

Realistic Text-to-Speech AI converter
Create realistic Voiceovers online! Insert any text to generate speech and download audio mp3 or wav for any purpose. Speak a text with AI-powered voices.You can convert text to voice for free for reference only. For all features, purchase the paid plans
How to convert text into speech?
- Just type some text or import your written content
- Press "generate" button
- Download MP3 / WAV
Full list of benefits of neural voices
Downloadable tts.
You can download converted audio files in MP3, WAV, OGG for free.

If your Limit balance is sufficient, you can use a single query to convert a text of up to 2,000,000 characters into speech.
Commercial Use
You can use the generated audio for commercial purposes. Examples: YouTube, Tik Tok, Instagram, Facebook, Twitch, Twitter, Podcasts, Video Ads, Advertising, E-book, Presentation and other.

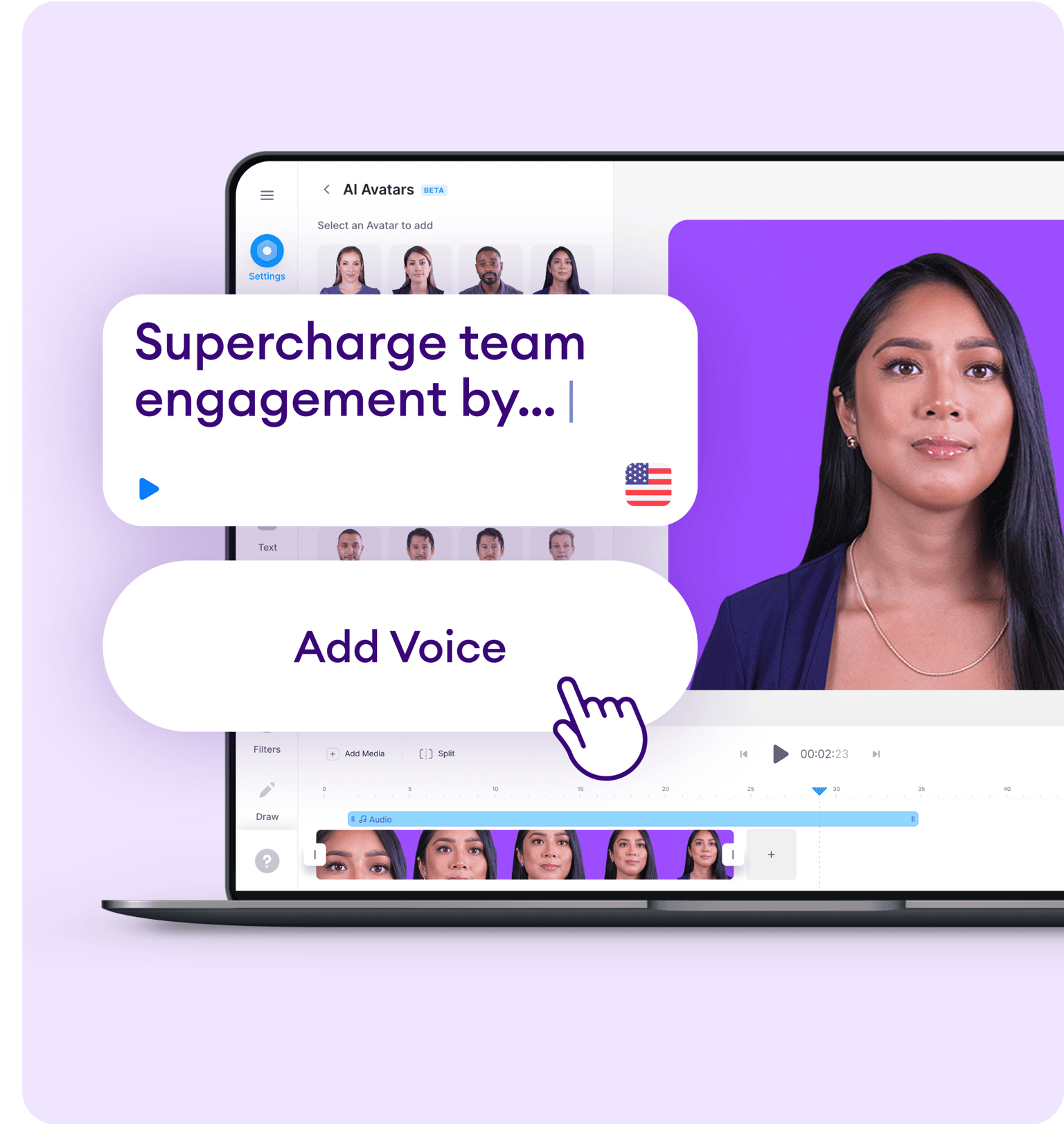
Multi-voice editor
Dialogue with AI Voices. You can use several voices at once in one text.

Custom voice settings
Change Speed, Pitch, Stress, Pronunciation, Intonation , Emphasis , Pauses and more. SSML support .

You spend little on re-dubbing the text. Limits are spent only for changed sentences in the text.

Over 1000 Natural Sounding Voices
Crystal-clear voice over like a Human. Males, females, children's, elderly voices.
Powerful support
We will help you with any questions about text-to-speech. Ask any questions, even the simplest ones. We are happy to help.
Compatible with editing programs
Works with any video creation software: Adobe Premier, After effects, Audition, DaVinci Resolve, Apple Motion, Camtasia, iMovie, Audacity, etc.

You can share the link to the audio. Send audio links to your friends and colleagues.

Cloud save your history
All your files and texts are automatically saved in your profile on our cloud server. Add tracks to your favorites in one click.

Use our text to voice converter to make videos with natural sounding speech!
Say goodbye to expensive traditional audio creation
Cheap price. Create a professional voiceover in real time for pennies. it is 100 times cheaper than a live speaker.
Traditional audio creation

- Expensive live speakers, high prices
- A long search for freelancers and studios
- Editing requires complex tools and knowledge
- The announcer in the studio voices a long time. It takes time to give him a task and accept it..

- Affordable tts generation starting at $0.08 per 1000 characters
- Website accessible in your browser right now
- Intuitive interface, suitable for beginners
- SpeechGen generates text from speech very quickly. A few clicks and the audio is ready.
Create AI-generated realistic voice-overs.
Ways to use. Cases.
See how other people are already using our realistic speech synthesis. There are hundreds of variations in applications. Here are some of them.
- Voice over for videos. Commercial, YouTube, Tik Tok, Instagram, Facebook, and other social media. Add voice to any videos!
- E-learning material. Ex: learning foreign languages, listening to lectures, instructional videos.
- Advertising. Increase installations and sales! Create AI-generated realistic voice-overs for video ads, promo, and creatives.
- Public places. Synthesizing speech from text is needed for airports, bus stations, parks, supermarkets, stadiums, and other public areas.
- Podcasts. Turn text into podcasts to increase content reach. Publish your audio files on iTunes, Spotify, and other podcast services.
- Mobile apps and desktop software. The synthesized ai voices make the app friendly.
- Essay reader. Read your essay out loud to write a better paper.
- Presentations. Use text-to-speech for impressive PowerPoint presentations and slideshow.
- Reading documents. Save your time reading documents aloud with a speech synthesizer.
- Book reader. Use our text-to-speech web app for ebook reading aloud with natural voices.
- Welcome audio messages for websites. It is a perfect way to re-engage with your audience.
- Online article reader. Internet users translate texts of interesting articles into audio and listen to them to save time.
- Voicemail greeting generator. Record voice-over for telephone systems phone greetings.
- Online narrator to read fairy tales aloud to children.
- For fun. Use the robot voiceover to create memes, creativity, and gags.
Maximize your content’s potential with an audio-version. Increase audience engagement and drive business growth.
Who uses Text to Speech?
SpeechGen.io is a service with artificial intelligence used by about 1,000 people daily for different purposes. Here are examples.
Video makers create voiceovers for videos. They generate audio content without expensive studio production.
Newsmakers convert text to speech with computerized voices for news reporting and sports announcing.
Students and busy professionals to quickly explore content
Foreigners. Second-language students who want to improve their pronunciation or listen to the text comprehension
Software developers add synthesized speech to programs to improve the user experience.
Marketers. Easy-to-produce audio content for any startups
IVR voice recordings. Generate prompts for interactive voice response systems.
Educators. Foreign language teachers generate voice from the text for audio examples.
Booklovers use Speechgen as an out loud book reader. The TTS voiceover is downloadable. Listen on any device.
HR departments and e-learning professionals can make learning modules and employee training with ai text to speech online software.
Webmasters convert articles to audio with lifelike robotic voices. TTS audio increases the time on the webpage and the depth of views.
Animators use ai voices for dialogue and character speech.
Text to Speech enables brands, companies, and organizations to deliver enhanced end-user experience, while minimizing costs.
Frequently Asked Questions
Convert any text to super realistic human voices. See all tariff plans .
Enhance Your Content Accessibility
Boost your experience with our additional features. Easily convert PDFs, DOCx files, and video subtitles into natural-sounding audio.
📄🔊 PDF to Audio
Transform your PDF documents into audible content for easier consumption and enhanced accessibility.
📝🎧 DOCx to mp3
Easily convert Word documents into speech for listening on the go or for those who prefer audio format
📺💬 Subtitles to Speech
Make your video content more accessible by converting subtitles into natural-sounding audio.
Supported languages
- Amharic (Ethiopia)
- Arabic (Algeria)
- Arabic (Egypt)
- Arabic (Saudi Arabia)
- Bengali (India)
- Catalan (Spain)
- English (Australia)
- English (Canada)
- English (GB)
- English (Hong Kong)
- English (India)
- English (Philippines)
- German (Austria)
- Hindi India
- Spanish (Argentina)
- Spanish (Mexico)
- Spanish (United States)
- Tamil (India)
- All languages: +76
We use cookies to ensure you get the best experience on our website. Learn more: Privacy Policy
Free AI Text to Speech Online

Click to generate speech in:
Intelligent ai speech synthesis, diverse and dynamic voices, emotional range..
Diverse emotional inflections tailored for every narrative need.
Multilingual Capability.
All our voices fluently span 29 languages, retaining unique characteristics across each.
Voice Variety.
Design with Voice Design, explore with Voice Library, or select top-tier voice actors for unmatched natural voice quality.

Text to Speech in 29 Languages
Precision voice tuning.
Choose between expressive variability or consistent stability to fit your content's tone.
Clarity + Similarity Enhancement
Optimize for clear, artifact-free voices or enhance for speaker resemblance.
Style Exaggeration
Accentuate voice styles or prioritize speed and stability.
Text to speech for teams of all sizes

The voices are really amazing and very natural sounding. Even the voices for other languages are impressive. This allows us to do things with our educational content that would not have been possible in the past.
It's amazing to see that text to speech became that good. Write your text, select a voice and receive stunning and near-perfect results! Regenerating results will also give you different results (depending on the settings). The service supports 30+ languages, including Dutch (which is very rare). ElevenLabs has proved that it isn't impossible to have near-perfect text-to-speech 'Dutch'...
We use the tool daily for our content creation. Cloning our voices was incredibly simple. It's an easy-to-navigate platform that delivers exceptionally high quality. Voice cloning is just a matter of uploading an audio file, and you're ready to use the voice. We also build apps where we utilize the API from ElevenLabs; the API is very simple for developers to use. So, if you need a...
As an author I have written numerous books but have been limited by my inability to write them in other languages period now that I have found 11 labs, it has allowed me to create my own voice so that when writing them in different languages it's not someone else's voice but my own. That's certainly lends a level of authenticity that no other narrator can provide me.
ElevenLabs came to my notice from some Youtube videos that complained how this app was used to clone the US presidents voice. Apparently the app did its job very well. And that is the best thing about ElevenLabs. It does its job well. Converting text to speech is done very accurately. If you choose one of the 100s of voices available in the app, the quality of the output is superior to all...
Absolutely loving ElevenLabs for their spot-on voice generations! 🎉 Their pronunciation of Bahasa Indonesia is just fantastic - so natural and precise. It's been a game-changer for making tech and communication feel more authentic and easy. Big thumbs up! 👍
I have found ElevenLabs extremely useful in helping me create an audio book utilizing a clone of my own voice. The clone was super easy to create using audio clips from a previous audio book I recorded. And, I feel as though my cloned voice is pretty similar to my own. Using ElevenLabs has been a lot easier than sitting in front of a boom mic for hours on end. Bravo for a great AI product!
The variety of voices and the realness that expresses everything that is asked of it
I like that ElevenLabs uses cutting-edge AI and deep learning to create incredibly natural-sounding speech synthesis and text-to-speech. The voices generated are lifelike and emotive.
A fast and easy-to-use text to speech API
We obsess over building the fastest and simplest text to speech API so you can focus on building incredible applications.

Ultra-low latency.
We deliver streamed audio in under a second.
Ease of use.
ElevenLabs brings the most compelling, rich and lifelike voices to developers in just a few lines of code.
Developer Community.
Get all the help you need through our expert community.
Global AI Speech Generator

Language selection
Accent selection, audio generation, wall of text to speech voices, how to use text to speech, choose your preferred voice, settings, and model..
For a pre-made voice, you can use our extensive library of voices. Or, you can clone, customize and fine-tune voices.

Enter the text you want to convert to speech.
Write naturally in any of our supported languages. Our AI will understand the language and context.

Generate spoken audio and instantly listen to the results.
Convert written text to high-quality files that can be downloaded in a variety of audio formats.

Perfect Your Sound
Punctuation.
The placement of commas, periods, and other punctuation significantly influences the delivery and pauses in the output.
Longer text provides added context, ensuring a smoother and more natural audio flow.
Speaker Profile
Match your content to the ideal speaker. Different profiles have distinct delivery styles, catering to various tones and emotions.
Voice Settings
Refine your output by adjusting voice settings. Find the perfect balance to enhance clarity and authenticity.
Text to Speech Use Cases
Our AI text to speech software is designed to be flexible and easy to use, with a variety of voice options to suit your needs.
Take content creation to the next level
Create immersive gaming experiences, publish your written works, build engaging ai chatbots.

Why ElevenLabs Text to Speech?
Efficient content production..
Transform long written content to audio, fast. Maximize reach without traditional recording constraints.
Advanced API.
Seamlessly integrate and experience dynamic TTS capabilities.
Contextual TTS.
Our AI reads between the lines, capturing the heart of the content.
Language Authenticity.
Experience genuine speech in 29 languages, from nuances to native idioms.
Comprehensive Support.
Never feel lost. Our dedicated support and rich resource library mean you're always equipped to make the most of our cutting-edge technology.
Ethical AI Principles.
We prioritize user privacy, data protection, and uphold the highest ethical standards in AI development and deployment.
Frequently asked questions
How does the elevenlabs ai text to speech differ from other tts technologies.
ElevenLabs TTS leverages advanced deep learning models which are regularly updated and refined, ensuring high-quality audio output, emotion mapping, and a vast range of vocal choices for your ideal custom voice.
Can I customize the voice settings to match specific content needs?
Absolutely. Users can adjust Stability, Clarity, and Enhancement settings, allowing for voice outputs that range from entertainingly expressive to professionally sincere. Our platform provides the flexibility to match your content's unique requirements.
What is AI text to speech used for?
Text to speech has a vast array of applications, some are well established but more are emerging all the time. TTS is ideal for creating explainer videos, converting books into audio and producing creative video content without hiring voice actors. Our speech technology is ideal for any situation where accessibility and engagement can be improved through communicated written content in a high-quality voice.
What does "text to speech with emotion" mean?
It means our artificial intelligence model understands the context and can deliver the natural sounding speech with appropriate emotional intonations – be it excitement, sorrow, or neutrality. It adds a layer of realism, making the speech output more relatable and engaging.
How many languages does ElevenLabs support?
ElevenLabs proudly supports text to speech synthesis in 29 languages, ensuring that your content can resonate with a global audience.
How varied are the voice options available on ElevenLabs?
We offer a diverse range of voice profiles, catering to different tones, accents, and emotions. Whether you're seeking a particular regional accent or a specific emotional delivery, ElevenLabs ensures you find the perfect match for your content.
How secure is my data with ElevenLabs?
User data privacy and security are our top priorities. All user data and text inputs are handled with the utmost care, ensuring they are not used beyond the specified service purpose.
Does ElevenLabs offer an API for developers?
Yes, we provide a robust API that allows developers to integrate our advanced text-to-speech capabilities into their own applications, platforms, or tools.
How can I turn text into mp3 speech?
ElevenLabs makes it easy to turn text into mp3. Simply enter your text, choose a voice, generate the audio, and download.
Text to Speech Voice Over with Realistic AI Voices
Murf offers a selection of 100% natural sounding AI voices in 20 languages to make professional voice over for your videos and presentations. Start your free trial.

Quality Guaranteed, No Robotic Voices
Our voices are all human sounding and quality checked across dozens of parameters. Gone are the days of robotic text to speech, most people can’t even tell between our advanced AI voices and recorded human voices.
Text to Speech Voices in 20+ Languages
Murf offers a selection of voices across 20+ languages. Most languages have voices available for testing quality in the free plan. Some languages also support multiple accents like English, Spanish and Portuguese.

A Simple Text to Voice Converter

High-Quality Voices for Every Use Case

Not Just a Text to Speech Tool

Emphasize specific words
Want to make your voiceover sound interesting? Use Murf’s ‘Emphasis’ feature to put that extra force on syllables, words, or phrases that add life to your voiceover.

Take control of your narration with pitch
Use Murf’s ‘Pitch’ functionality to draw the listeners' attention to words or phrases expressing emotions. Customize the voice as you like to make it work for yourself.

Elevate your story with pauses
Add pauses of varying lengths to your narration using Murf’s ‘Pause’ feature to give the listener's attention powers a rest and prepare them to receive your message.

Perfect Word Pronunciation
Articulate words accurately and enhance clarity in speech by customizing pronunciation. Use alternative spellings or IPAs to achieve the right pronunciation.

Fine Tune Narration Speed
Effortlessly increase or decrease the pace of the voiceover to ensure it aligns with the rhythm and flow of the message.

Expressive Voice Style Palette
Infuse your narration with the exact emotion your content needs using Murf’s dynamic voice styles. Choose from versatile options like excited, sad, angry, calm, terrified, friendly, and more.
Text to Voice Made Easy
Reliable and secure. your data, our promise..

Why Use Murf Text to Speech?
Murf's text to audio software changes the way you create and edit voiceovers with lifelike, flawless AI voices. What used to take hours, weeks, or even months now only takes minutes. You can also include images, videos, and presentations to your voiceover and sync them together without the need for a third-party tool. Here are a few reasons why you should use Murf's text to speech.

Save time and hundreds of dollars in recording expensive voice overs.

Editing voice over is as simple as editing text. Just cut, copy paste and render.

Create a consistent brand voice across all your customer touchpoints.

Connect with global customers effectively with our multiple language AI voices.

Build scalable voice applications with Murf’s API.
Voice over in 20+ languages.
@MURFAISTUDIO

Hear from Our Customers

Murf allows me to create TTS voiceovers in a matter of minutes. Previously, I had a tedious process of sending scripts out to agencies and waited days to get voiceovers back. With Murf, I can make changes whenever I like, diversify my speaker portfolio by picking new voices instantly, and even ramp up my course localization.

Murf it's an amazing text-to-speech AI voice generator, easy to work with, flexible and reliable. Its voices, non-pro and pro (either English, Spanish, and French), are both so real that many clients of mine have been surprised to know that they were not from professional voice-over actors.

I recently tried murf.ai and I have to say I am thoroughly impressed. The quality of the generated voice is exceptional and very realistic, which is important for my business needs. The platform is user-friendly and easy to navigate, and the range of voices available is impressive.

This website is so easy and clear that you will find yourself mastering all the tools in no time. The fact that regenerating the voice with different voices, punctuations, and tones does not deduct from your allowed minutes is so fair and reasonable. And the price is affordable too. Highly recommended

This is the most human-like voice I was able to find. It's very lively,and I found it suitable for many types of videos including marketing and e-learning, it kept my audience engaged!

I just started to create a video channel about historical figures, and Murf.ai really brings them to life. I found my top voice for my scripts, and the easy integration of video elements makes it a breeze to create informative videos. I also like the easy changes one can make to the tone of voice from within the editor.

Frequently Asked Questions
Text to speech: what is it and how does it works.
In essence, text to speech is the generation of synthesized speech from text. It was primarily designed as an assistive technology to help individuals with hearing impairments, visual and learning disabilities, and aged citizens to understand and consume content in a better manner. Today, the applications of TTS systems have grown manifold, and range from content creation to voiceover generation to customer service, and more. With a touch of a button, TTS can take words on a computer or other digital device and convert them into audio files. Today, the technology is used to create narratives for explainer videos or product demos , turn a book into an audio book, generate voiceovers for elearning materials, training videos, ads and commercials, YouTube videos, or podcasts, among other things.
How does TTS work?
Text to speech software leverages AI and deep learning algorithms to process the written input and sythesize a spoken output. The written text is first broken down into individual words and phrases by the TTS software’s text analysis component and then various rules and algorithms are applied to determine the appropriate pronunciation, inflection, and emphasis for each word. The speech synthesis component of the software then takes this information along with pre-recorded sound samples of individual phonemes and uses it to generate the spoken words and sentences, which is then spoken out loud using a synthesized voice generated by a computer or other device.
Top Five Use Cases of Text to Speech Software
From increasing brand visibility and customer traction to improving customer service and boosting customer engagement to helping people with visual impairments, reading difficulties, and learning disabilities, text to speech is proving to be a game-changing technology across industries.
Considering the myriad of benefits offered by TTS technology and how simple they make information retention, businesses are integrating text to speech into their workflow in one form or another. Here is a glimpse of all the ways text to speech is currently being utilized:
TTS in Assistive Technology
For quite some time now, text to speech software has been used as an accessibility tool for individuals with a variety of special needs linked to Dyslexia, visual impairments, or other disabilities that make it difficult to read traditional text. Using TTS platforms, people facing such problems can convert text to speech and learn by listening on the go. Text to speech solutions also improves literacy and comprehension skills. When used in language education, they can make learning more engaging. For example, it's much easier and faster to apprehend a foreign language when listening to the live translation of written words with correct intonation and pronunciation than when reading.
TTS in Translations
Given the fact that modern text to speech solutions come with multilingual support, brands can reach local customers by converting their content from text to audio in the local language. This will help target and connect with native-speaking customers or audiences in remote areas.
Furthermore, text to speech solutions can also be used to translate content from one language to another. This is especially beneficial for users who come across a piece of content in a language they don't understand and can have it read aloud in their native language or a language they are adept at for better understanding.
TTS in Customer Service
With advancements in speech synthesis, it has become easier to create text and convert it to pre-recorded voices for interactive voice response calls. Today's TTS technology comes with human-like AI voices that can make natural human conversations on IVR calls. This helps contact centers provide personalized customer interactions without requiring assistance from live agents.
TTS serves as both an inbound and outbound customer service tool. For example, when used in tandem with an IVR system, TTS solutions can provide personalized information to callers, such as greeting a customer by name, providing account information, confirming details about the order, payment, or appointment, and more. Furthermore, by tapping into the extensive range of languages, accents, and a wide variety female and male voices offered by TTS software, companies can provide an experience that matches their customer's profiles or help promote an image for their brand.
TTS in Automotive Industry
Text to speech solutions help make connected and autonomous cars safer and sound truly unique, begetting an on-road revolution. They can be used in in-car conversational systems for navigational prompts and map data, infotainment systems to read aloud information about the car, such as fuel level or tire pressure, and swap music and voice assistants to place phone calls, read messages, and more.
TTS in Healthcare
In the healthcare industry, text to speech solutions can be used to read aloud patient information, instructions for taking medication, and provide information to doctors and other medical professionals about upcoming appointments, scheduling calls, and more.
Why text to speech matters for businesses?
It's an exciting time to stake your claim in the realm of speech synthesis. There are a number of key industries where the text to speech technology has already succeeded in making a dent. Here are a few different ways in which businesses can harness the power of text to speech and save money and time:
Enhances customer experience
Any business can leverage TTS to alleviate human agent workload and offer customized conversational customer support. By integrating these solutions with IVR systems, companies can automate customer interactions, facilitate smart and personalized self-service by providing voice responses in the customer's language and remove communication barriers. Furthermore, organizations can also use TTS to make AI-enabled routine calls to inform customers about promotional offers, payment reminders, and much more. That said, by using text to speech in voice-activated chatbots, businesses can provide customers, especially the visually impaired, with a more immersive experience, thereby enriching the customer experience.
Global market penetration
Text to speech solutions offer synthetic voices in multiple languages enabling businesses to create content in several different languages and reach customers across different countries worldwide. Organizations can build trust with customers by creating voiceovers for ads, commercials, product demos, explainer videos, and PowerPoint presentations, among other content pieces in regional dialects and native languages.
Increases Web Presence
That said, with the help of TTS solutions, businesses can provide an audio version of their content in addition to a written version, enabling more accessibility to a broader audience, who can choose whether to read or listen to it based on their preferences. This increases the brand's web presence. Moreover, using text to speech, brands can create a familiar, recognizable and unique voice across all their voice channels, making it easy for customers to identify the brand the second they hear it. This way, the brand shows up everywhere and improves its web presence.
Who else can benefit from text to speech?
Today’s online text to speech systems can generate speech that is almost indistinguishable from a human voice, making them a valuable tool for a wide range of applications, from improving accessibility for people with disabilities to providing convenient and efficient ways to communicate information.
Here is a list of everybody that can benefit immensely from using best text to speech softwares for their content and voiceover needs:
Many educators struggle to enhance the value of their curriculum while simplifying their workloads. This is where realistic text to speech technology plays a key role. Firstly, it improves accessibility for students with disabilities. Screen readers and other tools which are speech enabled can make learning an equal opportunity and enjoyable experience for those with learning and physical disabilities. Secondly, it helps teach comprehension in an effective manner. Text to speech software offers an easy way for students to listen to how words are spoken in their natural structure and following the same is easier through audio playback.
TTS software also enhances engagement and makes learning interesting for students. For example, using natural sounding text to speech voices, teachers can create engaging presentations and elearning modules that capture student’s attention.
In marketing specifically, text to speech technology can help improve data collection, facilitate comprehensive customer profiling, and better data analysis. Online text to speech tools offer an easy way for businesses to reach a broader audience and create customized user experiences.
For instance, marketing teams can create and deliver videos to prospective clients to establish a connection and brief them on queries and complicated products or services in the language and accent the customer is comfortable with. Furthermore, AI voices enable marketing teams to create crisp, high quality professional-sounding voiceovers in a few simple steps without hiring voice actors or requiring any professional recording studios.
Text to speech generators offer authors numerous advantages. One, it serves as an editing aid and helps storytellers proof read their novels and manuscripts to identify grammatical errors and other mistakes in their drafts before publishing. Listening to their stories being read aloud also allows authors to gauge the response to their work on other people. Authors can also use realistic voice generators to convert their books into audiobooks and podcasts and broaden the reach of their work.
From interviews about true crime to politics and science, there are all sorts of popular podcast formats today. And, regardless of how good your podcast topic is, it won’t matter if the host doesn’t have a good voice. That said, not everyone can have that best podcast voice like an old-school radio anchor or a news presenter. This is where text to speech platforms come in. You don’t have to record scripted intros, prologues, or epilogues, an AI narrator can do it for you. Through text to speech software, you can automatically create the narrative and voiceover for your podcast in the language and tone you want in a matter of minutes by simply uploading the script to the platform.
Creating good voice overs for your animated explainer videos or product demos or games typically meant investing a lot of money on recording equipment and hiring professional voice actors. Not anymore. With AI text to speech platforms, you can add natural sounding voices to your animated video to make them more engaging and captivating. In fact, with text to speech software, you can give each character in your animated video or game, a unique voice.
Customer Support Executives
Integrating realistic text to voice software with an IVR system enables customer service agents to concentrate more on complex customers rather than common queries. TTS-enabled IVR systems are capable of gathering information and providing responses to customers as necessary in a way that sounds just like an actual customer service agent.
Furthermore, TTS systems also eliminate the need for IVR businesses to schedule voiceover retakes months in advance. With TTS systems, businesses can render a new voiceover in minutes creating thousands of iterations within a few clicks.
Text to speech is a game-changer for students of all ages and educational levels. By converting written text into spoken words, students can enhance their learning experience and comprehension. Text to speech technology can read content out aloud, making it easier for students to absorb information while multitasking. It is particularly useful for students with dyslexia, ADHD, or other learning disabilities as it provides them with an alternative way to consume educational content. Furthermore, the tool can also be used to add narrations to presentations, explainer videos, how-to videos, and more.
Be it corporate trainers, fitness trainers, or lifestyle instructors, text to speech can be used to create engaging and accessible learning materials. For example, fitness trainers can convert written content into audio-based workout routines and personalized exercise plans. This helps to increase engagement levels and knowledge retention among the audience.
Similarly, corporate trainers can also use TTS to create presentations on employee policies and other organizational practices. It makes the coursework highly engaging and improves employee performance at many levels. Additionally, using audio course materials is a great way to respect the staff with disabilities and give everyone equal access to training.
Content Creators
Content creators, including social media users, bloggers, writers, influencers, and authors, can leverage text to speech to enhance their productivity and reach a broader audience.
This technology enables content creators to convert their written articles, scripts, blog posts, or eBooks into high-quality audio files quickly in multiple languages instead of manually recording the voiceover.
Consequently, it opens up new avenues for content consumption. This allows readers to listen to the content while performing other tasks or when reading isn’t feasible, such as during commutes or workouts.
Video Producers
Video creators can easily add voiceovers or narration to their videos, eliminating the need for hiring voice actors or spending hours recording audio. This not only saves time and resources but also ensures consistent and professional-sounding voiceovers.
Murf: The Ultimate Text to Speech Software
If you are looking for a text to speech generator that can create stunning voiceovers for your tutorials, presentations, or videos, Murf is the one to go for.
Murf can generate human-like, realistic, and natural-sounding voices. Its pièce de résistance is that Murf can do it in over 120+ unique voices in 20+ languages.
This text aloud reader also allows you to tweak the pitch of the voice, add pauses or emphasis, and alter the speed of the output to get the output just the way you want it.
And the best part? Murf is extremely easy to use. Just type or paste in your script, choose your preferred voice in the language you want, and hit play. Murf will do the rest.
Create Engaging Content with Murf's AI Voices
Murf text to audio converter can be used in a number of scenarios to elevate the quality of your overall content. Let's look at a few use cases where Murf can help and why it’s the best text to speech reader out there:
E-learning Videos
Murf’s free text to speech reader can help you create e-learning videos in multiple languages that will make your content accessible to a global audience. You can also increase the engagement of your e-learning video by adding emotions and expressions to your content.
Presentations
Murf’s AI voices can add a touch of professionalism to your presentations to help drive home those key points. You can use Murf to narrate your slides, explain your concepts, or tell the story of your brand in the exact tone and style you envisioned.
You can also use this free text to speech reader to make your audiobooks sound as if they its been narrated by an actual person.
With Murf, you can also mix and match different voices for the various characters in the audiobook to take your storytelling up a few notches.
Sales and Marketing Videos
Murf can also enhance your sales and marketing videos with persuasive and professional voiceovers. You can use these videos to showcase your products, services, or offers and tailor them in multiple languages to advertise to a potentially global audience.
Product Demos
Finally, Murf can help you create informative and engaging product demo videos that showcase your product’s features and benefits in the best possible light.
Key Features of Murf Text to Speech
Apart from enabling users to enhance the quality of their voiceover content with compelling, nuanced, and natural sounding text to speech voices, Murf offers an intuitive voice user interface and the ability to customize and control the voiceover output with features like pitch, speed, emphasis, pause, pronunciation and more.
More than Just a Text to Speech Software
Tired of hearing monotonous, robotic-sounding voiceovers? Not anymore. With Murf, enhance the quality of your content with compelling, nuanced, and natural sounding text to speech that replicate the subtleties of human voice. Fine-tune your voiceover narration and add more character to an AI voice with features such as Emphasis, Pronunciation, Speed, and more! From inviting and conversational to excited and loud to empathetic and authoritative, we have AI voices that span different intonations and emotions. Murf AI text to speech (TTS) supports Arabic, Chinese, Danish, Dutch, English, Finnish, French, German, Hindi, Indonesian, Italian, Japanese, Korean, Norwegian, Portuguese, Romanian, Russian, Spanish, Tamil, and Turkish. Some of these languages also support multiple accents. For example, our English language AI voices support British, Australian, American, and Indian accents. Our Spanish AI voices support Mexican and Spain accents. The TTS online software also offers users the ability to add background audio or music to their content. Murf studio, in fact, comes with a curated selection of royalty-free music in their gallery that the user can choose from to add some music to their video. You can also upload your own audio files or even import from external sources like YouTube, Vimeo, and other video websites. Murf's text to sound has a voice changer feature that lets you upload your existing recording and revamp it with professional AI voice in a single click. You can change your voice to an AI voice in three simple steps: transcribe the audio, choose an AI voice, and regenerate the audio in a new voice. It's as easy as pie.
Additionally, the tool also supports an AI translation feature that enables you to convert your scripts and voiceovers into multiple languages in minutes. With Murf AI Translate, you can convert your projects into 20 different global and regional languages, making them accessible to a broader audience and expanding your reach.
Summing It Up
Murf is a powerful text to speech reader that can help you create engaging and professional voiceovers for your videos, presentations , and so much more.
To put it in short, with Murf, you can:
- Save a ton of money that would have otherwise been spent on voice actors and renting out studio spaces.
- Widen your reach to a global audience with its support for over 120+ unique voices in over 20+ languages.
- Make your content accessible to anyone with visual or specific cognitive disabilities.
So, what are you waiting for? Sign up for a free trial of Murf today!
Murf supports Text to speech in

Important Links
How to create.

Create Conversational Human-like Agents using Voice AI
AI Voice Generator: Most Realistic Text to Speech AI
Generate ai voices, indistinguishable from humans.
Create ultra realistic Text to Speech (TTS) using PlayHT’s AI Voice Generator. Our Voice AI instantly converts text in to natural sounding humanlike voice performances across any language and accent.
Trusted by individuals and teams of all sizes
Our Products - A New Way to Generate Speech

AI Text to Speech
Realistic AI Voice Models for Generating Expressive Speech

AI Voice Cloning
Voice Cloning that Encapsulates Every Accent and Dialect

Voice Generation API
Real Time Voice Cloning and Voice Generation API
Enhance Your Projects with Ultra-Realistic AI Voices
Create engaging voice content with unique AI Voices perfect for your audience
- AI Voiceovers for Videos
- Audio Publishing
- Audio Storytelling
- Conversational AI
- Custom Voice Creation
- IVR Systems
- Translation & Dubbing
- Voice Accessibility

Power your videos with clear, consistent, and professional voiceovers. Perfect for marketing, explainer, product demos, and YouTube videos.

Embed SEO-friendly audio widgets on your websites for accessibility and engagement. Publish your newspaper, article, or blog content in audio format.

Narrate your audiobooks with ultra-realistic voices seamlessly and effectively. Shorten your production time by generating audio in seconds.

Voice your conversational assistants with ultra-realistic, humanlike voices. Create scalable, delightful customer experiences.

Modify your existing voiceovers, or generate a unique custom voice that perfectly fits your brand’s personality for a connected customer experience.

Curate engaging e-learning material with voices capable of pronouncing terminologies and acronyms. Update your training material effortlessly by regenerating audio.

Create and customize your own podcast with unique voices or clone your own voice to scale your podcast production.

Streamline your game’s pre-production with ultra-realistic AI voices. The perfect placeholder for voice acting for your Pre-Vis and Pitch-Vis needs.

Automate your IVR system’s voice responses with AI voices. Revolutionize your customer experience by delivering seamless, personalized interactions every time.

Localize your video and voice content in seconds. Automatically dub your existing audio into other languages. Instantly make your videos accessible to a global audience.

Integrate human-like voices in your assistive voice devices and applications. Provide ultra-realistic voice experiences to enhance accessibility.

Make use of PlayHT’s Voice Generation API to power your conversational chatbot, live streams, and games. Reduce development time and costs.
Generative Voice AI that Captures Any Voice, Language or Accent
Contextually Aware, Emotional and Expressive Text to Speech Models Built with Advanced Voice AI Powered by Research
Generate Conversational, Long-form or Short-form Voice Content With Consistent Quality and Performances.
Secure and Private Voice Generations with Full Commercial and Copyrights
Text to Speech AI Voices
Choose from an expansive library of 800+ natural-sounding AI Voices, coupled with humanlike intonation. Unlock a multilingual experience with 142 languages and accents, enhanced by our cutting-edge Machine Learning technology
Conversational Voices
Perfect for entertainment videos, podcasts and audiobooks
Narrative Voices
Ideal for audiobooks, explainer videos and documentary videos
Explainer Voices
Ideal for entertainment videos, explainer videos, podcasts and audiobooks
Children Voices
Perfect for audiobooks, explainer videos and e-learning
Local Accents
Localize your entertainment videos, adverts and audiobooks
Ideal for gaming, creative videos and ads
Character Voices
Perfect for gaming, creative videos and ads
Training Voices
Suitable for training videos, L&D and E-learning
AI Voices in 100+ Languages
Our extensive AI Voice library spans across all major languages and accents in the world

Multi-Lingual Speech Synthesis
Preserve a speaker’s voice and native accent while translating and dubbing across languages with our Cross-Language Voice Cloning and Multilingual Speech Synthesis
Create any voice, transfer speaking styles and use it to generate speech using our state-of-the-art Voice Cloning feature.
Powerful and Feature-Rich, Online Text-to-Voice Studio

Type, paste or import text and instantly turn it into audio with our online Text to Speech editor. Enhance the audio with speech styles, pronunciations and SSML tags.
907 AI Voices
Choose from a growing library of 907 natural-sounding Text to Speech voices across 142 languages and accents.
Speech Styles
Use expressive emotional speaking styles to make the voices sound more natural and engaging.
Multi-Voice Feature
Create conversations in your audio projects by using different voices in the same audio file.
Custom Pronunciations
Define how specific words are pronounced. Save and re-use those pronunciations when synthesizing speech.
Voice Inflections
Fine-tune the rate, pitch, emphasis and add pauses to create a more suitable voice tone
Preview Mode
Listen and preview a single paragraph or full text before converting it to speech.
Learn How to Use Our AI Voice Technology Effectively

Ethical AI & Safety
We are dedicated to ensuring our Voice AI is used responsibly and safely.
Learn About our AI Voice Generation & Text-to-Speech Technology
What is ai voice, what is an ai voice generator, how long does it take to synthesize text into speech, what customizations can i do with the ai voices, can i use the voices for commercial purpose, do you offer a free version, how real does an ai generated voice sound, how much does ai voice cost, how to generate ai voice, can i generate character ai voices using playht, how does playht generate realistic ai voices, does playht work offline, is there a free ai tool that can convert text to speech, which is the best ai voice generator, how do you get ai voice over, is the use of ai voices legal, what is the ai tool that reads text aloud, what is the most realistic ai voice that sounds human, what is the ai voice generator everyone is using on tiktok, what ai are people using for celebrity voices, how do you make an ai voice sound like someone, get started with the best ai voice generator today.
Convert text into speech.
Here is the list of all the voices that you can use to generate speech
Free Text to Speech Online with Ultra-Realistic AI Voices
Transform your text into lifelike speech. Choose from over 2000 ultra realistic voices in 75+ languages, saving time and cost on voiceover artists.
Credit card not required
Try free text to speech
Create studio-quality voice overs in minutes.
Experience the power of AI voices through our free text-to-speech tool. Capture your audience's attention with our high-quality and natural-sounding AI voices. With a diverse selection of voices available, tailor the tone and style to perfectly align with your brand's identity, ensuring an immersive viewer experience.
Gone are the days of spending countless hours recording voiceovers or hiring expensive voice talent. Our free text-to-speech feature allows you to bring your scripts to life with ease, requiring just a few clicks. Simply input your text, choose your preferred voice, and let our advanced AI technology handle the rest.
Whether you're developing captivating marketing videos, informative tutorials, or educational content, our free text-to-speech tool empowers you to deliver your message with clarity and impact.
Unlock a world of possibilities and streamline your workflow with our script-based editing and extensive media library. Seamlessly blend text and visuals to create compelling videos that captivate your audience from beginning to end.
How to convert text to speech in 4 steps
Input your text.
Start with your text, ideas, blog article, or any type of textual script.

Choose and personalise your AI voice
Select and customize your AI voice from a choice of over 2000 humanlike text-to-speech voices in 75+ languages.

Customize the voiceover
Customize the audio by selecting appropriate emotions, while controlling pitch, rate and pauses in your speech.

Preview and export your audio
Once you are satisfied with the preview, export it.

Try the best Text to Speech AI Voices
📚 audiobooks, 📽 documentary, 👩🏫 e-learning, 💁♀️ explainer video, 📜 narration, 📦 product demo, ☎️ telephone, 📺 television, 🎤 voice assistant, 💬 youtube narration, we have voices for every part of the world, 🇯🇵 japanese, 🇬🇧 british english, 🇧🇷 portuguese, 🇻🇳 vietnamese, sneak peak of the emotions behind our voices, 👧🏻 ana (child) - excited, 👩🏼💼 sara - whispering, 👨🏼 james - angry, 👩🏫 aria - narration, 💁♀️ jane - friendly, 🧔🏾♂️ davis - sad, loved by content creators around the world, 4,000,000 +.
happy content creators, marketers, & educators.
average satisfaction rating from 5,500 + reviews on G2, Capterra, Trustpilot & more.
$95+ million
and 1,750,000 + hours saved in content creation so far.

Nicolai Grut
Digital Product Manager
Excellent Neural Voices + Super Fast App
I love how clean and fast the interface is, using Fliki is fast and snappy and the audio is "rendered" incredibly quickly.

Lisa Batitto
Public Relations Professional
Hoping for something like this!
I'm having a great experience with Fliki so I was excited about this deal. My first project is turning my blog posts into videos, and posting on YouTube/TikTok.
credit card not required
Frequently asked questions
Yes, Fliki offers a tier that allows users to explore text to voice and text to video features without any cost.
You can generate 5 minutes of free audio and video content per month. However, certain advanced features and premium AI capabilities may require a paid subscription.
Fliki stands out from other tools because we combine text to video AI and text to speech AI capabilities to give you an all in one platform for your content creation needs.
Fliki helps you create visually captivating videos with professional-grade voiceovers, all in one place. In addition, we take pride in our exceptional AI Voices and Voice Clones known for their superior quality.
Fliki supports over 75 languages in over 100 dialects.
The AI speech generator offers 1300+ ultra-realistic voices, ensuring that you can create videos with voice overs in your desired language with ease.
No, our text-to-video tool is fully web-based. You only need a device with internet access and a browser preferably Google Chrome, to create, edit, and publish your videos.
In Fliki you can create voiceovers upto 30 mins with the Premium subscription plan.
Yes, Fliki supports emotions! With certain voices marked with the ⚡️ icon, you can add a touch of emotion to your videos. Whether you want to convey anger, cheerfulness, hopefulness, or other emotions, these voices are designed to bring your script to life and evoke the desired response from your audience.
Unlock the power of emotions in your videos with Fliki and create content that truly resonates with your viewers.
Text-to-speech (TTS) technology converts written text into spoken language, allowing users to listen to the content instead of reading it.
Yes, Fliki text to speech is free to use. However, we do have a Fair Usage Policy (FUP) rate limits in place to ensure fair access for all users.
The Fliki text-to-speech service supports 75+ languages and 100+ dialects.
Yes, there is a limit of 200 characters on the free text-to-speech service. However, users have the option to sign up and create up to 5 minutes of text-to-speech content per month for free. Additionally, users can subscribe to our service to create even more content beyond this limit.
Fliki supports voice cloning, allowing you to replicate your own voice or create unique voices for different characters. This feature saves time on recording and adds authenticity to your content.
It also opens up creative possibilities and assists individuals with speech impairments. With Fliki, you can personalize your content, enhance creativity, and overcome limitations with ease.
No, prior experience as a designer or video editor is not required to use Fliki. Our intuitive and user-friendly platform offers capabilities that make it super easy for anyone to create content.
Our Voice Cloning AI, Text to Speech AI, and Text to Video AI, combined with our ready to use templates and 10 million+ rich stock media, allow you to create high-quality videos without any design or video editing expertise.
You can cancel your subscription at anytime by navigating to Account and selecting "Manage billing"
Prices are listed in USD. We accept all major debit and credit cards along with GPay, Apple Pay and local payment wallets in supported countries.
Fliki operates on a subscription system with flexible pricing tiers. Users can access the platform for free or upgrade to a premium plan for advanced features.
The paid subscription includes benefits like ultra realistic AI voices, extended video durations, commercial usage rights, watermark removal, and priority customer support.
Payments can be made through the secure payment gateway provided.
Check out our pricing page for more information.
Stop wasting time, effort and money creating videos
Hours of content you create per month: 4 hour s
To save over 96 hours of effort & $ 4800 per month
No technical skills or software download required.
AI Voice Generator
Generate human-like voices with VEED’s AI text-to-speech technology. The best online AI voice generator

AI text-to-speech: Generate AI voices in multiple languages
Instantly generate lifelike voices, narrate your stories, and breathe life into your presentations using VEED’s AI voice text-to-speech tool. Join the multitudes of content creators choosing VEED and revolutionizing the way the world listens and speaks—with AI. Our advanced artificial intelligence software lets you convert written content to voice automatically, so you can save on video production costs. No need to hire voice actors for your content! Just type or paste a text, and our AI voice generator will read it like it’s their natural language.
How to convert text to speech with AI:
1 upload or record.
Upload your video to VEED or start recording using our free webcam recorder.
2 Convert text to voice or use an AI avatar
Click Audio from the left menu and select Text to Speech. Type or paste your text and click Add to Project. You will see an audio file in the timeline. Or you can go to the Elements tab, select an AI avatar preset, and type your text. Our AI avatar will read your text aloud.
3 Export or keep creating!
Export your video or keep exploring our full range of AI and manual video editing tools to make your video look as engaging as possible.
Learn more about our AI voice text-to-speech tool in this video:

One-click online text reader: text-to-speech AI
Effortlessly transform written content into spoken word in one click with VEED’s powerful artificial intelligence software. Auto-generate voiceovers, narrations, audiobooks , commentaries, and more. No need to record your voice or hire professional voice actors. Save time, money, and effort, and streamline your content creation process with VEED!
Realistic AI voices and animated avatars
Don’t settle for robotic-sounding AI voices. VEED features a wide range of voice profiles with different expressions: happy, excited, whispering, casual, and more. Or choose an AI avatar from our presets and let your animated avatar present in your video. Choose from over 50 avatars with realistic facial expressions and intonations, diverse personalities, styles, and backgrounds.
A full suite of AI tools to help you craft engaging videos
VEED’s AI voice changer is just one of the AI tools included in our robust all-in-one AI video editor . With VEED, you can remove the clutter in your video using our one-click video background remover . Clean your audio instantly, remove filler words, and use our nifty magic cut tool to let our AI splice up a masterpiece from your video clips. Plus, a wide range of video editing tools to help you create the most engaging content!
Frequently Asked Questions
VEED lets you automatically convert text to speech using AI. Just click Text-to-Speech from the Audio menu and type or paste your text. Select a voice profile, and an AI voice will read it aloud for you. You can add the audio file to your project and create a video or download the audio as an MP3 file.
All our voice profiles in our selection sound like real humans—and not like the robotic voiceovers you mostly hear on TikTok. Our AI text-to-speech generator uses real voice actors!
More and more content creators on TikTok are using VEED to automatically generate voiceovers from text. VEED lets you transform text to speech with AI in one click!
Currently, you can add up to 1,000 characters to convert to speech per video project.
Discover more:
- Afrikaans Text to Speech
- AI Voice Over
- Amharic Text to Speech
- Arabic Text to Speech
- Audiobook Maker
- Bangla Text to Speech
- Cantonese Text to Speech
- Chinese Text to Speech
- Convert Articles to Audio
- English Text to Speech
- French Text to Speech
- German Text to Speech
- Hebrew Text to Speech
- Hindi Text to Speech
- Irish Text to Speech
- Italian Text to Speech
- Japanese Text to Speech
- Korean Text to Speech
- Lao Text to Speech
- Malayalam Text to Speech
- Persian Text to Speech
- Realistic Text to Speech
- Russian Text to Speech
- Somali Text to Speech
- Spanish Text to Speech
- Speech in Swahili
- Tamil Text to Speech
- Text Reader
- Text to Audio
- Text to Podcast
- Text to Speech Bulgarian
- Text to Speech Catalan
- Text to Speech Converter
- Text to Speech Croatian
- Text to Speech Czech
- Text to Speech Danish
- Text to Speech Dutch
- Text to Speech Estonian
- Text to Speech Finnish
- Text to Speech Greek
- Text to Speech Gujarati
- Text to Speech Human Voice
- Text to Speech Hungarian
- Text to Speech Khmer
- Text to Speech Latvian
- Text to Speech Lithuanian
- Text to Speech Malay
- Text to Speech Marathi
- Text to Speech MP3
- Text to Speech Norwegian
- Text to Speech Polish
- Text to Speech Portuguese
- Text to Speech Romana
- Text to Speech Serbian
- Text to Speech Slovak
- Text to Speech Slovenian
- Text to Speech Swedish
- Text to Speech Tagalog
- Text to Speech Telugu
- Text to Speech Thai
- Text to Speech Turkish
- Text to Speech Ukrainian
- Text to Speech Voice Changer
- Text to Speech with Emotion
- Text to Talk
- Text to Voice Generator
- Text to Voice Over
- Urdu Text to Speech
- Vietnamese Text to Speech
What they say about VEED
Veed is a great piece of browser software with the best team I've ever seen. Veed allows for subtitling, editing, effect/text encoding, and many more advanced features that other editors just can't compete with. The free version is wonderful, but the Pro version is beyond perfect. Keep in mind that this a browser editor we're talking about and the level of quality that Veed allows is stunning and a complete game changer at worst.
I love using VEED as the speech to subtitles transcription is the most accurate I've seen on the market. It has enabled me to edit my videos in just a few minutes and bring my video content to the next level
Laura Haleydt - Brand Marketing Manager, Carlsberg Importers
The Best & Most Easy to Use Simple Video Editing Software! I had tried tons of other online editors on the market and been disappointed. With VEED I haven't experienced any issues with the videos I create on there. It has everything I need in one place such as the progress bar for my 1-minute clips, auto transcriptions for all my video content, and custom fonts for consistency in my visual branding.
Diana B - Social Media Strategist, Self Employed
More than an AI text-to-speech voice generator
VEED is so much more than an AI voice text-to-speech tool. It’s a complete professional video-editing software that lets you create stunning videos in just minutes. Packed with a multitude of AI tools, VEED is the only software you need to create your most engaging and share-worthy content. Try VEED and start creating amazing videos that you can share with the world now!

LIMITED TIME OFFER: For a limited time, enjoy 50% off on select plans.
AI Voice Generator: Realistic Text to Speech & Voice Cloning
Hyper realistic ai voice generator that .css-1625k06{background:var(--chakra-colors-transparent);white-space:nowrap;background-image:linear-gradient(to right, var(--chakra-colors-blue-600), var(--chakra-colors-skyblue-600));color:transparent;-webkit-background-clip:text;background-clip:text;} captivates your audience.
Join the over 2,000,000 users who love LOVO AI. Our award-winning voice generator and text to speech software is packed with 500+ voices in 100 languages. Create engaging videos with voice for marketing, training, social media, and more!
Start now for free

Chloe Woods
English Female

Sophia Butler

Santa Clause
English Male

Katelyn Harrison

Bryan Lee Jr.

Thomas Coleman
Create and edit videos effortlessly with Genny’s all-in-one voice and video editing platform.
Trusted by professionals & creatives globally
Introducing Genny The best way to add voiceover to video
Experience unparalleled voiceover production with our voice generator and online video editor, featuring professional grade human-like voices and powerful editing tools.
The most natural voices in the world
Surprise your audience with the perfect AI voice in 100+ languages for your content.
Genny is the .css-1ezzeyz{background:linear-gradient(90deg, #2871DE 0%, #27AADC 100%);white-space:nowrap;color:var(--chakra-colors-transparent);-webkit-background-clip:text;background-clip:text;-webkit-background-clip:text;-webkit-text-fill-color:transparent;} ultimate generative AI tool
For all your voiceover and video needs - scripts, ultra-realistic voices, images, editing and more! Genny has all the features you need to create engaging videos with integrated AI features.

Save $$ and time on voiceovers
Using Genny removes the need to spend time and money to record or use expensive equipment to achieve professional voiceovers with our advanced voice generator.
Text To Speech

Sync audio and video seamlessly
Achieve perfect synchronization without sacrificing speed or accuracy. With Genny’s online video editor, you can edit content effortlessly to create engaging high-quality videos.
Online Video Editor

Boost engagement with subtitles
Globalize your content and boost engagement in 20+ languages with our auto subtitle generator. Customize, animate, and transform your video with just a few clicks.
Auto Subtitle Generator

Write scripts 10x faster
Writer's block is everyone's nightmare. Genny's AI writer can help you get started on your script quickly by generating professionally written content in a lightening fast.

Create unique voices in minutes
Genny’s voice cloning lets you instantly create custom voices with just one minute of audio. Give your brand a unique voice that sets your content apart from the crowd.
Voice Cloning

Generate royalty-free images
No more spending hours searching the web for the perfect stock image. Generate HD royalty-free images and add them to your videos in seconds with Genny’s AI art generator.
AI Art Generator
.css-bd7824{background:linear-gradient(90deg, #2E94FF 0%, #408CFF 32.81%, #3DB5FF 71.35%, #2ED1EA 100%);white-space:nowrap;color:var(--chakra-colors-transparent);-webkit-background-clip:text;background-clip:text;-webkit-background-clip:text;-webkit-text-fill-color:transparent;} Collaborate with your team
Drive efficiency and collaborate creatively with Genny teams and keep your projects safely secured with our cloud storage so you and your team can access them at any time!
Learn About Genny Teams
.css-1pdu0yo{background:var(--chakra-colors-transparent);white-space:nowrap;background-image:linear-gradient(90deg, #2E94FF 0%, #408CFF 32.81%, #3DB5FF 71.35%, #2ED1EA 100%);color:transparent;-webkit-background-clip:text;background-clip:text;webkit-background-clip:text;webkit-text-fill-color:transparent;} Versatile API made for developers
With our easy to use API, you now have the power to use the most advanced AI voices in the world in your own app or service! Get started in as little as 5 lines of code.
LOVO Open API
AI Voice Generator for any use case
Unlock your creative potential
Try Genny for free
Create a free voiceover
Start .css-l9o03z{background:var(--chakra-colors-transparent);white-space:nowrap;color:var(--chakra-colors-blue-600);} saving 90% of your time and budget today!
See pricing
No Credit Card required
14-day trial of pro
You might find an answer faster here
If you cannot find an answer, email [email protected] for help.
What happens if I hit my credit limit?
What does "Voice Generation Hours" Mean?
How is LOVO different from other TTS?
Can I use LOVO for Youtube videos?
Do I own the rights to content created?
What is an AI voice?
Which languages do you support?
Which emotions can LOVO express?
Do you have an API?
Do you have an enterprise plan?
Can I cancel any time?
What is an AI voice generator?
Check out latest articles on our blog

6 Benefits of Real-Time Voice Cloning

Effective Text To Speech Tools For Instructional Design

Most Popular AI Voiceover Apps For TikTok

Best AI tools for businesses and marketers
Voice generators - perfect for content creation
Scale content without scaling costs or resources.
With AI now more accessible than ever, tools like text-to-speech generators are the perfect assistant for content creation. These tools save you time and money by removing the need for expensive equipment or time-consuming tasks such as recording and editing while providing high-quality audio with realistic human voices.
Produce professional-grade content
At LOVO, our team has focused on creating Genny, the most advanced voice generator that produces high-quality voiceovers to elevate your video and audio projects. Complete the final stages of your project with Genny by generating your voiceover and seamlessly syncing it with your video. Then, before exporting your video, add all the finishing touches for a truly professional look, such as subtitles, images, logos, and video clips.
Create with ease and speed
Genny is designed to allow anyone to get started immediately - no downloading software or complicated onboarding or learning is required. Simply sign in with your web browser and you are good to go! Our intuitive and easy-to-use UI makes it a breeze for anyone who needs to create content up and running in minutes. This means you can focus on what matters most - engaging and delivering your message to your audience.
AI Realistic Voice Generator and Text-to-Speech

Free AI Voice Generator
Use Deepgram's AI voice generator to produce human speech from text. AI matches text with correct pronunciation for natural, high-quality audio.
AI Voice Generation
Discover the Unparalleled Clarity and Versatility of Deepgram's AI Voice Generator
We harness the power of advanced artificial intelligence to bring you a state-of-the-art AI voice generator designed to meet all your audio creation needs. Whether you're a content creator, marketer, educator, or developer, our platform offers an incredibly realistic and customizable voice generation solution.
Human Voice Generation
Our AI voice generator is engineered to produce voices that are indistinguishable from real human speech. With a vast library of voices across different genders, ages, and accents, Deepgram empowers you to find the perfect voice for your project.
Low-latency Text to Speech
Deepgram's voice generator is one of the fastest on the market. We design our AI models to produce high-quality voices
How It Works
Choose Your Voice : Select from our diverse library of high-quality, natural-sounding AI voices.
Generate: Enter your text, generate your voiceover in seconds.
Download: Once you have you AI generated speech, easily download your audio file.
AI Voice Generator Use Cases
E-Learning and Educational Content : Create engaging and informative educational materials that cater to learners of all types.
Marketing and Advertising : Enhance your marketing materials with high-quality voiceovers that grab attention.
Audiobooks and Podcasts : Produce audiobooks and podcasts efficiently, with voices that keep your audience engaged.
Accessibility : Make your content more accessible with voiceovers that can be easily understood by everyone, including those with visual impairments or reading difficulties.
- Latest News
- Artificial Intelligence
- Big Data and Analytics
- Cybersecurity
- Applications
- IT Management
- Small Business
- Development
- PC Hardware
- Search Engines
- Virtualization
5 Best AI Voice Generators: AI Text-To-Speech in 2024
In search of the best AI voice generator? Discover the leading AI text-to-speech platforms available in 2024.

eWEEK content and product recommendations are editorially independent. We may make money when you click on links to our partners. Learn More .
An AI voice generator is a specialized type of generative AI technology that enables users to create new voices or manipulate existing vocal audio with no audio engineering expertise. Instead, they simply insert text, or some other media, with requested parameters to direct the vocal generator to create a relevant voice or voice product.
In this guide, we’ll take a closer look at the five best AI voice generators available today, but first, here’s a glance at where each of these tools differentiates itself the most:
- Murf : Best for Multichannel Content Creation
- PlayHT : Best for AI Voice Agents
- LOVO : Best Combined AI Voice and Video Platform
- ElevenLabs : Best for Enterprise AI Scalability
- Speechify : Best for AI Narration
Featured Partners: AI Software

Top AI Voice Generator Software Comparison
In addition to text-to-speech and voice cloning capabilities, we’ll primarily compare these tools across these key criteria for generative AI voice generation software:
TABLE OF CONTENTS
Murf: Best for Multichannel Content Creation
Murf is one of the top generative AI voice tools available to both casual and business users, providing them with an accessible user interface and a range of scalable voice generation and editing features. Its primary focus areas include text-to-speech content generation, no-code voice editing, AI-powered translation, AI voice deployment to apps via API, voice cloning, and an AI dubbing feature that is currently in beta for more than 20 languages.
Many business users select this tool for its wide range of collaborative features, its enterprise-level security and compliance expertise and features, its vocal quality and variety, and its comprehensive support for various enterprise use cases.
In addition to its easy-to-use enterprise integrations with various creative and product development tools, Murf also offers free creative guides and resources on the following topics: e-learning, explainer videos, YouTube videos, Spotify ads, corporate videos, advertisements, audiobooks, podcasts, video games, training videos, presentations, product demos, IVR voices, animation character voices, and documentaries.
Pros and Cons
- Creator Lite: $23 per month billed annually, or $29 billed monthly for one editor to access up to five projects and 24 hours per year of voice generation.
- Creator Plus: $39 per month billed annually, or $49 billed monthly for one editor to access up to 30 projects and four hours per month of voice generation (up to 48 hours per year).
- Business Lite: $79 per month billed annually, or $99 billed monthly for up to three editors and five viewers to access up to 50 projects and eight hours per month of voice generation (up to 96 hours per year). Free trial access to this plan’s features is available for one editor, up to two projects, and up to 10 minutes of voice generation.
- Business Plus: $159 per month billed annually, or $199 billed monthly for up to three editors and five viewers to access up to 200 projects and 20 hours per month of voice generation (up to 240 hours per year). Free trial access to this plan’s features is available for one editor, up to two projects, and up to 10 minutes of voice generation.
- Enterprise: Pricing information available upon request. This plan is designed for more than five editors and unlimited viewers to create custom projects with unlimited voice generation access.
- Murf API: Pricing information available upon request.
- AI Translation: Add-on for Enterprise and Business plan users. Pricing information available upon request.
- Integrations: Integrations are available for Canva, Google Slides, Adobe Audition, Adobe Captivate and Captivate Classic, and HTML Embed Code. Users can also download Murf Voices Installer to directly incorporate Murf voices into Windows apps.
- Vocal library: More than 200 voices, styles, and tonalities in more than 20 languages are available to users.
- Team collaboration and project organization: Folders, sub-folders, shareable links, and private folders and projects all support controlled collaboration.
- Enterprise compliance: Depending on the plan selected, users can benefit from GDPR, SOC2, and EU compliance support as well as SSO, access logs, custom contracts, and security reviews.
- Visual voice editing: Easy-to-use buttons and clickability to adjust pitch, emphasis, speed, interjections, pauses, pronunciation, and more.
To see a list of the leading generative AI apps, read our guide: Top 20 Generative AI Tools and Apps 2024
PlayHT: Best for AI Voice Agents
PlayHT has been a favorite artificial intelligence voice generation tool for a few years now, extending to users a highly accessible and scalable tool for multilingual AI voice generation. Compared to other AI voice generation tools, PlayHT first and foremost sets itself apart with its range of voice and language options: All plans, including the free plan, can access 907 voices and 142 different languages and accents. The tool also comes with limited instant voice clones and will soon offer high-fidelity clones to enterprise users.
Beyond its more conventional AI voice features and tools, PlayHT has set its sights on a very specific enterprise use case: AI voice agents. With its new feature set, Play Agents, users can create their own AI voice agent avatars with specific parameters and prompts about how they should greet and respond to user interactions. The tool also comes with several prebuilt agent templates, API-driven agent training and tracking for developers, and a simple table for tracking agent conversation history.
Pricing for PlayHT depends on whether you select PlayHT Studio, AI voice agents, or the API subscription plans:
PlayHT Studio
- Free Plan: $0 for non-commercial access to all voices and languages, one instant voice clone, and up to 12,500 characters.
- Creator: $31.20 per month billed annually, or $39 billed monthly.
- Unlimited: Typically $99 per month, billed annually or monthly. A special discount is currently running for the annual plan for $29 per month.
- Enterprise: Custom pricing.
AI Voice Agents
- Free Plan: $0 for non-commercial access to 30 minutes of agent content creation.
- Pro: $20 billed monthly plus $0.05 per each minute used over 400 minutes.
- Business: $99 billed monthly plus $0.05 per each minute used over 2,000 minutes.
- Growth: $499 billed monthly plus $0.05 per each minute used over 10,000 minutes.
- Enterprise: Custom pricing for unlimited limits and other advanced features.
- Hacker: $5 billed monthly plus $0.25 per every additional 1,000 characters over 25,000 characters per month.
- Startup: $299 billed monthly plus $0.20 per every additional 1,000 characters over 1.5 million characters per month.
- Growth: $999 billed monthly plus $0.10 per every additional 1,000 characters over 10 million characters per month.
- Business: Custom pricing for large volume discounts and custom rate limits.
- Multilingual voice library: PlayHT’s voice library includes 907 text-to-speech voices and 142 languages and accents.
- Pronunciation library: This feature allows users to define specific pronunciations and save these rules for future projects.
- Multi-voice content creation: A single audio file and project can include multiple voices, which is useful for AI conversational projects .
- Play Agents feature: Custom AI voice agents and preconfigured agent templates for healthcare, hotels, restaurants, front desks, and e-commerce can be used to create more intelligent customer service AI chatbots/agents.
- Real-time streaming API: Character-based pricing for API access, which scales up to include dedicated enterprise clusters and other advanced features.
For more information about generative AI providers, read our in-depth guide: Generative AI Companies: Top 20 Leaders
LOVO: Best Combined AI Voice and Video Platform
LOVO offers its users a suite of useful AI features that not only support AI voice generation and voiceover initiatives but also other creative tasks related to video and image creation . LOVO’s flagship platform, Genny, is a user-friendly tool that uses its own generative AI technologies to enable video editing, subtitle generation, voice generation, and voice cloning tasks. With the help of ChatGPT and Stable Diffusion models , users can also generate shortform and longform text and AI art projects at no additional cost and with no third-party tooling requirements.
Users most appreciate that this tool supports multiple languages and unique vocal tones, is easy to use, and offers high-quality voice outputs compared to many competitors. Many users also appreciate that they can purchase affordable, lifetime deals through AppSumo.
Pricing for LOVO depends on whether you select an All in One or Subtitles subscription plan:
- Basic: $24 per month billed annually, or $29 per user billed monthly. Limited to one user per plan subscription.
- Pro: $48 per user per month, billed annually, with a 50% discount for the first year, or $48 per user billed monthly. A 14-day free trial is also available for this plan’s features.
- Pro +: $149 per user per month, billed annually, with a 50% discount for the first year, or $149 per user billed monthly.
- Enterprise: Pricing information available upon request.
- Free: $0 for limited features.
- Subtitles: $12 per user per month, billed annually, or $18 per user billed monthly.
- Genny: All-in-one video creation platform with voice generation, voice cloning, subtitle generation, art generation, text generation, and video editing capabilities.
- Multilingual voice library: The text-to-speech library includes more than 500 voices and more than 100 languages. LOVO also caters voices to 30 different emotions.
- Built-in voice recorder: For voice cloning, users can record their voices directly within the LOVO tool. They also have the option to upload a prerecorded clip, if preferred.
- Simple Mode: For shorter voice generation and voiceover projects (between 2,000 and 5,000 characters), users can work with the lightweight, faster Simple Mode format.
- API access: LOVO voice application development features are available in all plans.
For an in-depth comparison of two leading AI art generators, see our guide: Midjourney vs. Dall-E: Best AI Image Generator 2024
ElevenLabs: Best for Enterprise AI Scalability
ElevenLabs is an artificial intelligence research firm that has developed comprehensive AI voice technologies for text to speech, speech to speech, dubbing, voice cloning, and multilingual content generation. Users frequently compliment ElevenLabs on the quality of the voice products it produces, noting that the vocal tone and overall quality feel more realistic than what most other competitors are producing.
ElevenLabs is one of the most business-friendly AI voice tools on the market today, offering advanced features at different price points. Its free plan is fairly comprehensive, including access to 29 languages and thousands of voices, automated dubbing, custom voices, and API. Six different pricing tiers are available, with the top tier offering unique enterprise draws like custom terms and SSO, unlimited concurrency, and volume-based discounts.
Additionally, ElevenLabs offers a grant program designed for the unique needs of business startups. Eligible startup applicants who can convince the vendor of their longterm strategy and growth potential will be given three months of free access with 11 million characters per month and enterprise features.
- Free: $0 for 10,000 monthly characters, or approximately 10 minutes of audio per month.
- Starter: $50 per year, billed annually, with the first two months free, or $5 billed monthly with 80% off the first month.
- Creator: $220 per year, billed annually, with the first two months free, or $22 billed monthly with 50% off the first month.
- Pro: $990 per year, billed annually, with the first two months free, or $99 billed monthly.
- Scale: $3,300 per year, billed annually, with the first two months free, or $330 billed monthly.
- Custom Enterprise Plans: Pricing information available upon request.
- Precision voice tuning: With this drag-and-drop editing feature, users can adjust vocal stability and variability, vocal clarity, and style exaggerations on a scale.
- Multilingual voice library: More than 1,000 voices across 29 different languages are available for text-to-speech content generation.
- Speech to speech: Users can upload an audio file or record their voice for voice changing, custom voices, and voice cloning capabilities.
- Dubbing Studio: Video translation and dubbing available in 29 different languages. Speaker. Studio interface allows users to granularly adjust specs.
- AI Speech Classifier: This unique feature allows users to upload an audio file so the vendor can evaluate if the clip was created by ElevenLabs AI.
Speechify: Best for AI Narration
Speechify is an AI voice solution that specializes in text-to-speech technology for mobile platforms and more casual use cases, like audiobook narration. With the Speechify AI platform, users can select from a wide variety of AI voices, including voices that mimic celebrities like Gwyneth Paltrow and Snoop Dogg. All of this is available in various mobile and online locations, including through browser extensions that are accessible and favorably reviewed by users.
While Speechify’s core audience is recreational users, students, and other more casual users who want a convenient solution for reading off text in various formats, the platform offers some key enterprise AI usability features through its Voice Over Studio for Business. With this suite of Speechify solutions, business users can benefit from unlimited video and voice downloads, commercial rights, collaborative project management features, dozens of voices, and enterprise security and compliance features.
Pricing for Speechify all depends on how you want to use the tool. Here are some of the options you have as a Speechify user:
- Speechify Limited (text to speech): $0 for 10 standard reading voices and limited text-to-speech features.
- Speechify Premium: $139 per year for advanced text-to-speech features and capabilities.
- Speechify Studio Free: $0 for access to basic AI voice and video features with no downloads.
- Speechify Studio Basic: $24 per user per month, billed annually, or $69 per user billed monthly.
- Speechify Studio Professional: $32.08 per user per month, billed annually, or $99 per user billed monthly.
- Speechify Studio Enterprise: Pricing information available upon request.
- Text to Speech API: Users can join the waitlist.
- Speechify Audiobooks: $9.99 per month, or $120 billed annually.
Custom pricing and discounts may also be available for business teams and educational organizations.
- Browser extensions and app: Users can access Speechify through the Chrome extension, Edge Add-on, Android, iOS, and PDF readers like Adobe Acrobat.
- Multilingual voice library: More than 100 voices in over 40 languages are available for enterprise users.
- AI dubbing: Dubbing is available in multiple languages, with the ability to adjust voice, tone, and speed.
- AI video generator: Users can combine Speechify’s AI voiceovers with avatars to create AI videos.
- Various upload and download formats: Content can be uploaded in .txt, .docx, .srt, and YouTube URL formats; Speechify projects can be downloaded as video, audio, or text.
Key Features of AI Voice Generator Software
AI voice generator software typically includes features that help users transform text, existing audio, and other media into voices with adjustable qualities to meet their needs. Additionally, many of these generative AI tools come with features to make enterprise-level collaboration and content creation run more smoothly. In general, expect to find the following features in AI voice generators:
Text to Speech
Text to speech (TTS) is a type of AI technology that changes written text into spoken audio. Most AI voice generator software allows users to upload text of different lengths and in different languages in order to generate a vocal version of the same content.
Voice Cloning
With voice cloning, AI technology can capture the content, tonality, speed, and other characteristics of a person’s voice in a recording and use that information to create a faithful replica or clone of that unique voice. With this capability, users can generate entirely new content and recordings that sound like they were spoken by that person.
Custom Voices or Voice Changing
On some AI voice platforms, if you submit your own voice clip or directly record your voice into the app, you can then change that voice into a completely different character, adjusting the tone, accent, mood, and other features. Many users want this feature for creative projects like video game development.
Multilingual Voice Library
Most generative AI voice tools give users access to a diverse, multilingual library of predeveloped voice models. Through extensive training, these TTS models are prepared to create voice transcripts and recordings that accurately adhere to each language’s specific pronunciations, tonalities, pauses, and other characteristics of that language’s speech patterns.
Dubbing and Translation
Taking TTS a step further, dubbing and translation with AI make the effort to translate an existing text or voice recording into a different spoken language. For dubbing specifically, existing recordings — often movies, commercials, and other visual media — receive a new vocal overlay, typically dubbed in a different language by an AI model.
APIs and Third-Party Integrations
With the help of APIs and built-in third-party integrations, users can more easily add AI voice creation and editing capabilities directly into their app and product development workflows. A growing number of AI voice tools are adding relevant third-party integrations to creative platforms as well as social and distribution channels.
To learn about today’s top generative AI tools for the video market, see our guide: 5 Best AI Video Generators
How We Evaluated AI Voice Generators
To evaluate these AI voice generators and other leaders in this AI market sector, we looked at each tool’s standard and unique features while focusing on the following criteria. Each criterion is weighted based on its importance to the typical business user:
Vocal Quality – 30%
Needless to say, vocal quality, fidelity, and usability are the most important aspects of an AI voice generator. Within this criterion, we evaluated each tool based on the realistic quality of AI voices, the accuracy of AI voice generations, the availability of different voices and languages, and the ability to granularly edit generated voice products. We also considered whether a tool offered users the ability to customize or record their own voices and voiceovers.
Enterprise Scalability – 30%
Enterprise scalability is hugely important for AI voice generators since many companies invest in this type of platform to create global marketing, sales, and product content at scale.
For enterprise scalability, we assessed each tool’s global library of voices and dialects, its adherence to enterprise security and compliance standards, features that go beyond voice content production, collaboration and sharing capabilities, integrations with relevant third-party tools and platforms, and the scalability of APIs. We placed a special emphasis on each tool’s enterprise-level plans and the additional features that are available at this level.
Pricing – 20%
Pricing is a crucial factor when considering AI voice technology, as the cost of these tools varies widely for the features you get at that price point. As part of this evaluation, we identified whether each tool offered a free plan option, we compared how prices scale from package to package, we considered how many price points were available to users, and we looked at the value of the features added to each tier, particularly enterprise-level tiers.
Ease of Use – 20%
AI voice tools are supposed to make content creation a simpler task; for this reason, ease of use and accessibility were also important factors in how we judged each of these tools. We looked at each tool’s no-code features, the user-friendliness of voice editing tools, the quality of customer support at each subscription tier, and the availability of self-service resources and community forums for getting started and troubleshooting.
AI Voice Generators: Frequently Asked Questions (FAQs)
Learn more about AI voice generator technology and the top solutions available through these frequently asked questions:
What is the best AI voice generator?
The best AI voice generator will depend on your particular needs and project plans, but Murf is consistently a top choice for its flexibility, with a wide range of general use cases.
Is there a free AI voice generator?
Yes, several AI voice generators are free or are available in free, limited versions.
What is the best free AI voice generator?
The best free AI voice generator options will vary based on your exact requirements. ElevenLabs is the best free solution for users who require API access and interoperability with other resources, while Speechify is the most generous for users who don’t require downloads or more complex features.
Bottom Line: AI Voice Generators Are Affordable and Customizable
AI voice technology has grown in popularity for content creators of all backgrounds and budgets. These type of generative AI tools enable creative scalability for videos, podcasts, audiobooks, customer service interactions, and a slew of other enterprise use cases that require consistent and original voice content. What’s more, this technology is frequently customizable and available in affordable plans, meaning users of all stripes can try out these tools to figure out their potential for their projects.
If you’re not sure which of the AI voice tools in this guide is the best fit for your organization, take some time to test out the free plans or trials that are available for each tool. You’ll quickly discover if the software meets your particular needs, if it’s user friendly, and if it has the features necessary to keep up with your organization’s security and compliance requirements.
For a full portrait of the AI vendors serving a wide array of business needs, read our in-depth guide: 150+ Top AI Companies 2024
Get the Free Newsletter!
Subscribe to Daily Tech Insider for top news, trends & analysis
MOST POPULAR ARTICLES
10 best artificial intelligence (ai) 3d generators, ringcentral expands its collaboration platform, 8 best ai data analytics software &..., zeus kerravala on networking: multicloud, 5g, and..., datadog president amit agarwal on trends in....

AI Powered Text to Speech Converter
Create realistic voices for any text in seconds by using over 200+ realistic voices across 50+ languages & dialects.
Try us with a 5K characters free trial
No use cases were published yet
Choose your perfect voice.
With over 200+ voices in 50+ languages to choose from and a platform that is trained on your use cases and dialogues, our technology delivers natural-sounding speech that is unmatched in the industry.
Our platform offers both male and female voices with diverse accents such as American, British, Australian, and more.
Neural Voices
Experience the power of AI-powered text to speech with our neural voices. Enjoy natural and lifelike voices that will bring your projects to life, powered by the latest neural network technology.
With our neural voices, you can create engaging audio content in multiple languages for any application - from gaming to educational materials.
Various Audio Formats
Our text to speech service offers a wide range of audio formats, making it easy to access and use regardless of your device or platform.
We support variety of different audio formats, including MP3, WAV, OGG and WEBM.
With just three clicks, you can instantly generate a 100% human-sounding voiceover from any written content.
Simply copy and paste the text into our platform, select the voice of your choice, and click the generate button. Within seconds, you will have a high-quality voiceover that is ready to use.
Download & Share
We understand the importance of being able to download and share your audio content easily and quickly.
Once you've created your audio content, our easy-to-use download and sharing features make it simple to distribute your content to colleagues, clients, or friends via email, social media, or other channels.
Full Set of SSML Features
We offer a full set of SSML (Speech Synthesis Markup Language) features that allow you to customize the way your text is spoken and create a more engaging and natural-sounding voiceover.
Our SSML features include prosody, emphasis, pauses, pitch, and more, which enable you to add nuance, emotion, and tone to your text and create a more expressive and engaging voiceover.
Empower your content with over 200+ voices
Get access to over 200+ voices in 50+ languages and dialects that are constantly updated and improved for a natural and lifelike voice synthesis experience.
Browse the full list of supported voices.
24/7 Customer Support
We know our products inside and out, and we’re always happy to talk you through your issues. You can ask us just about anything.

March 3, 2023

Text to speech
An AI Speech feature that converts text to lifelike speech.
Bring your apps to life with natural-sounding voices
Build apps and services that speak naturally. Differentiate your brand with a customized, realistic voice generator, and access voices with different speaking styles and emotional tones to fit your use case—from text readers and talkers to customer support chatbots.
Lifelike synthesized speech
Enable fluid, natural-sounding text to speech that matches the intonation and emotion of human voices.
Customizable text-talker voices
Create a unique AI voice generator that reflects your brand's identity.
Fine-grained text-to-talk audio controls
Tune voice output for your scenarios by easily adjusting rate, pitch, pronunciation, pauses, and more.
Flexible deployment
Run Text to Speech anywhere—in the cloud, on-premises, or at the edge in containers.
Tailor your speech output
Fine-tune synthesized speech audio to fit your scenario. Define lexicons and control speech parameters such as pronunciation, pitch, rate, pauses, and intonation with Speech Synthesis Markup Language (SSML) or with the audio content creation tool .
Deploy Text to Speech anywhere, from the cloud to the edge
Run Text to Speech wherever your data resides. Build lifelike speech synthesis into applications optimized for both robust cloud capabilities and edge locality using containers .
Build a custom voice for your brand
Differentiate your brand with a unique custom voice . Develop a highly realistic voice for more natural conversational interfaces using the Custom Neural Voice capability, starting with 30 minutes of audio.
Fuel App Innovation with Cloud AI Services
Learn five key ways your organization can get started with AI to realize value quickly.
Comprehensive privacy and security
Documentation.
AI Speech, part of Azure AI Services, is certified by SOC, FedRAMP, PCI DSS, HIPAA, HITECH, and ISO.
View and delete your custom voice data and synthesized speech models at any time. Your data is encrypted while it’s in storage.
Your data remains yours. Your text data isn't stored during data processing or audio voice generation.
Backed by Azure infrastructure, AI Speech offers enterprise-grade security, availability, compliance, and manageability.
Comprehensive security and compliance, built in
Microsoft invests more than $1 billion annually on cybersecurity research and development.

We employ more than 3,500 security experts who are dedicated to data security and privacy.

Azure has more certifications than any other cloud provider. View the comprehensive list .

Flexible pricing gives you the power and control you need
Pay only for what you use, with no upfront costs. With Text to Speech, you pay as you go based on the number of characters you convert to audio.
Get started with an Azure free account

After your credit, move to pay as you go to keep building with the same free services. Pay only if you use more than your free monthly amounts.

Guidelines for building responsible synthetic voices

Learn about responsible deployment
Synthetic voices must be designed to earn the trust of others. Learn the principles of building synthesized voices that create confidence in your company and services.

Obtain consent from voice talent
Help voice talent understand how neural text-to-speech (TTS) works and get information on recommended use cases.

Be transparent
Transparency is foundational to responsible use of computer voice generators and synthetic voices. Help ensure that users understand when they’re hearing a synthetic voice and that voice talent is aware of how their voice will be used. Learn more with our disclosure design guidelines.
Documentation and resources
Get started.
Read the documentation
Take the Microsoft Learn course
Get started with a 30-day learning journey
Explore code samples
Check out the sample code
See customization resources
Customize your speech solution with Speech studio . No code required.
Start building with AI Services
Voice Generator
This web app allows you to generate voice audio from text - no login needed, and it's completely free! It uses your browser's built-in voice synthesis technology, and so the voices will differ depending on the browser that you're using. You can download the audio as a file, but note that the downloaded voices may be different to your browser's voices because they are downloaded from an external text-to-speech server. If you don't like the externally-downloaded voice, you can use a recording app on your device to record the "system" or "internal" sound while you're playing the generated voice audio.
Want more voices? You can download the generated audio and then use voicechanger.io to add effects to the voice. For example, you can make the voice sound more robotic, or like a giant ogre, or an evil demon. You can even use it to reverse the generated audio, randomly distort the speed of the voice throughout the audio, add a scary ghost effect, or add an "anonymous hacker" effect to it.
Note: If the list of available text-to-speech voices is small, or all the voices sound the same, then you may need to install text-to-speech voices on your device. Many operating systems (including some versions of Android, for example) only come with one voice by default, and the others need to be downloaded in your device's settings. If you don't know how to install more voices, and you can't find a tutorial online, you can try downloading the audio with the download button instead. As mentioned above, the downloaded audio uses external voices which may be different to your device's local ones.
You're free to use the generated voices for any purpose - no attribution needed. You could use this website as a free voice over generator for narrating your videos in cases where don't want to use your real voice. You can also adjust the pitch of the voice to make it sound younger/older, and you can even adjust the rate/speed of the generated speech, so you can create a fast-talking high-pitched chipmunk voice if you want to.
Note: If you have offline-compatible voices installed on your device (check your system Text-To-Speech settings), then this web app works offline! Find the "add to homescreen" or "install" button in your browser to add a shortcut to this app in your home screen. And note that if you don't have an internet connection, or if for some reason the voice audio download isn't working for you, you can also use a recording app that records your devices "internal" or "system" sound.
Got some feedback? You can share it with me here .
If you like this project check out these: AI Chat , AI Anime Generator , AI Image Generator , and AI Story Generator .
5 of the best AI voice generators
Suswati Basu is a multilingual, award-winning editor and the founder of the intersectional literature channel, How To Be Books. She was shortlisted for the Guardian…
Sam Shedden is an experienced journalist and editor with over a decade of experience in online news. A seasoned technology writer and content strategist, he…

Across the board, users want a piece of the pie when it comes to AI. It’s hardly surprising that there has been an influx of creative ways to test its abilities in the form of generators. Whether it’s music makers like Suno or video creators such as Sora , there are now a multitude of ways to play around with these new technologies. The next iteration of these gadgets includes voice generators, which can assist with tasks such as text-to-speech and voice cloning.
What are AI voice generators and how do they work?
AI voice generator software transforms written text into voices that closely resemble human speech. It can be customized for various speech styles, ages, genders, and accents, and can also translate text into multiple languages. An increasing number of people are using this technology to narrate YouTube videos, podcasts, and video games. There have even been reports of it being used to narrate audiobooks.
These generators rely on deep learning algorithms, which are a branch of artificial intelligence that improves through analyzing large volumes of data. The way it works involves first training on a large dataset of voice recordings. Through this training, the algorithms learn to recognize speech patterns, such as intonation, rhythm, and accents, from these recordings. The quality and variety of the data used to train the generator influence how well it can create different and precise voices.
After the training phase, the AI uses text-to-speech (TTS) technology to convert written text into spoken words. This process starts with the AI breaking down the input text into its phonetic elements, and then synthesizing these components to construct complete words and sentences.
To make it more realistic, some sophisticated AI voice generators integrate Natural Language Processing (NLP) techniques. NLP enables the AI to grasp and process the subtleties of human language, allowing it to adjust its output for linguistic nuances such as sarcasm, questions, or excitement. This makes the synthesized speech sound more natural and human. It’s expected to improve as these technologies evolve.
What are the best AI voice generators?
Using the pangram – a sentence that contains all the letters of the alphabet – we tested out the different AI voice generators out there:
“The quick brown fox jumps over the lazy dog.”

ElevenLabs is one of the most notable firms in this area of AI. Its free online software provides users access to 27 different voice options, as well as the ability to translate into 29 different languages, including Chinese, Hindi, and Russian. The software is free and users are able to download on the free version. Users should be cautious when translating from English to other languages, as the translations are not always accurate and can significantly alter the intended meaning.
The maximum number of characters that can be generated in a single request on the platform is 2,500 for users who are not subscribed and 5,000 for those who are subscribed. There are also five tiers, including the free membership, with prices ranging from $1 to $330 per month, offering between 10 minutes and 40 hours of audio. The audio quality varies across the different packages, as does the ability to distribute commercially.
The UK-based company ElevenLabs got unicorn status in January 2024 after securing an $80 million Series B funding round, making it a serious player in the AI voice generation game. It also announced that it would be launching AI sound effects .
Mati Staniszewski, CEO and co-founder of ElevenLabs, said their goal is “to transform how we interact with content by breaking down language and communication barriers.” He added that the London-based voice cloning company hopes to build cutting-edge technology to make content accessible across languages and voices “to enable everyone to connect with information and stories that matter.”
The company has faced backlash in the past after it was blamed for deepfake robocalls of Joe Biden to New Hampshire voters.
VEED.IO is generally known as video editing software – it’s even named after it. However, it has recently introduced realistic text-to-speech AI voiceovers as well. Users can choose from a wide range of AI voices in multiple languages, but they must sign up for the service on a free plan. Unlike ElevenLabs, there are discrepancies when emphasizing certain words within sentences. Currently, up to 1,000 characters can be added per video project. Users can also translate their text into 60 different languages.
While there is a free option, the products come with watermarks. The paid tiers are for its video component, which ranges from £10 to £49 per month billed annually. The audio part of the software is free.
On their blog, VEED vice president of marketing Leila Woodington said : “The less time you have to spend on the routine parts of production, the more time you have to think about the storytelling and the craft.”
Murf.AI offers 10 minutes in its free trial, providing access to over 120 voices in its studio. Theoretically, depending on the selected voice, it allows users to alter the mood of the voice to include angry, conversational, inspirational, and sad tones. The availability of UK regional accents was particularly exciting to see. However, while the voice sounds somewhat robotic, the accents on certain words are accurate. Users are not able to download the recordings for free.
A cool feature offered by Murf , which isn’t provided by any other text-to-speech converter, is that it allows users to change their voice while recording. The voiceovers can be personalized based on pitch, speed, and volume. It even offers a tool to create Spotify ads.
It offers three tiers, including its free plan, with prices ranging from $23 to $79 per month when billed annually. Only the most expensive membership allows people to change their voices and integrate their works with Google Slides. However, both paid plans permit users to utilize their recordings for commercial purposes.
Like VEED.IO and Murf.AI, people have to sign up for PlayHT . What’s interesting about PlayHT is that each sample is unique and can be downloaded. The recording sounds fairly natural, though a little morose, and the software provides around 12,400 free characters.
It also has a voice cloning feature, integrations into WordPress, as well as custom pronunciations. However, this is not available on the free tier. The two paid plans are both billed yearly and are $31.20 and $99.
A YouTuber was reported to have used PlayHT to modify the AI-generated voice on a Pokédex to make it have the sound and cadence of the actual device in the show.
LOVO also requires registering and paying for its service before recordings can be downloaded, however, users can test out 180 characters without signing up. One of Lovo Studio’s standout features is its ability to generate natural-sounding voices in various languages. Whether users need English voiceovers or voices in different languages, LOVO Studio’s AI technology delivers voices that are remarkably human-like and emulate human speech effectively.
LOVO Studio provides a range of plans catering to different needs, starting with a free plan providing basic functionality. This allows users to explore the platform and its capabilities without any cost. The Pro plan is available for $48 per month for those seeking more features and customization options. The platform also offers premium voices for users looking for even higher quality and more distinct options, for $75 per month billed annually.
Featured image: DALL.E / Canva
About ReadWrite’s Editorial Process
The ReadWrite Editorial policy involves closely monitoring the tech industry for major developments, new product launches, AI breakthroughs, video game releases and other newsworthy events. Editors assign relevant stories to staff writers or freelance contributors with expertise in each particular topic area. Before publication, articles go through a rigorous round of editing for accuracy, clarity, and to ensure adherence to ReadWrite's style guidelines.
- Application

Suswati Basu Tech journalist
Suswati Basu is a multilingual, award-winning editor and the founder of the intersectional literature channel, How To Be Books. She was shortlisted for the Guardian Mary Stott Prize and longlisted for the Guardian International Development Journalism Award. With 18 years of experience in the media industry, Suswati has held significant roles such as head of audience and deputy editor for NationalWorld news, digital editor for Channel 4 News and ITV News. She has also contributed to the Guardian and received training at the BBC As an audience, trends, and SEO specialist, she has participated in panel events alongside Google. Her…
Related News

Microsoft plans $1.5bn investment in Abu Dhabi AI group

Adobe expands generative AI features to video editing software Premiere Pro

Medium bans AI-generated content from its paid Partner Program

Elon Musk’s xAI previews Grok-1.5V, its first multimodal model
Most popular tech stories.
- Samsung Galaxy S25: release date, specs and price
- 5 best AI content detectors
- iPhone 16 Pro: release date and rumors
- Most Trending Cryptocurrency Today – Ethena, Meme Ai, Dogwifhat
- Apple explores frontier of personal robotics with innovative home devices
Latest News

Nintendo Indie World Showcase set for April 17
Nintendo's next live stream event, the Indie World Showcase, will air at 10 a.m. EDT on April 17 on the console maker's official YouTube account. Nintendo promises a 20-minute look...

Elon Musk wants to charge new users for posting on X

All the games leaving PS Plus Extra and premium in May 2024 - and the new games arriving

'Bitcoin and stocks may be about to have major correction', says analyst
All the games leaving ps plus extra and premium in may 2024 – and the new games arriving, ‘bitcoin and stocks may be about to have major correction’, says analyst.

UK is aiming to regulate cryptocurrencies by July 2024
Popular topics, get the biggest tech headlines of the day delivered to your inbox.
By signing up, you agree to our Terms and Privacy Policy. Unsubscribe anytime.
Explore the latest in tech with our Tech News. We cut through the noise for concise, relevant updates, keeping you informed about the rapidly evolving tech landscape with curated content that separates signal from noise.
Explore tech impact in In-Depth Stories. Narrative data journalism offers comprehensive analyses, revealing stories behind data. Understand industry trends for a deeper perspective on tech's intricate relationships with society.
Empower decisions with Expert Reviews, merging industry expertise and insightful analysis. Delve into tech intricacies, get the best deals, and stay ahead with our trustworthy guide to navigating the ever-changing tech market.

Realistic Voice AI
Lifelike and Powerful AI-Powered Free Online Text to Speech
Try the tool (any language)
How it works
Welcome to Realistic Voice, the leading AI Text-to-Speech platform that brings your written words to life with astonishing realism. Our advanced system utilizes state-of-the-art neural network models to generate natural and human-like speech patterns. So, how does it work? First, you simply input your text into our intuitive interface. Our powerful algorithms then analyze the input, taking into account various linguistic and contextual factors. Next, the system employs deep learning techniques to generate an audio waveform that closely resembles human speech. The resulting output preserves nuances such as intonation, rhythm, and even emotional expressions, ensuring an immersive and authentic auditory experience. Whether you’re a content creator, a developer, or someone looking for a lifelike voice for their project, Realistic Voice is your ultimate solution for converting text into captivating spoken content.
Text-to-Speech technology has revolutionized the way we engage with written content, opening up a wide range of exciting possibilities. With its versatility and natural-sounding voices, TTS can be utilized across various domains. For instance, authors and publishers can transform their books into engaging audiobooks, reaching a wider audience and providing an immersive storytelling experience. Documentaries and educational videos can benefit from TTS by adding a professional and captivating voiceover that enhances the viewer’s understanding and engagement. Content creators on platforms like YouTube and vlogs can use TTS to generate dynamic and expressive voices that accompany their videos, making them more engaging and accessible to diverse audiences. Additionally, TTS can bring poetry to life, providing a unique way to experience and appreciate literary works. From accessibility solutions for individuals with visual impairments to interactive voice-based applications and virtual assistants, the applications of TTS are vast and continually expanding, enabling seamless integration of written content into the auditory realm.
#1 Text To Speech (TTS) Reader Online
Proudly serving millions of users since 2015
Type or upload any text, file, website & book for listening online, proofreading, reading-along or generating professional mp3 voice-overs.
I need to >
Play Text Out Loud
Reads out loud plain text, files, e-books and websites. Remembers text & caret position, so you can come back to listening later, unlimited length, recording and more.
Create Humanlike Voiceovers
Murf is a text-to-speech tool offering 200+ natural voices for creating high-quality voiceovers for e-learning, podcasts, YouTubes & audiobooks, simplifying audio content production.
Additional Text-To-Speech Solutions
Turns your articles, PDFs, emails, etc. into podcasts, so you can listen to it on your own podcast player when convenient, with all the advantages that come with your podcast app.
SpeechNinja says what you type in real time. It enables people with speech difficulties to speak out loud using synthesized voice (AAC) and more.
Battle tested for years, serving millions of users, especially good for very long texts.
Need to read a webpage? Simply paste its URL here & click play. Leave empty to read about the Beatles 🎸
Books & Stories
Listen to some of the best stories ever written. We have them right here. Want to upload your own? Use the main player to upload epub files.
Simply paste any URL (link to a page) and it will import & read it out loud.
Chrome Extension
Reads out loud webpages, directly from within the page.
TTSReader for mobile - iOS or Android. Includes exporting audio to mp3 files.
NEW 🚀 - TTS Plugin
Make your own website speak your content - with a single line of code. Hassle free.
TTSReader Premium
Support our development team & enjoy ad-free better experience. Commercial users, publishers are required a premium license.
TTSReader reads out loud texts, webpages, pdfs & ebooks with natural sounding voices. Works out of the box. No need to download or install. No sign in required. Simply click 'play' and enjoy listening right in your browser. TTSReader remembers your text and position between sessions, so you can continue listening right where you left. Recording the generated speech is supported as well. Works offline, so you can use it at home, in the office, on the go, driving or taking a walk. Listening to textual content using TTSReader enables multitasking, reading on the go, improved comprehension and more. With support for multiple languages, it can be used for unlimited use cases .
Get Started for Free
Main Use Cases
Listen to great content.
Most of the world's content is in textual form. Being able to listen to it - is huge! In that sense, TTSReader has a huge advantage over podcasts. You choose your content - out of an infinite variety - that includes humanity's entire knowledge and art richness. Listen to lectures, to PDF files. Paste or upload any text from anywhere, edit it if needed, and listen to it anywhere and anytime.
Proofreading
One of the best ways to catch errors in your writing is to listen to it being read aloud. By using TTSReader for proofreading, you can catch errors that you might have missed while reading silently, allowing you to improve the quality and accuracy of your written content. Errors can be in sentence structure, punctuation, and grammar, but also in your essay's structure, order and content.
Listen to web pages
TTSReader can be used to read out loud webpages in two different ways. 1. Using the regular player - paste the URL and click play. The website's content will be imported into the player. (2) Using our Chrome extension to listen to pages without leaving the page . Listening to web pages with TTSReader can provide a more accessible, convenient, and efficient way of consuming online content.
Turn ebooks into audiobooks
Upload any ebook file of epub format - and TTSReader will read it out loud for you, effectively turning it into an audiobook alternative. You can find thousands of epub books for free, available for download on Project Gutenberg's site, which is an open library for free ebooks.
Read along for speed & comprehension
TTSReader enables read along by highlighting the sentence being read and automatically scrolling to keep it in view. This way you can follow with your own eyes - in parallel to listening to it. This can boost reading speed and improve comprehension.
Generate audio files from text
TTSReader enables exporting the synthesized speech with a single click. This is available currently only on Windows and requires TTSReader’s premium . Adhering to the commercial terms some of the voices may be used commercially for publishing, such as narrating videos.
Accessibility, dyslexia, etc.
For individuals with visual impairments or reading difficulties, listening to textual content, lectures, articles & web pages can be an essential tool for accessing & comprehending information.
Language learning
TTSReader can read out text in multiple languages, providing learners with listening as well as speaking practice. By listening to the text being read aloud, learners can improve their comprehension skills and pronunciation.
Kids - stories & learning
Kids love stories! And if you can read them stories - it's definitely the best! But, if you can't, let TTSReader read them stories for you. Set the right voice and speed, that is appropriate for their comprehension level. For kids who are at the age of learning to read - this can also be an effective tool to strengthen that skill, as it highlights every sentence being read.
Main Features
Ttsreader is a free text to speech reader that supports all modern browsers, including chrome, firefox and safari..
Includes multiple languages and accents. If on Chrome - you will get access to Google's voices as well. Super easy to use - no download, no login required. Here are some more features
Fun, Online, Free. Listen to great content
Drag, drop & play (or directly copy text & play). That’s it. No downloads. No logins. No passwords. No fuss. Simply fun to use and listen to great content. Great for listening in the background. Great for proof-reading. Great for kids and more. Learn more, including a YouTube we made, here .
Multilingual, Natural Voices
We facilitate high-quality natural-sounding voices from different sources. There are male & female voices, in different accents and different languages. Choose the voice you like, insert text, click play to generate the synthesized speech and enjoy listening.
Exit, Come Back & Play from Where You Stopped
TTSReader remembers the article and last position when paused, even if you close the browser. This way, you can come back to listening right where you previously left. Works on Chrome & Safari on mobile too. Ideal for listening to articles.
Vs. Recorded Podcasts
In many aspects, synthesized speech has advantages over recorded podcasts. Here are some: First of all - you have unlimited - free - content. That includes high-quality articles and books, that are not available on podcasts. Second - it’s free. Third - it uses almost no data - so it’s available offline too, and you save money. If you like listening on the go, as while driving or walking - get our free Android Text Reader App .
Read PDF Files, Texts & Websites
TTSReader extracts the text from pdf files, and reads it out loud. Also useful for simply copying text from pdf to anywhere. In addition, it highlights the text currently being read - so you can follow with your eyes. If you specifically want to listen to websites - such as blogs, news, wiki - you should get our free extension for Chrome
Export Speech to Audio Files
TTSReader enables exporting the synthesized speech to mp3 audio files. This is available currently only on Windows, and requires ttsreader’s premium .
Pricing & Plans
- Online text to speech player
- Chrome extension for reading webpages
- Premium TTSReader.com
- Premium Chrome extension
- Better support from the development team
Compare plans
Sister Apps Developed by Our Team
Speechnotes
Dictation & Transcription
Type with your voice for free, or automatically transcribe audio & video recordings
Buttons - Kids Dictionary
Turns your device into multiple push-buttons interactive games
Animals, numbers, colors, counting, letters, objects and more. Different levels. Multilingual. No ads. Made by parents, for our own kids.
Ways to Get In Touch, Feedback & Community
Visit our contact page , for various ways to get in touch with us, send us feedback and interact with our community of users & developers.
Don't have an account? Register
Two Factor Authentication
Forgot password.
Already have an account? Login
Pronunciation
Access more product features by logging in.
Pause Settings
- Question ? Seconds
- Exclamation ! Seconds
- At @ Seconds
- Hash # Seconds
- Between Paragraphs Seconds
Pronunciation Editor
Pronunciations are only supported by paid plans.
Voice Profile
Voice profiles are only supported by paid plans.
Voice Selection
Audio Setting
My projects, add project, edit project name, delete project, are you sure you want to delete this project, add to archive, volume ( 0db ), speed ( 0% ), pitch ( 0% ).
- Voice Effects
- Voice Settings
Voice Volume
Voice Speed
Voice Pitch
Audio Settings
Upload Background Music
File upload.
- No voices here, Please add some
Delete Voice
Are you sure you want to delete this voice, full text view, export voice, trusted by 1000+ well-known brands, create audio files for your commercial use.
Voicemaker allows you to redistribute your generated audio files even after your subscription expires.

Audiobooks & Podcast

Youtube videos

E-learning material

Sales & Social media videos

Public use and brodcasting

Web & Mobile Application

Call Centers & IVR System
View plans >, share audio across multiple platforms.
The converted audio files can be shared on any platform worldwide.
Industry-leading features that help us grow fast
Every day, text characters are converted into voiceovers.
Registered users from over 120 countries worldwide.
Discover how voice-over transforms words into human-sounding voices.
Pro settings.
Voice Stability
Voice Similarity
AI Voice Recorder: Everything You Need to Know
Table of contents.
AI voice recorders are poised to revolutionize the way we record, transcribe, and interact with audio. This isn’t just another gadget; it’s a fusion of AI technology and user-friendly design that transforms speech into text, offers seamless transcription services, and so much more.
Here, I’ll delve into everything you need to know about AI voice recorders, from their core functionalities to how they’re changing the face of content creation, meeting notes, and even podcasts.
What is an AI Voice Recorder
An AI voice recorder is more than just an audio recorder; it’s an AI-powered device or application capable of capturing voice memos, transcribing them into text, and performing a range of tasks like summarizing content or converting text to speech .
What sets it apart is its ability to transcribe in real-time, filter out background noise, and understand various languages, including English and French, making it invaluable for professionals, students, and anyone looking to enhance their note-taking or content creation process.
Key Functionalities and Features
One of the most significant advantages of using an AI voice recorder is its array of functionalities. These devices can transcribe speeches, meetings, and voiceovers into text transcription with remarkable accuracy.
Voice recorders can handle various audio formats, such as WAV and MP3, ensuring that your recordings are of the highest quality audio. Moreover, the transcription services are not just limited to English; many AI voice recorders are proficient in multiple languages, making them versatile tools for global use.
For content creators, podcasters, and professionals, the ability to record audio, transcribe it in real time, and even collaborate on the go is transformative. AI voice recorders offer functionalities like cloud storage for easy access and sharing, advanced audio editing features for crafting quality content, and algorithms that minimize background noise, ensuring that your recordings are clear and professional.
Compatibility and Accessibility
AI voice recorders are compatible across various platforms. Whether you’re an iPhone user or prefer Android, these recorders are designed to be incredibly user-friendly, offering a seamless experience on iOS and Android devices alike. Recorder apps often come with a straightforward interface, allowing you to record, transcribe, and edit audio files effortlessly.
Moreover, the integration of AI technology, like ChatGPT and other AI voice generators, into these recorders has made them more intelligent. They can understand context, summarize meetings, and even answer FAQs, making them a pro tool for anyone looking to enhance their productivity.
The Future of AI Voice Recorders
As we move forward, the potential of AI voice recorders to transform industries is immense. With companies like Microsoft and OpenAI leading the charge, the integration of advanced AI voice and transcription technologies is set to redefine how we approach recording meetings, creating podcasts, and even conducting interviews.
The ability to transcribe multi-lingual content in real-time, collaborate with team members remotely, and produce high-quality audio content is just the beginning.
Moreover, the emphasis on developing algorithms that can accurately transcribe and interpret speech voice, even in noisy environments, and the move towards more sophisticated audio editing tools, signal a future where voice recorders are not just tools but essential partners in content creation and communication.
AI voice recorders is a testament to how far AI technology has come in making our lives easier and our work more efficient. From offering real-time transcription services to facilitating seamless collaboration across different languages and platforms, AI voice recorders are set to revolutionize the way we think about recording, transcribing, and interacting with audio.
Whether you’re a professional looking to record meeting notes, a content creator aiming to produce high-quality podcasts, or just someone who loves to keep voice memos, the AI voice recorder is a tool that promises to make your audio experience better than ever before.
Frequently asked questions
Is there an ai that can record your voice.
Yes, there are AI-powered voice recorders that can record your voice and offer additional functionalities such as real-time transcription and noise reduction.
How do I record audio with AI voice?
To record audio with an AI voice, you typically need to install a voice recorder app that incorporates AI features, then use the app’s interface to start and manage your recordings.
Is AI voice free?
The availability of free AI voice recorders varies; some apps offer free versions with basic features, while more advanced functionalities might require a paid subscription.
What is the best recorder for ChatGPT?
For recording conversations with ChatGPT, any high-quality digital voice recorder that can capture clear audio or a smartphone app designed for recording meetings or notes would be effective, as ChatGPT itself does not record audio.
- Previous The Best Multilingual AI Speech Models
- Next Best AI Speech to Speech Tools

Cliff Weitzman
Cliff Weitzman is a dyslexia advocate and the CEO and founder of Speechify, the #1 text-to-speech app in the world, totaling over 100,000 5-star reviews and ranking first place in the App Store for the News & Magazines category. In 2017, Weitzman was named to the Forbes 30 under 30 list for his work making the internet more accessible to people with learning disabilities. Cliff Weitzman has been featured in EdSurge, Inc., PC Mag, Entrepreneur, Mashable, among other leading outlets.
Recent Blogs

Multilingual Voice API: Bridging Communication Gaps in a Diverse World

Resemble.AI vs ElevenLabs: A Comprehensive Comparison

Apps to Read PDFs on Mobile and Desktop

How to Convert a PDF to an Audiobook: A Step-by-Step Guide
AI for Translation: Bridging Language Barriers
IVR Conversion Tool: A Comprehensive Guide for Healthcare Providers
Best AI Speech to Speech Tools
The Best Multilingual AI Speech Models
Program that will Read PDF Aloud: Yes it Exists
How to Convert Your Emails to an Audiobook: A Step-by-Step Tutorial

How to Convert iOS Files to an Audiobook

How to Convert Google Docs to an Audiobook

How to Convert Word Docs to an Audiobook
Alternatives to Deepgram Text to Speech API
Is Text to Speech HSA Eligible?
Can You Use an HSA for Speech Therapy?
Surprising HSA-Eligible Items
Ultimate guide to ElevenLabs

Voice changer for Discord
How to download YouTube audio

Speechify 3.0 is the Best Text to Speech App Yet.

Voice API: Everything You Need to Know

Best text to speech generator apps

The best AI tools other than ChatGPT

Top voice over marketplaces reviewed
Speechify Studio vs. Descript

Everything to Know About Google Cloud Text to Speech API
Source of Joe Biden deepfake revealed after election interference
How to listen to scientific papers
How to add music to CapCut
Speechify text to speech helps you save time
Popular blogs.
The Best Celebrity Voice Generators in 2024
Youtube text to speech: elevating your video content with speechify.
The 7 best alternatives to Synthesia.io
Everything you need to know about text to speech on tiktok.
The 10 best text-to-speech apps for Android
How to convert a PDF to speech
The top girl voice changers
How to use siri text to speech.
Obama text to speech
Robot voice generators: the futuristic frontier of audio creation.
PDF Read Aloud: Free & Paid Options
Alternatives to FakeYou text to speech
All about deepfake voices, tiktok voice generator.
Only available on iPhone and iPad
To access our catalog of 100,000+ audiobooks, you need to use an iOS device.
Coming to Android soon...
Join the waitlist
Enter your email and we will notify you as soon as Speechify Audiobooks is available for you.
You’ve been added to the waitlist. We will notify you as soon as Speechify Audiobooks is available for you.
To revisit this article, visit My Profile, then View saved stories .
- Backchannel
- Newsletters
- WIRED Insider
- WIRED Consulting
By Benj Edwards, Ars Technica
OpenAI Can Re-Create Human Voices—but Won’t Release the Tech Yet
Voice synthesis has come a long way since 1978’s Speak & Spell toy, which once wowed people with its state-of-the-art ability to read words aloud using an electronic voice. Now, using deep-learning AI models , software can create not only realistic-sounding voices but can also convincingly imitate existing voices using small samples of audio.
Along those lines, OpenAI this week announced Voice Engine, a text-to-speech AI model for creating synthetic voices based on a 15-second segment of recorded audio. It has provided audio samples of the Voice Engine in action on its website .
Once a voice is cloned, a user can input text into the Voice Engine and get an AI-generated voice result. But OpenAI is not ready to widely release its technology. The company initially planned to launch a pilot program for developers to sign up for the Voice Engine API earlier this month. But after more consideration about ethical implications, the company decided to scale back its ambitions for now.
“In line with our approach to AI safety and our voluntary commitments, we are choosing to preview but not widely release this technology at this time,” the company writes. “We hope this preview of Voice Engine both underscores its potential and also motivates the need to bolster societal resilience against the challenges brought by ever more convincing generative models.”
Voice cloning tech in general is not particularly new—there have been several AI voice synthesis models since 2022, and the tech is active in the open source community with packages like OpenVoice and XTTSv2 . But the idea that OpenAI is inching toward letting anyone use its particular brand of voice tech is notable. And in some ways, the company's reticence to release it fully might be the bigger story.
OpenAI says that benefits of its voice technology include providing reading assistance through natural-sounding voices, enabling global reach for creators by translating content while preserving native accents, supporting non-verbal individuals with personalized speech options, and assisting patients in recovering their own voice after speech-impairing conditions.
But it also means that anyone with 15 seconds of someone's recorded voice could effectively clone it, and that has obvious implications for potential misuse. Even if OpenAI never widely releases its Voice Engine, the ability to clone voices has already caused trouble in society through phone scams where someone imitates a loved one's voice and election campaign robocalls featuring cloned voices from politicians like Joe Biden.
Also, researchers and reporters have shown that voice-cloning technology can be used to break into bank accounts that use voice authentication (such as Chase's Voice ID ), which prompted US senator Sherrod Brown of Ohio, the chair of the US Senate Committee on Banking, Housing, and Urban Affairs, to send a letter to the CEOs of several major banks in May 2023 to inquire about the security measures banks are taking to counteract AI-powered risks.
OpenAI recognizes that the tech might cause trouble if broadly released, so it's initially trying to work around those issues with a set of rules. It has been testing the technology with a set of select partner companies since last year. For example, video synthesis company HeyGen has been using the model to translate a speaker's voice into other languages while keeping the same vocal sound.

Charlie Wood

Eric Ravenscraft

Caitlin Kelly

To use Voice Engine, each partner must agree to terms of use that prohibit "the impersonation of another individual or organization without consent or legal right." The terms also require that partners acquire informed consent from the people whose voices are being cloned, and they must also clearly disclose that the voices they produce are AI-generated. OpenAI is also baking a watermark into every voice sample that will assist in tracing the origin of any voice generated by its Voice Engine model.
So, as it stands now, OpenAI is showing off its technology, but the company is not yet ready to put itself on the line (yet) for the potential social chaos a broad release might cause. Instead, the company has re-calibrated its marketing approach to appear as if it is warning all of us about this already-existing technology in a responsible way.
"We are taking a cautious and informed approach to a broader release due to the potential for synthetic voice misuse," the company said in a statement. "We hope to start a dialogue on the responsible deployment of synthetic voices and how society can adapt to these new capabilities. Based on these conversations and the results of these small scale tests, we will make a more informed decision about whether and how to deploy this technology at scale."
In line with its mission to cautiously roll out the tech, OpenAI has provided three recommendations for how society should change to accommodate its technology in its blog post . These steps include phasing out voice-based authentication for bank accounts, educating the public in understanding "the possibility of deceptive AI content," and accelerating the development of techniques that can track the origin of audio content, "so it's always clear when you're interacting with a real person or with an AI."
OpenAI also says that future voice-cloning tech should require verifying that the original speaker is "knowingly adding their voice to the service" and creating a list of voices that are forbidden to clone, such as those that are "too similar to prominent figures." That kind of screening tech may end up excluding anyone whose voice might naturally and accidentally sound too close to a celebrity or US president.
Tech Developed in 2022
According to the company, OpenAI developed its Voice Engine technology in late 2022, and many people have already been using a version of the technology with pre-defined (and not cloned) voices in two ways: The spoken conversation mode in the ChatGPT app released in September and OpenAI's text-to-speech API that debuted in November of last year.
With all the voice-cloning competition out there, OpenAI says that Voice Engine is notable for being a “small” AI model (how small, exactly, we do not know). But having been developed in 2022, it almost feels late to the party. And it may not be perfect in its cloning ability. Previous user-trained text-to-voice models like those from ElevenLabs and Microsoft have struggled with accents that fall outside their training dataset.
For now, Voice Engine remains a limited release to select partners.
This story originally appeared on Ars Technica .
You Might Also Like …
Navigate election season with our Politics Lab newsletter and podcast
Think Google’s “Incognito mode” protects your privacy? Think again
Blowing the whistle on sexual harassment and assault in Antarctica
The earth will feast on dead cicadas
Upgrading your Mac? Here’s what you should spend your money on

Matt Burgess

Joel Khalili

Lauren Goode

Jenna Scatena

Amanda Hoover

Steven Levy


Today, we’re launching Universal-1, our most powerful and accurate multilingual speech-to-text model to date—trained on 12.5M hours of multilingual audio data.
Today, AssemblyAI is launching Universal-1 , our most capable and highly trained speech recognition model. Trained on over 12.5 million hours of multilingual audio data, Universal-1 achieves best-in-class speech-to-text accuracy, reduces word error rate and hallucinations, improves timestamp estimation, and helps us continue to raise the bar as the industry-leading Speech AI provider.
Universal-1 is trained on four major languages: English, Spanish, French, and German, and shows extremely strong speech-to-text accuracy in almost all conditions, including heavy background noise, accented speech, natural conversations, and changes in language, while achieving fast turn-around time and improved timestamp accuracy.

In the last few years we've seen an explosion of audio data available online. This coupled with advances in AI technology have allowed organizations to unlock the value of voice data in ways that were previously impossible. As a result, organizations are building new products, services, and capabilities that serve millions of people around the world. By building on AssemblyAI’s Speech AI models, customers have built products that can summarize video calls with clear notes and action items, automate customer service experiences and help organizations understand the voice of their customers with insights from every customer interaction, and create apps that help teachers guide students more effectively as they learn to read.
With Universal-1 we sought to build on the industry-leading performance of our previous models, and designed this new model guided by the idea that accuracy of every word matters. In conversations with customers, it was clear that there was a need in the industry for a model that focused on the nuances of spoken language across accents, tone, dialect, faithfulness, and more. We hope the new capabilities of Universal-1 will help power the next generation of AI products and features built with voice data.
Accuracy is paramount when deciding which speech-to-text model to implement. AssemblyAI's Automatic Speech Recognition (ASR) model is best-in-class, and we are beneficiaries of the constant improvements they implement, like Universal-1. We provide lead intelligence to over 200,000 small businesses. If the transcriptions are not accurate, then the downstream intelligence our customers depend on will also be subpar — garbage in, garbage out.
Ryan Johnson, Chief Product Officer, CallRail
Universal-1 ASR: Pushing the Boundaries of Speech AI
Universal-1 accomplishes the following improvements:
Accurate and robust multilingual speech-to-text Universal-1 represents another major milestone in our mission to provide accurate, faithful, and robust speech-to-text capabilities for multiple languages, helping our customers and developers worldwide build various Speech AI applications.
- Universal-1 achieves 10% or greater improvement in English, Spanish, and German speech-to-text accuracy, compared to the next-best commercial speech-to-text system we tested.
- Universal-1 reduces hallucination rate by 30% over a widely used open-source model, Whisper Large-v3, providing users with confidence in the results we deliver.
- Humans prefer the outputs from Universal-1 over Conformer-2, our previous generation model, 71% of the time when they have a preference.
- Universal-1 exhibits the ability to code switch, transcribing multiple languages within a single audio file.

Precise timestamp estimation Word-level timestamps are essential for various downstream applications, such as audio and video editing. In conversation analytics and meeting transcription, accurate timestamps are crucial to enable speaker diarization to align speaker labels with recognized words.
- Word-level timestamps are essential for various downstream applications, such as audio and video editing as well as conversation analytics.
- Universal-1 improves our timestamp accuracy by 13% relative to Conformer-2.
- The improvement in timestamp estimation results in a positive impact on speaker diarization, improving concatenated minimum-permutation word error rate (cpWER) by 14% and speaker count estimation accuracy by 71% compared to Conformer-2.
Efficient parallel inference
- Effective parallelization during inference is crucial to achieve very low turnaround processing time for long audio files.
- Universal-1 achieves a 5x speed-up compared to a fast and batch-enabled implementation of Whisper Large-v3 on the same hardware.
# See it in action
Paul. It's okay. I'm here. I'm here. It's been a while since you've had one of those nightmares. Tell me, what was it about? It's only fragments. Nothing's clear. You've been fighting the Harkonnens for decades. Load. My family's been fighting them for centuries. Your blood comes from dukes and great houses. Here, we're equal. What we do, we do for the benefit of all. Well, I'd very much like to be equal to you. Maybe I'll show you the way. Deal with this prophet. Send assassins. Theodorother, he's psychotic. I see possible futures all at once. And in so many futures, our enemies prevail. But I do see a way. There is a narrow way through. My allegiance is to you. Do you believe me? This is a form of power that our world has not yet seen. The ultimate power. I want you to know I will love you as long as I breathe. You will never lose me as long as you stay who you are. Consider what you're about to do, Paul Atreides. Silence. This prophecy is how they enslave us. Journey. You are not prepared for what is done to come.
Entonces le digo yo a Martínez, Martínez, espérame right here cinco minutes que yo tengo que ir al toilet. Pero hay no idea lo que me iba a encontrar yo en ese toilet. Oye, te mando mamá, you cooking for me the sunny side up cuando tú sabes que a mí me gusta scramble. Emilito. ¿Number one, who told you que esto es para ti? En number dos, lo primero que tú dices en mi cocina es good morning. Ah, good morning, mami. Pues good morning, mamá. Good morning, mija. Así que no estoy en el toilet doing my business cuando escucho una woman screaming from el toilet de Alao. Mamá Sonny, side up for me, please. Sony, side up. Pero ya tú no eres vegetarian. No more lacto. Y aquí podemos ver a mi older sister que todos los días está cambiando el diet pensando que le estaban haciendo daño y boom. I can't believe my eyeball. Mami. El jefe Kissing in the mouth con Missy Martinez. Oh, my God. ¿Oye, quién me ayuda con algo de mi Instagram? I can't figure it out. Dame acá. Abuelita. ¿What is it? ¿Carolina? That's too la baby. Baja volumen, mi amor. Yo sospechaba algo porque ese jefe Eli's grabbing and touching all the girls en la oficina. Emilio, Mrs. Martinez no es ninguna santa, you know. Mamá, tú no puedes estar comiendo tu chorizo every morning. Habías hecho cáncer de colon. Emilio, sé something. ¿What? ¿Cómo que Emilio? ¿Qué falta de respeto es esa? You call me dad. ¿Abuelita, how? ¿Cómo es que tú tienes 100 likes en esta foto? Esa es mi people from bingo. Ay, my salud de colon ideal. So por favor, min, your own business. Carolina de volume. Wow, abuelita, tú eres una rockstar. ¿Can you like my post emily to bless the table? Yo bendije ayer, papá. Den tu lilianita. Thank you for all this comida que tu pones en nuestra family table. Bless the hands que prepararon la comida. Perdónanos por comer dis baby chicken huevos and forgive my papá Emilio for being so gossipy and chismoso. Amén. Amén. No, no, no, no puedo tomar café. No te hagas el sentido. No, no, no.
My name is Angelica Skyler Alexander Hamilton. Where's your family from? Unimportant. There's a million things I haven't. Just you wait. Just you wait. So this is what it feels like to match wit for someone at your level. What the hell is the catch? It's the feeling of freedom. Of seeing the light is Ben Franklin with the key and a kite. You see it, right? The conversation lasted two minutes, maybe three minutes. Everything we said in total agreement. It's the dream and it's a bit of a dance, a bit of a posture. It's a bit of a stance. He's a bit of a flirt. But I'm gonna give it a chance. I asked about his family. Did you see his answer? His hands started fidgeting. He looked askance. He's penniless. He's flying by the seat of his pants. Handsome boy, does he know it. Peach fuzz. Then he can't even grow it. Want to take him far away from this place? Then I turn and see my sister's face. And she is helpless. And I know she is helpless. And her eyes are just helpless. And I realize three fundamental truths at the exact same time.
Universal-1’s training data far exceeds the training data used for most existing speech-to-text models. This training data includes audio from non-native speakers, audio with heavy background noise, conversations involving multiple talkers held in various domains and settings, to better simulate how speech happens in the real world. Universal-1 also builds on our predecessor models, Conformer-1 and Conformer-2, to capture proper nouns and alphanumeric details with high accuracy.
We’re excited to see the impact that Universal-1 has on applications like:
- Conversational intelligence platforms that are now able to analyze vast amounts of customer data quickly, accurately, and reliably in order to surface critical voice of customer insights and analytics regardless of accent, recording condition, number of speakers, and more.
- AI notetakers that can now generate highly accurate and hallucination-free meeting notes to serve as the basis for LLM-powered summaries, action items, and other metadata generation with accurate proper noun, speaker, and timing information included.
- Creator tool applications that are now able to build AI-powered video editing workflows for their end-users leveraging precise speech-to-text outputs in multiple languages with low error rates and reliable word timing information.
- Telehealth platforms automating clinical note entry and claims submission processes with a high success rate leveraging accurate and faithful speech-to-text outputs, including rare words like prescription names and medical diagnoses, in adversarial and far field recording conditions.
Improving the accuracy of Speech AI across languages
Trained on English, Spanish, German, and French data, Universal-1 is built to support the languages most often used by our customers and their end-users.
Today, Universal-1 is available in English & Spanish, with German and French being made available shortly. We will be adding additional language support within future Universal models over time.
Best & Nano ASR Tiers: More Options to Build with AssemblyAI
Today, we’re also introducing our Best and Nano tiers to give you more options when building with Speech AI models from AssemblyAI depending on your budget, accuracy needs, and use case.
At AssemblyAI, we use a combination of models to produce your results. Our Best tier will house our most powerful and accurate models, including Universal-1. This tier is best suited for use cases where accuracy is paramount, and end-users will interact directly with the results generated from our models.
We are also introducing a Nano tier—a lightweight lower cost speech-to-text option available in many languages. Nano is best suited for use cases like search and topic detection or for use cases where accuracy is not paramount.
What Comes Next for Universal-1
Universal-1 is available via our API , and you can start building on it today. We’ll continue to improve our Speech AI models over time, so stay tuned for updates as we add new capabilities and languages to Universal-1.
# Frequently Asked Questions
Read our research post here. View all of our research here .
Our Best tier supports 17 languages. Our Nano tier supports 99 languages. As of April 3, 2024, Universal-1 will be supporting English and Spanish requests to our API when selecting Best.
At AssemblyAI, we use a combination of models to produce your results. AssemblyAI’s Best tier is our most robust and accurate offering, housing our most powerful models, and has the broadest range of capabilities. The Best tier is suited for use cases where accuracy and power are paramount. AssemblyAI’s Nano tier is a fast, lightweight offering that gives product and development teams access to Speech AI at an attainable price point across 99 languages. It is best for teams with extensive language needs, and those who are looking for a low-cost Speech AI option.
If you are a current AssemblyAI customer, you do not need to make any changes to your plan to access the Best tier. Our existing customers will default onto Best, with no pricing changes to your account and no action required. If you are a current customer who would like to try out Nano, simply select the Nano tier when building in our API.
Visit our Pricing page.
- Get Inspired
- Announcements
Gemini 1.5 Pro Now Available in 180+ Countries; With Native Audio Understanding, System Instructions, JSON Mode and More
April 09, 2024

Grab an API key in Google AI Studio , and get started with the Gemini API Cookbook
Less than two months ago, we made our next-generation Gemini 1.5 Pro model available in Google AI Studio for developers to try out. We’ve been amazed by what the community has been able to debug , create and learn using our groundbreaking 1 million context window.
Today, we’re making Gemini 1.5 Pro available in 180+ countries via the Gemini API in public preview, with a first-ever native audio (speech) understanding capability and a new File API to make it easy to handle files. We’re also launching new features like system instructions and JSON mode to give developers more control over the model’s output. Lastly, we’re releasing our next generation text embedding model that outperforms comparable models. Go to Google AI Studio to create or access your API key, and start building.
Unlock new use cases with audio and video modalities
We’re expanding the input modalities for Gemini 1.5 Pro to include audio (speech) understanding in both the Gemini API and Google AI Studio. Additionally, Gemini 1.5 Pro is now able to reason across both image (frames) and audio (speech) for videos uploaded in Google AI Studio, and we look forward to adding API support for this soon.
Gemini API Improvements
Today, we’re addressing a number of top developer requests:
1. System instructions : Guide the model’s responses with system instructions, now available in Google AI Studio and the Gemini API. Define roles, formats, goals, and rules to steer the model's behavior for your specific use case. Set System Instructions easily in Google AI Studio 2. JSON mode : Instruct the model to only output JSON objects. This mode enables structured data extraction from text or images. You can get started with cURL, and Python SDK support is coming soon. 3. Improvements to function calling : You can now select modes to limit the model’s outputs, improving reliability. Choose text, function call, or just the function itself.
A new embedding model with improved performance
Starting today, developers will be able to access our next generation text embedding model via the Gemini API. The new model, text-embedding-004 , (text-embedding-preview-0409 in Vertex AI ), achieves a stronger retrieval performance and outperforms existing models with comparable dimensions, on the MTEB benchmarks .
These are just the first of many improvements coming to the Gemini API and Google AI Studio in the next few weeks. We’re continuing to work on making Google AI Studio and the Gemini API the easiest way to build with Gemini. Get started today in Google AI Studio with Gemini 1.5 Pro, explore code examples and quickstarts in our new Gemini API Cookbook , and join our community channel on Discord .
- Skip to main content
- Keyboard shortcuts for audio player
Untangling Disinformation
Using ai to detect ai-generated deepfakes can work for audio — but not always.
Huo Jingnan

As deepfake generation technology improves and leaves ever-fewer telltale signs that humans can rely on, computational methods for detection are becoming the norm. But technological solutions are no silver bullet for the problem of detecting AI-generated voices. Aaron Marin for NPR hide caption
As deepfake generation technology improves and leaves ever-fewer telltale signs that humans can rely on, computational methods for detection are becoming the norm. But technological solutions are no silver bullet for the problem of detecting AI-generated voices.
Artificial intelligence is supercharging audio deepfakes , with alarm bells ringing in areas from politics to financial fraud.
The federal government has banned robocalls using voices generated by AI and is offering a cash prize for solutions to mitigate harms from voice cloning frauds . At the same time, researchers and the private sector are racing to develop software to detect voice clones, with companies often marketing them as fraud-detection tools.
The stakes are high. Detection software getting it wrong can carry serious implications.

It takes a few dollars and 8 minutes to create a deepfake. And that's only the start
"If we label a real audio as fake, let's say, in a political context, what does that mean for the world? We lose trust in everything," says Sarah Barrington, an AI and forensics researcher at the University of California, Berkeley.
"And if we label fake audios as real, then the same thing applies. We can get anyone to do or say anything and completely distort the discourse of what the truth is."
As deepfake generation technology improves and leaves ever-fewer telltale signs that humans can rely on, computational methods for detection are becoming the norm.
But an NPR experiment indicated that technological solutions are no silver bullet for the problem of detecting AI-generated voices.
Probably yes? Probably not
NPR identified three deepfake audio detection providers — Pindrop Security , AI or Not and AI Voice Detector . Most claim their tools are over 90% accurate at differentiating between real audio and AI-generated audio. Pindrop only works with businesses, while the others are available for individuals to use.

5 tips for not getting tricked online this April Fools' Day — and beyond
NPR submitted 84 clips of five to eight seconds to each provider. About half of the clips were snippets of real radio stories from three NPR reporters. The rest were cloned voices of the same reporters saying the same words as in the authentic clips.
The voice clones were generated by technology company PlayHT. To clone each voice, NPR submitted four 30-second clips of audio — one snippet of a previously aired radio story of each reporter and one recording made for this purpose.
Our experiment revealed that the detection software often failed to identify AI-generated clips, or misidentified real voices as AI-generated, or both. While Pindrop Security's tool got all but three samples correct, AI or Not's tool got about half wrong, failing to catch most of the AI-generated clips.
The verdicts these companies provide aren't just a binary yes or no. They give their results in the form of probabilities between 0% and 100%, indicating how likely it is that the audio was generated by AI.

AI-generated images are everywhere. Here's how to spot them
AI Voice Detector's CEO, Abdellah Azzouzi, told NPR in an interview that if the model predicts that a clip was 60% or more likely to be generated by AI, then it considers the clip AI-generated. Under this definition, the tool wrongly identified 20 out of the 84 samples NPR submitted.
AI Voice Detector updated its website after the interview. While the probability percentages for most previously tested clips remained the same, they now include an additional note laying out a new way of interpreting those results. Clips flagged as 80% or more are now deemed "highly likely to be generated by AI." Those scoring between 20% and 80% are "inconclusive." Clips rated less than 20 are "highly likely to be real."

That panicky call from a relative? It could be a thief using a voice clone, FTC warns
In an email to NPR, the company did not respond to NPR's questions about why the thresholds changed, but says it's "always updating our services to offer the best to those who trust us." The company also removed the claim from its website that the tool was more than 90% accurate.
Under these revised definitions, AI Voice Detector's tool got five of the clips NPR submitted wrong and returned inconclusive results for 32 clips.
While the other providers also provide results as probabilities, they did not provide results marked as inconclusive.
Using AI to catch AI
While NPR's anecdotal experiment is not a formal test or academic study, it highlights some challenges in the tricky business of deepfake detection.

AI images and conspiracy theories are driving a push for media literacy education
Detection technologies often involve training machine learning models. Since machine learning and artificial intelligence are virtually the same technology, people also call this approach "using AI to detect AI."
Barrington has both tested various detection methods and developed one with her team. Researchers curate a dataset of real audio and fake audio, transforming each into a series of numbers that are fed into the computer to analyze. The computer then finds the patterns humans cannot see to distinguish the two.
"Things like in the frequency domain, or very sort of small differences between audio signals and the noise, and things that we can't hear but to a computer are actually quite obvious," says Barrington.
Amit Gupta, head of product at Pindrop Security, says one of the things their algorithm does when evaluating a piece of audio is to reverse-engineer the vocal tract — the actual physical properties of a person's body — that would be needed to produce the sound. They called one fraudster's voice that they caught "Giraffe Man."

The FCC says AI voices in robocalls are illegal
"When you hear the sequence of sound from that fraudster, it is only possible for a vocal tract where a human had a 7-foot-long neck," Gupta says. "Machines don't have a vocal tract. ... And that's where they make mistakes."
Anatoly Kvitnitsky, CEO of AI or Not, says his company trains its machine learning model based on clients' specific-use cases. As a result, he said, the general-use model the public has access to is not as accurate.
"The format is a little bit different depending on if it's a phone call ... if it's a YouTube video. If it's a Spotify song, or TikTok video. All of those formats leave a different kind of trace."

Tech giants pledge action against deceptive AI in elections
While often better at detecting fake audio than people, machine learning models can easily be stumped in the wild. Accuracy can drop if the audio is degraded or contains background noise. Model makers need to train their detectors on every new AI audio generator on the market to detect the subtle differences between them and real people. With new deepfake models being released frequently and open source models becoming available for everyone to tweak and use, it's a game of whack-a-mole.
After NPR told AI or Not which provider it used to generate the deepfake audio clips, the company released an updated detection model that returned better results. It caught most of the AI clips, but also misidentified more real voices as AI. Its tool cannot process some other clips and returned error messages.
What's more, all of these accuracy rates only pertain to English-language audio. Machine learning models need to analyze real and fake audio samples from each language to tell the difference between them.

Meta will start labeling AI-generated images on Instagram and Facebook
While there seems to be an arm's race between deepfake voice generators and deepfake voice detectors, Barrington says it's important for the two sides to work together to make detection better.
ElevenLabs, whose technology was used to create the audio for the deepfake Biden robocall , has a publicly available tool that detects its own product. Previously, the website claimed that the tool also detects audio generated by other providers, but independent research has shown poor results. PlayHT says a tool to detect AI voices — including its own — is still under development.
Detection at scale isn't there yet
Tech giants including major social media companies such as Meta, TikTok and X have expressed their interest in "developing technology to watermark, detect and label realistic content that's been created with AI." Most platforms' efforts seem to focus more on video, and it's unclear whether that would include audio, says Katie Harbath, chief global affairs officer at Duco Experts, a consultancy on trust and safety.

AI fakes raise election risks as lawmakers and tech companies scramble to catch up
In March, YouTube announced that it would require content creators to self-label some videos made with generative AI before they upload videos. This follows similar steps from TikTok . Meta says it's also going to roll out labeling on Facebook and Instagram, using watermarks from companies that produce generative AI content.
Barrington says specific algorithms could detect deepfakes of world leaders whose voices are well known and documented, such as President Biden. That won't be the case for people who are less well known.
"What people should be very careful about is the potential for deepfake audio in down-ballot races," Harbath says. With less local journalism and with fact-checkers at capacity, deepfakes could cause disruption.

AI-generated deepfakes are moving fast. Policymakers can't keep up
As for scam calls impersonating loved ones, there's no high-tech detection that flags them. You and your family can come up with questions a scammer wouldn't know the answer to in advance, and the FTC recommends calling back to make sure the call was not spoofed.
"Anyone who says 'here's an algorithm,' just, you know, a web browser plug-in, it will tell you yes or no — I think that's hugely misleading," Barrington says.
IMAGES
VIDEO
COMMENTS
Rated the best text to speech (TTS) software online. Create premium AI voices for free and generate text-to-speech voiceovers in minutes with our character AI voice generator. Use free text to speech AI to convert text to mp3 in 29 languages with 100+ voices.
NaturalReader is a web-based text to speech (TTS) service that uses natural AI voices to read aloud PDFs, websites, and books. Learn more about TTS technology, its applications, and the languages it supports.
SpeechGen.io is a web service that converts text into speech using cutting-edge AI voices with an American English accent. You can use it for work, videos, business, ads, social media, entertainment, and more. Download audio files in MP3, WAV, OGG and use them for commercial purposes.
Global AI Speech Generator Convert text to mp3 in 29 languages and 70+ voices. Our AI text to speech software is designed to be flexible and easy to use, with a variety of voice options to suit your needs.
Murf AI lets you create studio-quality voice overs from text with over 120 AI voices in 20 languages. You can also add video, music, or image, and sync your voice with your projects.
Murf offers a selection of 100% natural sounding AI voices in 20 languages to make professional voice over for your videos and presentations. You can try Murf for free and choose from a variety of voices across different accents and age groups.
Convert text to speech with over 120 AI voices in 20+ languages on Canva. Customize your voice with speed, pitch, emotion, and tonality, and add it to any video, design, or presentation.
Text to Speech - Google Cloud
PlayHT offers realistic AI voices that convert text in to natural sounding humanlike voice performances across any language and accent. You can create engaging voice content with unique AI Voices, perfect for marketing, explainer, gaming, e-learning and more.
Text to Speech. Voice to Voice. Instant Voice Cloning. Rap. Prompt Builder. Text to speech. Convert text into speech. Voice Selection. Here is the list of all the voices that you can use to generate speech. Gender. English. Access. Your Text. Add your text below to generate speech.
Our free text-to-speech feature allows you to bring your scripts to life with ease, requiring just a few clicks. Simply input your text, choose your preferred voice, and let our advanced AI technology handle the rest. Whether you're developing captivating marketing videos, informative tutorials, or educational content, our free text-to-speech ...
VEED's AI text-to-speech tool lets you generate human-like voices with realistic AI avatars or presets. You can convert written content to voice automatically, save on video production costs, and edit your videos with other AI tools. Try it for free and join the multitudes of content creators choosing VEED.
LOVO AI is a text to speech software that offers realistic AI voices in 100 languages and 500+ voices for various use cases. You can create videos, podcasts, ads, audiobooks and more with Genny AI voice generator, Genny's text to speech engine, and Genny's AI writer and art generator.
Experience the ease of the AI Realistic Voice Generator with 1,100+ voices in 80+ languages. Speechki generates realistic Text-to-Speech voiceovers online and transforms any of your text into high-quality audio content. Discover the future of content creation with Speechki today!
Use Deepgram's AI voice generator to produce human speech from text. AI matches text with correct pronunciation for natural, high-quality audio. Type something here, and Aura will turn your text into a realistic human voice. AI matches what is written with how it should be said so your audio sounds natural and high-quality. 180 / 2, 000.
Speechify Premium: $139 per year for advanced text-to-speech features and capabilities. Speechify Studio Free: $0 for access to basic AI voice and video features with no downloads. Speechify ...
Experience the power of AI-powered text to speech with our neural voices. Enjoy natural and lifelike voices that will bring your projects to life, powered by the latest neural network technology. With our neural voices, you can create engaging audio content in multiple languages for any application - from gaming to educational materials.
Learn how to use the Audio API to turn text into lifelike spoken audio in multiple languages and formats. Choose from 6 built-in voices and stream real time audio with low latency.
Text to speech is an AI Speech feature that converts text to realistic voices for apps and services. Customize, deploy, and fine-tune your speech output with different speaking styles, emotional tones, and fine-grained controls.
Generate voice audio from text using your browser's built-in voice synthesis technology or external text-to-speech server. Adjust pitch and speed, download or record the audio, and add effects with voicechanger.io.
AI voice generator software transforms written text into voices that closely resemble human speech. It can be customized for various speech styles, ages, genders, and accents, and can also ...
Speechify is a text to speech app that uses artificial intelligence to read words aloud in natural sounding voices. You can listen to any text, image, or document at any speed, with 40+ languages and 100+ accents to choose from.
Lifelike and Powerful AI-Powered Free Online Text to Speech. Try the tool (any language) How it works. Welcome to Realistic Voice, the leading AI Text-to-Speech platform that brings your written words to life with astonishing realism. Our advanced system utilizes state-of-the-art neural network models to generate natural and human-like speech ...
TTSReader is a free and easy-to-use web service that converts any text, file, website or book into natural sounding speech. You can listen, proofread, read along, export audio files and more with TTSReader's features and voices.
Voicemaker is a text to speech converter that uses neural TTS AI to generate natural and realistic voiceovers from any text. You can customize voice effects, settings, and audio formats, and redistribute your audio files for free after your subscription expires.
AI voice recorders are poised to revolutionize the way we record, transcribe, and interact with audio. This isn't just another gadget; it's a fusion of AI technology and user-friendly design that transforms speech into text, offers seamless transcription services, and so much more.
Voice Engine is a new text-to-speech AI model for creating synthetic voices. OpenAI has said a wide release would be too risky. Along those lines, OpenAI this week announced Voice Engine, a text ...
Universal-1 is our most powerful speech recognition model. Trained on over 12.5 million hours of multilingual audio data, Universal-1 achieves best-in-class speech-to-text accuracy across four major languages: English, Spanish, French, and German.
Go to Google AI Studio to create or access your API key, and start building. Unlock new use cases with audio and video modalities. We're expanding the input modalities for Gemini 1.5 Pro to include audio (speech) understanding in both the Gemini API and Google AI Studio. Additionally, Gemini 1.5 Pro is now able to reason across both image ...
AI Voice Detector's CEO, Abdellah Azzouzi, told NPR in an interview that if the model predicts that a clip was 60% or more likely to be generated by AI, then it considers the clip AI-generated.