their study.
Once they have a pool of participants representative of the population they are interested in looking at, they will randomly assign the participants to their groups.
- Control group : Some participants will end up in the control group, which serves as a baseline and does not receive the independent variables.
- Experimental group : Other participants will end up in the experimental groups that receive some form of the independent variables.
By using random assignment, the researchers make it more likely that the groups are equal at the start of the experiment. Since the groups are the same on other variables, it can be assumed that any changes that occur are the result of varying the independent variables.
After a treatment has been administered, the researchers will then collect data in order to determine if the independent variable had any impact on the dependent variable.
Random Assignment vs. Random Selection
It is important to remember that random assignment is not the same thing as random selection , also known as random sampling.
Random selection instead involves how people are chosen to be in a study. Using random selection, every member of a population stands an equal chance of being chosen for a study or experiment.
So random sampling affects how participants are chosen for a study, while random assignment affects how participants are then assigned to groups.
Examples of Random Assignment
Imagine that a psychology researcher is conducting an experiment to determine if getting adequate sleep the night before an exam results in better test scores.
Forming a Hypothesis
They hypothesize that participants who get 8 hours of sleep will do better on a math exam than participants who only get 4 hours of sleep.
Obtaining Participants
The researcher starts by obtaining a pool of participants. They find 100 participants from a local university. Half of the participants are female, and half are male.
Randomly Assign Participants to Groups
The researcher then assigns random numbers to each participant and uses a random number generator to randomly assign each number to either the 4-hour or 8-hour sleep groups.
Conduct the Experiment
Those in the 8-hour sleep group agree to sleep for 8 hours that night, while those in the 4-hour group agree to wake up after only 4 hours. The following day, all of the participants meet in a classroom.
Collect and Analyze Data
Everyone takes the same math test. The test scores are then compared to see if the amount of sleep the night before had any impact on test scores.
Why Is Random Assignment Important in Psychology Research?
Random assignment is important in psychology research because it helps improve a study’s internal validity. This means that the researchers are sure that the study demonstrates a cause-and-effect relationship between an independent and dependent variable.
Random assignment improves the internal validity by minimizing the risk that there are systematic differences in the participants who are in each group.
Key Points to Remember About Random Assignment
- Random assignment in psychology involves each participant having an equal chance of being chosen for any of the groups, including the control and experimental groups.
- It helps control for potential confounding variables, reducing the likelihood of pre-existing differences between groups.
- This method enhances the internal validity of experiments, allowing researchers to draw more reliable conclusions about cause-and-effect relationships.
- Random assignment is crucial for creating comparable groups and increasing the scientific rigor of psychological studies.

5 Chapter 5: Experimental and Quasi-Experimental Designs
Case stu dy: the impact of teen court.
Research Study
An Experimental Evaluation of Teen Courts 1
Research Question
Is teen court more effective at reducing recidivism and improving attitudes than traditional juvenile justice processing?
Methodology
Researchers randomly assigned 168 juvenile offenders ages 11 to 17 from four different counties in Maryland to either teen court as experimental group members or to traditional juvenile justice processing as control group members. (Note: Discussion on the technical aspects of experimental designs, including random assignment, is found in detail later in this chapter.) Of the 168 offenders, 83 were assigned to teen court and 85 were assigned to regular juvenile justice processing through random assignment. Of the 83 offenders assigned to the teen court experimental group, only 56 (67%) agreed to participate in the study. Of the 85 youth randomly assigned to normal juvenile justice processing, only 51 (60%) agreed to participate in the study.
Upon assignment to teen court or regular juvenile justice processing, all offenders entered their respective sanction. Approximately four months later, offenders in both the experimental group (teen court) and the control group (regular juvenile justice processing) were asked to complete a post-test survey inquiring about a variety of behaviors (frequency of drug use, delinquent behavior, variety of drug use) and attitudinal measures (social skills, rebelliousness, neighborhood attachment, belief in conventional rules, and positive self-concept). The study researchers also collected official re-arrest data for 18 months starting at the time of offender referral to juvenile justice authorities.
Teen court participants self-reported higher levels of delinquency than those processed through regular juvenile justice processing. According to official re-arrests, teen court youth were re-arrested at a higher rate and incurred a higher average number of total arrests than the control group. Teen court offenders also reported significantly lower scores on survey items designed to measure their “belief in conventional rules” compared to offenders processed through regular juvenile justice avenues. Other attitudinal and opinion measures did not differ significantly between the experimental and control group members based on their post-test responses. In sum, those youth randomly assigned to teen court fared worse than control group members who were not randomly assigned to teen court.
Limitations with the Study Procedure
Limitations are inherent in any research study and those research efforts that utilize experimental designs are no exception. It is important to consider the potential impact that a limitation of the study procedure could have on the results of the study.
In the current study, one potential limitation is that teen courts from four different counties in Maryland were utilized. Because of the diversity in teen court sites, it is possible that there were differences in procedure between the four teen courts and such differences could have impacted the outcomes of this study. For example, perhaps staff members at one teen court were more punishment-oriented than staff members at the other county teen courts. This philosophical difference may have affected treatment delivery and hence experimental group members’ belief in conventional attitudes and recidivism. Although the researchers monitored each teen court to help ensure treatment consistency between study sites, it is possible that differences existed in the day-to-day operation of the teen courts that may have affected participant outcomes. This same limitation might also apply to control group members who were sanctioned with regular juvenile justice processing in four different counties.
A researcher must also consider the potential for differences between the experimental and control group members. Although the offenders were randomly assigned to the experimental or control group, and the assumption is that the groups were equivalent to each other prior to program participation, the researchers in this study were only able to compare the experimental and control groups on four variables: age, school grade, gender, and race. It is possible that the experimental and control group members differed by chance on one or more factors not measured or available to the researchers. For example, perhaps a large number of teen court members experienced problems at home that can explain their more dismal post-test results compared to control group members without such problems. A larger sample of juvenile offenders would likely have helped to minimize any differences between the experimental and control group members. The collection of additional information from study participants would have also allowed researchers to be more confident that the experimental and control group members were equivalent on key pieces of information that could have influenced recidivism and participant attitudes.
Finally, while 168 juvenile offenders were randomly assigned to either the experimental or control group, not all offenders agreed to participate in the evaluation. Remember that of the 83 offenders assigned to the teen court experimental group, only 56 (67%) agreed to participate in the study. Of the 85 youth randomly assigned to normal juvenile justice processing, only 51 (60%) agreed to participate in the study. While this limitation is unavoidable, it still could have influenced the study. Perhaps those 27 offenders who declined to participate in the teen court group differed significantly from the 56 who agreed to participate. If so, it is possible that the differences among those two groups could have impacted the results of the study. For example, perhaps the 27 youths who were randomly assigned to teen court but did not agree to be a part of the study were some of the least risky of potential teen court participants—less serious histories, better attitudes to begin with, and so on. In this case, perhaps the most risky teen court participants agreed to be a part of the study, and as a result of being more risky, this led to more dismal delinquency outcomes compared to the control group at the end of each respective program. Because parental consent was required for the study authors to be able to compare those who declined to participate in the study to those who agreed, it is unknown if the participants and nonparticipants differed significantly on any variables among either the experimental or control group. Moreover, of the resulting 107 offenders who took part in the study, only 75 offenders accurately completed the post-test survey measuring offending and attitudinal outcomes.
Again, despite the experimental nature of this study, such limitations could have impacted the study results and must be considered.
Impact on Criminal Justice
Teen courts are generally designed to deal with nonserious first time offenders before they escalate to more serious and chronic delinquency. Innovative programs such as “Scared Straight” and juvenile boot camps have inspired an increase in teen court programs across the country, although there is little evidence regarding their effectiveness compared to traditional sanctions for youthful offenders. This study provides more specific evidence as to the effectiveness of teen courts relative to normal juvenile justice processing. Researchers learned that teen court participants fared worse than those in the control group. The potential labeling effects of teen court, including stigma among peers, especially where the offense may have been very minor, may be more harmful than doing less or nothing. The real impact of this study lies in the recognition that teen courts and similar sanctions for minor offenders may do more harm than good.
One important impact of this study is that it utilized an experimental design to evaluate the effectiveness of a teen court compared to traditional juvenile justice processing. Despite the study’s limitations, by using an experimental design it improved upon previous teen court evaluations by attempting to ensure any results were in fact due to the treatment, not some difference between the experimental and control group. This study also utilized both official and self-report measures of delinquency, in addition to self-report measures on such factors as self-concept and belief in conventional rules, which have been generally absent from teen court evaluations. The study authors also attempted to gauge the comparability of the experimental and control groups on factors such as age, gender, and race to help make sure study outcomes were attributable to the program, not the participants.
In This Chapter You Will Learn
The four components of experimental and quasi-experimental research designs and their function in answering a research question
The differences between experimental and quasi-experimental designs
The importance of randomization in an experimental design
The types of questions that can be answered with an experimental or quasi-experimental research design
About the three factors required for a causal relationship
That a relationship between two or more variables may appear causal, but may in fact be spurious, or explained by another factor
That experimental designs are relatively rare in criminal justice and why
About common threats to internal validity or alternative explanations to what may appear to be a causal relationship between variables
Why experimental designs are superior to quasi-experimental designs for eliminating or reducing the potential of alternative explanations
Introduction
The teen court evaluation that began this chapter is an example of an experimental design. The researchers of the study wanted to determine whether teen court was more effective at reducing recidivism and improving attitudes compared to regular juvenile justice case processing. In short, the researchers were interested in the relationship between variables —the relationship of teen court to future delinquency and other outcomes. When researchers are interested in whether a program, policy, practice, treatment, or other intervention impacts some outcome, they often utilize a specific type of research method/design called experimental design. Although there are many types of experimental designs, the foundation for all of them is the classic experimental design. This research design, and some typical variations of this experimental design, are the focus of this chapter.
Although the classic experiment may be appropriate to answer a particular research question, there are barriers that may prevent researchers from using this or another type of experimental design. In these situations, researchers may turn to quasi-experimental designs. Quasi-experiments include a group of research designs that are missing a key element found in the classic experiment and other experimental designs (hence the term “quasi” experiment). Despite this missing part, quasi-experiments are similar in structure to experimental designs and are used to answer similar types of research questions. This chapter will also focus on quasi-experiments and how they are similar to and different from experimental designs.
Uncovering the relationship between variables, such as the impact of teen court on future delinquency, is important in criminal justice and criminology, just as it is in other scientific disciplines such as education, biology, and medicine. Indeed, whereas criminal justice researchers may be interested in whether a teen court reduces recidivism or improves attitudes, medical field researchers may be concerned with whether a new drug reduces cholesterol, or an education researcher may be focused on whether a new teaching style leads to greater academic gains. Across these disciplines and topics of interest, the experimental design is appropriate. In fact, experimental designs are used in all scientific disciplines; the only thing that changes is the topic. Specific to criminal justice, below is a brief sampling of the types of questions that can be addressed using an experimental design:
Does participation in a correctional boot camp reduce recidivism?
What is the impact of an in-cell integration policy on inmate-on-inmate assaults in prisons?
Does police officer presence in schools reduce bullying?
Do inmates who participate in faith-based programming while in prison have a lower recidivism rate upon their release from prison?
Do police sobriety checkpoints reduce drunken driving fatalities?
What is the impact of a no-smoking policy in prisons on inmate-on-inmate assaults?
Does participation in a domestic violence intervention program reduce repeat domestic violence arrests?
A focus on the classic experimental design will demonstrate the usefulness of this research design for addressing criminal justice questions interested in cause and effect relationships. Particular attention is paid to the classic experimental design because it serves as the foundation for all other experimental and quasi-experimental designs, some of which are covered in this chapter. As a result, a clear understanding of the components, organization, and logic of the classic experimental design will facilitate an understanding of other experimental and quasi-experimental designs examined in this chapter. It will also allow the reader to better understand the results produced from those various designs, and importantly, what those results mean. It is a truism that the results of a research study are only as “good” as the design or method used to produce them. Therefore, understanding the various experimental and quasi-experimental designs is the key to becoming an informed consumer of research.
The Challenge of Establishing Cause and Effect
Researchers interested in explaining the relationship between variables, such as whether a treatment program impacts recidivism, are interested in causation or causal relationships. In a simple example, a causal relationship exists when X (independent variable) causes Y (dependent variable), and there are no other factors (Z) that can explain that relationship. For example, offenders who participated in a domestic violence intervention program (X–domestic violence intervention program) experienced fewer re-arrests (Y–re-arrests) than those who did not participate in the domestic violence program, and no other factor other than participation in the domestic violence program can explain these results. The classic experimental design is superior to other research designs in uncovering a causal relationship, if one exists. Before a causal relationship can be established, however, there are three conditions that must be met (see Figure 5.1). 2
FIGURE 5.1 | The Cause and Effect Relationship
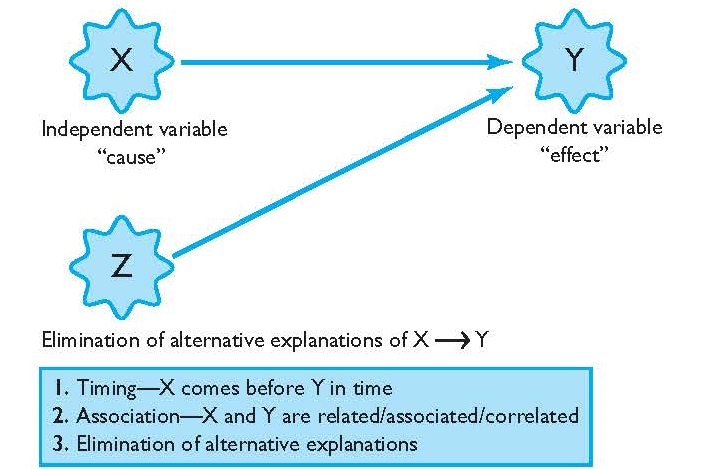
Timing The first condition for a causal relationship is timing. For a causal relationship to exist, it must be shown that the independent variable or cause (X) preceded the dependent variable or outcome (Y) in time. A decrease in domestic violence re-arrests (Y) cannot occur before participation in a domestic violence reduction program (X ), if the domestic violence program is proposed to be the cause of fewer re-arrests. Ensuring that cause comes before effect is not sufficient to establish that a causal relationship exists, but it is one requirement that must be met for a causal relationship.
Association In addition to timing, there must also be an observable association between X and Y, the second necessary condition for a causal relationship. Association is also commonly referred to as covariance or correlation. When an association or correlation exits, this means there is some pattern of relationship between X and Y —as X changes by increasing or decreasing, Y also changes by increasing or decreasing. Here, the notion of X and Y increasing or decreasing can mean an actual increase/decrease in the quantity of some factor, such as an increase/decrease in the number of prison terms or days in a program or re-arrests. It can also refer to an increase/decrease in a particular category, for example, from nonparticipation in a program to participation in a program. For instance, subjects who participated in a domestic violence reduction program (X) incurred fewer domestic violence re-arrests (Y) than those who did not participate in the program. In this example, X and Y are associated—as X change s or increases from nonparticipation to participation in the domestic violence program, Y or the number of re-arrests for domestic violence decreases.
Associations between X and Y can occur in two different directions: positive or negative. A positive association means that as X increases, Y increases, or, as X decreases, Y decreases. A negative association means that as X increases, Y decreases, or, as X decreases, Y increases. In the example above, the association is negative—participation in the domestic violence program was associated with a reduction in re-arrests. This is also sometimes called an inverse relationship.
Elimination of Alternative Explanations Although participation in a domestic violence program may be associated with a reduction in re-arrests, this does not mean for certain that participation in the program was the cause of reduced re-arrests. Just as timing by itself does not imply a causal relationship, association by itself does not imply a causal relationship. For example, instead of the program being the cause of a reduction in re-arrests, perhaps several of the program participants died shortly after completion of the domestic violence program and thus were not able to engage in domestic violence (and their deaths were unknown to the researcher tracking re-arrests). Perhaps a number of the program participants moved out of state and domestic violence re-arrests occurred but were not able to be uncovered by the researcher. Perhaps those in the domestic violence program experienced some other event, such as the trauma of a natural disaster, and that experience led to a reduction in domestic violence, an event not connected to the domestic violence program. If any of these situations occurred, it might appear that the domestic violence program led to fewer re-arrests. However, the observed reduction in re-arrests can actually be attributed to a factor unrelated to the domestic violence program.
The previous discussion leads to the third and final necessary consideration in determining a causal relationship— elimination of alternative explanations. This means that the researcher must rule out any other potential explanation of the results, except for the experimental condition such as a program, policy, or practice. Accounting for or ruling out alternative explanations is much more difficult than ensuring timing and association. Ruling out all alternative explanations is difficult because there are so many potential other explanations that can wholly or partly explain the findings of a research study. This is especially true in the social sciences, where researchers are often interested in relationships explaining human behavior. Because of this difficulty, associations by themselves are sometimes mistaken as causal relationships when in fact they are spurious. A spurious relationship is one where it appears that X and Y are causally related, but the relationship is actually explained by something other than the independent variable, or X.
One only needs to go so far as the daily newspaper to find headlines and stories of mere associations being mistaken, assumed, or represented as causal relationships. For example, a newspaper headline recently proclaimed “Churchgoers live longer.” 3 An uninformed consumer may interpret this headline as evidence of a causal relationship—that going to church by itself will lead to a longer life—but the astute consumer would note possible alternative explanations. For example, people who go to church may live longer because they tend to live healthier lifestyles and tend to avoid risky situations. These are two probable alternative explanations to the relationship independent of simply going to church. In another example, researchers David Kalist and Daniel Yee explored the relationship between first names and delinquent behavior in their manuscript titled “First Names and Crime: Does Unpopularity Spell Trouble?” 4 Kalist and Lee (2009) found that unpopular names are associated with juvenile delinquency. In other words, those individuals with the most unpopular names were more likely to be delinquent than those with more popular names. According to the authors, is it not necessarily someone’s name that leads to delinquent behavior, but rather, the most unpopular names also tend to be correlated with individuals who come from disadvantaged home environments and experience a low socio-economic status of living. Rightly noted by the authors, these alternative explanations help to explain the link between someone’s name and delinquent behavior—a link that is not causal.
A frequently cited example provides more insight to the claim that an association by itself is not sufficient to prove causality. In certain cities in the United States, for example, as ice cream sales increase on a particular day or in a particular month so does the incidence of certain forms of crime. If this association were represented as a causal statement, it would be that ice cream or ice cream sales causes crime. There is an association, no doubt, and let us assume that ice cream sales rose before the increase in crime (timing). Surely, however, this relationship between ice cream sales and crime is spurious. The alternative explanation is that ice cream sales and crime are associated in certain parts of the country because of the weather. Ice cream sales tend to increase in warmer temperatures, and it just so happens that certain forms of crime tend to increase in warmer temperatures as well. This coincidence or association does not mean a causal relationship exists. Additionally, this does not mean that warm temperatures cause crime either. There are plenty of other alternative explanations for the increase in certain forms of crime and warmer temperatures. 6 For another example of a study subject to alternative explanations, read the June 2011 news article titled “Less Crime in U.S. Thanks to Videogames.” 7 Based on your reading, what are some other potential explanations for the crime drop other than videogames?
The preceding examples demonstrate how timing and association can be present, but the final needed condition for a causal relationship is that all alternative explanations are ruled out. While this task is difficult, the classic experimental design helps to ensure these additional explanatory factors are minimized. When other designs are used, such as quasi-experimental designs, the chance that alternative explanations emerge is greater. This potential should become clearer as we explore the organization and logic of the classic experimental design.
CLASSICS IN CJ RESEARCH
Minneapolis Domestic Violence Experiment
The Minneapolis Domestic Violence Experiment (MDVE) 5
Which police action (arrest, separation, or mediation) is most effective at deterring future misdemeanor domestic violence?
The experiment began on March 17, 1981, and continued until August 1, 1982. The experiment was conducted in two of Minneapolis’s four police precincts—the two with the highest number of domestic violence reports and arrests. A total of 314 reports of misdemeanor domestic violence were handled by the police during this time frame.
This study utilized an experimental design with the random assignment of police actions. Each police officer involved in the study was given a pad of report forms. Upon a misdemeanor domestic violence call, the officer’s action (arrest, separation, or mediation) was predetermined by the order and color of report forms in the officer’s notebook. Colored report forms were randomly ordered in the officer’s notebook and the color on the form determined the officer response once at the scene. For example, after receiving a call for domestic violence, an officer would turn to his or her report pad to determine the action. If the top form was pink, the action was arrest. If on the next call the top form was a different color, an action other than arrest would occur. All colored report forms were randomly ordered through a lottery assignment method. The result is that all police officer actions to misdemeanor domestic violence calls were randomly assigned. To ensure the lottery procedure was properly carried out, research staff participated in ride-alongs with officers to ensure that officers did not skip the order of randomly ordered forms. Research staff also made sure the reports were received in the order they were randomly assigned in the pad of report forms.
To examine the relationship of different officer responses to future domestic violence, the researchers examined official arrests of the suspects in a 6-month follow-up period. For example, the researchers examined those initially arrested for misdemeanor domestic violence and how many were subsequently arrested for domestic violence within a 6-month time frame. They did the same procedure for the police actions of separation and mediation. The researchers also interviewed the victim(s) of each incident and asked if a repeat domestic violence incident occurred with the same suspect in the 6-month follow-up period. This allowed researchers to examine domestic violence offenses that may have occurred but did not come to the official attention of police. The researchers then compared official arrests for domestic violence to self-reported domestic violence after the experiment.
Suspects arrested for misdemeanor domestic violence, as opposed to situations where separation or mediation was used, were significantly less likely to engage in repeat domestic violence as measured by official arrest records and victim interviews during the 6-month follow-up period. According to official police records, 10% of those initially arrested engaged in repeat domestic violence in the followup period, 19% of those who initially received mediation engaged in repeat domestic violence, and 24% of those who randomly received separation engaged in repeat domestic violence. According to victim interviews, 19% of those initially arrested engaged in repeat domestic violence, compared to 37% for separation and 33% for mediation. The general conclusion of the experiment was that arrest was preferable to separation or mediation in deterring repeat domestic violence across both official police records and victim interviews.
A few issues that affected the random assignment procedure occurred throughout the study. First, some officers did not follow the randomly assigned action (arrest, separation, or mediation) as a result of other circumstances that occurred at the scene. For example, if the randomly assigned action was separation, but the suspect assaulted the police officer during the call, the officer might arrest the suspect. Second, some officers simply ignored the assigned action if they felt a particular call for domestic violence required another action. For example, if the action was mediation as indicated by the randomly assigned report form, but the officer felt the suspect should be arrested, he or she may have simply ignored the randomly assigned response and substituted his or her own. Third, some officers forgot their report pads and did not know the randomly assigned course of action to take upon a call of domestic violence. Fourth and finally, the police chief also allowed officers to deviate from the randomly assigned action in certain circumstances. In all of these situations, the random assignment procedures broke down.
The results of the MDVE had a rapid and widespread impact on law enforcement practice throughout the United States. Just two years after the release of the study, a 1986 telephone survey of 176 urban police departments serving cities with populations of 100,000 or more found that 46 percent of the departments preferred to make arrests in cases of minor domestic violence, largely due to the effectiveness of this practice in the Minneapolis Domestic Violence Experiment. 8
In an attempt to replicate the findings of the Minneapolis Domestic Violence Experiment, the National Institute of Justice sponsored the Spouse Assault Replication Program. Replication studies were conducted in Omaha, Charlotte, Milwaukee, Miami, and Colorado Springs from 1986–1991. In three of the five replications, offenders randomly assigned to the arrest group had higher levels of continued domestic violence in comparison to other police actions during domestic violence situations. 9 Therefore, rather than providing results that were consistent with the Minneapolis Domestic Violence Experiment, the results from the five replication experiments produced inconsistent findings about whether arrest deters domestic violence. 10
Despite the findings of the replications, the push to arrest domestic violence offenders has continued in law enforcement. Today many police departments require officers to make arrests in domestic violence situations. In agencies that do not mandate arrest, department policy typically states a strong preference toward arrest. State legislatures have also enacted laws impacting police actions regarding domestic violence. Twenty-one states have mandatory arrest laws while eight have pro-arrest statutes for domestic violence. 11
The Classic Experimental Design
Table 5.1 provides an illustration of the classic experimental design. 12 It is important to become familiar with the specific notation and organization of the classic experiment before a full discussion of its components and their purpose.
Major Components of the Classic Experimental Design
The classic experimental design has four major components:
1. Treatment
2. Experimental Group and Control Group
3. Pre-Test and Post-Test
4. Random Assignment
Treatment The first component of the classic experimental design is the treatment, and it is denoted by X in the classic experimental design. The treatment can be a number of things—a program, a new drug, or the implementation of a new policy. In a classic experimental design, the primary goal is to determine what effect, if any, a particular treatment had on some outcome. In this way, the treatment can also be considered the independent variable.
TABLE 5.1 | The Classic Experimental Design
Experimental Group = Group that receives the treatment
Control Group = Group that does not receive the treatment
R = Random assignment
O 1 = Observation before the treatment, or the pre-test
X = Treatment or the independent variable
O 2 = Observation after the treatment, or the post-test
Experimental and Control Groups The second component of the classic experiment is an experimental group and a control group. The experimental group receives the treatment, and the control group does not receive the treatment. There will always be at least one group that receives the treatment in experimental and quasi-experimental designs. In some cases, experiments may have multiple experimental groups receiving multiple treatments.
Pre-Test and Post-Test The third component of the classic experiment is a pre-test and a post-test. A pretest is a measure of the dependent variable or outcome before the treatment. The post-test is a measure of the dependent variable after the treatment is administered. It is important to note that the post-test is defined based on the stated goals of the program. For example, if the stated goal of a particular program is to reduce re-arrests, the post-test will be a measure of re-arrests after the program. The dependent variable also defines the pre-test. For example, if a researcher wanted to examine the impact of a domestic violence reduction program (treatment or X) on the goal of reducing re-arrests (dependent variable or Y), the pre-test would be the number of domestic violence arrests incurred before the program. Program goals may be numerous and all can constitute a post-test, and hence, the pre-test. For example, perhaps the goal of the domestic violence program is also that participants learn of different pro-social ways to handle domestic conflicts other than resorting to violence. If researchers wanted to examine this goal, the post-test might be subjects’ level of knowledge about pro-social ways to handle domestic conflicts other than violence. The pre-test would then be subjects’ level of knowledge about these pro-social alternatives to violence before they received the treatment program.
Although all designs have a post-test, it is not always the case that designs have a pre-test. This is because researchers may not have access or be able to collect information constituting the pre-test. For example, researchers may not be able to determine subjects’ level of knowledge about alternatives to domestic violence before the intervention program if the subjects are already enrolled in the domestic violence intervention program. In other cases, there may be financial barriers to collecting pre-test information. In the teen court evaluation that started this chapter, for example, researchers were not able to collect pre-test information on study participants due to the financial strain it would have placed on the agencies involved in the study. 13 There are a number of potential reasons why a pre-test might not be available in a research study. The defining feature, however, is that the pre-test is determined by the post-test.
Random Assignment The fourth component of the classic experiment is random assignment. Random assignment refers to a process whereby members of the experimental group and control group are assigned to the two groups through a random and unbiased process. Random assignment should not be mistaken for random selection as discussed in Chapter 3. Random selection refers to selecting a smaller but representative sample from a larger population. For example, a researcher may randomly select a sample from a larger city population for the purposes of sending sample members a mail survey to determine their attitudes on crime. The goal of random selection in this example is to make sure the sample, although smaller in size than the population, accurately represents the larger population.
Random assignment, on the other hand, refers to the process of assigning subjects to either the experimental or control group with the goal that the groups are similar or equivalent to each other in every way (see Figure 5.2). The exception to this rule is that one group gets the treatment and the other does not (see discussion below on why equivalence is so important). Although the concept of random is similar in each, the goals are different between random selection and random assignment. 14 Experimental designs all feature random assignment, but this is not true of other research designs, in particular quasi-experimental designs.
FIGURE 5.2 | Random Assignment
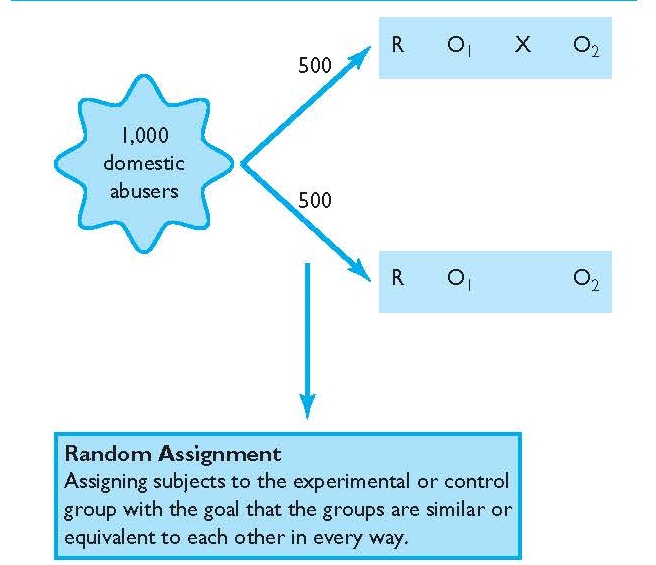
The classic experimental design is the foundation for all other experimental and quasi-experimental designs because it retains all of the major components discussed above. As mentioned, sometimes designs do not have a pre-test, a control group, or random assignment. Because the pre-test, control group, and random assignment are so critical to the goal of uncovering a causal relationship, if one exists, we explore them further below.
The Logic of the Classic Experimental Design
Consider a research study using the classic experimental design where the goal is to determine if a domestic violence treatment program has any effect on re-arrests for domestic violence. The randomly assigned experimental and control groups are comprised of persons who had previously been arrested for domestic violence. The pretest is a measure of the number of domestic violence arrests before the program. This is because the goal of the program is to determine whether re-arrests are impacted after the treatment. The post-test is the number of re-arrests following the treatment program.
Once randomly assigned, the experimental group members receive the domestic violence program, and the control group members do not. After the program, the researcher will compare the pre-test arrests for domestic violence of the experimental group to post-test arrests for domestic violence to determine if arrests increased, decreased, or remained constant since the start of the program. The researcher will also compare the post-test re-arrests for domestic violence between the experimental and control groups. With this example, we explore the usefulness of the classic experimental design, and the contribution of the pre-test, random assignment, and the control group to the goal of determining whether a domestic violence program reduces re-arrests.
The Pre-Test As a component of the classic experiment, the pre-test allows an examination of change in the dependent variable from before the domestic violence program to after the domestic violence program. In short, a pre-test allows the researcher to determine if re-arrests increased, decreased, or remained the same following the domestic violence program. Without a pre-test, researchers would not be able to determine the extent of change, if any, from before to after the program for either the experimental or control group.
Although the pre-test is a measure of the dependent variable before the treatment, it can also be thought of as a measure whereby the researcher can compare the experimental group to the control group before the treatment is administered. For example, the pre-test helps researchers to make sure both groups are similar or equivalent on previous arrests for domestic violence. The importance of equivalence between the experimental and control groups on previous arrests is discussed below with random assignment.
Random Assignment Random assignment helps to ensure that the experimental and control groups are equivalent before the introduction of the treatment. This is perhaps one of the most critical aspects of the classic experiment and all experimental designs. Although the experimental and control groups will be made up of different people with different characteristics, assigning them to groups via a random assignment process helps to ensure that any differences or bias between the groups is eliminated or minimized. By minimizing bias, we mean that the groups will balance each other out on all factors except the treatment. If they are balanced out on all factors prior to the administration of the treatment, any differences between the groups at the post-test must be due to the treatment—the only factor that differs between the experimental group and the control group. According to Shadish, Cook, and Campbell: “If implemented correctly, random assignment creates two or more groups of units that are probabilistically similar to each other on the average. Hence, any outcome differences that are observed between those groups at the end of a study are likely to be due to treatment, not to differences between the groups that already existed at the start of the study.” 15 Considered in another way, if the experimental and control group differed significantly on any relevant factor other than the treatment, the researcher would not know if the results observed at the post-test are attributable to the treatment or to the differences between the groups.
Consider an example where 500 domestic abusers were randomly assigned to the experimental group and 500 were randomly assigned to the control group. Because they were randomly assigned, we would likely find more frequent domestic violence arrestees in both groups, older and younger arrestees in both groups, and so on. If random assignment was implemented correctly, it would be highly unlikely that all of the experimental group members were the most serious or frequent arrestees and all of the control group members were less serious and/or less frequent arrestees. While there are no guarantees, we know the chance of this happening is extremely small with random assignment because it is based on known probability theory. Thus, except for a chance occurrence, random assignment will result in equivalence between the experimental and control group in much the same way that flipping a coin multiple times will result in heads approximately 50% of the time and tails approximately 50% of the time. Over 1,000 tosses of a coin, for example, should result in roughly 500 heads and 500 tails. While there is a chance that flipping a coin 1,000 times will result in heads 1,000 times, or some other major imbalance between heads and tails, this potential is small and would only occur by chance.
The same logic from above also applies with randomly assigning people to groups, and this can even be done by flipping a coin. By assigning people to groups through a random and unbiased process, like flipping a coin, only by chance (or researcher error) will one group have more of one characteristic than another, on average. If there are no major (also called statistically significant) differences between the experimental and control group before the treatment, the most plausible explanation for the results at the post-test is the treatment.
As mentioned, it is possible by some chance occurrence that the experimental and control group members are significantly different on some characteristic prior to administration of the treatment. To confirm that the groups are in fact similar after they have been randomly assigned, the researcher can examine the pre-test if one is present. If the researcher has additional information on subjects before the treatment is administered, such as age, or any other factor that might influence post-test results at the end of the study, he or she can also compare the experimental and control group on those measures to confirm that the groups are equivalent. Thus, a researcher can confirm that the experimental and control groups are equivalent on information known to the researcher.
Being able to compare the groups on known measures is an important way to ensure the random assignment process “worked.” However, perhaps most important is that randomization also helps to ensure similarity across unknown variables between the experimental and control group. Because random assignment is based on known probability theory, there is a much higher probability that all potential differences between the groups that could impact the post-test should balance out with random assignment—known or unknown. Without random assignment, it is likely that the experimental and control group would differ on important but unknown factors and such differences could emerge as alternative explanations for the results. For example, if a researcher did not utilize random assignment and instead took the first 500 domestic abusers from an ordered list and assigned them to the experimental group and the last 500 domestic abusers and assigned them to the control group, one of the groups could be “lopsided” or imbalanced on some important characteristic that could impact the outcome of the study. With random assignment, there is a much higher likelihood that these important characteristics among the experimental and control groups will balance out because no individual has a different chance of being placed into one group versus the other. The probability of one or more characteristics being concentrated into one group and not the other is extremely small with random assignment.
To further illustrate the importance of random assignment to group equivalence, suppose the first 500 domestic violence abusers who were assigned to the experimental group from the ordered list had significantly fewer domestic violence arrests before the program than the last 500 domestic violence abusers on the list. Perhaps this is because the ordered list was organized from least to most chronic domestic abusers. In this instance, the control group would be lopsided concerning number of pre-program domestic violence arrests—they would be more chronic than the experimental group. The arrest imbalance then could potentially explain the post-test results following the domestic violence program. For example, the “less risky” offenders in the experimental group might be less likely to be re-arrested regardless of their participation in the domestic violence program, especially compared to the more chronic domestic abusers in the control group. Because of imbalances between the experimental and control group on arrests before the program was implemented, it would not be known for certain whether an observed reduction in re-arrests after the program for the experimental group was due to the program or the natural result of having less risky offenders in the experimental group. In this instance, the results might be taken to suggest that the program significantly reduces re-arrests. This conclusion might be spurious, however, for the association may simply be due to the fact that the offenders in the experimental group were much different (less frequent offenders) than the control group. Here, the program may have had no effect—the experimental group members may have performed the same regardless of the treatment because they were low-level offenders.
The example above suggests that differences between the experimental and control groups based on previous arrest records could have a major impact on the results of a study. Such differences can arise with the lack of random assignment. If subjects were randomly assigned to the experimental and control group, however, there would be a much higher probability that less frequent and more frequent domestic violence arrestees would have been found in both the experimental and control groups and the differences would have balanced out between the groups—leaving any differences between the groups at the post-test attributable to the treatment only.
In summary, random assignment helps to ensure that the experimental and control group members are balanced or equivalent on all factors that could impact the dependent variable or post-test—known or unknown. The only factor they are not balanced or equal on is the treatment. As such, random assignment helps to isolate the impact of the treatment, if any, on the post-test because it increases confidence that the only difference between the groups should be that one group gets the treatment and the other does not. If that is the only difference between the groups, any change in the dependent variable between the experimental and control group must be attributed to the treatment and not an alternative explanation, such as significant arrest history imbalance between the groups (refer to Figure 5.2). This logic also suggests that if the experimental group and control group are imbalanced on any factor that may be relevant to the outcome, that factor then becomes a potential alternative explanation for the results—an explanation that reduces the researcher’s ability to isolate the real impact of the treatment.
WHAT RESEARCH SHOWS: IMPACTING CRIMINAL JUSTICE OPERATIONS
Scared Straight
The 1978 documentary Scared Straight introduced to the public the “Lifer’s Program” at Rahway State Prison in New Jersey. This program sought to decrease juvenile delinquency by bringing at-risk and delinquent juveniles into the prison where they would be “scared straight” by inmates serving life sentences. Participants in the program were talked to and yelled at by the inmates in an effort to scare them. It was believed that the fear felt by the participants would lead to a discontinuation of their problematic behavior so that they would not end up in prison themselves. Although originally touted as a success based on anecdotal evidence, subsequent evaluations of the program and others like it proved otherwise.
Using a classic experimental design, Finckenauer evaluated the original “Lifer’s Program” at Rahway State Prison. 16 Participating juveniles were randomly assigned to the experimental group or the control group. Results of the evaluation were not positive. Post-test measures revealed that juveniles who were assigned to the experimental group and participated in the program were actually more seriously delinquent afterwards than those who did not participate in the program. Also using an experimental design with random assignment, Yarborough evaluated the “Juvenile Offenders Learn Truth” (JOLT) program at the State Prison of Southern Michigan at Jackson. 17 This program was similar to that of the “Lifer’s Program” only with fewer obscenities used by the inmates. Post-test measurements were taken at two intervals, 3 and 6 months after program completion. Again, results were not positive. Findings revealed no significant differences between those juveniles who attended the program and those who did not.
Other experiments conducted on Scared Straight -like programs further revealed their inability to deter juveniles from future criminality. 18 Despite the intuitive popularity of these programs, these evaluations proved that such programs were not successful. In fact, it is postulated that these programs may have actually done more harm than good.
The Control Group The presence of an equivalent control group (created through random assignment) also gives the researcher more confidence that the findings at the post-test are due to the treatment and not some other alternative explanation. This logic is perhaps best demonstrated by considering how interpretation of results is affected without a control group. Absent an equivalent control group, it cannot be known whether the results of the study are due to the program or some other factor. This is because the control group provides a baseline of comparison or a “control.” For example, without a control group, the researcher may find that domestic violence arrests declined from pre-test to post-test. But the researcher would not be able to definitely attribute that finding to the program without a control group. Perhaps the single experimental group incurred fewer arrests because they matured over their time in the program, regardless of participation in the domestic violence program. Having a randomly assigned control group would allow this consideration to be eliminated, because the equivalent control group would also have naturally matured if that was the case.
Because the control group is meant to be similar to the experimental group on all factors with the exception that the experimental group receives the treatment, the logic is that any differences between the experimental and control group after the treatment must then be attributable only to the treatment itself—everything else occurs equally in both the experimental and control groups and thus cannot be the cause of results. The bottom line is that a control group allows the researcher more confidence to attribute any change in the dependent variable from pre- to post-test and between the experimental and control groups to the treatment—and not another alternative explanation. Absent a control group, the researcher would have much less confidence in the results.
Knowledge about the major components of the classic experimental design and how they contribute to an understanding of cause and effect serves as an important foundation for studying different types of experimental and quasi-experimental designs and their organization. A useful way to become familiar with the components of the experimental design and their important role is to consider the impact on the interpretation of results when one or more components are lacking. For example, what if a design lacked a pre-test? How could this impact the interpretation of post-test results and knowledge about the comparability of the experimental and control group? What if a design lacked random assignment? What are some potential problems that could occur and how could those potential problems impact interpretation of results? What if a design lacked a control group? How does the absence of an equivalent control group affect a researcher’s ability to determine the unique effects of the treatment on the outcomes being measured? The ability to discuss the contribution of a pre-test, random assignment, and a control group—and what is the impact when one or more of those components is absent from a research design—is the key to understanding both experimental and quasi-experimental designs that will be discussed in the remainder of this chapter. As designs lose these important parts and transform from a classic experiment to another experimental design or to a quasi-experiment, they become less useful in isolating the impact that a treatment has on the dependent variable and allow more room for alternative explanations of the results.
One more important point must be made before further delving into experimental and quasi-experimental designs. This point is that rarely, if ever, will the average consumer of research be exposed to the symbols or specific language of the classic experiment, or other experimental and quasi-experimental designs examined in this chapter. In fact, it is unlikely that the average consumer will ever be exposed to the terms pre-test, post-test, experimental group, or random assignment in the popular media, among other terms related to experimental and quasi-experimental designs. Yet, consumers are exposed to research results produced from these and other research designs every day. For example, if a national news organization or your regional newspaper reported a story about the effectiveness of a new drug to reduce cholesterol or the effects of different diets on weight loss, it is doubtful that the results would be reported as produced through a classic experimental design that used a control group and random assignment. Rather, these media outlets would use generally nonscientific terminology such as “results of an experiment showed” or “results of a scientific experiment indicated” or “results showed that subjects who received the new drug had greater cholesterol reductions than those who did not receive the new drug.” Even students who regularly search and read academic articles for use in course papers and other projects will rarely come across such design notation in the research studies they utilize. Depiction of the classic experimental design, including a discussion of its components and their function, simply illustrates the organization and notation of the classic experimental design. Unfortunately, the average consumer has to read between the lines to determine what type of design was used to produce the reported results. Understanding the key components of the classic experimental design allows educated consumers of research to read between those lines.
RESEARCH IN THE NEWS
“Swearing Makes Pain More Tolerable” 19
In 2009, Richard Stephens, John Atkins, and Andrew Kingston of the School of Psychology at Keele University conducted a study with 67 undergraduate students to determine if swearing affects an individual’s response to pain. Researchers asked participants to immerse their hand in a container filled with ice-cold water and repeat a preferred swear word. The researchers then asked the same participants to immerse their hand in ice-cold water while repeating a word used to describe a table (a non-swear word). The results showed that swearing increased pain tolerance compared to the non-swearing condition. Participants who used a swear word were able to hold their hand in ice-cold water longer than when they did not swear. Swearing also decreased participants’ perception of pain.
1. This study is an example of a repeated measures design. In this form of experimental design, study participants are exposed to an experimental condition (swearing with hand in ice-cold water) and a control condition (non-swearing with hand in ice-cold water) while repeated outcome measures are taken with each condition, for example, the length of time a participant was able to keep his or her hand submerged in ice-cold water. Conduct an Internet search for “repeated measures design” and explore the various ways such a study could be conducted, including the potential benefits and drawbacks to this design.
2. After researching repeated measures designs, devise a hypothetical repeated measures study of your own.
3. Retrieve and read the full research study “Swearing as a Response to Pain” by Stephens, Atkins, and Kingston while paying attention to the design and methods (full citation information for this study is listed below). Has your opinion of the study results changed after reading the full study? Why or why not?
Full Study Source: Stephens, R., Atkins, J., and Kingston, A. (2009). “Swearing as a response to pain.” NeuroReport 20, 1056–1060.
Variations on the Experimental Design
The classic experimental design is the foundation upon which all experimental and quasi-experimental designs are based. As such, it can be modified in numerous ways to fit the goals (or constraints) of a particular research study. Below are two variations of the experimental design. Again, knowledge about the major components of the classic experiment, how they contribute to an explanation of results, and what the impact is when one or more components are missing provides an understanding of all other experimental designs.
Post-Test Only Experimental Design
The post-test only experimental design could be used to examine the impact of a treatment program on school disciplinary infractions as measured or operationalized by referrals to the principal’s office (see Table 5.2). In this design, the researcher randomly assigns a group of discipline problem students to the experimental group and control group by flipping a coin—heads to the experimental group and tails to the control group. The experimental group then enters the 3-month treatment program. After the program, the researcher compares the number of referrals to the principal’s office between the experimental and control groups over some period of time, for example, discipline referrals at 6 months after the program. The researcher finds that the experimental group has a much lower number of referrals to the principal’s office in the 6 month follow-up period than the control group.
TABLE 5.2 | Post-Test Only Experimental Design
Several issues arise in this example study. The researcher would not know if discipline problems decreased, increased, or stayed the same from before to after the treatment program because the researcher did not have a count of disciplinary referrals prior to the treatment program (e.g., a pre-test). Although the groups were randomly assigned and are presumed equivalent, the absence of a pre-test means the researcher cannot confirm that the experimental and control groups were equivalent before the treatment was administered, particularly on the number of referrals to the principal’s office. The groups could have differed by a chance occurrence even with random assignment, and any such differences between the groups could potentially explain the post-test difference in the number of referrals to the principal’s office. For example, if the control group included much more serious or frequent discipline problem students than the experimental group by chance, this difference might explain the lower number of referrals for the experimental group, not that the treatment produced this result.
Experimental Design with Two Treatments and a Control Group
This design could be used to determine the impact of boot camp versus juvenile detention on post-release recidivism (see Table 5.3). Recidivism in this study is operationalized as re-arrest for delinquent behavior. First, a population of known juvenile delinquents is randomly assigned to either boot camp, juvenile detention, or a control condition where they receive no sanction. To accomplish random assignment to groups, the researcher places the names of all youth into a hat and assigns the groups in order. For example, the first name pulled goes into experimental group 1, the next into experimental group 2, and the next into the control group, and so on. Once randomly assigned, the experimental group youth receive either boot camp or juvenile detention for a period of 3 months, whereas members of the control group are released on their own recognizance to their parents. At the end of the experiment, the researcher compares the re-arrest activity of boot camp participants to detention delinquents to control group members during a 6-month follow-up period.
TABLE 5.3 | Experimental Design with Two Treatments and a Control Group
This design has several advantages. First, it includes all major components of the classic experimental design, and simply adds an additional treatment for comparison purposes. Random assignment was utilized and this means that the groups have a higher probability of being equivalent on all factors that could impact the post-test. Thus, random assignment in this example helps to ensure the only differences between the groups are the treatment conditions. Without random assignment, there is a greater chance that one group of youth was somehow different, and this difference could impact the post-test. For example, if the boot camp youth were much less serious and frequent delinquents than the juvenile detention youth or control group youth, the results might erroneously show that the boot camp reduced recidivism when in fact the youth in boot camp may have been the “best risks”—unlikely to get re-arrested with or without boot camp. The pre-test in the example above allows the researcher to determine change in re-arrests from pretest to post-test. Thus, the researcher can determine if delinquent behavior, as measured by re-arrest, increased, decreased, or remained constant from pre- to post-test. The pre-test also allows the researcher to confirm that the random assignment process resulted in equivalent groups based on the pre-test. Finally, the presence of a control group allows the researcher to have more confidence that any differences in the post-test are due to the treatment. For example, if the control group had more re-arrests than the boot camp or juvenile detention experimental groups 6 months after their release from those programs, the researcher would have more confidence that the programs produced fewer re-arrests because the control group members were the same as the experimental groups; the only difference was that they did not receive a treatment.
The one key feature of experimental designs is that they all retain random assignment. This is why they are considered “experimental” designs. Sometimes, however, experimental designs lack a pre-test. Knowledge of the usefulness of a pre-test demonstrates the potential problems with those designs where it is missing. For example, in the post-test only experimental design, a researcher would not be able to make a determination of change in the dependent variable from pre- to post-test. Perhaps most importantly, the researcher would not be able to confirm that the experimental and control groups were in fact equivalent on a pre-test measure before the introduction of the treatment. Even though both groups were randomly assigned, and probability theory suggests they should be equivalent, without a pre-test measure the researcher could not confirm similarity because differences could occur by chance even with random assignment. If there were any differences at the post-test between the experimental group and control group, the results might be due to some explanation other than the treatment, namely that the groups differed prior to the administration of the treatment. The same limitation could apply in any form of experimental design that does not utilize a pre-test for conformational purposes.
Understanding the contribution of a pre-test to an experimental design shows that it is a critical component. It provides a measure of change and also gives the researcher more confidence that the observed results are due to the treatment, and not some difference between the experimental and control groups. Despite the usefulness of a pre-test, however, perhaps the most critical ingredient of any experimental design is random assignment. It is important to note that all experimental designs retain random assignment.
Experimental Designs Are Rare in Criminal Justice and Criminology
The classic experiment is the foundation for other types of experimental and quasi-experimental designs. The unfortunate reality, however, is that the classic experiment, or other experimental designs, are few and far between in criminal justice. 20 Recall that one of the major components of an experimental design is random assignment. Achieving random assignment is often a barrier to experimental research in criminal justice. Achieving random assignment might, for example, require the approval of the chief (or city council or both) of a major metropolitan police agency to allow researchers to randomly assign patrol officers to certain areas of a city and/or randomly assign police officer actions. Recall the MDVE. This experiment required the full cooperation of the chief of police and other decision-makers to allow researchers to randomly assign police actions. In another example, achieving random assignment might require a judge to randomly assign a group of youthful offenders to a certain juvenile court sanction (experimental group), and another group of similar youthful offenders to no sanction or an alternative sanction as a control group. 21 In sum, random assignment typically requires the cooperation of a number of individuals and sometimes that cooperation is difficult to obtain.
Even when random assignment can be accomplished, sometimes it is not implemented correctly and the random assignment procedure breaks down. This is another barrier to conducting experimental research. For example, in the MDVE, researchers randomly assigned officer responses, but the officers did not always follow the assigned course of action. Moreover, some believe that the random assignment of criminal justice programs, sentences, or randomly assigning officer responses may be unethical in certain circumstances, and even a violation of the rights of citizens. For example, some believe it is unfair when random assignment results in some delinquents being sentenced to boot camp while others get assigned to a control group without any sanction at all or a less restrictive sanction than boot camp. In the MDVE, some believe it is unfair that some suspects were arrested and received an official record whereas others were not arrested for the same type of behavior. In other cases, subjects in the experimental group may receive some benefit from the treatment that is essentially denied to the control group for a period of time and this can become an issue as well.
There are other important reasons why random assignment is difficult to accomplish. Random assignment may, for example, involve a disruption of the normal procedures of agencies and their officers. In the MDVE, officers had to adjust their normal and established routine, and this was a barrier at times in that study. Shadish, Cook, and Campbell also note that random assignment may not always be feasible or desirable when quick answers are needed. 22 This is because experimental designs sometimes take a long time to produce results. In addition to the time required in planning and organizing the experiment, and treatment delivery, researchers may need several months if not years to collect and analyze the data before they have answers. This is particularly important because time is often of the essence in criminal justice research, especially in research efforts testing the effect of some policy or program where it is not feasible to wait years for answers. Waiting for the results of an experimental design means that many policy-makers may make decisions without the results.
Quasi-Experimental Designs
In general terms, quasi-experiments include a group of designs that lack random assignment. Quasi-experiments may also lack other parts, such as a pre-test or a control group, just like some experimental designs. The absence of random assignment, however, is the ingredient that transforms an otherwise experimental design into a quasi-experiment. Lacking random assignment is a major disadvantage because it increases the chances that the experimental and control groups differ on relevant factors before the treatment—both known and unknown—differences that may then emerge as alternative explanations of the outcomes.
Just like experimental designs, quasi-experimental designs can be organized in many different ways. This section will discuss three types of quasi-experiments: nonequivalent group design, one-group longitudinal design, and two-group longitudinal design.
Nonequivalent Group Design
The nonequivalent group design is perhaps the most common type of quasi-experiment. 23 Notice that it is very similar to the classic experimental design with the exception that it lacks random assignment (see Table 5.4). Additionally, what was labeled the experimental group in an experimental design is sometimes called the treatment group in the nonequivalent group design. What was labeled the control group in the experimental design is sometimes called the comparison group in the nonequivalent group design. This terminological distinction is an indicator that the groups were not created through random assignment.
TABLE 5.4 | Nonequivalent Group Design
NR = Not Randomly assigned
One of the main problems with the nonequivalent group design is that it lacks random assignment, and without random assignment, there is a greater chance that the treatment and comparison groups may be different in some way that can impact study results. Take, for example, a nonequivalent group design where a researcher is interested in whether an aggression-reduction treatment program can reduce inmate-on-inmate assaults in a prison setting. Assume that the researcher asked for inmates who had previously been involved in assaultive activity to volunteer for the aggression-reduction program. Suppose the researcher placed the first 50 volunteers into the treatment group and the next 50 volunteers into the comparison group. Note that this method of assignment is not random but rather first come, first serve.
Because the study utilized volunteers and there was no random assignment, it is possible that the first 50 volunteers placed into the treatment group differed significantly from the last 50 volunteers who were placed in the comparison group. This can lead to alternative explanations for the results. For example, if the treatment group was much younger than the comparison group, the researcher may find at the end of the program that the treatment group still maintained a higher rate of infractions than the comparison group—even after the aggression-reduction program! The conclusion might be that the aggression program actually increased the level of violence among the treatment group. This conclusion would likely be spurious and may be due to the age differential between the treatment and comparison groups. Indeed, research has revealed that younger inmates are significantly more likely to engage in prison assaults than older inmates. The fact that the treatment group incurred more assaults than the comparison group after the aggression-reduction program may only relate to the age differential between the groups, not that the program had no effect or that it somehow may have increased aggression. The previous example highlights the importance of random assignment and the potential problems that can occur in its absence.
Although researchers who utilize a quasi-experimental design are not able to randomly assign their subjects to groups, they can employ other techniques in an attempt to make the groups as equivalent as possible on known or measured factors before the treatment is given. In the example above, it is likely that the researcher would have known the age of inmates, their prior assault record, and various other pieces of information (e.g., previous prison stays). Through a technique called matching, the researcher could make sure the treatment and comparison groups were “matched” on these important factors before administering the aggression reduction program to the treatment group. This type of matching can be done individual to individual (e.g., subject #1 in treatment group is matched to a selected subject #1 in comparison group on age, previous arrests, gender), or aggregately, such that the comparison group is similar to the treatment group overall (e.g., average ages between groups are similar, equal proportions of males and females). Knowledge of these and other important variables, for example, would allow the researcher to make sure that the treatment group did not have heavy concentrations of younger or more frequent or serious offenders than the comparison group—factors that are related to assaultive activity independent of the treatment program. In short, matching allows the researcher some control over who goes into the treatment and comparison groups so as to balance these groups on important factors absent random assignment. If unbalanced on one or more factors, these factors could emerge as alternative explanations of the results. Figure 5.3 demonstrates the logic of matching both at the individual and aggregate level in a quasi-experimental design.
Matching is an important part of the nonequivalent group design. By matching, the researcher can approximate equivalence between the groups on important variables that may influence the post-test. However, it is important to note that a researcher can only match subjects on factors that they have information about—a researcher cannot match the treatment and comparison group members on factors that are unmeasured or otherwise unknown but which may still impact outcomes. For example, if the researcher has no knowledge about the number of previous incarcerations, the researcher cannot match the treatment and comparison groups on this factor. Matching also requires that the information used for matching is valid and reliable, which is not always the case. Agency records, for example, are notorious for inconsistencies, errors, omissions, and for being dated, but are often utilized for matching purposes. Asking survey questions to generate information for matching (for example, how many times have you been incarcerated?) can also be problematic because some respondents may lie, forget, or exaggerate their behavior or experiences.
In addition to the above considerations, the more factors a researcher wishes to match the group members on, the more difficult it becomes to find appropriate matches. Matching on prior arrests or age is less complex than matching on several additional pieces of information. Finally, matching is never considered superior to random assignment when the goal is to construct equitable groups. This is because there is a much higher likelihood of equivalence with random assignment on factors that are both measured and unknown to the researcher. Thus, the results produced from a nonequivalent group design, even with matching, are at a greater risk of alternative explanations than an experimental design that features random assignment.
FIGURE 5.3 | (a) Individual Matching (b) Aggregate Matching
The previous discussion is not to suggest that the nonequivalent group design cannot be useful in answering important research questions. Rather, it is to suggest that the nonequivalent group design, and hence any quasi-experiment, is more susceptible to alternative explanations than the classic experimental design because of the absence of random assignment. As a result, a researcher must be prepared to rule out potential alternative explanations. Quasi-experimental designs that lack a pre-test or a comparison group are even less desirable than the nonequivalent group design and are subject to additional alternative explanations because of these missing parts. Although the quasi-experiment may be all that is available and still can serve as an important design in evaluating the impact of a particular treatment, it is not preferable to the classic experiment. Researchers (and consumers) must be attuned to the potential issues of this design so as to make informed conclusions about the results produced from such research studies.
The Effects of Red Light Camera (RLC) Enforcement
On March 15, 2009, an article appeared in the Santa Cruz Sentinel entitled “Ticket’s in the Mail: Red-Light Cameras Questioned.” The article stated “while studies show fewer T-bone crashes at lights with cameras and fewer drivers running red lights, the number of rear-end crashes increases.” 24 The study mentioned in the newspaper, which showed fewer drivers running red lights with cameras, was conducted by Richard Retting, Susan Ferguson, and Charles Farmer of the Insurance Institute for Highway Safety (IIHS). 25 They completed a quasi-experimental study in Philadelphia to determine the impact of red light cameras (RLC) on red light violations. In the study, the researchers selected nine intersections—six of which were experimental sites that utilized RLCs and three comparison sites that did not utilize RLCs. The six experimental sites were located in Philadelphia, Pennsylvania, and the three comparison sites were located in Atlantic County, New Jersey. The researchers chose the comparison sites based on the proximity to Philadelphia, the ability to collect data using the same methods as at experimental intersections (e.g., the use of cameras for viewing red light traffic), and the fact that police officials in Atlantic County had offered assistance selecting and monitoring the intersections.
The authors collected three phases of information in the RLC study at the experimental and comparison sites:
Phase 1 Data Collection: Baseline (pre-test) data collection at the experimental and comparison sites consisting of the number of vehicles passing through each intersection, the number of red light violations, and the rate of red light violations per 10,000 vehicles.
Phase 2 Data Collection: Number of vehicles traveling through experimental and comparison intersections, number of red light violations after a 1-second yellow light increase at the experimental sites (treatment 1), number of red light violations at comparison sites without a 1-second yellow light increase, and red light violations per 10,000 vehicles at both experimental and comparison sites.
Phase 3 Data Collection: Red light violations after a 1-second yellow light increase and RLC enforcement at the experimental sites (treatment 2), red light violations at comparison sites without a 1-second yellow increase or RLC enforcement, number of vehicles passing through the experimental and comparison intersections, and the rate of red light violations per 10,000 vehicles.
The researchers operationalized “red light violations” as those where the vehicle entered the intersection one-half of a second or more after the onset of the red signal where the vehicle’s rear tires had to be positioned behind the crosswalk or stop line prior to entering on red. Vehicles already in the intersection at the onset of the red light, or those making a right turn on red with or without stopping were not considered red light violations.
The researchers collected video data at each of the experimental and comparison sites during Phases 1–3. This allowed the researchers to examine red light violations before, during, and after the implementation of red light enforcement and yellow light time increases. Based on an analysis of data, the researchers revealed that the implementation of a 1-second yellow light increase led to reductions in the rate of red light violations from Phase 1 to Phase 2 in all of the experimental sites. In 2 out of 3 comparison sites, the rate of red light violations also decreased, despite no yellow light increase. From Phase 2 to Phase 3 (the enforcement of red light camera violations in addition to a 1-second yellow light increase at experimental sites), the authors noted decreases in the rate of red light violations in all experimental sites, and decreases among 2 of 3 comparison sites without red light enforcement in effect.
Concluding their study, the researchers noted that the study “found large and highly significant incremental reductions in red light running associated with increased yellow signal timing followed by the introduction of red light cameras.” Despite these findings, the researchers noted a number of potential factors to consider in light of the findings: the follow-up time periods utilized when counting red light violations before and after the treatment conditions were instituted; publicity about red light camera enforcement; and the size of fines associated with red light camera enforcement (the fine in Philadelphia was $100, higher than in many other cities), among others.
After reading about the study used in the newspaper article, has your impression of the newspaper headline and quote changed?
For more information and research on the effect of RLCs, visit the Insurance Institute for Highway Safety at http://www .iihs.org/research/topics/rlr.html .
One-Group Longitudinal Design
Like all experimental designs, the quasi-experimental design can come in a variety of forms. The second quasi-experimental design (above) is the one-group longitudinal design (also called a simple interrupted time series design). 26 An examination of this design shows that it lacks both random assignment and a comparison group (see Table 5.5). A major difference between this design and others we have covered is that it includes multiple pre-test and post-test observations.
TABLE 5.5 | One-Group Longitudinal Design
The one-group longitudinal design is useful when researchers are interested in exploring longer-term patterns. Indeed, the term longitudinal generally means “over time”—repeated measurements of the pre-test and post-test over time. This is different from cross-sectional designs, which examine the pre-test and post-test at only one point in time (e.g., at a single point before the application of the treatment and at a single point after the treatment). For example, in the nonequivalent group design and the classic experimental design previously examined, both are cross-sectional because pre-tests and post-tests are measured at one point in time (e.g., at a point 6 months after the treatment). Yet, these designs could easily be considered longitudinal if researchers took repeated measures of the pre-test and post-test.
The organization of the one-group longitudinal design is to examine a baseline of several pre-test observations, introduce a treatment or intervention, and then examine the post-test at several different time intervals. As organized, this design is useful for gauging the impact that a particular program, policy, or law has, if any, and how long the treatment impact lasts. Consider an example whereby a researcher is interested in gauging the impact of a tobacco ban on inmate-on-inmate assaults in a prison setting. This is an important question, for recent years have witnessed correctional systems banning all tobacco products from prison facilities. Correctional administrators predicted that there would be a major increase of inmate-on-inmate violence once the bans took effect. The one-group longitudinal design would be one appropriate design to examine the impact of banning tobacco on inmate assaults.
To construct this study using the one-group longitudinal design, the researcher would first examine the rate of inmate-on-inmate assaults in the prison system (or at an individual prison, a particular cellblock, or whatever the unit of analysis) prior to the removal of tobacco. This is the pre-test, or a baseline of assault activity before the ban goes into effect. In the design presented above, perhaps the researcher would measure the level of assaults in the preceding four months prior to the tobacco ban. When establishing a pre-test baseline, the general rule is that, in a longitudinal design, the more time utilized, both in overall time and number of intervals, the better. For example, the rate of assaults in the preceding month is not as useful as an entire year of data on inmate assaults prior to the tobacco ban. Next, once the tobacco ban is implemented, the researcher would then measure the rate of inmate assaults in the coming months to determine what impact the ban had on inmate-on-inmate assaults. This is shown in Table 5.5 as the multiple post-test measures of assaults. Assaults may increase, decrease, or remain constant from the pre-test baseline over the term of the post-test.
If assaults increased at the same time as the ban went into effect, the researcher might conclude that the increase was due only to the tobacco ban. But, could there be alternative explanations? The answer to this question is yes, there may be other plausible explanations for the increase even with several months of pre-test data. Unfortunately, without a comparison group there is no way for the researcher to be certain if the increase in assaults was due to the tobacco ban, or some other factor that may have spurred the increase in assaults and happened at the same time as the tobacco ban. What if assaults decreased after the tobacco ban went into effect? In this scenario, because there is no comparison group, the researcher would still not know if the results would have happened anyway without the tobacco ban. In these instances, the lack of a comparison group prevents the researcher from confidently attributing the results to the tobacco ban, and interpretation is subject to numerous alternative explanations.
Two-Group Longitudinal Design
A remedy for the previous situation would be to introduce a comparison group (see Table 5.6). Prior to the full tobacco ban, suppose prison administrators conducted a pilot program at one prison to provide insight as to what would happen once the tobacco ban went into effect systemwide. To conduct this pilot, the researcher identified one prison. At this prison, the researcher identified two different cellblocks, C-Block and D-Block. C-Block constitutes the treatment group, or the cellblock of inmates who will have their tobacco taken away. D-Block is the comparison group—inmates in this cellblock will retain their tobacco privileges during the course of the study and during a determined follow-up period to measure post-test assaults (e.g., 12-months). This is a two-group longitudinal design (also sometimes called a multiple interrupted time series design), and adding a comparison group makes this design superior to the one-group longitudinal design.
TABLE 5.6 | Two-Group Longitudinal Design
The usefulness of adding a comparison group to the study means that the researcher can have more confidence that the results at the post-test are due to the tobacco ban and not some alternative explanation. This is because any difference in assaults at the post-test between the treatment and comparison group should be attributed to the only difference between them, the tobacco ban. For this interpretation to hold, however, the researcher must be sure that C-Block and D-Block are similar or equivalent on all factors that might influence the post-test. There are many potential factors that should be considered. For example, the researcher will want to make sure that the same types of inmates are housed in both cellblocks. If a chronic group of assaultive inmates constitutes members of C-Block, but not D-Block, this differential could explain the results, not the treatment.
The researcher might also want to make sure equitable numbers of tobacco and non-tobacco users are found in each cellblock. If very few inmates in C-Block are smokers, the real effect of removing tobacco may be hidden. The researcher might also examine other areas where potential differences might arise, for example, that both cellblocks are staffed with equal numbers of officers, that officers in each cellblock tend to resolve inmate disputes similarly, and other potential issues that could influence post-test measure of assaults. Equivalence could also be ensured by comparing the groups on additional evidence before the ban takes effect: number of prior prison sentences, time served in prison, age, seriousness of conviction crime, and other factors that might relate to assaultive behavior, regardless of the tobacco ban. Moreover, the researcher should ensure that inmates in C-Block do not know that their D-Block counterparts are still allowed tobacco during the pilot study, and vice versa. If either group knows about the pilot program being an experiment, they might act differently than normal, and this could become an explanation of results. Additionally, the researchers might also try to make sure that C-Block inmates are completely tobacco free after the ban goes into effect—that they do not hoard, smuggle, or receive tobacco from officers or other inmates during the tobacco ban in or outside of the cellblock. If these and other important differences are accounted for at the individual and cellblock level, the researcher will have more confidence that any differences in assaults at the post-test between the treatment and comparison groups are related to the tobacco ban, and not some other difference between the two groups or the two cellblocks.
The addition of a comparison group aids in the ability of the researcher to isolate the true impact of a tobacco ban on inmate-on-inmate assaults. All factors that influence the treatment group should also influence the comparison group because the groups are made up of equivalent individuals in equivalent circumstances, with the exception of the tobacco ban. If this is the only difference, the results can be attributed to the ban. Although the addition of the comparison group in the two-group longitudinal design provides more confidence that the findings are attributed to the tobacco ban, the fact that this design lacks randomization means that alternative explanations cannot be completely ruled out—but they can be minimized. This example also suggests that the quasi-experiment in this instance may actually be preferable to an experimental design—noting the realities of prison administration. For example, prison inmates are not typically randomly assigned to different cellblocks by prison officers. Moreover, it is highly unlikely that a prison would have two open cellblocks waiting for a researcher to randomly assign incoming inmates to the prison for a tobacco ban study. Therefore, it is likely there would be differences among the groups in the quasi-experiment.
Fortunately, if differences between the groups are present, the researcher can attempt to determine their potential impact before interpretation of results. The researcher can also use statistical models after the ban takes effect to determine the impact of any differences between the groups on the post-test. While the two-group longitudinal quasi-experiment just discussed could also take the form of an experimental design, if random assignment could somehow be accomplished, the previous discussion provides one situation where an experimental design might be appropriate and desired for a particular research question, but would not be realistic considering the many barriers.
The Threat of Alternative Explanations
Alternative explanations are those factors that could explain the post-test results, other than the treatment. Throughout this chapter, we have noted the potential for alternative explanations and have given several examples of explanations other than the treatment. It is important to know that potential alternative explanations can arise in any research design discussed in this chapter. However, alternative explanations often arise because some design part is missing, for example, random assignment, a pre-test, or a control or comparison group. This is especially true in criminal justice where researchers often conduct field studies and have less control over their study conditions than do researchers who conduct experiments under highly controlled laboratory conditions. A prime example of this is the tobacco ban study, where it would be difficult for researchers to ensure that C-Block inmates, the treatment group, were completely tobacco free during the course of the study.
Alternative explanations are typically referred to as threats to internal validity. In this context, if an experiment is internally valid, it means that alternative explanations have been ruled out and the treatment is the only factor that produced the results. If a study is not internally valid, this means that alternative explanations for the results exist or potentially exist. In this section, we focus on some common alternative explanations that may arise in experimental and quasi-experimental designs. 27
Selection Bias
One of the more common alternative explanations that may occur is selection bias. Selection bias generally indicates that the treatment group (or experimental group) is somehow different from the comparison group (or control group) on a factor that could influence the post-test results. Selection bias is more often a threat in quasi-experimental designs than experimental designs due to the lack of random assignment. Suppose in our study of the prison tobacco ban, members of C-Block were substantially younger than members of D-Block, the comparison group. Such an imbalance between the groups would mean the researcher would not know if the differences in assaults are real (meaning the result of the tobacco ban) or a result of the age differential. Recall that research shows that younger inmates are more assaultive than older inmates and so we would expect more assaults among the younger offenders independent of the tobacco ban.
In a quasi-experiment, selection bias is perhaps the most prevalent type of alternative explanation and can seriously compromise results. Indeed, many of the examples above have referred to potential situations where the groups are imbalanced or not equivalent on some important factor. Although selection bias is a common threat in quasi-experimental designs because of lack of random assignment, and can be a threat in experimental designs because the groups could differ by chance alone or the practice of randomization was not maintained throughout the study (see Classics in CJ Research-MDVE above), a researcher may be able to detect such differentials. For example, the researcher could detect such differences by comparing the groups on the pre-test or other types of information before the start of the study. If differences were found, the researcher could take measures to correct them. The researcher could also use a statistical model that could account or control for differences between the groups and isolate the impact of the treatment, if any. This discussion is beyond the scope of this text but would be a potential way to deal with selection bias and estimate the impact of this bias on study results. The researcher could also, if possible, attempt to re-match the groups in a quasi-experiment or randomly assign the groups a second time in an experimental design to ensure equivalence. At the least, the researcher could recognize the group differences and discuss their potential impact on the results. Without a pre-test or other pre-study information on study participants, however, such differences might not be able to be detected and, therefore, it would be more difficult to determine how the differences, as a result of selection bias, influenced the results.
Another potential alternative explanation is history. History refers to any event experienced differently by the treatment and comparison groups in the time between the pre-test and the post-test that could impact results. Suppose during the course of the tobacco ban study several riots occurred on D-Block, the comparison group. Because of the riots, prison officers “locked down” this cellblock numerous times. Because D-Block inmates were locked down at various times, this could have affected their ability to otherwise engage in inmate assaults. At the end of the study, the assaults in D-Block might have decreased from their pre-test levels because of the lockdowns, whereas in C-Block assaults may have occurred at their normal pace because there was not a lockdown, or perhaps even increased from the pretest because tobacco was also taken away. Even if the tobacco ban had no effect and assaults remained constant in C-Block from pre- to post-test, the lockdown in D-Block might make it appear that the tobacco ban led to increased assaults in C-Block. Thus, the researcher would not know if the post-test results for the C-Block treatment group were attributable to the tobacco ban or the simple fact that D-Block inmates were locked down and their assault activity was artificially reduced. In this instance, the comparison group becomes much less useful because the lockdown created a historical factor that imbalanced the groups during the treatment phase and nullified the comparison.
Another potential alternative explanation is maturation. Maturation refers to the natural biological, psychological, or emotional processes we all experience as time passes—aging, becoming more or less intelligent, becoming bored, and so on. For example, if a researcher was interested in the effect of a boot camp on recidivism for juvenile offenders, it is possible that over the course of the boot camp program the delinquents naturally matured as they aged and this produced the reduction in recidivism—not that the boot camp somehow led to this reduction. This threat is particularly applicable in situations that deal with populations that rapidly change over a relatively short period of time or when a treatment lasts a considerable period of time. However, this threat could be eliminated with a comparison group that is similar to the treatment group. This is because the maturation effects would occur in both groups and the effect of the boot camp, if any, could be isolated. This assumes, however, that the groups are matched and equitable on factors subject to the maturation process, such as age. If not, such differentials could be an alternative explanation of results. For example, if the treatment and comparison groups differ by age, on average, this could mean that one group changes or matures at a different rate than the other group. This differential rate of change or maturation as a result of the age differential could explain the results, not the treatment. This example demonstrates how selection bias and maturation can interact at the same time as alternative explanations. This example also suggests the importance of an equivalent control or comparison group to eliminate or minimize the impact of maturation as an alternative explanation.
Attrition or Subject Mortality
Attrition or subject mortality is another typical alternative explanation. Attrition refers to differential loss in the number or type of subjects between the treatment and comparison groups and can occur in both experimental and quasi-experimental designs. Suppose we wanted to conduct a study to determine who is the better research methods professor among the authors of this textbook. Let’s assume that we have an experimental design where students were randomly assigned to professor 1, professor 2, or professor 3. By randomly assigning students to each respective professor, there is greater probability that the groups are equivalent and thus there are no differences between the three groups with one exception—the professor they receive and his or her particular teaching and delivery style. This is the treatment. Let’s also assume that the professors will be administering the same tests and using the same textbook. After the group members are randomly assigned, a pre-treatment evaluation shows the groups are in fact equivalent on all important known factors that could influence post-test scores, such as grade point average, age, time in school, and exposure to research methods concepts. Additionally, all groups scored comparably on a pre-test of knowledge about research methods, thus there is more confidence that the groups are in fact equivalent.
At the conclusion of the study, we find that professor 2’s group has the lowest final test scores of the three. However, because professor 2 is such an outstanding professor, the results appear odd. At first glance, the researcher thinks the results could have been influenced by students dropping out of the class. For example, perhaps several of professor 2’s students dropped the course but none did from the classes of professor 1 or 3. It is revealed, however, that an equal number of students dropped out of all three courses before the post-test and, therefore, this could not be the reason for the low scores in professor 2’s course. Upon further investigation, however, the researcher finds that although an equal number of students dropped out of each class, the dropouts in professor 2’s class were some of his best students. In contrast, those who dropped out of professor 1’s and professor 3’s courses were some of their poorest students. In this example, professor 2 appears to be the least effective teacher. However, this result appears to be due to the fact that his best students dropped out, and this highly influenced the final test average for his group. Although there was not a differential loss of subjects in terms of numbers (which can also be an attrition issue), there was differential loss in the types of students. This differential loss, not the teaching style, is an alternative explanation of the results.
Testing or Testing Bias
Another potential alternative explanation is testing or testing bias. Suppose that after the pre-test of research methods knowledge, professor 1 and professor 3 reviewed the test with their students and gave them the correct answers. Professor 2 did not. The fact that professor l’s and professor 3’s groups did better on the post-test final exam may be explained by the finding that students in those groups remembered the answers to the pre-test, were thus biased at the pre-test, and this artificially inflated their post-test scores. Testing bias can explain the results because students in groups 1 and 3 may have simply remembered the answers from the pre-test review. In fact, the students in professor l’s and 3’s courses may have scored high on the post-test without ever having been exposed to the treatment because they were biased at the pre-test.
Instrumentation
Another alternative explanation that can arise is instrumentation. Instrumentation refers to changes in the measuring instrument from pre- to post-test. Using the previous example, suppose professors 1 and 3 did not give the same final exam as professor 2. For example, professors 1 and 3 changed the final exam and professor 2 kept the final exam the same as the pretest. Because professors 1 and 3 changed the exam, and perhaps made it easier or somehow different from the pre-test exam, results that showed lower scores for professor 2’s students may be related only to instrumentation changes from pre- to post-test. Obviously, to limit the influence of instrumentation, researchers should make sure that instruments remain consistent from pre- to post-test.
A final alternative explanation is reactivity. Reactivity occurs when members of the treatment or experimental group change their behavior simply as a result of being part of a study. This is akin to the finding that people tend to change their behavior when they are being watched or are aware they are being studied. If members of the experiment know they are part of an experiment and are being studied and watched, it is possible that their behavior will change independent of the treatment. If this occurs, the researcher will not know if the behavior change is the result of the treatment, or simply a result of being part of a study. For example, suppose a researcher wants to determine if a boot camp program impacts the recidivism of delinquent offenders. Members of the experimental group are sentenced to boot camp and members of the control group are released on their own recognizance to their parents. Because members of the experimental group know they are part of the experiment, and hence being watched closely after they exit boot camp, they may artificially change their behavior and avoid trouble. Their change of behavior may be totally unrelated to boot camp, but rather, to their knowledge of being part of an experiment.
Other Potential Alternative Explanations
The above discussion provided some typical alternative explanations that may arise with the designs discussed in this chapter. There are, however, other potential alternative explanations that may arise. These alternative explanations arise only when a control or comparison group is present.
One such alternative explanation is diffusion of treatment. Diffusion of treatment occurs when the control or comparison group learns about the treatment its members are being denied and attempts to mimic the behavior of the treatment group. If the control group is successful in mimicking the experimental group, for example, the results at the end of the study may show similarity in outcomes between groups and cause the researcher to conclude that the program had no effect. In fact, however, the finding of no effect can be explained by the comparison group mimicking the treatment group. 28 In reality, there may be no effect of the treatment, but the researcher would not know this for sure because the control group effectively transformed into another experimental group—there is then no baseline of comparison. Consider a study where a researcher wants to determine the impact of a training program on class behavior and participation. In this study, the experimental group is exposed to several sessions of training on how to act appropriately in class and how to engage in class participation. The control group does not receive such training, but they are aware that they are part of an experiment. Suppose after a few class sessions the control group starts to mimic the behavior of the experimental group, acting the same way and participating in class the same way. At the conclusion of the study, the researcher might determine that the program had no impact because the comparison group, which did not receive the new program, showed similar progress.
In a related explanation, sometimes the comparison or control group learns about the experiment and attempts to compete with the experimental or treatment group. This alternative explanation is called compensatory rivalry. For example, suppose a police chief wants to determine if a new training program will increase the endurance of SWAT team officers. The chief randomly assigns SWAT members to either an experimental or control group. The experimental group will receive the new endurance training program and the control group will receive the normal program that has been used for years. During the course of the study, suppose the control group learns that the treatment group is receiving the new endurance program and starts to compete with the experimental group. Perhaps the control group runs five more miles per day and works out an extra hour in the weight room, in addition to their normal endurance program. At the end of the study, and due to the control group’s extra and competing effort, the results might show no effect of the new endurance program, and at worst, experimental group members may show a decline in endurance compared to the control group. The rivalry or competing behavior actually explains the results, not that the new endurance program has no effect or a damaging effect. Although the new endurance program may in reality have no effect, this cannot be known because of the actions of the control group, who learned about the treatment and competed with the experimental group.
Closely related to compensatory rivalry is the alternative explanation of comparison or control group demoralization. 29 In this instance, instead of competing with the experimental or treatment group, the control or comparison group simply gives up and changes their normal behavior. Using the SWAT example, perhaps the control group simply quits their normal endurance program when they learn about the treatment group receiving the new endurance program. At the post-test, their endurance will likely drop considerably compared to the treatment group. Because of this, the new endurance program might emerge as a shining success. In reality, however, the researcher will not know if any changes in endurance between the experimental and control groups are a result of the new endurance program or the control group giving up. Due to their giving up, there is no longer a comparison group of equitable others, the change in endurance among the treatment group members could be attributed to a number of alternative explanations, for example, maturation. If the comparison group behaves normally, the researcher will be able to exclude maturation as a potential explanation. This is because any maturation effects will occur in both groups.
The previous discussion suggests that when the control or comparison group learns about the experiment and the treatment they are denied, potential alternative explanations can arise. Perhaps the best remedy to protect from the alternative explanations just discussed is to make sure the treatment and comparison groups do not have contact with one another. In laboratory experiments this can be ensured, but sometimes this is a problem in criminal justice studies, which are often conducted in the field.
The previous discussion also suggests that there are numerous alternative explanations that can impact the interpretation of results from a study. A careful researcher would know that alternative explanations must be ruled out before reaching a definitive conclusion about the impact of a particular program. The researcher must be attuned to these potential alternative explanations because they can influence results and how results are interpreted. Moreover, the discussion shows that several alternative explanations can occur at the same time. For example, it is possible that selection bias, maturation, attrition, and compensatory rivalry all emerge as alternative explanations in the same study. Knowing about these potential alternative explanations and how they can impact the results of a study is what distinguishes a consumer of research from an educated consumer of research.
Chapter Summary
The primary focus of this chapter was the classic experimental design, the foundation for other types of experimental and quasi-experimental designs. The classic experimental design is perhaps the most useful design when exploring causal relationships. Often, however, researchers cannot employ the classic experimental design to answer a research question. In fact, the classic experimental design is rare in criminal justice and criminology because it is often difficult to ensure random assignment for a variety of reasons. In circumstances where an experimental design is appropriate but not feasible, researchers may turn to one of many quasi-experimental designs. The most important difference between the two is that quasi-experimental designs do not feature random assignment. This can create potential problems for researchers. The main problem is that there is a greater chance the treatment and comparison groups may differ on important characteristics that could influence the results of a study. Although researchers can attempt to prevent imbalances between the groups by matching them on important known characteristics, it is still much more difficult to establish equivalence than it is in the classic experiment. As such, it becomes more difficult to determine what impact a treatment had, if any, as one moves from an experimental to a quasi-experimental design.
Perhaps the most important lesson to be learned in this chapter is that to be an educated consumer of research results requires an understanding of the type of design that produced the results. There are numerous ways experimental and quasi-experimental designs can be structured. This is why much attention was paid to the classic experimental design. In reality, all experimental and quasi-experimental designs are variations of the classic experiment in some way—adding or deleting certain components. If the components and organization and logic of the classic experimental design are understood, consumers of research will have a better understanding of the results produced from any sort of research design. For example, what problems in interpretation arise when a design lacks a pre-test, a control group, or random assignment? Having an answer to this question is a good start toward being an informed consumer of research results produced through experimental and quasi-experimental designs.
Critical Thinking Questions
1. Why is randomization/random assignment preferable to matching? Provide several reasons with explanation.
2. What are some potential reasons a researcher would not be able to utilize random assignment?
3. What is a major limitation of matching?
4. What is the difference between a longitudinal study and a cross-sectional study?
5. Describe a hypothetical study where maturation, and not the treatment, could explain the outcomes of the research.
association (or covariance or correlation): One of three conditions that must be met for establishing cause and effect, or a causal relationship. Association refers to the condition that X and Y must be related for a causal relationship to exist. Association is also referred to as covariance or correlation. Although two variables may be associated (or covary or be correlated), this does not automatically imply that they are causally related
attrition or subject mortality: A threat to internal validity, it refers to the differential loss of subjects between the experimental (treatment) and control (comparison) groups during the course of a study
cause and effect relationship: A cause and effect relationship occurs when one variable causes another, and no other explanation for that relationship exists
classic experimental design or experimental design: A design in a research study that features random assignment to an experimental or control group. Experimental designs can vary tremendously, but a constant feature is random assignment, experimental and control groups, and a post-test. For example, a classic experimental design features random assignment, a treatment, experimental and control groups, and pre- and post-tests
comparison group: The group in a quasi-experimental design that does not receive the treatment. In an experimental design, the comparison group is referred to as the control group
compensatory rivalry: A threat to internal validity, it occurs when the control or comparison group attempts to compete with the experimental or treatment group
control group: In an experimental design, the control group does not receive the treatment. The control group serves as a baseline of comparison to the experimental group. It serves as an example of what happens when a group equivalent to the experimental group does not receive the treatment
cross-sectional designs: A measurement of the pre-test and post-test at one point in time (e.g., six months before and six months after the program)
demoralization: A threat to internal validity closely associated with compensatory rivalry, it occurs when the control or comparison group gives up and changes their normal behavior. While in compensatory rivalry the group members compete, in demoralization, they simply quit. Both are not normal behavioral reactions
dependent variable: Also known as the outcome in a research study. A post-test is a measure of the dependent variable
diffusion of treatment: A threat to internal validity, it occurs when the control or comparison group members learn that they are not getting the treatment and attempt to mimic the behavior of the experimental or treatment group. This mimicking may make it seem as if the treatment is having no effect, when in fact it may be
elimination of alternative explanations: One of three conditions that must be met for establishing cause and effect. Elimination of alternative explanations means that the researcher has ruled out other explanations for an observed relationship between X and Y
experimental group: In an experimental design, the experimental group receives the treatment
history: A threat to internal validity, it refers to any event experienced differently by the treatment and comparison groups—an event that could explain the results other than the supposed cause
independent variable: Also called the cause
instrumentation: A threat to internal validity, it refers to changes in the measuring instrument from pre- to post-test
longitudinal: Refers to repeated measurements of the pre-test and post-test over time, typically for the same group of individuals. This is the opposite of cross-sectional
matching: A process sometimes utilized in some quasi-experimental designs that feature treatment and comparison groups. Matching is a process whereby the researcher attempts to ensure equivalence between the treatment and comparison groups on known information, in the absence of the ability to randomly assign the groups
maturation: A threat to internal validity, maturation refers to the natural biological, psychological, or emotional processes as time passes
negative association: Refers to a negative association between two variables. A negative association is demonstrated when X increases and Y decreases, or X decreases and Y increases. Also known as an inverse relationship—the variables moving in opposite directions
operationalized or operationalization: Refers to the process of assigning a working definition to a concept. For example, the concept of intelligence can be operationalized or defined as grade point average or score on a standardized exam, among others
pilot program or test: Refers to a smaller test study or pilot to work out problems before a larger study and to anticipate changes needed for a larger study. Similar to a test run
positive association: Refers to a positive association between two variables. A positive association means as X increases, Y increases, or as X decreases, Y decreases
post-test: The post-test is a measure of the dependent variable after the treatment has been administered
pre-test: The pre-test is a measure of the dependent variable or outcome before a treatment is administered
quasi-experiment: A quasi-experiment refers to any number of research design configurations that resemble an experimental design but primarily lack random assignment. In the absence of random assignment, quasi-experimental designs feature matching to attempt equivalence
random assignment: Refers to a process whereby members of the experimental group and control group are assigned to each group through a random and unbiased process
random selection: Refers to selecting a smaller but representative subset from a population. Not to be confused with random assignment
reactivity: A threat to internal validity, it occurs when members of the experimental (treatment) or control (comparison) group change their behavior unnaturally as a result of being part of a study
selection bias: A threat to internal validity, selection bias occurs when the experimental (treatment) group and control (comparison) group are not equivalent. The difference between the groups can be a threat to internal validity, or, an alternative explanation to the findings
spurious: A spurious relationship is one where X and Y appear to be causally related, but in fact the relationship is actually explained by a variable or factor other than X
testing or testing bias: A threat to internal validity, it refers to the potential of study members being biased prior to a treatment, and this bias, rather than the treatment, may explain study results
threat to internal validity: Also known as alternative explanation to a relationship between X and Y. Threats to internal validity are factors that explain Y, or the dependent variable, and are not X, or the independent variable
timing: One of three conditions that must be met for establishing cause and effect. Timing refers to the condition that X must come before Y in time for X to be a cause of Y. While timing is necessary for a causal relationship, it is not sufficient, and considerations of association and eliminating other alternative explanations must be met
treatment: A component of a research design, it is typically denoted by the letter X. In a research study on the impact of teen court on juvenile recidivism, teen court is the treatment. In a classic experimental design, the treatment is given only to the experimental group, not the control group
treatment group: The group in a quasi-experimental design that receives the treatment. In an experimental design, this group is called the experimental group
unit of analysis: Refers to the focus of a research study as being individuals, groups, or other units of analysis, such as prisons or police agencies, and so on
variable(s): A variable is a concept that has been given a working definition and can take on different values. For example, intelligence can be defined as a person’s grade point average and can range from low to high or can be defined numerically by different values such as 3.5 or 4.0
1 Povitsky, W., N. Connell, D. Wilson, & D. Gottfredson. (2008). “An experimental evaluation of teen courts.” Journal of Experimental Criminology, 4, 137–163.
2 Hirschi, T., and H. Selvin (1966). “False criteria of causality in delinquency.” Social Problems, 13, 254–268.
3 Robert Roy Britt, “Churchgoers Live Longer.” April, 3, 2006. http://www.livescience.com/health/060403_church_ good.html. Retrieved on September 30, 2008.
4 Kalist, D., and D. Yee (2009). “First names and crime: Does unpopularity spell trouble?” Social Science Quarterly, 90 (1), 39–48.
5 Sherman, L. (1992). Policing domestic violence. New York: The Free Press.
6 For historical and interesting reading on the effects of weather on crime and other disorder, see Dexter, E. (1899). “Influence of weather upon crime.” Popular Science Monthly, 55, 653–660 in Horton, D. (2000). Pioneering Perspectives in Criminology. Incline Village, NV: Copperhouse.
7 http://www.escapistmagazine.com/news/view/111191-Less-Crime-in-U-S-Thanks-to-Videogames , retrieved on September 13, 2011. This news article was in response to a study titled “Understanding the effects of violent videogames on violent crime.” See Cunningham, Scott, Engelstätter, Benjamin, and Ward, (April 7, 2011). Available at SSRN: http://ssm.com/abstract= 1804959.
8 Cohn, E. G. (1987). “Changing the domestic violence policies of urban police departments: Impact of the Minneapolis experiment.” Response, 10 (4), 22–24.
9 Schmidt, Janell D., & Lawrence W. Sherman (1993). “Does arrest deter domestic violence?” American Behavioral Scientist, 36 (5), 601–610.
10 Maxwell, Christopher D., Joel H. Gamer, & Jeffrey A. Fagan. (2001). The effects of arrest on intimate partner violence: New evidence for the spouse assault replication program. Washington D.C.: National Institute of Justice.
11 Miller, N. (2005). What does research and evaluation say about domestic violence laws? A compendium of justice system laws and related research assessments. Alexandria, VA: Institute for Law and Justice.
12 The sections on experimental and quasi-experimental designs rely heavily on the seminal work of Campbell and Stanley (Campbell, D.T., & J. C. Stanley. (1963). Experimental and quasi-experimental designs for research. Chicago: RandMcNally) and more recently, Shadish, W., T. Cook, & D. Campbell. (2002). Experimental and quasi-experimental designs for generalized causal inference. New York: Houghton Mifflin.
13 Povitsky et al. (2008). p. 146, note 9.
14 Shadish, W., T. Cook, & D. Campbell. (2002). Experimental and quasi-experimental designs for generalized causal inference. New York: Houghton Mifflin Company.
15 Ibid, 15.
16 Finckenauer, James O. (1982). Scared straight! and the panacea phenomenon. Englewood Cliffs, N.J.: Prentice Hall.
17 Yarborough, J.C. (1979). Evaluation of JOLT (Juvenile Offenders Learn Truth) as a deterrence program. Lansing, MI: Michigan Department of Corrections.
18 Petrosino, Anthony, Carolyn Turpin-Petrosino, & James O. Finckenauer. (2000). “Well-meaning programs can have harmful effects! Lessons from experiments of programs such as Scared Straight.” Crime and Delinquency, 46, 354–379.
19 “Swearing makes pain more tolerable” retrieved at http:// www.livescience.com/health/090712-swearing-pain.html (July 13, 2009). Also see “Bleep! My finger! Why swearing helps ease pain” by Tiffany Sharpies, retrieved at http://www.time.com/time/health/article /0,8599,1910691,00.html?xid=rss-health (July 16, 2009).
20 For an excellent discussion of the value of controlled experiments and why they are so rare in the social sciences, see Sherman, L. (1992). Policing domestic violence. New York: The Free Press, 55–74.
21 For discussion, see Weisburd, D., T. Einat, & M. Kowalski. (2008). “The miracle of the cells: An experimental study of interventions to increase payment of court-ordered financial obligations.” Criminology and Public Policy, 7, 9–36.
22 Shadish, Cook, & Campbell. (2002).
24 Kelly, Cathy. (March 15, 2009). “Tickets in the mail: Red-light cameras questioned.” Santa Cruz Sentinel.
25 Retting, Richard, Susan Ferguson, & Charles Farmer. (January 2007). “Reducing red light running through longer yellow signal timing and red light camera enforcement: Results of a field investigation.” Arlington, VA: Insurance Institute for Highway Safety.
26 Shadish, Cook, & Campbell. (2002).
27 See Shadish, Cook, & Campbell. (2002), pp. 54–61 for an excellent discussion of threats to internal validity. Also see Chapter 2 for an extended discussion of all forms of validity considered in research design.
28 Trochim, W. (2001). The research methods knowledge base, 2nd ed. Cincinnati, OH: Atomic Dog.
Applied Research Methods in Criminal Justice and Criminology by University of North Texas is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License , except where otherwise noted.
Share This Book
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
- Random Assignment in Experiments | Introduction & Examples
Random Assignment in Experiments | Introduction & Examples
Published on 6 May 2022 by Pritha Bhandari . Revised on 13 February 2023.
In experimental research, random assignment is a way of placing participants from your sample into different treatment groups using randomisation.
With simple random assignment, every member of the sample has a known or equal chance of being placed in a control group or an experimental group. Studies that use simple random assignment are also called completely randomised designs .
Random assignment is a key part of experimental design . It helps you ensure that all groups are comparable at the start of a study: any differences between them are due to random factors.
Table of contents
Why does random assignment matter, random sampling vs random assignment, how do you use random assignment, when is random assignment not used, frequently asked questions about random assignment.
Random assignment is an important part of control in experimental research, because it helps strengthen the internal validity of an experiment.
In experiments, researchers manipulate an independent variable to assess its effect on a dependent variable, while controlling for other variables. To do so, they often use different levels of an independent variable for different groups of participants.
This is called a between-groups or independent measures design.
You use three groups of participants that are each given a different level of the independent variable:
- A control group that’s given a placebo (no dosage)
- An experimental group that’s given a low dosage
- A second experimental group that’s given a high dosage
Random assignment to helps you make sure that the treatment groups don’t differ in systematic or biased ways at the start of the experiment.
If you don’t use random assignment, you may not be able to rule out alternative explanations for your results.
- Participants recruited from pubs are placed in the control group
- Participants recruited from local community centres are placed in the low-dosage experimental group
- Participants recruited from gyms are placed in the high-dosage group
With this type of assignment, it’s hard to tell whether the participant characteristics are the same across all groups at the start of the study. Gym users may tend to engage in more healthy behaviours than people who frequent pubs or community centres, and this would introduce a healthy user bias in your study.
Although random assignment helps even out baseline differences between groups, it doesn’t always make them completely equivalent. There may still be extraneous variables that differ between groups, and there will always be some group differences that arise from chance.
Most of the time, the random variation between groups is low, and, therefore, it’s acceptable for further analysis. This is especially true when you have a large sample. In general, you should always use random assignment in experiments when it is ethically possible and makes sense for your study topic.
Prevent plagiarism, run a free check.
Random sampling and random assignment are both important concepts in research, but it’s important to understand the difference between them.
Random sampling (also called probability sampling or random selection) is a way of selecting members of a population to be included in your study. In contrast, random assignment is a way of sorting the sample participants into control and experimental groups.
While random sampling is used in many types of studies, random assignment is only used in between-subjects experimental designs.
Some studies use both random sampling and random assignment, while others use only one or the other.

Random sampling enhances the external validity or generalisability of your results, because it helps to ensure that your sample is unbiased and representative of the whole population. This allows you to make stronger statistical inferences .
You use a simple random sample to collect data. Because you have access to the whole population (all employees), you can assign all 8,000 employees a number and use a random number generator to select 300 employees. These 300 employees are your full sample.
Random assignment enhances the internal validity of the study, because it ensures that there are no systematic differences between the participants in each group. This helps you conclude that the outcomes can be attributed to the independent variable .
- A control group that receives no intervention
- An experimental group that has a remote team-building intervention every week for a month
You use random assignment to place participants into the control or experimental group. To do so, you take your list of participants and assign each participant a number. Again, you use a random number generator to place each participant in one of the two groups.
To use simple random assignment, you start by giving every member of the sample a unique number. Then, you can use computer programs or manual methods to randomly assign each participant to a group.
- Random number generator: Use a computer program to generate random numbers from the list for each group.
- Lottery method: Place all numbers individually into a hat or a bucket, and draw numbers at random for each group.
- Flip a coin: When you only have two groups, for each number on the list, flip a coin to decide if they’ll be in the control or the experimental group.
- Use a dice: When you have three groups, for each number on the list, roll a die to decide which of the groups they will be in. For example, assume that rolling 1 or 2 lands them in a control group; 3 or 4 in an experimental group; and 5 or 6 in a second control or experimental group.
This type of random assignment is the most powerful method of placing participants in conditions, because each individual has an equal chance of being placed in any one of your treatment groups.
Random assignment in block designs
In more complicated experimental designs, random assignment is only used after participants are grouped into blocks based on some characteristic (e.g., test score or demographic variable). These groupings mean that you need a larger sample to achieve high statistical power .
For example, a randomised block design involves placing participants into blocks based on a shared characteristic (e.g., college students vs graduates), and then using random assignment within each block to assign participants to every treatment condition. This helps you assess whether the characteristic affects the outcomes of your treatment.
In an experimental matched design , you use blocking and then match up individual participants from each block based on specific characteristics. Within each matched pair or group, you randomly assign each participant to one of the conditions in the experiment and compare their outcomes.
Sometimes, it’s not relevant or ethical to use simple random assignment, so groups are assigned in a different way.
When comparing different groups
Sometimes, differences between participants are the main focus of a study, for example, when comparing children and adults or people with and without health conditions. Participants are not randomly assigned to different groups, but instead assigned based on their characteristics.
In this type of study, the characteristic of interest (e.g., gender) is an independent variable, and the groups differ based on the different levels (e.g., men, women). All participants are tested the same way, and then their group-level outcomes are compared.
When it’s not ethically permissible
When studying unhealthy or dangerous behaviours, it’s not possible to use random assignment. For example, if you’re studying heavy drinkers and social drinkers, it’s unethical to randomly assign participants to one of the two groups and ask them to drink large amounts of alcohol for your experiment.
When you can’t assign participants to groups, you can also conduct a quasi-experimental study . In a quasi-experiment, you study the outcomes of pre-existing groups who receive treatments that you may not have any control over (e.g., heavy drinkers and social drinkers).
These groups aren’t randomly assigned, but may be considered comparable when some other variables (e.g., age or socioeconomic status) are controlled for.
In experimental research, random assignment is a way of placing participants from your sample into different groups using randomisation. With this method, every member of the sample has a known or equal chance of being placed in a control group or an experimental group.
Random selection, or random sampling , is a way of selecting members of a population for your study’s sample.
In contrast, random assignment is a way of sorting the sample into control and experimental groups.
Random sampling enhances the external validity or generalisability of your results, while random assignment improves the internal validity of your study.
Random assignment is used in experiments with a between-groups or independent measures design. In this research design, there’s usually a control group and one or more experimental groups. Random assignment helps ensure that the groups are comparable.
In general, you should always use random assignment in this type of experimental design when it is ethically possible and makes sense for your study topic.
To implement random assignment , assign a unique number to every member of your study’s sample .
Then, you can use a random number generator or a lottery method to randomly assign each number to a control or experimental group. You can also do so manually, by flipping a coin or rolling a die to randomly assign participants to groups.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Bhandari, P. (2023, February 13). Random Assignment in Experiments | Introduction & Examples. Scribbr. Retrieved 14 May 2024, from https://www.scribbr.co.uk/research-methods/random-assignment-experiments/
Is this article helpful?

Pritha Bhandari
Other students also liked, a quick guide to experimental design | 5 steps & examples, controlled experiments | methods & examples of control, control groups and treatment groups | uses & examples.

Unraveling the Mystery of Random Assignment in Psychology

Random assignment is a crucial concept in psychology research, ensuring the validity and reliability of experiments. But what exactly is random assignment, and why is it so important in the field of psychology?
In this article, we will discuss the difference between random assignment and random sampling, the steps involved in random assignment, and how researchers can effectively implement this technique. We will also explore the benefits and limitations of random assignment, as well as ways to ensure its effectiveness in psychology research.
Join us as we unravel the mystery of random assignment in psychology.
- Random assignment is a research method used in psychology to eliminate bias and increase internal validity by randomly assigning participants to different groups.
- Unlike random sampling, which selects participants for a study, random assignment randomly distributes participants into groups to ensure unbiased results.
- Researchers can ensure effective random assignment by using randomization tables, random number generators, and stratified random assignment to increase the accuracy and generalizability of their findings.
- 1 What is Random Assignment in Psychology?
- 2.1 What is the Difference between Random Assignment and Random Sampling?
- 3.1 What are the Steps Involved in Random Assignment?
- 4.1 Eliminates Bias
- 4.2 Increases Internal Validity
- 4.3 Allows for Generalizability
- 5.1 Practical Limitations
- 5.2 Ethical Concerns
- 6.1 Use a Randomization Table
- 6.2 Use a Random Number Generator
- 6.3 Use Stratified Random Assignment
- 7.1 What is random assignment and why is it important in psychology?
- 7.2 How is random assignment different from random selection?
- 7.3 What are some common methods of random assignment in psychology research?
- 7.4 Are there any limitations to random assignment in psychology research?
- 7.5 What are the advantages of using random assignment in psychology research?
- 7.6 Can random assignment be used in all types of psychology research?
What is Random Assignment in Psychology?
Random assignment in psychology refers to the method of placing participants in experimental groups through a random process to ensure unbiased distribution of characteristics.
This method is crucial in research studies as it allows for the elimination of potential biases that could skew results, leading to more accurate and generalizable findings. By randomly assigning participants, researchers can be more confident that any differences observed between groups are due to the treatment or intervention being studied rather than pre-existing individual characteristics.
For example, in a study investigating the effectiveness of a new therapy for anxiety, random assignment would involve randomly assigning participants with similar levels of anxiety to either the treatment group receiving the new therapy or the control group receiving a placebo. Variables such as age, gender, and severity of anxiety are controlled through random assignment to ensure that any differences in outcomes can be attributed to the therapy.
Why is Random Assignment Important in Psychology Experiments?
Random assignment holds paramount importance in psychology experiments as it enhances internal validity, establishes cause-and-effect relationships, and ensures accurate data analysis.
Random assignment involves the objective allocation of participants into different experimental groups without any bias or preconceived notions. This method is crucial in ensuring that researchers can confidently draw conclusions about the causal relationships being examined, rather than attributing any observed effects to other variables.
By randomly assigning participants, researchers can control for potential confounding variables and eliminate the influence of extraneous factors, thus strengthening the internal validity of the study. This process minimizes the likelihood of alternative explanations for the results, allowing for more accurate interpretations and conclusions.
In fields like clinical trials, the use of random assignment is fundamental in evaluating the effectiveness of new treatments or interventions. Test performance studies also rely on random assignment to evenly distribute factors that may impact scores, such as motivation levels or prior knowledge. In behavioral studies, random assignment ensures that participants are evenly distributed across conditions, reducing the risk of bias and increasing the generalizability of findings.
What is the Difference between Random Assignment and Random Sampling?
Random assignment and random sampling are distinct concepts in research methodology; while random assignment involves the allocation of participants to groups, random sampling pertains to the selection of a representative sample from a population.
In research design, random assignment plays a crucial role in ensuring the control and distribution of variables among different experimental groups, thereby minimizing bias and allowing researchers to establish cause-effect relationships. On the other hand, random sampling is essential for obtaining a sample that accurately represents the larger population being studied, increasing the generalizability of research findings.
For instance, in a study investigating the effects of a new medication, researchers may use random assignment to assign participants randomly to either the treatment group receiving the medication or the control group receiving a placebo. This random allocation helps in isolating the impact of the medication from other variables.
Conversely, when employing random sampling, researchers aim to select participants in a way that every individual in the population has an equal chance of being included in the study. This method ensures that the sample closely reflects the characteristics of the entire population under investigation.
How is Random Assignment Used in Psychology Research?
Random assignment is a fundamental component of psychology research, utilized to allocate participants randomly to groups in controlled experiments to investigate the impact of variables on study outcomes.
In experimental design, researchers use random assignment to ensure that participants have equal chances of being assigned to different conditions, reducing bias and increasing the validity of the study results.
This method allows researchers to confidently infer causality between variables, as any differences observed in outcomes can be attributed to the manipulation of independent variables, rather than pre-existing participant characteristics.
Clinical research often relies on random assignment to assess the efficacy of new treatments or interventions, helping to establish evidence-based practices that improve patient outcomes.
What are the Steps Involved in Random Assignment?
The steps in random assignment entail the creation of groups, selection of participants, and the assignment process itself, ensuring a randomized distribution in the experimental design.
The creation of groups involves categorizing the participants based on relevant criteria such as age, gender, or other demographics to form distinct experimental and control groups. Then, the selection of participants requires a systematic approach to avoid bias, ensuring that each individual has an equal chance of inclusion.
Following this, the assignment process involves using randomization methods like coin flipping, random number generators, or computer algorithms to determine which group each participant will be allocated to. By doing this, the randomization helps reduce the impact of confounding variables, making the results more reliable and valid.
What are the Benefits of Using Random Assignment in Psychology?
Using random assignment in psychology offers multiple benefits such as eliminating bias , increasing internal validity, and establishing causal relationships crucial for accurate data analysis in behavioral studies.
Random assignment is a method that involves every participant having an equal chance of being assigned to any condition or group within a study. By implementing this technique, researchers can ensure that potential confounding variables are evenly distributed across groups, leading to more reliable and valid results . This process is integral in psychology research as it not only strengthens the internal validity of a study but also allows researchers to confidently attribute any observed differences to the treatment being studied.
Eliminates Bias
One of the key benefits of random assignment is its ability to eliminate bias by ensuring that participants are equally distributed between the control and treatment groups, mitigating the impact of confounding variables.
Reducing bias in research is crucial as it enhances the internal validity of the study, making the results more reliable and generalizable.
- Random assignment is particularly vital in experimental studies, where the goal is to determine causality.
For instance, imagine a study on the effectiveness of a new medication for hypertension. If participants with severe hypertension are all placed in the treatment group, and those with mild hypertension in the control group, the results may not accurately reflect the medication’s true impact.
Increases Internal Validity
Random assignment enhances internal validity by ensuring that any observed effects are attributed to the manipulation of the independent variable rather than external factors, strengthening the causal inference between variables.
Control and treatment groups play a crucial role in this process. The control group does not receive the treatment , serving as a baseline comparison to evaluate the impact of the independent variable. On the other hand, the treatment group is exposed to the independent variable. This distinction allows researchers to isolate the effects of the intervention accurately.
The relationship between the independent and dependent variables is key. The independent variable is manipulated by the researcher to observe its effect on the dependent variable. For instance, in a study testing a new drug’s efficacy (independent variable), the patient’s health outcomes (dependent variable) are measured.
Allows for Generalizability
Random assignment enables generalizability by creating samples that represent the broader population, increasing the validity of research findings and supporting the generalization of hypotheses to larger groups.
When researchers use random assignment, it helps to eliminate bias and ensure that participants are equally distributed between different experimental conditions. This method enhances the likelihood that the results are not skewed by pre-existing differences among participants, thus making the findings more reliable and applicable to a wider range of individuals.
By having diverse and representative samples through random assignment, researchers can draw conclusions that are more likely to be valid for the entire population, rather than just a specific subgroup. This approach also enhances the ability to make predictions and recommendations based on the study’s outcomes that can be beneficial for decision-making processes in various fields.
What are the Limitations of Random Assignment in Psychology?
Despite its advantages, random assignment in psychology experiments faces limitations such as practical constraints that may affect the implementation process and ethical considerations related to participant welfare.
One practical challenge encountered with random assignment is the logistical complexity of ensuring a truly random allocation of participants to experimental conditions. Researchers may find it difficult to maintain perfect randomization due to issues like accessibility, time constraints, and resources required. For instance, in a study aiming to investigate the effects of sleep deprivation on cognitive performance, ensuring that participants are randomly assigned to control and experimental groups might be challenging.
Ethical dilemmas arise concerning the well-being of participants. Random assignment can lead to unequal group distributions, potentially exposing some individuals to risks without corresponding benefits. For instance, assigning participants with a history of mental health issues to a placebo group in a study testing the efficacy of a new treatment can raise ethical concerns.
Addressing these challenges requires researchers to adopt measures such as stratified random assignment, where participants are grouped based on specific characteristics to ensure balanced representation across experimental conditions. By predefining strata, researchers can control for variables that may affect outcomes.
Practical Limitations
Practical limitations of random assignment include logistical challenges in participant recruitment, constraints in experimental design, and potential impacts on study outcomes due to practical considerations.
One of the major challenges researchers face is the difficulty of ensuring a truly randomized sample, especially when dealing with complex recruitment processes and limited resources for participant selection. The logistics involved in coordinating experimental procedures for each participant can be overwhelming, leading to delays in data collection and analysis.
These issues can significantly affect the internal validity of a study, as deviations from random assignment may introduce bias and confound the results. To mitigate these challenges, researchers can adopt strategies such as stratified randomization or matching to improve participant allocation and minimize the impact of logistical constraints on the study outcomes.
Ethical Concerns
Ethical concerns in random assignment revolve around participant welfare, equitable treatment in the control and treatment groups, and the ethical implications of manipulating variables that may impact individuals’ well-being.
When conducting a psychology experiment, researchers must ensure that the random assignment of participants to different groups is carried out in a fair and unbiased manner. This is crucial in maintaining the integrity of the study and upholding ethical principles.
Participant welfare is paramount, and researchers have a responsibility to safeguard the well-being of individuals involved in the research.
How Can Researchers Ensure Effective Random Assignment?
Researchers can ensure effective random assignment by utilizing tools such as randomization tables , random number generators , and stratified random assignment methods to enhance the randomness and validity of group allocations.
Randomization tables help match participants to different treatment groups based on a predefined criteria or algorithm, ensuring an unbiased assignment process. Random number generators play a crucial role in allocating participants to groups without any conscious or subconscious bias, fostering transparent and fair treatment allocations.
Implementing stratified assignments involves dividing participants into subgroups based on specific characteristics, such as age, gender, or severity of the condition, to create more homogeneous groups for more accurate results.
Best practices for maintaining the integrity of the random assignment process include double-blinding the study, ensuring proper concealment of allocation mechanisms, and conducting randomization procedures by an independent party to minimize potential biases.
Use a Randomization Table
A randomization table is a valuable tool in research that aids in the allocation of participants to different groups using a predetermined random sequence, ensuring an unbiased distribution in the random assignment process.
By utilizing a randomization table, researchers can avoid selection bias and ensure that each participant has an equal chance of being assigned to any group. This method promotes fairness and helps in achieving comparability among the groups in a study. For example, in a clinical trial testing a new medication, a randomization table can be employed to assign participants either to the treatment group receiving the medication or the control group receiving a placebo.
The benefits of using randomization tables include increased internal validity, reduced confounding variables, and the ability to demonstrate causal relationships with greater confidence. This tool enhances the reliability and replicability of research findings by minimizing systematic errors in group allocations.
Use a Random Number Generator
In research, a random number generator is employed to allocate participants randomly to groups, ensuring an unbiased distribution and enhancing the validity and reliability of study outcomes.
Random number generators play a crucial role in the scientific method by enabling researchers to achieve randomness essential for reliable experiments. They aid in minimizing selection bias, thereby contributing to the integrity of the study design. Random number generators uphold the principle of chance, fostering a fair and equal opportunity for each participant to be assigned to a specific condition. This methodological approach ensures that the treatment and control groups are comparable, leading to more accurate conclusions and interpretations.
Use Stratified Random Assignment
Stratified random assignment involves grouping participants based on specific characteristics before random assignment, allowing for the control of variables and ensuring a balanced representation within groups.
This methodology is particularly useful in research design as it helps minimize the potential biases that can arise in studies. By dividing participants into homogeneous subgroups, such as age, gender, or socio-economic status, researchers can ensure that each subgroup is appropriately represented in the study sample. For example, in a healthcare study, stratified random assignment can ensure that both younger and older age groups are equally represented, providing more comprehensive results that can be generalized to the larger population.
Frequently Asked Questions
What is random assignment and why is it important in psychology.
Random assignment is the process of randomly assigning participants to different groups in a research study. It is important in psychology because it helps to eliminate bias and ensure that the groups being compared are similar, allowing researchers to determine the true effects of a variable.
How is random assignment different from random selection?
Random assignment involves randomly assigning participants to different groups, while random selection involves randomly choosing participants from a larger population. Random assignment is done within the chosen sample, while random selection is done before the sample is chosen.
What are some common methods of random assignment in psychology research?
Some common methods of random assignment include simple random assignment, stratified random assignment, and matched random assignment. Simple random assignment involves randomly assigning participants to groups with no restrictions. Stratified random assignment involves dividing participants into subgroups and then randomly assigning participants from each subgroup to different groups. Matched random assignment involves pairing participants based on certain characteristics and then randomly assigning one of each pair to a group.
Are there any limitations to random assignment in psychology research?
Yes, there are some limitations to random assignment. For example, it may not always be feasible or ethical to randomly assign participants to different groups. Additionally, random assignment does not guarantee that the groups will be exactly equal on all characteristics, which could potentially impact the results of the study.
What are the advantages of using random assignment in psychology research?
The main advantage of using random assignment is that it helps to eliminate bias and ensure that the groups being compared are similar. This allows researchers to make more accurate conclusions about the relationship between variables and determine causality.
Can random assignment be used in all types of psychology research?
Random assignment is commonly used in experimental research, where participants are randomly assigned to different conditions. However, it may not be as useful in other types of research, such as correlational studies, where participants are not manipulated and groups cannot be randomly assigned.

Lena Nguyen, an industrial-organizational psychologist, specializes in employee engagement, leadership development, and organizational culture. Her consultancy work has helped businesses build stronger teams and create environments that promote innovation and efficiency. Lena’s articles offer a fresh perspective on managing workplace dynamics and harnessing the potential of human capital in achieving business success.
Similar Posts
Understanding Observational Learning in Psychology
The article was last updated by Alicia Rhodes on February 4, 2024. Observational learning is a fascinating concept in psychology that sheds light on how…
Exploring the Mozart Effect in Psychology
The article was last updated by Sofia Alvarez on February 9, 2024. Have you ever heard of the Mozart Effect? This intriguing concept suggests that…
The Power of Chunking in Psychology: Examples and Applications
The article was last updated by Lena Nguyen on February 9, 2024. Have you ever struggled to remember a long list of items or solve…
Understanding Cognitive Accessibility in Psychology
The article was last updated by Dr. Naomi Kessler on February 8, 2024. Cognitive accessibility is a crucial aspect of daily life that impacts how…
The Role and Significance of a Neutral Stimulus in Psychology
The article was last updated by Ethan Clarke on February 4, 2024. Neutral stimuli play a crucial role in psychology, particularly in the realm of…
Guide to Writing a Psychology Essay
The article was last updated by Sofia Alvarez on February 9, 2024. Are you struggling with writing a psychology essay? You’re not alone. From understanding…

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- J Hum Reprod Sci
- v.4(1); Jan-Apr 2011
This article has been retracted.
An overview of randomization techniques: an unbiased assessment of outcome in clinical research.
Department of Biostatics, National Institute of Animal Nutrition & Physiology (NIANP), Adugodi, Bangalore, India
Randomization as a method of experimental control has been extensively used in human clinical trials and other biological experiments. It prevents the selection bias and insures against the accidental bias. It produces the comparable groups and eliminates the source of bias in treatment assignments. Finally, it permits the use of probability theory to express the likelihood of chance as a source for the difference of end outcome. This paper discusses the different methods of randomization and use of online statistical computing web programming ( www.graphpad.com /quickcalcs or www.randomization.com ) to generate the randomization schedule. Issues related to randomization are also discussed in this paper.
INTRODUCTION
A good experiment or trial minimizes the variability of the evaluation and provides unbiased evaluation of the intervention by avoiding confounding from other factors, which are known and unknown. Randomization ensures that each patient has an equal chance of receiving any of the treatments under study, generate comparable intervention groups, which are alike in all the important aspects except for the intervention each groups receives. It also provides a basis for the statistical methods used in analyzing the data. The basic benefits of randomization are as follows: it eliminates the selection bias, balances the groups with respect to many known and unknown confounding or prognostic variables, and forms the basis for statistical tests, a basis for an assumption of free statistical test of the equality of treatments. In general, a randomized experiment is an essential tool for testing the efficacy of the treatment.
In practice, randomization requires generating randomization schedules, which should be reproducible. Generation of a randomization schedule usually includes obtaining the random numbers and assigning random numbers to each subject or treatment conditions. Random numbers can be generated by computers or can come from random number tables found in the most statistical text books. For simple experiments with small number of subjects, randomization can be performed easily by assigning the random numbers from random number tables to the treatment conditions. However, in the large sample size situation or if restricted randomization or stratified randomization to be performed for an experiment or if an unbalanced allocation ratio will be used, it is better to use the computer programming to do the randomization such as SAS, R environment etc.[ 1 – 6 ]
REASON FOR RANDOMIZATION
Researchers in life science research demand randomization for several reasons. First, subjects in various groups should not differ in any systematic way. In a clinical research, if treatment groups are systematically different, research results will be biased. Suppose that subjects are assigned to control and treatment groups in a study examining the efficacy of a surgical intervention. If a greater proportion of older subjects are assigned to the treatment group, then the outcome of the surgical intervention may be influenced by this imbalance. The effects of the treatment would be indistinguishable from the influence of the imbalance of covariates, thereby requiring the researcher to control for the covariates in the analysis to obtain an unbiased result.[ 7 , 8 ]
Second, proper randomization ensures no a priori knowledge of group assignment (i.e., allocation concealment). That is, researchers, subject or patients or participants, and others should not know to which group the subject will be assigned. Knowledge of group assignment creates a layer of potential selection bias that may taint the data.[ 9 ] Schul and Grimes stated that trials with inadequate or unclear randomization tended to overestimate treatment effects up to 40% compared with those that used proper randomization. The outcome of the research can be negatively influenced by this inadequate randomization.
Statistical techniques such as analysis of covariance (ANCOVA), multivariate ANCOVA, or both, are often used to adjust for covariate imbalance in the analysis stage of the clinical research. However, the interpretation of this post adjustment approach is often difficult because imbalance of covariates frequently leads to unanticipated interaction effects, such as unequal slopes among subgroups of covariates.[ 1 ] One of the critical assumptions in ANCOVA is that the slopes of regression lines are the same for each group of covariates. The adjustment needed for each covariate group may vary, which is problematic because ANCOVA uses the average slope across the groups to adjust the outcome variable. Thus, the ideal way of balancing covariates among groups is to apply sound randomization in the design stage of a clinical research (before the adjustment procedure) instead of post data collection. In such instances, random assignment is necessary and guarantees validity for statistical tests of significance that are used to compare treatments.
TYPES OF RANDOMIZATION
Many procedures have been proposed for the random assignment of participants to treatment groups in clinical trials. In this article, common randomization techniques, including simple randomization, block randomization, stratified randomization, and covariate adaptive randomization, are reviewed. Each method is described along with its advantages and disadvantages. It is very important to select a method that will produce interpretable and valid results for your study. Use of online software to generate randomization code using block randomization procedure will be presented.
Simple randomization
Randomization based on a single sequence of random assignments is known as simple randomization.[ 3 ] This technique maintains complete randomness of the assignment of a subject to a particular group. The most common and basic method of simple randomization is flipping a coin. For example, with two treatment groups (control versus treatment), the side of the coin (i.e., heads - control, tails - treatment) determines the assignment of each subject. Other methods include using a shuffled deck of cards (e.g., even - control, odd - treatment) or throwing a dice (e.g., below and equal to 3 - control, over 3 - treatment). A random number table found in a statistics book or computer-generated random numbers can also be used for simple randomization of subjects.
This randomization approach is simple and easy to implement in a clinical research. In large clinical research, simple randomization can be trusted to generate similar numbers of subjects among groups. However, randomization results could be problematic in relatively small sample size clinical research, resulting in an unequal number of participants among groups.
Block randomization
The block randomization method is designed to randomize subjects into groups that result in equal sample sizes. This method is used to ensure a balance in sample size across groups over time. Blocks are small and balanced with predetermined group assignments, which keeps the numbers of subjects in each group similar at all times.[ 1 , 2 ] The block size is determined by the researcher and should be a multiple of the number of groups (i.e., with two treatment groups, block size of either 4, 6, or 8). Blocks are best used in smaller increments as researchers can more easily control balance.[ 10 ]
After block size has been determined, all possible balanced combinations of assignment within the block (i.e., equal number for all groups within the block) must be calculated. Blocks are then randomly chosen to determine the patients’ assignment into the groups.
Although balance in sample size may be achieved with this method, groups may be generated that are rarely comparable in terms of certain covariates. For example, one group may have more participants with secondary diseases (e.g., diabetes, multiple sclerosis, cancer, hypertension, etc.) that could confound the data and may negatively influence the results of the clinical trial.[ 11 ] Pocock and Simon stressed the importance of controlling for these covariates because of serious consequences to the interpretation of the results. Such an imbalance could introduce bias in the statistical analysis and reduce the power of the study. Hence, sample size and covariates must be balanced in clinical research.
Stratified randomization
The stratified randomization method addresses the need to control and balance the influence of covariates. This method can be used to achieve balance among groups in terms of subjects’ baseline characteristics (covariates). Specific covariates must be identified by the researcher who understands the potential influence each covariate has on the dependent variable. Stratified randomization is achieved by generating a separate block for each combination of covariates, and subjects are assigned to the appropriate block of covariates. After all subjects have been identified and assigned into blocks, simple randomization is performed within each block to assign subjects to one of the groups.
The stratified randomization method controls for the possible influence of covariates that would jeopardize the conclusions of the clinical research. For example, a clinical research of different rehabilitation techniques after a surgical procedure will have a number of covariates. It is well known that the age of the subject affects the rate of prognosis. Thus, age could be a confounding variable and influence the outcome of the clinical research. Stratified randomization can balance the control and treatment groups for age or other identified covariates. Although stratified randomization is a relatively simple and useful technique, especially for smaller clinical trials, it becomes complicated to implement if many covariates must be controlled.[ 12 ] Stratified randomization has another limitation; it works only when all subjects have been identified before group assignment. However, this method is rarely applicable because clinical research subjects are often enrolled one at a time on a continuous basis. When baseline characteristics of all subjects are not available before assignment, using stratified randomization is difficult.[ 10 ]
Covariate adaptive randomization
One potential problem with small to moderate size clinical research is that simple randomization (with or without taking stratification of prognostic variables into account) may result in imbalance of important covariates among treatment groups. Imbalance of covariates is important because of its potential to influence the interpretation of a research results. Covariate adaptive randomization has been recommended by many researchers as a valid alternative randomization method for clinical research.[ 8 , 13 ] In covariate adaptive randomization, a new participant is sequentially assigned to a particular treatment group by taking into account the specific covariates and previous assignments of participants.[ 7 ] Covariate adaptive randomization uses the method of minimization by assessing the imbalance of sample size among several covariates.
Using the online randomization http://www.graphpad.com/quickcalcs/index.cfm , researcher can generate randomization plan for treatment assignment to patients. This online software is very simple and easy to implement. Up to 10 treatments can be allocated to patients and the replication of treatment can also be performed up to 9 times. The major limitations of this software is that once the randomization plan is generated, same randomization plan cannot be generated as this uses the seed point of local computer clock and is not displayed for further use. Other limitation of this online software Maximum of only 10 treatments can be assigned to patients. Entering the web address http://www.graphpad.com/quickcalcs/index.cfm on address bar of any browser, the page of graphpad appears with number of options. Select the option of “Random Numbers” and then press continue, Random Number Calculator with three options appears. Select the tab “Randomly assign subjects to groups” and press continue. In the next page, enter the number of subjects in each group in the tab “Assign” and select the number of groups from the tab “Subjects to each group” and keep number 1 in repeat tab if there is no replication in the study. For example, the total number of patients in a three group experimental study is 30 and each group will assigned to 10 patients. Type 10 in the “Assign” tab and select 3 in the tab “Subjects to each group” and then press “do it” button. The results is obtained as shown as below (partial output is presented)
Another randomization online software, which can be used to generate randomization plan is http://www.randomization.com . The seed for the random number generator[ 14 , 15 ] (Wichmann and Hill, 1982, as modified by McLeod, 1985) is obtained from the clock of the local computer and is printed at the bottom of the randomization plan. If a seed is included in the request, it overrides the value obtained from the clock and can be used to reproduce or verify a particular plan. Up to 20 treatments can be specified. The randomization plan is not affected by the order in which the treatments are entered or the particular boxes left blank if not all are needed. The program begins by sorting treatment names internally. The sorting is case sensitive, however, so the same capitalization should be used when recreating an earlier plan. Example of 10 patients allocating to two groups (each with 5 patients), first the enter the treatment labels in the boxes, and enter the total number of patients that is 10 in the tab “Number of subjects per block” and enter the 1 in the tab “Number of blocks” for simple randomization or more than one for Block randomization. The output of this online software is presented as follows.
The benefits of randomization are numerous. It ensures against the accidental bias in the experiment and produces comparable groups in all the respect except the intervention each group received. The purpose of this paper is to introduce the randomization, including concept and significance and to review several randomization techniques to guide the researchers and practitioners to better design their randomized clinical trials. Use of online randomization was effectively demonstrated in this article for benefit of researchers. Simple randomization works well for the large clinical trails ( n >100) and for small to moderate clinical trials ( n <100) without covariates, use of block randomization helps to achieve the balance. For small to moderate size clinical trials with several prognostic factors or covariates, the adaptive randomization method could be more useful in providing a means to achieve treatment balance.
Source of Support: Nil
Conflict of Interest: None declared.
IMAGES
VIDEO
COMMENTS
Studies that use simple random assignment are also called completely randomized designs. Random assignment is a key part of experimental design. It helps you ensure that all groups are comparable at the start of a study: any differences between them are due to random factors, not research biases like sampling bias or selection bias.
Random assignment plays an important role in the psychology research process. Not only does this process help eliminate possible sources of bias, but it also makes it easier to generalize the results of a tested sample of participants to a larger population. Random assignment helps ensure that members of each group in the experiment are the ...
Random assignment helps ensure that the groups are comparable at the onset of the study. ... Scientific evidence is a long and continuous process, and the groups will tend to be equal in the long run when data is aggregated in a meta-analysis. Additionally, external validity (i.e., the extent to which the researcher can use the results of the ...
Random assignment uses chance to assign subjects to the control and treatment groups in an experiment. This process helps ensure that the groups are equivalent at the beginning of the study, which makes it safer to assume the treatments caused any differences between groups that the experimenters observe at the end of the study.
Random assignment of participants helps to ensure that any differences between and within the groups are not systematic at the outset of the experiment. ... Random sampling is a related, but distinct, process. Random sampling is recruiting participants in a way that they represent a larger population.
Random assignment is a method for assigning participants in a sample to the different conditions, and it is an important element of all experimental research in psychology and other fields too. In its strictest sense, random assignment should meet two criteria. One is that each participant has an equal chance of being assigned to each condition ...
Random Assignment is a process used in research where each participant has an equal chance of being placed in any group within the study. This technique is essential in experiments as it helps to eliminate biases, ensuring that the different groups being compared are similar in all important aspects. ... These generators ensure that each ...
The upshot is that random assignment to conditions—although not infallible in terms of controlling extraneous variables—is always considered a strength of a research design. Note: Do not confuse random assignation with random sampling. Random sampling is a method for selecting a sample from a population; we will talk about this in Chapter 7.
Random distribution can be achieved by an automatized process, like a random number generator, pre-existing lists for assigning the subjects to the groups in a certain order, or even a coin flip. Importantly, random assignment cannot ensure that the distributions of gender, age, and other potential confounds are the same across all groups.
Random assignment of participants helps to ensure that any differences between and within the groups are not systematic at the outset of the experiment. Thus, any differences between groups recorded at the end of the experiment can be more confidently attributed to the experimental procedures or treatment. … Random assignment does not ...
If there are two conditions in an experiment, then the simplest way to implement random assignment is to flip a coin for each participant. Heads means being assigned to the treatment and tails means being assigned to the control (or vice versa). 3. Rolling a die. Rolling a single die is another way to randomly assign participants.
Random assignment allows cause-and-effect relationships to be identified but it is only one part of the process. Random assignment produces groups that are, in theory, equal at the start of the ...
Random assignment in psychology involves each participant having an equal chance of being chosen for any of the groups, including the control and experimental groups. It helps control for potential confounding variables, reducing the likelihood of pre-existing differences between groups. This method enhances the internal validity of experiments ...
Random assignment is used in experiments with a between-groups or independent measures design. In this research design, there's usually a control group and one or more experimental groups. Random assignment helps ensure that the groups are comparable.
Random Assignment Random assignment helps to ensure that the experimental and control groups are equivalent before the introduction of the treatment. This is perhaps one of the most critical aspects of the classic experiment and all experimental designs. ... assigning them to groups via a random assignment process helps to ensure that any ...
With simple random assignment, every member of the sample has a known or equal chance of being placed in a control group or an experimental group. Studies that use simple random assignment are also called completely randomised designs. Random assignment is a key part of experimental design. It helps you ensure that all groups are comparable at ...
Random assignment in psychology refers to the method of placing participants in experimental groups through a random process to ensure unbiased distribution of characteristics. This method is crucial in research studies as it allows for the elimination of potential biases that could skew results, leading to more accurate and generalizable findings.
Random selection, or random sampling, is a way of selecting members of a population for your study's sample. In contrast, random assignment is a way of sorting the sample into control and experimental groups. Random sampling enhances the external validity or generalizability of your results, while random assignment improves the internal ...
Second, proper randomization ensures no a priori knowledge of group assignment (i.e., allocation concealment). That is, researchers, subject or patients or participants, and others should not know to which group the subject will be assigned. Knowledge of group assignment creates a layer of potential selection bias that may taint the data. Schul ...
Random assignment, blinding, and controlling are key aspects of the design of experiments, because they help ensure that the results are not spurious or deceptive via confounding. This is why randomized controlled trials are vital in clinical research, especially ones that can be double-blinded and placebo-controlled. Benefits of random assignment
random assignment helps to ensure that the experimental groups are (on average) equal and that any difference on the dependent variable is due to the participants' being in different experimental groups. and more. Study with Quizlet and memorize flashcards containing terms like How are theories, hypotheses, and research different? a. Theories ...
random assignment. randomly assigns participants to a condition. Increases confidence that the groups are "before the manipulation" ... RA helps ensure that groups are similar before manipulation. Thus, any differences after the manipulation, are due to the manipulation, not CVs. About us.
Study with Quizlet and memorize flashcards containing terms like If people who score high on extraversion also score high on measures of happiness, extraversion and happiness are _____, I develop a Bleemness scale. It consists of one item, "How Bleem are you?" The most likely form of validity represented by this scale is _____, Howard wants to study the relationship between income and dominance.