- Reviews / Why join our community?
- For companies
- Frequently asked questions

Visual Representation
What is visual representation.
Visual Representation refers to the principles by which markings on a surface are made and interpreted. Designers use representations like typography and illustrations to communicate information, emotions and concepts. Color, imagery, typography and layout are crucial in this communication.
Alan Blackwell, cognition scientist and professor, gives a brief introduction to visual representation:
- Transcript loading…
We can see visual representation throughout human history, from cave drawings to data visualization :
Art uses visual representation to express emotions and abstract ideas.
Financial forecasting graphs condense data and research into a more straightforward format.
Icons on user interfaces (UI) represent different actions users can take.
The color of a notification indicates its nature and meaning.

Van Gogh's "The Starry Night" uses visuals to evoke deep emotions, representing an abstract, dreamy night sky. It exemplifies how art can communicate complex feelings and ideas.
© Public domain
Importance of Visual Representation in Design
Designers use visual representation for internal and external use throughout the design process . For example:
Storyboards are illustrations that outline users’ actions and where they perform them.
Sitemaps are diagrams that show the hierarchy and navigation structure of a website.
Wireframes are sketches that bring together elements of a user interface's structure.
Usability reports use graphs and charts to communicate data gathered from usability testing.
User interfaces visually represent information contained in applications and computerized devices.

This usability report is straightforward to understand. Yet, the data behind the visualizations could come from thousands of answered surveys.
© Interaction Design Foundation, CC BY-SA 4.0
Visual representation simplifies complex ideas and data and makes them easy to understand. Without these visual aids, designers would struggle to communicate their ideas, findings and products . For example, it would be easier to create a mockup of an e-commerce website interface than to describe it with words.

Visual representation simplifies the communication of designs. Without mockups, it would be difficult for developers to reproduce designs using words alone.
Types of Visual Representation
Below are some of the most common forms of visual representation designers use.
Text and Typography
Text represents language and ideas through written characters and symbols. Readers visually perceive and interpret these characters. Typography turns text into a visual form, influencing its perception and interpretation.
We have developed the conventions of typography over centuries , for example, in documents, newspapers and magazines. These conventions include:
Text arranged on a grid brings clarity and structure. Gridded text makes complex information easier to navigate and understand. Tables, columns and other formats help organize content logically and enhance readability.
Contrasting text sizes create a visual hierarchy and draw attention to critical areas. For example, headings use larger text while body copy uses smaller text. This contrast helps readers distinguish between primary and secondary information.
Adequate spacing and paragraphing improve the readability and appearance of the text. These conventions prevent the content from appearing cluttered. Spacing and paragraphing make it easier for the eye to follow and for the brain to process the information.
Balanced image-to-text ratios create engaging layouts. Images break the monotony of text, provide visual relief and illustrate or emphasize points made in the text. A well-planned ratio ensures neither text nor images overwhelm each other. Effective ratios make designs more effective and appealing.
Designers use these conventions because people are familiar with them and better understand text presented in this manner.

This table of funerals from the plague in London in 1665 uses typographic conventions still used today. For example, the author arranged the information in a table and used contrasting text styling to highlight information in the header.
Illustrations and Drawings
Designers use illustrations and drawings independently or alongside text. An example of illustration used to communicate information is the assembly instructions created by furniture retailer IKEA. If IKEA used text instead of illustrations in their instructions, people would find it harder to assemble the furniture.

IKEA assembly instructions use illustrations to inform customers how to build their furniture. The only text used is numeric to denote step and part numbers. IKEA communicates this information visually to: 1. Enable simple communication, 2. Ensure their instructions are easy to follow, regardless of the customer’s language.
© IKEA, Fair use
Illustrations and drawings can often convey the core message of a visual representation more effectively than a photograph. They focus on the core message , while a photograph might distract a viewer with additional details (such as who this person is, where they are from, etc.)
For example, in IKEA’s case, photographing a person building a piece of furniture might be complicated. Further, photographs may not be easy to understand in a black-and-white print, leading to higher printing costs. To be useful, the pictures would also need to be larger and would occupy more space on a printed manual, further adding to the costs.
But imagine a girl winking—this is something we can easily photograph.
Ivan Sutherland, creator of the first graphical user interface, used his computer program Sketchpad to draw a winking girl. While not realistic, Sutherland's representation effectively portrays a winking girl. The drawing's abstract, generic elements contrast with the distinct winking eye. The graphical conventions of lines and shapes represent the eyes and mouth. The simplicity of the drawing does not draw attention away from the winking.

A photo might distract from the focused message compared to Sutherland's representation. In the photo, the other aspects of the image (i.e., the particular person) distract the viewer from this message.
© Ivan Sutherland, CC BY-SA 3.0 and Amina Filkins, Pexels License
Information and Data Visualization
Designers and other stakeholders use data and information visualization across many industries.
Data visualization uses charts and graphs to show raw data in a graphic form. Information visualization goes further, including more context and complex data sets. Information visualization often uses interactive elements to share a deeper understanding.
For example, most computerized devices have a battery level indicator. This is a type of data visualization. IV takes this further by allowing you to click on the battery indicator for further insights. These insights may include the apps that use the most battery and the last time you charged your device.

macOS displays a battery icon in the menu bar that visualizes your device’s battery level. This is an example of data visualization. Meanwhile, macOS’s settings tell you battery level over time, screen-on-usage and when you last charged your device. These insights are actionable; users may notice their battery drains at a specific time. This is an example of information visualization.
© Low Battery by Jemis Mali, CC BY-NC-ND 4.0, and Apple, Fair use
Information visualization is not exclusive to numeric data. It encompasses representations like diagrams and maps. For example, Google Maps collates various types of data and information into one interface:
Data Representation: Google Maps transforms complex geographical data into an easily understandable and navigable visual map.
Interactivity: Users can interactively customize views that show traffic, satellite imagery and more in real-time.
Layered Information: Google Maps layers multiple data types (e.g., traffic, weather) over geographical maps for comprehensive visualization.
User-Centered Design : The interface is intuitive and user-friendly, with symbols and colors for straightforward data interpretation.

The volume of data contained in one screenshot of Google Maps is massive. However, this information is presented clearly to the user. Google Maps highlights different terrains with colors and local places and businesses with icons and colors. The panel on the left lists the selected location’s profile, which includes an image, rating and contact information.
© Google, Fair use
Symbolic Correspondence
Symbolic correspondence uses universally recognized symbols and signs to convey specific meanings . This method employs widely recognized visual cues for immediate understanding. Symbolic correspondence removes the need for textual explanation.
For instance, a magnifying glass icon in UI design signifies the search function. Similarly, in environmental design, symbols for restrooms, parking and amenities guide visitors effectively.

The Interaction Design Foundation (IxDF) website uses the universal magnifying glass symbol to signify the search function. Similarly, the play icon draws attention to a link to watch a video.
How Designers Create Visual Representations
Visual language.
Designers use elements like color , shape and texture to create a communicative visual experience. Designers use these 8 principles:
Size – Larger elements tend to capture users' attention readily.
Color – Users are typically drawn to bright colors over muted shades.
Contrast – Colors with stark contrasts catch the eye more effectively.
Alignment – Unaligned elements are more noticeable than those aligned ones.
Repetition – Similar styles repeated imply a relationship in content.
Proximity – Elements placed near each other appear to be connected.
Whitespace – Elements surrounded by ample space attract the eye.
Texture and Style – Users often notice richer textures before flat designs.
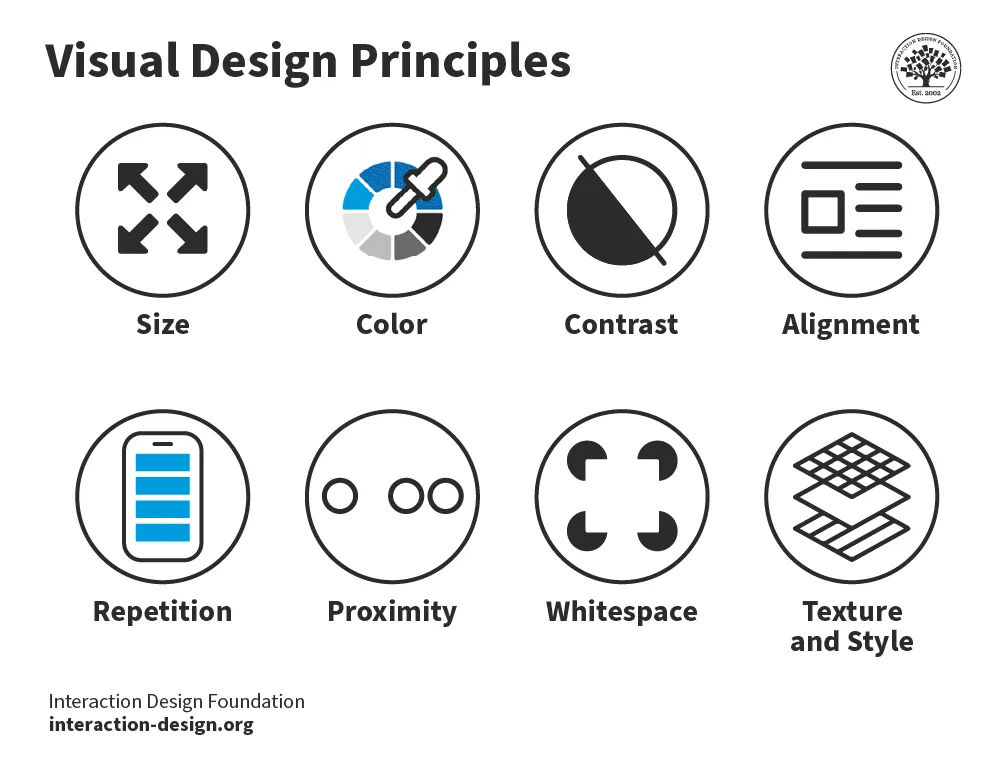
The 8 visual design principles.
In web design , visual hierarchy uses color and repetition to direct the user's attention. Color choice is crucial as it creates contrast between different elements. Repetition helps to organize the design—it uses recurring elements to establish consistency and familiarity.
In this video, Alan Dix, Professor and Expert in Human-Computer Interaction, explains how visual alignment affects how we read and absorb information:
Correspondence Techniques
Designers use correspondence techniques to align visual elements with their conceptual meanings. These techniques include color coding, spatial arrangement and specific imagery. In information visualization, different colors can represent various data sets. This correspondence aids users in quickly identifying trends and relationships .

Color coding enables the stakeholder to see the relationship and trend between the two pie charts easily.
In user interface design, correspondence techniques link elements with meaning. An example is color-coding notifications to state their nature. For instance, red for warnings and green for confirmation. These techniques are informative and intuitive and enhance the user experience.

The IxDF website uses blue for call-to-actions (CTAs) and red for warnings. These colors inform the user of the nature of the action of buttons and other interactive elements.
Perception and Interpretation
If visual language is how designers create representations, then visual perception and interpretation are how users receive those representations. Consider a painting—the viewer’s eyes take in colors, shapes and lines, and the brain perceives these visual elements as a painting.
In this video, Alan Dix explains how the interplay of sensation, perception and culture is crucial to understanding visual experiences in design:
Copyright holder: Michael Murphy _ Appearance time: 07:19 - 07:37 _ Link: https://www.youtube.com/watch?v=C67JuZnBBDc
Visual perception principles are essential for creating compelling, engaging visual representations. For example, Gestalt principles explain how we perceive visual information. These rules describe how we group similar items, spot patterns and simplify complex images. Designers apply Gestalt principles to arrange content on websites and other interfaces. This application creates visually appealing and easily understood designs.
In this video, design expert and teacher Mia Cinelli discusses the significance of Gestalt principles in visual design . She introduces fundamental principles, like figure/ground relationships, similarity and proximity.
Interpretation
Everyone's experiences, culture and physical abilities dictate how they interpret visual representations. For this reason, designers carefully consider how users interpret their visual representations. They employ user research and testing to ensure their designs are attractive and functional.

Leonardo da Vinci's "Mona Lisa", is one of the most famous paintings in the world. The piece is renowned for its subject's enigmatic expression. Some interpret her smile as content and serene, while others see it as sad or mischievous. Not everyone interprets this visual representation in the same way.
Color is an excellent example of how one person, compared to another, may interpret a visual element. Take the color red:
In Chinese culture, red symbolizes luck, while in some parts of Africa, it can mean death or illness.
A personal experience may mean a user has a negative or positive connotation with red.
People with protanopia and deuteranopia color blindness cannot distinguish between red and green.
In this video, Joann and Arielle Eckstut, leading color consultants and authors, explain how many factors influence how we perceive and interpret color:
Learn More about Visual Representation
Read Alan Blackwell’s chapter on visual representation from The Encyclopedia of Human-Computer Interaction.
Learn about the F-Shaped Pattern For Reading Web Content from Jakob Nielsen.
Read Smashing Magazine’s article, Visual Design Language: The Building Blocks Of Design .
Take the IxDF’s course, Perception and Memory in HCI and UX .
Questions related to Visual Representation
Some highly cited research on visual representation and related topics includes:
Roland, P. E., & Gulyás, B. (1994). Visual imagery and visual representation. Trends in Neurosciences, 17(7), 281-287. Roland and Gulyás' study explores how the brain creates visual imagination. They look at whether imagining things like objects and scenes uses the same parts of the brain as seeing them does. Their research shows the brain uses certain areas specifically for imagination. These areas are different from the areas used for seeing. This research is essential for understanding how our brain works with vision.
Lurie, N. H., & Mason, C. H. (2007). Visual Representation: Implications for Decision Making. Journal of Marketing, 71(1), 160-177.
This article looks at how visualization tools help in understanding complicated marketing data. It discusses how these tools affect decision-making in marketing. The article gives a detailed method to assess the impact of visuals on the study and combination of vast quantities of marketing data. It explores the benefits and possible biases visuals can bring to marketing choices. These factors make the article an essential resource for researchers and marketing experts. The article suggests using visual tools and detailed analysis together for the best results.
Lohse, G. L., Biolsi, K., Walker, N., & Rueter, H. H. (1994, December). A classification of visual representations. Communications of the ACM, 37(12), 36+.
This publication looks at how visuals help communicate and make information easier to understand. It divides these visuals into six types: graphs, tables, maps, diagrams, networks and icons. The article also looks at different ways these visuals share information effectively.
If you’d like to cite content from the IxDF website , click the ‘cite this article’ button near the top of your screen.
Some recommended books on visual representation and related topics include:
Chaplin, E. (1994). Sociology and Visual Representation (1st ed.) . Routledge.
Chaplin's book describes how visual art analysis has changed from ancient times to today. It shows how photography, post-modernism and feminism have changed how we see art. The book combines words and images in its analysis and looks into real-life social sciences studies.
Mitchell, W. J. T. (1994). Picture Theory. The University of Chicago Press.
Mitchell's book explores the important role and meaning of pictures in the late twentieth century. It discusses the change from focusing on language to focusing on images in cultural studies. The book deeply examines the interaction between images and text in different cultural forms like literature, art and media. This detailed study of how we see and read visual representations has become an essential reference for scholars and professionals.
Koffka, K. (1935). Principles of Gestalt Psychology. Harcourt, Brace & World.
"Principles of Gestalt Psychology" by Koffka, released in 1935, is a critical book in its field. It's known as a foundational work in Gestalt psychology, laying out the basic ideas of the theory and how they apply to how we see and think. Koffka's thorough study of Gestalt psychology's principles has profoundly influenced how we understand human perception. This book has been a significant reference in later research and writings.
A visual representation, like an infographic or chart, uses visual elements to show information or data. These types of visuals make complicated information easier to understand and more user-friendly.
Designers harness visual representations in design and communication. Infographics and charts, for instance, distill data for easier audience comprehension and retention.
For an introduction to designing basic information visualizations, take our course, Information Visualization .
Text is a crucial design and communication element, transforming language visually. Designers use font style, size, color and layout to convey emotions and messages effectively.
Designers utilize text for both literal communication and aesthetic enhancement. Their typography choices significantly impact design aesthetics, user experience and readability.
Designers should always consider text's visual impact in their designs. This consideration includes font choice, placement, color and interaction with other design elements.
In this video, design expert and teacher Mia Cinelli teaches how Gestalt principles apply to typography:
Designers use visual elements in projects to convey information, ideas, and messages. Designers use images, colors, shapes and typography for impactful designs.
In UI/UX design, visual representation is vital. Icons, buttons and colors provide contrast for intuitive, user-friendly website and app interfaces.
Graphic design leverages visual representation to create attention-grabbing marketing materials. Careful color, imagery and layout choices create an emotional connection.
Product design relies on visual representation for prototyping and idea presentation. Designers and stakeholders use visual representations to envision functional, aesthetically pleasing products.
Our brains process visuals 60,000 times faster than text. This fact highlights the crucial role of visual representation in design.
Our course, Visual Design: The Ultimate Guide , teaches you how to use visual design elements and principles in your work effectively.
Visual representation, crucial in UX, facilitates interaction, comprehension and emotion. It combines elements like images and typography for better interfaces.
Effective visuals guide users, highlight features and improve navigation. Icons and color schemes communicate functions and set interaction tones.
UX design research shows visual elements significantly impact emotions. 90% of brain-transmitted information is visual.
To create functional, accessible visuals, designers use color contrast and consistent iconography. These elements improve readability and inclusivity.
An excellent example of visual representation in UX is Apple's iOS interface. iOS combines a clean, minimalist design with intuitive navigation. As a result, the operating system is both visually appealing and user-friendly.
Michal Malewicz, Creative Director and CEO at Hype4, explains why visual skills are important in design:
Learn more about UI design from Michal in our Master Class, Beyond Interfaces: The UI Design Skills You Need to Know .
The fundamental principles of effective visual representation are:
Clarity : Designers convey messages clearly, avoiding clutter.
Simplicity : Embrace simple designs for ease and recall.
Emphasis : Designers highlight key elements distinctively.
Balance : Balance ensures design stability and structure.
Alignment : Designers enhance coherence through alignment.
Contrast : Use contrast for dynamic, distinct designs.
Repetition : Repeating elements unify and guide designs.
Designers practice these principles in their projects. They also analyze successful designs and seek feedback to improve their skills.
Read our topic description of Gestalt principles to learn more about creating effective visual designs. The Gestalt principles explain how humans group elements, recognize patterns and simplify object perception.
Color theory is vital in design, helping designers craft visually appealing and compelling works. Designers understand color interactions, psychological impacts and symbolism. These elements help designers enhance communication and guide attention.
Designers use complementary , analogous and triadic colors for contrast, harmony and balance. Understanding color temperature also plays a crucial role in design perception.
Color symbolism is crucial, as different colors can represent specific emotions and messages. For instance, blue can symbolize trust and calmness, while red can indicate energy and urgency.
Cultural variations significantly influence color perception and symbolism. Designers consider these differences to ensure their designs resonate with diverse audiences.
For actionable insights, designers should:
Experiment with color schemes for effective messaging.
Assess colors' psychological impact on the audience.
Use color contrast to highlight critical elements.
Ensure color choices are accessible to all.
In this video, Joann and Arielle Eckstut, leading color consultants and authors, give their six tips for choosing color:
Learn more about color from Joann and Arielle in our Master Class, How To Use Color Theory To Enhance Your Designs .
Typography and font choice are crucial in design, impacting readability and mood. Designers utilize them for effective communication and expression.
Designers' perception of information varies with font type. Serif fonts can imply formality, while sans-serifs can give a more modern look.
Typography choices by designers influence readability and user experience. Well-spaced, distinct fonts enhance readability, whereas decorative fonts may hinder it.
Designers use typography to evoke emotions and set a design's tone. Choices in font size, style and color affect the emotional impact and message clarity.
Designers use typography to direct attention, create hierarchy and establish rhythm. These benefits help with brand recognition and consistency across mediums.
Read our article to learn how web fonts are critical to the online user experience .
Designers create a balance between simplicity and complexity in their work. They focus on the main messages and highlight important parts. Designers use the principles of visual hierarchy, like size, color and spacing. They also use empty space to make their designs clear and understandable.
The Gestalt law of Prägnanz suggests people naturally simplify complex images. This principle aids in making even intricate information accessible and engaging.
Through iteration and feedback, designers refine visuals. They remove extraneous elements and highlight vital information. Testing with the target audience ensures the design resonates and is comprehensible.
Michal Malewicz explains how to master hierarchy in UI design using the Gestalt rule of proximity:
Literature on Visual Representation
Here’s the entire UX literature on Visual Representation by the Interaction Design Foundation, collated in one place:
Learn more about Visual Representation
Take a deep dive into Visual Representation with our course Perception and Memory in HCI and UX .
How does all of this fit with interaction design and user experience? The simple answer is that most of our understanding of human experience comes from our own experiences and just being ourselves. That might extend to people like us, but it gives us no real grasp of the whole range of human experience and abilities. By considering more closely how humans perceive and interact with our world, we can gain real insights into what designs will work for a broader audience: those younger or older than us, more or less capable, more or less skilled and so on.
“You can design for all the people some of the time, and some of the people all the time, but you cannot design for all the people all the time.“ – William Hudson (with apologies to Abraham Lincoln)
While “design for all of the people all of the time” is an impossible goal, understanding how the human machine operates is essential to getting ever closer. And of course, building solutions for people with a wide range of abilities, including those with accessibility issues, involves knowing how and why some human faculties fail. As our course tutor, Professor Alan Dix, points out, this is not only a moral duty but, in most countries, also a legal obligation.
Portfolio Project
In the “ Build Your Portfolio: Perception and Memory Project ”, you’ll find a series of practical exercises that will give you first-hand experience in applying what we’ll cover. If you want to complete these optional exercises, you’ll create a series of case studies for your portfolio which you can show your future employer or freelance customers.
This in-depth, video-based course is created with the amazing Alan Dix , the co-author of the internationally best-selling textbook Human-Computer Interaction and a superstar in the field of Human-Computer Interaction . Alan is currently a professor and Director of the Computational Foundry at Swansea University.
Gain an Industry-Recognized UX Course Certificate
Use your industry-recognized Course Certificate on your resume , CV , LinkedIn profile or your website.
All open-source articles on Visual Representation
Data visualization for human perception.

The Key Elements & Principles of Visual Design

- 1.1k shares
Guidelines for Good Visual Information Representations

- 4 years ago
Philosophy of Interaction
Information visualization – an introduction to multivariate analysis.

- 8 years ago
Aesthetic Computing
How to represent linear data visually for information visualization.

- 5 years ago
Open Access—Link to us!
We believe in Open Access and the democratization of knowledge . Unfortunately, world-class educational materials such as this page are normally hidden behind paywalls or in expensive textbooks.
If you want this to change , cite this page , link to us, or join us to help us democratize design knowledge !
Privacy Settings
Our digital services use necessary tracking technologies, including third-party cookies, for security, functionality, and to uphold user rights. Optional cookies offer enhanced features, and analytics.
Experience the full potential of our site that remembers your preferences and supports secure sign-in.
Governs the storage of data necessary for maintaining website security, user authentication, and fraud prevention mechanisms.
Enhanced Functionality
Saves your settings and preferences, like your location, for a more personalized experience.
Referral Program
We use cookies to enable our referral program, giving you and your friends discounts.
Error Reporting
We share user ID with Bugsnag and NewRelic to help us track errors and fix issues.
Optimize your experience by allowing us to monitor site usage. You’ll enjoy a smoother, more personalized journey without compromising your privacy.
Analytics Storage
Collects anonymous data on how you navigate and interact, helping us make informed improvements.
Differentiates real visitors from automated bots, ensuring accurate usage data and improving your website experience.
Lets us tailor your digital ads to match your interests, making them more relevant and useful to you.
Advertising Storage
Stores information for better-targeted advertising, enhancing your online ad experience.
Personalization Storage
Permits storing data to personalize content and ads across Google services based on user behavior, enhancing overall user experience.
Advertising Personalization
Allows for content and ad personalization across Google services based on user behavior. This consent enhances user experiences.
Enables personalizing ads based on user data and interactions, allowing for more relevant advertising experiences across Google services.
Receive more relevant advertisements by sharing your interests and behavior with our trusted advertising partners.
Enables better ad targeting and measurement on Meta platforms, making ads you see more relevant.
Allows for improved ad effectiveness and measurement through Meta’s Conversions API, ensuring privacy-compliant data sharing.
LinkedIn Insights
Tracks conversions, retargeting, and web analytics for LinkedIn ad campaigns, enhancing ad relevance and performance.
LinkedIn CAPI
Enhances LinkedIn advertising through server-side event tracking, offering more accurate measurement and personalization.
Google Ads Tag
Tracks ad performance and user engagement, helping deliver ads that are most useful to you.
Share Knowledge, Get Respect!
or copy link
Cite according to academic standards
Simply copy and paste the text below into your bibliographic reference list, onto your blog, or anywhere else. You can also just hyperlink to this page.
New to UX Design? We’re Giving You a Free ebook!

Download our free ebook The Basics of User Experience Design to learn about core concepts of UX design.
In 9 chapters, we’ll cover: conducting user interviews, design thinking, interaction design, mobile UX design, usability, UX research, and many more!
- Open access
- Published: 19 July 2015
The role of visual representations in scientific practices: from conceptual understanding and knowledge generation to ‘seeing’ how science works
- Maria Evagorou 1 ,
- Sibel Erduran 2 &
- Terhi Mäntylä 3
International Journal of STEM Education volume 2 , Article number: 11 ( 2015 ) Cite this article
73k Accesses
78 Citations
13 Altmetric
Metrics details
The use of visual representations (i.e., photographs, diagrams, models) has been part of science, and their use makes it possible for scientists to interact with and represent complex phenomena, not observable in other ways. Despite a wealth of research in science education on visual representations, the emphasis of such research has mainly been on the conceptual understanding when using visual representations and less on visual representations as epistemic objects. In this paper, we argue that by positioning visual representations as epistemic objects of scientific practices, science education can bring a renewed focus on how visualization contributes to knowledge formation in science from the learners’ perspective.
This is a theoretical paper, and in order to argue about the role of visualization, we first present a case study, that of the discovery of the structure of DNA that highlights the epistemic components of visual information in science. The second case study focuses on Faraday’s use of the lines of magnetic force. Faraday is known of his exploratory, creative, and yet systemic way of experimenting, and the visual reasoning leading to theoretical development was an inherent part of the experimentation. Third, we trace a contemporary account from science focusing on the experimental practices and how reproducibility of experimental procedures can be reinforced through video data.
Conclusions
Our conclusions suggest that in teaching science, the emphasis in visualization should shift from cognitive understanding—using the products of science to understand the content—to engaging in the processes of visualization. Furthermore, we suggest that is it essential to design curriculum materials and learning environments that create a social and epistemic context and invite students to engage in the practice of visualization as evidence, reasoning, experimental procedure, or a means of communication and reflect on these practices. Implications for teacher education include the need for teacher professional development programs to problematize the use of visual representations as epistemic objects that are part of scientific practices.
During the last decades, research and reform documents in science education across the world have been calling for an emphasis not only on the content but also on the processes of science (Bybee 2014 ; Eurydice 2012 ; Duschl and Bybee 2014 ; Osborne 2014 ; Schwartz et al. 2012 ), in order to make science accessible to the students and enable them to understand the epistemic foundation of science. Scientific practices, part of the process of science, are the cognitive and discursive activities that are targeted in science education to develop epistemic understanding and appreciation of the nature of science (Duschl et al. 2008 ) and have been the emphasis of recent reform documents in science education across the world (Achieve 2013 ; Eurydice 2012 ). With the term scientific practices, we refer to the processes that take place during scientific discoveries and include among others: asking questions, developing and using models, engaging in arguments, and constructing and communicating explanations (National Research Council 2012 ). The emphasis on scientific practices aims to move the teaching of science from knowledge to the understanding of the processes and the epistemic aspects of science. Additionally, by placing an emphasis on engaging students in scientific practices, we aim to help students acquire scientific knowledge in meaningful contexts that resemble the reality of scientific discoveries.
Despite a wealth of research in science education on visual representations, the emphasis of such research has mainly been on the conceptual understanding when using visual representations and less on visual representations as epistemic objects. In this paper, we argue that by positioning visual representations as epistemic objects, science education can bring a renewed focus on how visualization contributes to knowledge formation in science from the learners’ perspective. Specifically, the use of visual representations (i.e., photographs, diagrams, tables, charts) has been part of science and over the years has evolved with the new technologies (i.e., from drawings to advanced digital images and three dimensional models). Visualization makes it possible for scientists to interact with complex phenomena (Richards 2003 ), and they might convey important evidence not observable in other ways. Visual representations as a tool to support cognitive understanding in science have been studied extensively (i.e., Gilbert 2010 ; Wu and Shah 2004 ). Studies in science education have explored the use of images in science textbooks (i.e., Dimopoulos et al. 2003 ; Bungum 2008 ), students’ representations or models when doing science (i.e., Gilbert et al. 2008 ; Dori et al. 2003 ; Lehrer and Schauble 2012 ; Schwarz et al. 2009 ), and students’ images of science and scientists (i.e., Chambers 1983 ). Therefore, studies in the field of science education have been using the term visualization as “the formation of an internal representation from an external representation” (Gilbert et al. 2008 , p. 4) or as a tool for conceptual understanding for students.
In this paper, we do not refer to visualization as mental image, model, or presentation only (Gilbert et al. 2008 ; Philips et al. 2010 ) but instead focus on visual representations or visualization as epistemic objects. Specifically, we refer to visualization as a process for knowledge production and growth in science. In this respect, modeling is an aspect of visualization, but what we are focusing on with visualization is not on the use of model as a tool for cognitive understanding (Gilbert 2010 ; Wu and Shah 2004 ) but the on the process of modeling as a scientific practice which includes the construction and use of models, the use of other representations, the communication in the groups with the use of the visual representation, and the appreciation of the difficulties that the science phase in this process. Therefore, the purpose of this paper is to present through the history of science how visualization can be considered not only as a cognitive tool in science education but also as an epistemic object that can potentially support students to understand aspects of the nature of science.
Scientific practices and science education
According to the New Generation Science Standards (Achieve 2013 ), scientific practices refer to: asking questions and defining problems; developing and using models; planning and carrying out investigations; analyzing and interpreting data; using mathematical and computational thinking; constructing explanations and designing solutions; engaging in argument from evidence; and obtaining, evaluating, and communicating information. A significant aspect of scientific practices is that science learning is more than just about learning facts, concepts, theories, and laws. A fuller appreciation of science necessitates the understanding of the science relative to its epistemological grounding and the process that are involved in the production of knowledge (Hogan and Maglienti 2001 ; Wickman 2004 ).
The New Generation Science Standards is, among other changes, shifting away from science inquiry and towards the inclusion of scientific practices (Duschl and Bybee 2014 ; Osborne 2014 ). By comparing the abilities to do scientific inquiry (National Research Council 2000 ) with the set of scientific practices, it is evident that the latter is about engaging in the processes of doing science and experiencing in that way science in a more authentic way. Engaging in scientific practices according to Osborne ( 2014 ) “presents a more authentic picture of the endeavor that is science” (p.183) and also helps the students to develop a deeper understanding of the epistemic aspects of science. Furthermore, as Bybee ( 2014 ) argues, by engaging students in scientific practices, we involve them in an understanding of the nature of science and an understanding on the nature of scientific knowledge.
Science as a practice and scientific practices as a term emerged by the philosopher of science, Kuhn (Osborne 2014 ), refers to the processes in which the scientists engage during knowledge production and communication. The work that is followed by historians, philosophers, and sociologists of science (Latour 2011 ; Longino 2002 ; Nersessian 2008 ) revealed the scientific practices in which the scientists engage in and include among others theory development and specific ways of talking, modeling, and communicating the outcomes of science.
Visualization as an epistemic object
Schematic, pictorial symbols in the design of scientific instruments and analysis of the perceptual and functional information that is being stored in those images have been areas of investigation in philosophy of scientific experimentation (Gooding et al. 1993 ). The nature of visual perception, the relationship between thought and vision, and the role of reproducibility as a norm for experimental research form a central aspect of this domain of research in philosophy of science. For instance, Rothbart ( 1997 ) has argued that visualizations are commonplace in the theoretical sciences even if every scientific theory may not be defined by visualized models.
Visual representations (i.e., photographs, diagrams, tables, charts, models) have been used in science over the years to enable scientists to interact with complex phenomena (Richards 2003 ) and might convey important evidence not observable in other ways (Barber et al. 2006 ). Some authors (e.g., Ruivenkamp and Rip 2010 ) have argued that visualization is as a core activity of some scientific communities of practice (e.g., nanotechnology) while others (e.g., Lynch and Edgerton 1988 ) have differentiated the role of particular visualization techniques (e.g., of digital image processing in astronomy). Visualization in science includes the complex process through which scientists develop or produce imagery, schemes, and graphical representation, and therefore, what is of importance in this process is not only the result but also the methodology employed by the scientists, namely, how this result was produced. Visual representations in science may refer to objects that are believed to have some kind of material or physical existence but equally might refer to purely mental, conceptual, and abstract constructs (Pauwels 2006 ). More specifically, visual representations can be found for: (a) phenomena that are not observable with the eye (i.e., microscopic or macroscopic); (b) phenomena that do not exist as visual representations but can be translated as such (i.e., sound); and (c) in experimental settings to provide visual data representations (i.e., graphs presenting velocity of moving objects). Additionally, since science is not only about replicating reality but also about making it more understandable to people (either to the public or other scientists), visual representations are not only about reproducing the nature but also about: (a) functioning in helping solving a problem, (b) filling gaps in our knowledge, and (c) facilitating knowledge building or transfer (Lynch 2006 ).
Using or developing visual representations in the scientific practice can range from a straightforward to a complicated situation. More specifically, scientists can observe a phenomenon (i.e., mitosis) and represent it visually using a picture or diagram, which is quite straightforward. But they can also use a variety of complicated techniques (i.e., crystallography in the case of DNA studies) that are either available or need to be developed or refined in order to acquire the visual information that can be used in the process of theory development (i.e., Latour and Woolgar 1979 ). Furthermore, some visual representations need decoding, and the scientists need to learn how to read these images (i.e., radiologists); therefore, using visual representations in the process of science requires learning a new language that is specific to the medium/methods that is used (i.e., understanding an X-ray picture is different from understanding an MRI scan) and then communicating that language to other scientists and the public.
There are much intent and purposes of visual representations in scientific practices, as for example to make a diagnosis, compare, describe, and preserve for future study, verify and explore new territory, generate new data (Pauwels 2006 ), or present new methodologies. According to Latour and Woolgar ( 1979 ) and Knorr Cetina ( 1999 ), visual representations can be used either as primary data (i.e., image from a microscope). or can be used to help in concept development (i.e., models of DNA used by Watson and Crick), to uncover relationships and to make the abstract more concrete (graphs of sound waves). Therefore, visual representations and visual practices, in all forms, are an important aspect of the scientific practices in developing, clarifying, and transmitting scientific knowledge (Pauwels 2006 ).
Methods and Results: Merging Visualization and scientific practices in science
In this paper, we present three case studies that embody the working practices of scientists in an effort to present visualization as a scientific practice and present our argument about how visualization is a complex process that could include among others modeling and use of representation but is not only limited to that. The first case study explores the role of visualization in the construction of knowledge about the structure of DNA, using visuals as evidence. The second case study focuses on Faraday’s use of the lines of magnetic force and the visual reasoning leading to the theoretical development that was an inherent part of the experimentation. The third case study focuses on the current practices of scientists in the context of a peer-reviewed journal called the Journal of Visualized Experiments where the methodology is communicated through videotaped procedures. The three case studies represent the research interests of the three authors of this paper and were chosen to present how visualization as a practice can be involved in all stages of doing science, from hypothesizing and evaluating evidence (case study 1) to experimenting and reasoning (case study 2) to communicating the findings and methodology with the research community (case study 3), and represent in this way the three functions of visualization as presented by Lynch ( 2006 ). Furthermore, the last case study showcases how the development of visualization technologies has contributed to the communication of findings and methodologies in science and present in that way an aspect of current scientific practices. In all three cases, our approach is guided by the observation that the visual information is an integral part of scientific practices at the least and furthermore that they are particularly central in the scientific practices of science.
Case study 1: use visual representations as evidence in the discovery of DNA
The focus of the first case study is the discovery of the structure of DNA. The DNA was first isolated in 1869 by Friedrich Miescher, and by the late 1940s, it was known that it contained phosphate, sugar, and four nitrogen-containing chemical bases. However, no one had figured the structure of the DNA until Watson and Crick presented their model of DNA in 1953. Other than the social aspects of the discovery of the DNA, another important aspect was the role of visual evidence that led to knowledge development in the area. More specifically, by studying the personal accounts of Watson ( 1968 ) and Crick ( 1988 ) about the discovery of the structure of the DNA, the following main ideas regarding the role of visual representations in the production of knowledge can be identified: (a) The use of visual representations was an important part of knowledge growth and was often dependent upon the discovery of new technologies (i.e., better microscopes or better techniques in crystallography that would provide better visual representations as evidence of the helical structure of the DNA); and (b) Models (three-dimensional) were used as a way to represent the visual images (X-ray images) and connect them to the evidence provided by other sources to see whether the theory can be supported. Therefore, the model of DNA was built based on the combination of visual evidence and experimental data.
An example showcasing the importance of visual representations in the process of knowledge production in this case is provided by Watson, in his book The Double Helix (1968):
…since the middle of the summer Rosy [Rosalind Franklin] had had evidence for a new three-dimensional form of DNA. It occurred when the DNA 2molecules were surrounded by a large amount of water. When I asked what the pattern was like, Maurice went into the adjacent room to pick up a print of the new form they called the “B” structure. The instant I saw the picture, my mouth fell open and my pulse began to race. The pattern was unbelievably simpler than those previously obtained (A form). Moreover, the black cross of reflections which dominated the picture could arise only from a helical structure. With the A form the argument for the helix was never straightforward, and considerable ambiguity existed as to exactly which type of helical symmetry was present. With the B form however, mere inspection of its X-ray picture gave several of the vital helical parameters. (p. 167-169)
As suggested by Watson’s personal account of the discovery of the DNA, the photo taken by Rosalind Franklin (Fig. 1 ) convinced him that the DNA molecule must consist of two chains arranged in a paired helix, which resembles a spiral staircase or ladder, and on March 7, 1953, Watson and Crick finished and presented their model of the structure of DNA (Watson and Berry 2004 ; Watson 1968 ) which was based on the visual information provided by the X-ray image and their knowledge of chemistry.
X-ray chrystallography of DNA
In analyzing the visualization practice in this case study, we observe the following instances that highlight how the visual information played a role:
Asking questions and defining problems: The real world in the model of science can at some points only be observed through visual representations or representations, i.e., if we are using DNA as an example, the structure of DNA was only observable through the crystallography images produced by Rosalind Franklin in the laboratory. There was no other way to observe the structure of DNA, therefore the real world.
Analyzing and interpreting data: The images that resulted from crystallography as well as their interpretations served as the data for the scientists studying the structure of DNA.
Experimenting: The data in the form of visual information were used to predict the possible structure of the DNA.
Modeling: Based on the prediction, an actual three-dimensional model was prepared by Watson and Crick. The first model did not fit with the real world (refuted by Rosalind Franklin and her research group from King’s College) and Watson and Crick had to go through the same process again to find better visual evidence (better crystallography images) and create an improved visual model.
Example excerpts from Watson’s biography provide further evidence for how visualization practices were applied in the context of the discovery of DNA (Table 1 ).
In summary, by examining the history of the discovery of DNA, we showcased how visual data is used as scientific evidence in science, identifying in that way an aspect of the nature of science that is still unexplored in the history of science and an aspect that has been ignored in the teaching of science. Visual representations are used in many ways: as images, as models, as evidence to support or rebut a model, and as interpretations of reality.
Case study 2: applying visual reasoning in knowledge production, the example of the lines of magnetic force
The focus of this case study is on Faraday’s use of the lines of magnetic force. Faraday is known of his exploratory, creative, and yet systemic way of experimenting, and the visual reasoning leading to theoretical development was an inherent part of this experimentation (Gooding 2006 ). Faraday’s articles or notebooks do not include mathematical formulations; instead, they include images and illustrations from experimental devices and setups to the recapping of his theoretical ideas (Nersessian 2008 ). According to Gooding ( 2006 ), “Faraday’s visual method was designed not to copy apparent features of the world, but to analyse and replicate them” (2006, p. 46).
The lines of force played a central role in Faraday’s research on electricity and magnetism and in the development of his “field theory” (Faraday 1852a ; Nersessian 1984 ). Before Faraday, the experiments with iron filings around magnets were known and the term “magnetic curves” was used for the iron filing patterns and also for the geometrical constructs derived from the mathematical theory of magnetism (Gooding et al. 1993 ). However, Faraday used the lines of force for explaining his experimental observations and in constructing the theory of forces in magnetism and electricity. Examples of Faraday’s different illustrations of lines of magnetic force are given in Fig. 2 . Faraday gave the following experiment-based definition for the lines of magnetic forces:
a Iron filing pattern in case of bar magnet drawn by Faraday (Faraday 1852b , Plate IX, p. 158, Fig. 1), b Faraday’s drawing of lines of magnetic force in case of cylinder magnet, where the experimental procedure, knife blade showing the direction of lines, is combined into drawing (Faraday, 1855, vol. 1, plate 1)
A line of magnetic force may be defined as that line which is described by a very small magnetic needle, when it is so moved in either direction correspondent to its length, that the needle is constantly a tangent to the line of motion; or it is that line along which, if a transverse wire be moved in either direction, there is no tendency to the formation of any current in the wire, whilst if moved in any other direction there is such a tendency; or it is that line which coincides with the direction of the magnecrystallic axis of a crystal of bismuth, which is carried in either direction along it. The direction of these lines about and amongst magnets and electric currents, is easily represented and understood, in a general manner, by the ordinary use of iron filings. (Faraday 1852a , p. 25 (3071))
The definition describes the connection between the experiments and the visual representation of the results. Initially, the lines of force were just geometric representations, but later, Faraday treated them as physical objects (Nersessian 1984 ; Pocovi and Finlay 2002 ):
I have sometimes used the term lines of force so vaguely, as to leave the reader doubtful whether I intended it as a merely representative idea of the forces, or as the description of the path along which the power was continuously exerted. … wherever the expression line of force is taken simply to represent the disposition of forces, it shall have the fullness of that meaning; but that wherever it may seem to represent the idea of the physical mode of transmission of the force, it expresses in that respect the opinion to which I incline at present. The opinion may be erroneous, and yet all that relates or refers to the disposition of the force will remain the same. (Faraday, 1852a , p. 55-56 (3075))
He also felt that the lines of force had greater explanatory power than the dominant theory of action-at-a-distance:
Now it appears to me that these lines may be employed with great advantage to represent nature, condition, direction and comparative amount of the magnetic forces; and that in many cases they have, to the physical reasoned at least, a superiority over that method which represents the forces as concentrated in centres of action… (Faraday, 1852a , p. 26 (3074))
For giving some insight to Faraday’s visual reasoning as an epistemic practice, the following examples of Faraday’s studies of the lines of magnetic force (Faraday 1852a , 1852b ) are presented:
(a) Asking questions and defining problems: The iron filing patterns formed the empirical basis for the visual model: 2D visualization of lines of magnetic force as presented in Fig. 2 . According to Faraday, these iron filing patterns were suitable for illustrating the direction and form of the magnetic lines of force (emphasis added):
It must be well understood that these forms give no indication by their appearance of the relative strength of the magnetic force at different places, inasmuch as the appearance of the lines depends greatly upon the quantity of filings and the amount of tapping; but the direction and forms of these lines are well given, and these indicate, in a considerable degree, the direction in which the forces increase and diminish . (Faraday 1852b , p.158 (3237))
Despite being static and two dimensional on paper, the lines of magnetic force were dynamical (Nersessian 1992 , 2008 ) and three dimensional for Faraday (see Fig. 2 b). For instance, Faraday described the lines of force “expanding”, “bending,” and “being cut” (Nersessian 1992 ). In Fig. 2 b, Faraday has summarized his experiment (bar magnet and knife blade) and its results (lines of force) in one picture.
(b) Analyzing and interpreting data: The model was so powerful for Faraday that he ended up thinking them as physical objects (e.g., Nersessian 1984 ), i.e., making interpretations of the way forces act. Of course, he made a lot of experiments for showing the physical existence of the lines of force, but he did not succeed in it (Nersessian 1984 ). The following quote illuminates Faraday’s use of the lines of force in different situations:
The study of these lines has, at different times, been greatly influential in leading me to various results, which I think prove their utility as well as fertility. Thus, the law of magneto-electric induction; the earth’s inductive action; the relation of magnetism and light; diamagnetic action and its law, and magnetocrystallic action, are the cases of this kind… (Faraday 1852a , p. 55 (3174))
(c) Experimenting: In Faraday's case, he used a lot of exploratory experiments; in case of lines of magnetic force, he used, e.g., iron filings, magnetic needles, or current carrying wires (see the quote above). The magnetic field is not directly observable and the representation of lines of force was a visual model, which includes the direction, form, and magnitude of field.
(d) Modeling: There is no denying that the lines of magnetic force are visual by nature. Faraday’s views of lines of force developed gradually during the years, and he applied and developed them in different contexts such as electromagnetic, electrostatic, and magnetic induction (Nersessian 1984 ). An example of Faraday’s explanation of the effect of the wire b’s position to experiment is given in Fig. 3 . In Fig. 3 , few magnetic lines of force are drawn, and in the quote below, Faraday is explaining the effect using these magnetic lines of force (emphasis added):
Picture of an experiment with different arrangements of wires ( a , b’ , b” ), magnet, and galvanometer. Note the lines of force drawn around the magnet. (Faraday 1852a , p. 34)
It will be evident by inspection of Fig. 3 , that, however the wires are carried away, the general result will, according to the assumed principles of action, be the same; for if a be the axial wire, and b’, b”, b”’ the equatorial wire, represented in three different positions, whatever magnetic lines of force pass across the latter wire in one position, will also pass it in the other, or in any other position which can be given to it. The distance of the wire at the place of intersection with the lines of force, has been shown, by the experiments (3093.), to be unimportant. (Faraday 1852a , p. 34 (3099))
In summary, by examining the history of Faraday’s use of lines of force, we showed how visual imagery and reasoning played an important part in Faraday’s construction and representation of his “field theory”. As Gooding has stated, “many of Faraday’s sketches are far more that depictions of observation, they are tools for reasoning with and about phenomena” (2006, p. 59).
Case study 3: visualizing scientific methods, the case of a journal
The focus of the third case study is the Journal of Visualized Experiments (JoVE) , a peer-reviewed publication indexed in PubMed. The journal devoted to the publication of biological, medical, chemical, and physical research in a video format. The journal describes its history as follows:
JoVE was established as a new tool in life science publication and communication, with participation of scientists from leading research institutions. JoVE takes advantage of video technology to capture and transmit the multiple facets and intricacies of life science research. Visualization greatly facilitates the understanding and efficient reproduction of both basic and complex experimental techniques, thereby addressing two of the biggest challenges faced by today's life science research community: i) low transparency and poor reproducibility of biological experiments and ii) time and labor-intensive nature of learning new experimental techniques. ( http://www.jove.com/ )
By examining the journal content, we generate a set of categories that can be considered as indicators of relevance and significance in terms of epistemic practices of science that have relevance for science education. For example, the quote above illustrates how scientists view some norms of scientific practice including the norms of “transparency” and “reproducibility” of experimental methods and results, and how the visual format of the journal facilitates the implementation of these norms. “Reproducibility” can be considered as an epistemic criterion that sits at the heart of what counts as an experimental procedure in science:
Investigating what should be reproducible and by whom leads to different types of experimental reproducibility, which can be observed to play different roles in experimental practice. A successful application of the strategy of reproducing an experiment is an achievement that may depend on certain isiosyncratic aspects of a local situation. Yet a purely local experiment that cannot be carried out by other experimenters and in other experimental contexts will, in the end be unproductive in science. (Sarkar and Pfeifer 2006 , p.270)
We now turn to an article on “Elevated Plus Maze for Mice” that is available for free on the journal website ( http://www.jove.com/video/1088/elevated-plus-maze-for-mice ). The purpose of this experiment was to investigate anxiety levels in mice through behavioral analysis. The journal article consists of a 9-min video accompanied by text. The video illustrates the handling of the mice in soundproof location with less light, worksheets with characteristics of mice, computer software, apparatus, resources, setting up the computer software, and the video recording of mouse behavior on the computer. The authors describe the apparatus that is used in the experiment and state how procedural differences exist between research groups that lead to difficulties in the interpretation of results:
The apparatus consists of open arms and closed arms, crossed in the middle perpendicularly to each other, and a center area. Mice are given access to all of the arms and are allowed to move freely between them. The number of entries into the open arms and the time spent in the open arms are used as indices of open space-induced anxiety in mice. Unfortunately, the procedural differences that exist between laboratories make it difficult to duplicate and compare results among laboratories.
The authors’ emphasis on the particularity of procedural context echoes in the observations of some philosophers of science:
It is not just the knowledge of experimental objects and phenomena but also their actual existence and occurrence that prove to be dependent on specific, productive interventions by the experimenters” (Sarkar and Pfeifer 2006 , pp. 270-271)
The inclusion of a video of the experimental procedure specifies what the apparatus looks like (Fig. 4 ) and how the behavior of the mice is captured through video recording that feeds into a computer (Fig. 5 ). Subsequently, a computer software which captures different variables such as the distance traveled, the number of entries, and the time spent on each arm of the apparatus. Here, there is visual information at different levels of representation ranging from reconfiguration of raw video data to representations that analyze the data around the variables in question (Fig. 6 ). The practice of levels of visual representations is not particular to the biological sciences. For instance, they are commonplace in nanotechnological practices:
Visual illustration of apparatus
Video processing of experimental set-up
Computer software for video input and variable recording
In the visualization processes, instruments are needed that can register the nanoscale and provide raw data, which needs to be transformed into images. Some Imaging Techniques have software incorporated already where this transformation automatically takes place, providing raw images. Raw data must be translated through the use of Graphic Software and software is also used for the further manipulation of images to highlight what is of interest to capture the (inferred) phenomena -- and to capture the reader. There are two levels of choice: Scientists have to choose which imaging technique and embedded software to use for the job at hand, and they will then have to follow the structure of the software. Within such software, there are explicit choices for the scientists, e.g. about colour coding, and ways of sharpening images. (Ruivenkamp and Rip 2010 , pp.14–15)
On the text that accompanies the video, the authors highlight the role of visualization in their experiment:
Visualization of the protocol will promote better understanding of the details of the entire experimental procedure, allowing for standardization of the protocols used in different laboratories and comparisons of the behavioral phenotypes of various strains of mutant mice assessed using this test.
The software that takes the video data and transforms it into various representations allows the researchers to collect data on mouse behavior more reliably. For instance, the distance traveled across the arms of the apparatus or the time spent on each arm would have been difficult to observe and record precisely. A further aspect to note is how the visualization of the experiment facilitates control of bias. The authors illustrate how the olfactory bias between experimental procedures carried on mice in sequence is avoided by cleaning the equipment.
Our discussion highlights the role of visualization in science, particularly with respect to presenting visualization as part of the scientific practices. We have used case studies from the history of science highlighting a scientist’s account of how visualization played a role in the discovery of DNA and the magnetic field and from a contemporary illustration of a science journal’s practices in incorporating visualization as a way to communicate new findings and methodologies. Our implicit aim in drawing from these case studies was the need to align science education with scientific practices, particularly in terms of how visual representations, stable or dynamic, can engage students in the processes of science and not only to be used as tools for cognitive development in science. Our approach was guided by the notion of “knowledge-as-practice” as advanced by Knorr Cetina ( 1999 ) who studied scientists and characterized their knowledge as practice, a characterization which shifts focus away from ideas inside scientists’ minds to practices that are cultural and deeply contextualized within fields of science. She suggests that people working together can be examined as epistemic cultures whose collective knowledge exists as practice.
It is important to stress, however, that visual representations are not used in isolation, but are supported by other types of evidence as well, or other theories (i.e., in order to understand the helical form of DNA, or the structure, chemistry knowledge was needed). More importantly, this finding can also have implications when teaching science as argument (e.g., Erduran and Jimenez-Aleixandre 2008 ), since the verbal evidence used in the science classroom to maintain an argument could be supported by visual evidence (either a model, representation, image, graph, etc.). For example, in a group of students discussing the outcomes of an introduced species in an ecosystem, pictures of the species and the ecosystem over time, and videos showing the changes in the ecosystem, and the special characteristics of the different species could serve as visual evidence to help the students support their arguments (Evagorou et al. 2012 ). Therefore, an important implication for the teaching of science is the use of visual representations as evidence in the science curriculum as part of knowledge production. Even though studies in the area of science education have focused on the use of models and modeling as a way to support students in the learning of science (Dori et al. 2003 ; Lehrer and Schauble 2012 ; Mendonça and Justi 2013 ; Papaevripidou et al. 2007 ) or on the use of images (i.e., Korfiatis et al. 2003 ), with the term using visuals as evidence, we refer to the collection of all forms of visuals and the processes involved.
Another aspect that was identified through the case studies is that of the visual reasoning (an integral part of Faraday’s investigations). Both the verbalization and visualization were part of the process of generating new knowledge (Gooding 2006 ). Even today, most of the textbooks use the lines of force (or just field lines) as a geometrical representation of field, and the number of field lines is connected to the quantity of flux. Often, the textbooks use the same kind of visual imagery than in what is used by scientists. However, when using images, only certain aspects or features of the phenomena or data are captured or highlighted, and often in tacit ways. Especially in textbooks, the process of producing the image is not presented and instead only the product—image—is left. This could easily lead to an idea of images (i.e., photos, graphs, visual model) being just representations of knowledge and, in the worse case, misinterpreted representations of knowledge as the results of Pocovi and Finlay ( 2002 ) in case of electric field lines show. In order to avoid this, the teachers should be able to explain how the images are produced (what features of phenomena or data the images captures, on what ground the features are chosen to that image, and what features are omitted); in this way, the role of visualization in knowledge production can be made “visible” to students by engaging them in the process of visualization.
The implication of these norms for science teaching and learning is numerous. The classroom contexts can model the generation, sharing and evaluation of evidence, and experimental procedures carried out by students, thereby promoting not only some contemporary cultural norms in scientific practice but also enabling the learning of criteria, standards, and heuristics that scientists use in making decisions on scientific methods. As we have demonstrated with the three case studies, visual representations are part of the process of knowledge growth and communication in science, as demonstrated with two examples from the history of science and an example from current scientific practices. Additionally, visual information, especially with the use of technology is a part of students’ everyday lives. Therefore, we suggest making use of students’ knowledge and technological skills (i.e., how to produce their own videos showing their experimental method or how to identify or provide appropriate visual evidence for a given topic), in order to teach them the aspects of the nature of science that are often neglected both in the history of science and the design of curriculum. Specifically, what we suggest in this paper is that students should actively engage in visualization processes in order to appreciate the diverse nature of doing science and engage in authentic scientific practices.
However, as a word of caution, we need to distinguish the products and processes involved in visualization practices in science:
If one considers scientific representations and the ways in which they can foster or thwart our understanding, it is clear that a mere object approach, which would devote all attention to the representation as a free-standing product of scientific labor, is inadequate. What is needed is a process approach: each visual representation should be linked with its context of production (Pauwels 2006 , p.21).
The aforementioned suggests that the emphasis in visualization should shift from cognitive understanding—using the products of science to understand the content—to engaging in the processes of visualization. Therefore, an implication for the teaching of science includes designing curriculum materials and learning environments that create a social and epistemic context and invite students to engage in the practice of visualization as evidence, reasoning, experimental procedure, or a means of communication (as presented in the three case studies) and reflect on these practices (Ryu et al. 2015 ).
Finally, a question that arises from including visualization in science education, as well as from including scientific practices in science education is whether teachers themselves are prepared to include them as part of their teaching (Bybee 2014 ). Teacher preparation programs and teacher education have been critiqued, studied, and rethought since the time they emerged (Cochran-Smith 2004 ). Despite the years of history in teacher training and teacher education, the debate about initial teacher training and its content still pertains in our community and in policy circles (Cochran-Smith 2004 ; Conway et al. 2009 ). In the last decades, the debate has shifted from a behavioral view of learning and teaching to a learning problem—focusing on that way not only on teachers’ knowledge, skills, and beliefs but also on making the connection of the aforementioned with how and if pupils learn (Cochran-Smith 2004 ). The Science Education in Europe report recommended that “Good quality teachers, with up-to-date knowledge and skills, are the foundation of any system of formal science education” (Osborne and Dillon 2008 , p.9).
However, questions such as what should be the emphasis on pre-service and in-service science teacher training, especially with the new emphasis on scientific practices, still remain unanswered. As Bybee ( 2014 ) argues, starting from the new emphasis on scientific practices in the NGSS, we should consider teacher preparation programs “that would provide undergraduates opportunities to learn the science content and practices in contexts that would be aligned with their future work as teachers” (p.218). Therefore, engaging pre- and in-service teachers in visualization as a scientific practice should be one of the purposes of teacher preparation programs.
Achieve. (2013). The next generation science standards (pp. 1–3). Retrieved from http://www.nextgenscience.org/ .
Google Scholar
Barber, J, Pearson, D, & Cervetti, G. (2006). Seeds of science/roots of reading . California: The Regents of the University of California.
Bungum, B. (2008). Images of physics: an explorative study of the changing character of visual images in Norwegian physics textbooks. NorDiNa, 4 (2), 132–141.
Bybee, RW. (2014). NGSS and the next generation of science teachers. Journal of Science Teacher Education, 25 (2), 211–221. doi: 10.1007/s10972-014-9381-4 .
Article Google Scholar
Chambers, D. (1983). Stereotypic images of the scientist: the draw-a-scientist test. Science Education, 67 (2), 255–265.
Cochran-Smith, M. (2004). The problem of teacher education. Journal of Teacher Education, 55 (4), 295–299. doi: 10.1177/0022487104268057 .
Conway, PF, Murphy, R, & Rath, A. (2009). Learning to teach and its implications for the continuum of teacher education: a nine-country cross-national study .
Crick, F. (1988). What a mad pursuit . USA: Basic Books.
Dimopoulos, K, Koulaidis, V, & Sklaveniti, S. (2003). Towards an analysis of visual images in school science textbooks and press articles about science and technology. Research in Science Education, 33 , 189–216.
Dori, YJ, Tal, RT, & Tsaushu, M. (2003). Teaching biotechnology through case studies—can we improve higher order thinking skills of nonscience majors? Science Education, 87 (6), 767–793. doi: 10.1002/sce.10081 .
Duschl, RA, & Bybee, RW. (2014). Planning and carrying out investigations: an entry to learning and to teacher professional development around NGSS science and engineering practices. International Journal of STEM Education, 1 (1), 12. doi: 10.1186/s40594-014-0012-6 .
Duschl, R., Schweingruber, H. A., & Shouse, A. (2008). Taking science to school . Washington DC: National Academies Press.
Erduran, S, & Jimenez-Aleixandre, MP (Eds.). (2008). Argumentation in science education: perspectives from classroom-based research . Dordrecht: Springer.
Eurydice. (2012). Developing key competencies at school in Europe: challenges and opportunities for policy – 2011/12 (pp. 1–72).
Evagorou, M, Jimenez-Aleixandre, MP, & Osborne, J. (2012). “Should we kill the grey squirrels?” A study exploring students’ justifications and decision-making. International Journal of Science Education, 34 (3), 401–428. doi: 10.1080/09500693.2011.619211 .
Faraday, M. (1852a). Experimental researches in electricity. – Twenty-eighth series. Philosophical Transactions of the Royal Society of London, 142 , 25–56.
Faraday, M. (1852b). Experimental researches in electricity. – Twenty-ninth series. Philosophical Transactions of the Royal Society of London, 142 , 137–159.
Gilbert, JK. (2010). The role of visual representations in the learning and teaching of science: an introduction (pp. 1–19).
Gilbert, J., Reiner, M. & Nakhleh, M. (2008). Visualization: theory and practice in science education . Dordrecht, The Netherlands: Springer.
Gooding, D. (2006). From phenomenology to field theory: Faraday’s visual reasoning. Perspectives on Science, 14 (1), 40–65.
Gooding, D, Pinch, T, & Schaffer, S (Eds.). (1993). The uses of experiment: studies in the natural sciences . Cambridge: Cambridge University Press.
Hogan, K, & Maglienti, M. (2001). Comparing the epistemological underpinnings of students’ and scientists’ reasoning about conclusions. Journal of Research in Science Teaching, 38 (6), 663–687.
Knorr Cetina, K. (1999). Epistemic cultures: how the sciences make knowledge . Cambridge: Harvard University Press.
Korfiatis, KJ, Stamou, AG, & Paraskevopoulos, S. (2003). Images of nature in Greek primary school textbooks. Science Education, 88 (1), 72–89. doi: 10.1002/sce.10133 .
Latour, B. (2011). Visualisation and cognition: drawing things together (pp. 1–32).
Latour, B, & Woolgar, S. (1979). Laboratory life: the construction of scientific facts . Princeton: Princeton University Press.
Lehrer, R, & Schauble, L. (2012). Seeding evolutionary thinking by engaging children in modeling its foundations. Science Education, 96 (4), 701–724. doi: 10.1002/sce.20475 .
Longino, H. E. (2002). The fate of knowledge . Princeton: Princeton University Press.
Lynch, M. (2006). The production of scientific images: vision and re-vision in the history, philosophy, and sociology of science. In L Pauwels (Ed.), Visual cultures of science: rethinking representational practices in knowledge building and science communication (pp. 26–40). Lebanon, NH: Darthmouth College Press.
Lynch, M. & S. Y. Edgerton Jr. (1988). ‘Aesthetic and digital image processing representational craft in contemporary astronomy’, in G. Fyfe & J. Law (eds), Picturing Power; Visual Depictions and Social Relations (London, Routledge): 184 – 220.
Mendonça, PCC, & Justi, R. (2013). An instrument for analyzing arguments produced in modeling-based chemistry lessons. Journal of Research in Science Teaching, 51 (2), 192–218. doi: 10.1002/tea.21133 .
National Research Council (2000). Inquiry and the national science education standards . Washington DC: National Academies Press.
National Research Council (2012). A framework for K-12 science education . Washington DC: National Academies Press.
Nersessian, NJ. (1984). Faraday to Einstein: constructing meaning in scientific theories . Dordrecht: Martinus Nijhoff Publishers.
Book Google Scholar
Nersessian, NJ. (1992). How do scientists think? Capturing the dynamics of conceptual change in science. In RN Giere (Ed.), Cognitive Models of Science (pp. 3–45). Minneapolis: University of Minnesota Press.
Nersessian, NJ. (2008). Creating scientific concepts . Cambridge: The MIT Press.
Osborne, J. (2014). Teaching scientific practices: meeting the challenge of change. Journal of Science Teacher Education, 25 (2), 177–196. doi: 10.1007/s10972-014-9384-1 .
Osborne, J. & Dillon, J. (2008). Science education in Europe: critical reflections . London: Nuffield Foundation.
Papaevripidou, M, Constantinou, CP, & Zacharia, ZC. (2007). Modeling complex marine ecosystems: an investigation of two teaching approaches with fifth graders. Journal of Computer Assisted Learning, 23 (2), 145–157. doi: 10.1111/j.1365-2729.2006.00217.x .
Pauwels, L. (2006). A theoretical framework for assessing visual representational practices in knowledge building and science communications. In L Pauwels (Ed.), Visual cultures of science: rethinking representational practices in knowledge building and science communication (pp. 1–25). Lebanon, NH: Darthmouth College Press.
Philips, L., Norris, S. & McNab, J. (2010). Visualization in mathematics, reading and science education . Dordrecht, The Netherlands: Springer.
Pocovi, MC, & Finlay, F. (2002). Lines of force: Faraday’s and students’ views. Science & Education, 11 , 459–474.
Richards, A. (2003). Argument and authority in the visual representations of science. Technical Communication Quarterly, 12 (2), 183–206. doi: 10.1207/s15427625tcq1202_3 .
Rothbart, D. (1997). Explaining the growth of scientific knowledge: metaphors, models and meaning . Lewiston, NY: Mellen Press.
Ruivenkamp, M, & Rip, A. (2010). Visualizing the invisible nanoscale study: visualization practices in nanotechnology community of practice. Science Studies, 23 (1), 3–36.
Ryu, S, Han, Y, & Paik, S-H. (2015). Understanding co-development of conceptual and epistemic understanding through modeling practices with mobile internet. Journal of Science Education and Technology, 24 (2-3), 330–355. doi: 10.1007/s10956-014-9545-1 .
Sarkar, S, & Pfeifer, J. (2006). The philosophy of science, chapter on experimentation (Vol. 1, A-M). New York: Taylor & Francis.
Schwartz, RS, Lederman, NG, & Abd-el-Khalick, F. (2012). A series of misrepresentations: a response to Allchin’s whole approach to assessing nature of science understandings. Science Education, 96 (4), 685–692. doi: 10.1002/sce.21013 .
Schwarz, CV, Reiser, BJ, Davis, EA, Kenyon, L, Achér, A, Fortus, D, et al. (2009). Developing a learning progression for scientific modeling: making scientific modeling accessible and meaningful for learners. Journal of Research in Science Teaching, 46 (6), 632–654. doi: 10.1002/tea.20311 .
Watson, J. (1968). The Double Helix: a personal account of the discovery of the structure of DNA . New York: Scribner.
Watson, J, & Berry, A. (2004). DNA: the secret of life . New York: Alfred A. Knopf.
Wickman, PO. (2004). The practical epistemologies of the classroom: a study of laboratory work. Science Education, 88 , 325–344.
Wu, HK, & Shah, P. (2004). Exploring visuospatial thinking in chemistry learning. Science Education, 88 (3), 465–492. doi: 10.1002/sce.10126 .
Download references
Acknowledgements
The authors would like to acknowledge all reviewers for their valuable comments that have helped us improve the manuscript.
Author information
Authors and affiliations.
University of Nicosia, 46, Makedonitissa Avenue, Egkomi, 1700, Nicosia, Cyprus
Maria Evagorou
University of Limerick, Limerick, Ireland
Sibel Erduran
University of Tampere, Tampere, Finland
Terhi Mäntylä
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Maria Evagorou .
Additional information
Competing interests.
The authors declare that they have no competing interests.
Authors’ contributions
ME carried out the introductory literature review, the analysis of the first case study, and drafted the manuscript. SE carried out the analysis of the third case study and contributed towards the “Conclusions” section of the manuscript. TM carried out the second case study. All authors read and approved the final manuscript.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License ( https://creativecommons.org/licenses/by/4.0 ), which permits use, duplication, adaptation, distribution, and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Reprints and permissions
About this article
Cite this article.
Evagorou, M., Erduran, S. & Mäntylä, T. The role of visual representations in scientific practices: from conceptual understanding and knowledge generation to ‘seeing’ how science works. IJ STEM Ed 2 , 11 (2015). https://doi.org/10.1186/s40594-015-0024-x
Download citation
Received : 29 September 2014
Accepted : 16 May 2015
Published : 19 July 2015
DOI : https://doi.org/10.1186/s40594-015-0024-x
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Visual representations
- Epistemic practices
- Science learning

- Contributors
- Links
- Translations
- What is Gendered Innovations ?
Sex & Gender Analysis
- Research Priorities
- Rethinking Concepts
- Research Questions
- Analyzing Sex
- Analyzing Gender
- Sex and Gender Interact
- Intersectional Approaches
- Engineering Innovation
- Participatory Research
- Reference Models
- Language & Visualizations
- Tissues & Cells
- Lab Animal Research
- Sex in Biomedicine
- Gender in Health & Biomedicine
- Evolutionary Biology
- Machine Learning
- Social Robotics
- Hermaphroditic Species
- Impact Assessment
- Norm-Critical Innovation
- Intersectionality
- Race and Ethnicity
- Age and Sex in Drug Development
- Engineering
- Health & Medicine
- SABV in Biomedicine
- Tissues & Cells
- Urban Planning & Design
Case Studies
- Animal Research
- Animal Research 2
- Computer Science Curriculum
- Genetics of Sex Determination
- Chronic Pain
- Colorectal Cancer
- De-Gendering the Knee
- Dietary Assessment Method
- Heart Disease in Diverse Populations
- Medical Technology
- Nanomedicine
- Nanotechnology-Based Screening for HPV
- Nutrigenomics
- Osteoporosis Research in Men
- Prescription Drugs
- Systems Biology
- Assistive Technologies for the Elderly
- Domestic Robots
- Extended Virtual Reality
- Facial Recognition
- Gendering Social Robots
- Haptic Technology
- HIV Microbicides
- Inclusive Crash Test Dummies
- Human Thorax Model
- Machine Translation
- Making Machines Talk
- Video Games
- Virtual Assistants and Chatbots
- Agriculture
- Climate Change
- Environmental Chemicals
- Housing and Neighborhood Design
- Marine Science
- Menstrual Cups
- Population and Climate Change
- Quality Urban Spaces
- Smart Energy Solutions
- Smart Mobility
- Sustainable Fashion
- Waste Management
- Water Infrastructure
- Intersectional Design
- Major Granting Agencies
- Peer-Reviewed Journals
- Universities
Rethinking Language and Visual Representations
Language and visual representations are central to all knowledge-based activities, including those in science, health & medicine, and engineering. Word choice, charts, graphs, images, and icons have the power to shape scientific practice, questions asked, results obtained, and interpretations made. “Sharing a language means sharing a conceptual universe” within which assumptions, judgments, and interpretations of data can be said to “make sense” (Keller, 1992). Rethinking language also involves Rethinking Concepts and Theories.
Rethinking language and visual representations can:
- 1. Remove assumptions that may limit or restrict innovation and knowledge in unconscious ways.
- 2. Remove assumptions that unconsciously reinforce gender inequalities.
Consider the following examples:
- ● Unintended hypothesis-creating metaphors. Analogies and metaphors function to construct as well as describe. They have both a hypothesis-creating and proof-making function. By analyzing language—by “waking up” metaphors—we can critically judge how the imagery may be lending structure to our research (Martin, 1992; Martin, 1991). For example, zoologists often refer to herds of animals (horses, antelope, elephant seals, etc.) as “harems.” The word “harem” embeds assumptions about social organization, in this case polygyny. In this example, researchers failed to “see” what lies outside the logic of the metaphor. Recent DNA studies of mustangs show, however, that a given stallion typically sires less than a third of the foals in a band. Researchers who questioned the notion of a “harem” found that female mustangs range from band to band, often mating with a stallion of their choice (Brown, 1995). Other scholars have shown how the metaphor of the “cell as a factory” works to naturalize patriarchal norms in which the male “head” (coded as the nucleus) controls the domestic labor of women (Navare, 2023).
- ♦ In English, new words have been devised and usage altered to be more inclusive. For example, “fireman” has been replaced with “fire fighter,” “infantrymen” are now “soldiers,” and “animal husbandry” can be replaced with the more neutral “animal breeding and care.” Some old terms such as “aviatrix” and “lady doctor” have completely disappeared.
- ♦ In English, “they” should be used rather than the generic “he” when referring to a researcher, subject, or student whose gender is unknown. Many dictionaries now accept “they” as a singular, gender-neutral pronoun, or the sentence can be recast in the plural to avoid specific referents.
Visual Representations
Visual representations in science, medicine and engineering may contain gender-inflected messages in 1) the content of a field or discipline, or 2) the practitioners of a field or discipline. Consider the following:
- ● Visual Display of Data
- Visual displays of data may embed gender assumptions. As discussed in the case study on Public Transportation, the charts below represent trips made in Madrid in 2014. The first chart (left below) graphs transportation data as traditionally collected and reported. It privileges paid employment by presenting it as a single, large category. Caring work (shown in red) is divided into numerous small categories and hidden under other headings, such as escorting, shopping and leisure. The second chart (right) reconceptualizes public transportation trips by collecting care trips under one category. Visualizing care trips in one dedicated category emphasizes the importance of caring work and allows transportation engineers to design systems that work well for all segments of the population, improve urban efficiency, and guard against global warming (Sánchez de Madariaga, 2013, 2019).

- ● How might metaphors be gendered and create unintended hypotheses?
- ● Do gendered metaphors reinforce stereotypes?
- ● Are word choices or naming practices gendered?
- ● Do naming practices or pronoun choices exclude gender-diverse individuals?
- ● How does nomenclature influence who becomes a scientist or engineer?
- ● Are the language and images being used gender inclusive?
- ● Are graphs, charts, or images used to visualize abstract concepts gendered in unintended ways?
- ● Does a particular field of science or engineering promote a self-image that carries messages about the “gender appropriateness” of participation by women, men, and gender-diverse people?
- ● Are problem sets or training exercises chosen to illustrate basic scientific principles gendered in unintended ways?
Related Case Studies
Works cited.
Brown, N. (1995). The Wild Mares of Assateague. Research at Pennsylvania State University, 16, 15-19.
Christidou, V., & Kouvatas, A. (2011). Visual Self-Images of Scientists and Science in Greece. Public Understanding of Science, (Online in Advance of Print).
Keller, E. (1992). Secrets of Life, Secrets of Death: Essays on Language, Gender and Science . New York: Routledge. The European Journal of Women's Studies, 2 (3) , 379-394.
Lie, M. (1998). Computer Dialogues: Technology, Gender, and Change . Trondheim: Senter for kvinneforskning, Norges Teknisk-naturvitenskapelige Universitet.
Martin, E. (1992). The Woman in the Body: A Cultural Analysis of Reproduction . Boston: Beacon.
Martin, E. (1991). The egg and the sperm: How science has constructed a romance based on stereotypical male-female roles. Signs: Journal of Women in Culture and Society, 16 (3), 485-501.
Ministerio de Fomento. (2007). Encuesta de Movilidad de las Personas Residentes en España (Movilia 2006/2007) . Madrid: Ministerio de Fomento.
Navare, C. (2023). Instructions, commands, and coercive control: A critical discourse analysis of the textbook representation of the living cell. Cultural Studies of Science Education.
Sánchez de Madariaga, I. (2013). The Mobility of Care: A New Concept in Urban Transportation. In Sánchez de Madariaga, I., & Roberts, M. (Eds.) Fair Share Cities. The Impact of Gender Planning in Europe. London: Ashgate.
Sánchez de Madariaga, I. (2009). Vivienda, Movilidad, y Urbanismo para la Igualdad en la Diversidad: Ciudades, Género, y Dependencia. Ciudad y Territorio Estudios Territoriales, XLI (161-162), 581-598.
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Pre-trained representations are becoming crucial for many NLP and perception tasks. While representation learning in NLP has transitioned to training on raw text without human annotations, visual and vision-language representations still rely heavily on curated training datasets that are expensive or require expert knowledge. For vision applications, representations are mostly learned using datasets with explicit class labels such as ImageNet or OpenImages. For vision-language, popular datasets like Conceptual Captions, MSCOCO, or CLIP all involve a non-trivial data collection (and cleaning) process. This costly curation process limits the size of datasets and hence hinders the scaling of trained models. In this paper, we leverage a noisy dataset of over one billion image alt-text pairs, obtained without expensive filtering or post-processing steps in the Conceptual Captions dataset. A simple dual-encoder architecture learns to align visual and language representations of the image and text pairs using a contrastive loss. We show that the scale of our corpus can make up for its noise and leads to state-of-the-art representations even with such a simple learning scheme. Our visual representation achieves strong performance when transferred to classification tasks such as ImageNet and VTAB. The aligned visual and language representations enables zero-shot image classification and also set new state-of-the-art results on Flickr30K and MSCOCO image-text retrieval benchmarks, even when compared with more sophisticated cross-attention models. The representations also enable cross-modality search with complex text and text + image queries.

1 Introduction
In the existing literature, visual and vision-language representation learning are mostly studied separately with different training data sources. In the vision domain, pre-training on large-scale supervised data such as ImageNet (Deng et al., 2009 ) , OpenImages (Kuznetsova et al., 2020 ) , and JFT-300M (Sun et al., 2017 ; Kolesnikov et al., 2020 ) has proven to be critical for improving performance on downstream tasks via transfer learning. Curation of such pre-training datasets requires heavy work on data gathering, sampling, and human annotation, and hence is difficult to scale.
Pre-training has also become the de-facto approach in vision-language modeling (Lu et al., 2019 ; Chen et al., 2020c ; Li et al., 2020 ) . However, vision-language pre-training datasets such as Conceptual Captions (Sharma et al., 2018 ) , Visual Genome Dense Captions (Krishna et al., 2016 ) , and ImageBERT (Qi et al., 2020 ) require even heavier work on human annotation, semantic parsing, cleaning and balancing. As a result, the scales of these datasets are only in the realm of ∼ similar-to \sim 10M examples. This is at least an order of magnitude smaller than their counterparts in the vision domain, and much smaller than large corpora of text from the internet for NLP pre-training (e.g., Devlin et al. ( 2019 ); Radford et al. ( 2019 ); Yang et al. ( 2019 ); Liu et al. ( 2019b ); Raffel et al. ( 2020 ) ).
In this work, we leverage a dataset of over one billion noisy image alt-text pairs to scale visual and vision-language representation learning. We follow the procedures described in the Conceptual Captions dataset (Sharma et al., 2018 ) to have a large noisy dataset. But instead of applying the complex filtering and post-processing steps as proposed by (Sharma et al., 2018 ) to clean the dataset, we only apply simple frequency-based filtering. The resulting dataset is noisy, but is two orders of magnitude larger than the Conceptual Captions dataset. We show that visual and vision-language representations pre-trained on our exascale dataset achieve very strong performance on a wide range of tasks.
To train our model, we use an objective that aligns the visual and language representations in a shared latent embedding space using a simple dual-encoder architecture. Similar objectives has been applied to learning visual-semantic embeddings (VSE) (Frome et al., 2013 ; Faghri et al., 2018 ) . We name our model ALIGN : A L arge-scale I ma G e and N oisy-text embedding. Image and text encoders are learned via a contrastive loss (formulated as normalized softmax) that pushes the embeddings of matched image-text pair together while pushing those of non-matched image-text pair apart. This is one of the most effective loss functions for both self-supervised (Chen et al., 2020b ) and supervised (Zhai & Wu, 2019 ; Musgrave et al., 2020 ) representation learning. Considering paired texts as fine-grained labels of images, our image-to-text contrastive loss is analogous to the conventional label-based classification objective; and the key difference is that the text encoder generates the “label” weights. The top-left of Figure 1 summarizes the method we use in ALIGN.
The aligned image and text representations are naturally suited for cross-modality matching/retrieval tasks and achieve state-of-the-art (SOTA) results in corresponding benchmarks. For instance, ALIGN outperforms the previous SOTA method by over 7% in most zero-shot and fine-tuned R@1 metrics in Flickr30K and MSCOCO. Moreover, such cross-modality matching naturally enables zero-shot image classification when feeding the classnames into the text encoder, achieving 76.4% top-1 accuracy in ImageNet without using any of its training samples. The image representation itself also achieves superior performance in various downstream visual tasks. For example, ALIGN achieves 88.64% top-1 accuracy in ImageNet. Figure 1 -bottom shows the cross-modal retrieval examples that come from a real retrieval system built by ALIGN.
2 Related Work
High-quality visual representations for classification or retrieval are usually pre-trained on large-scale labeled datasets (Mahajan et al., 2018 ; Kolesnikov et al., 2020 ; Dosovitskiy et al., 2021 ; Juan et al., 2020 ) . Recently, self-supervised (Chen et al., 2020b ; Tian et al., 2020 ; He et al., 2020 ; Misra & Maaten, 2020 ; Li et al., 2021 ; Grill et al., 2020 ; Caron et al., 2020 ) and semi-supervised learning (Yalniz et al., 2019 ; Xie et al., 2020 ; Pham et al., 2020 ) have been studied as alternative paradigms. However, models trained by these methods so far show limited transferability to downstream tasks (Zoph et al., 2020 ) .
Leveraging images and natural language captions is another direction of learning visual representations. Joulin et al. ( 2015 ); Li et al. ( 2017 ); Desai & Johnson ( 2020 ); Sariyildiz et al. ( 2020 ); Zhang et al. ( 2020 ) show that a good visual representation can be learned by predicting the captions from images, which inspires our work. These works are however limited to small datasets such as Flickr (Joulin et al., 2015 ; Li et al., 2017 ) and COCO Captions (Desai & Johnson, 2020 ; Sariyildiz et al., 2020 ) , and the resulting models don’t produce a vision-language representation that is needed for tasks like cross-modal retrieval.
In the vision-language representation learning domain, visual-semantic embeddings (VSE) (Frome et al., 2013 ; Faghri et al., 2018 ) and improved versions (e.g., leveraging object detectors, dense feature maps, or multi-attention layers) (Socher et al., 2014 ; Karpathy et al., 2014 ; Kiros et al., ; Nam et al., 2017 ; Li et al., 2019 ; Messina et al., 2020 ; Chen et al., 2020a ) have been proposed. Recently more advanced models emerge with cross-modal attention layers (Liu et al., 2019a ; Lu et al., 2019 ; Chen et al., 2020c ; Huang et al., 2020b ) and show superior performance in image-text matching tasks. However, they are orders of magnitudes slower and hence impractical for image-text retrieval systems in the real world. In contrast, our model inherits the simplest VSE form, but still outperforms all previous cross-attention models in image-text matching benchmarks.
Closely related to our work is CLIP (Radford et al., 2021 ) , which proposes visual representation learning via natural language supervision in a similar contrastive learning setting. Besides using different vision and language encoder architectures, the key difference is on training data: ALIGN follows the natural distribution of image-text pairs from the raw alt-text data, while CLIP collects the dataset by first constructing an allowlist of high-frequency visual concepts from English Wikipedia. We demonstrate that strong visual and vision-language representations can be learned with a dataset that doesn’t require expert knowledge to curate.
3 A Large-Scale Noisy Image-Text Dataset
The focus of our work is to scale up visual and vision-language representation learning. For this purpose, we resort to a much larger dataset than existing ones. Specifically, we follow the methodology of constructing Conceptual Captions dataset (Sharma et al., 2018 ) to get a version of raw English alt-text data (image and alt-text pairs). The Conceptual Captions dataset was cleaned by heavy filtering and post-processing. Here, for the purpose of scaling, we trade quality for scale by relaxing most of the cleaning steps in the original work. Instead, we only apply minimal frequency-based filtering as detailed below. The result is a much larger (1.8B image-text pairs) but noisier dataset. Figure 2 shows some sample image-text pairs from the dataset.

Image-based filtering.
Following Sharma et al. ( 2018 ) , we remove pornographic images and keep only images whose shorter dimension is larger than 200 pixels and aspect ratio is smaller than 3. Images with more than 1000 associated alt-texts are discarded. To ensure that we don’t train on test images, we also remove duplicates or near-duplicates of test images in all downstream evaluation datasets (e.g., ILSVRC-2012, Flickr30K, and MSCOCO). See Appendix A for more details.
Text-based filtering.
We exclude alt-texts that are shared by more than 10 images. These alt-texts are often irrelevant to the content of the images (e.g., “1920x1080”, “alt_img”, and “cristina”). We also discard alt-texts that contain any rare token (outside of 100 million most frequent unigrams and bigrams from the raw dataset), and those that are either too short ( < < 3 unigrams) or too long ( > > 20 unigrams). This removes noisy texts like “image_tid 25&id mggqpuweqdpd&cache 0&lan_code 0”, or texts that are too generic to be useful.
4 Pre-training and Task Transfer
4.1 pre-training on noisy image-text pairs.
We pre-train ALIGN using a dual-encoder architecture. The model consists of a pair of image and text encoders with a cosine-similarity combination function at the top. We use EfficientNet with global pooling (without training the 1x1 conv layer in the classification head) as the image encoder and BERT with [CLS] token embedding as the text embedding encoder (we generate 100k wordpiece vocabulary from our training dataset). A fully-connected layer with linear activation is added on top of BERT encoder to match the dimension from the image tower. Both image and text encoders are trained from scratch.
The image and text encoders are optimized via normalized softmax loss (Zhai & Wu, 2019 ) . In training, we treat matched image-text pairs as positive and all other random image-text pairs that can be formed in a training batch as negative.
We minimize the sum of two losses: one for image-to-text classification
and the other for text-to-image classification
Here, x i subscript 𝑥 𝑖 x_{i} and y j subscript 𝑦 𝑗 y_{j} are the normalized embedding of image in the i 𝑖 i -th pair and that of text in the j 𝑗 j -th pair, respectively. N 𝑁 N is the batch size, and σ 𝜎 \sigma is the temperature to scale the logits. For in-batch negatives to be more effective, we concatenate embeddings from all computing cores to form a much larger batch. The temperature variable is crucial as both image and text embeddings are L2-normalized. Instead of manually sweeping for the optimal temperature value, we find that it can be effectively learned together with all the other parameters.
4.2 Transferring to Image-Text Matching & Retrieval
We evaluate ALIGN models on image-to-text and text-to-image retrieval tasks, with and without finetuning. Two benchmark datasets are considered: Flickr30K (Plummer et al., 2015 ) and MSCOCO (Chen et al., 2015 ) . We also evaluate ALIGN on Crisscrossed Captions (CxC) (Parekh et al., 2021 ) , which is an extension of MSCOCO with additional human semantic similarity judgments for caption-caption, image-image, and image-caption pairs. With extended annotations, CxC enables four intra- and inter-modal retrieval tasks including image-to-text, text-to-image, text-to-text, and image-to-image retrieval, and three semantic similarity tasks including semantic textual similarity (STS), semantic image similarity (SIS), and semantic image-text similarity (SITS). As the training set is identical to the original MSCOCO, we can directly evaluate the MSCOCO fine-tuned ALIGN model on CxC annotations.
4.3 Transferring to Visual Classification
We first apply zero-shot transfer of ALIGN to visual classification tasks on ImageNet ILSVRC-2012 benchmark (Deng et al., 2009 ) and its variants including ImageNet-R(endition) (Hendrycks et al., 2020 ) (non-natural images such as art, cartoons, sketches), ImageNet-A(dversarial) (Hendrycks et al., 2021 ) (more challenging images for ML models), and ImageNet-V2 (Recht et al., 2019 ) . All of these variants follow the same set (or a subset) of ImageNet classes, while the images in ImageNet-R and ImageNet-A are sampled from drastically different distributions from ImageNet.
We also transfer the image encoder to downstream visual classification tasks. For this purpose, we use the ImageNet as well as a handful of smaller fine-grained classification datasets such as Oxford Flowers-102 (Nilsback & Zisserman, 2008 ) , Oxford-IIIT Pets (Parkhi et al., 2012 ) , Stanford Cars (Krause et al., 2013 ) , and Food101 (Bossard et al., 2014 ) . For ImageNet, results from two settings are reported: training the top classification layer only (with frozen ALIGN image encoder) and fully fine-tuned. Only the latter setting is reported for fine-grained classification benchmarks. Following Kolesnikov et al. ( 2020 ) , we also evaluate the robustness of our model on Visual Task Adaptation Benchmark (VTAB) (Zhai et al., 2019 ) which consists of 19 diverse (covering subgroups of natural, specialized and structured image classification tasks) visual classification tasks with 1000 training samples each.
5 Experiments and Results
We train our ALIGN models from scratch, using the open-sourced implementation of EfficientNet as the image encoder and BERT as the text encoder. Unless in the ablation study, we use the results of ALIGN where the image encoder is EfficientNet-L2 and the text encoder is BERT-Large. The image encoder is trained at resolution of 289 × \times 289 pixels no matter what EfficientNet variant is used. We first resize input images to 346 × \times 346 resolution and then perform random crop (with additional random horizontal flip) in training and central crop in evaluation. For BERT we use wordpiece sequence of maximum 64 tokens since the input texts are no longer than 20 unigrams. The softmax temperature variable is initialized as 1.0 (this temperature variable is shared between image-to-text loss and text-to-image loss) and we use 0.1 as label smoothing parameter in the softmax losses. We use LAMB optimizer (You et al., 2020 ) 1 1 1 We tried SGD with momentum and ADAM which are known to work well for CNNs and BERT respectively. LAMB appears to be a better choice for training both image and text encoders. with weight decay ratio 1e-5. The learning rate is warmed up linearly to 1e-3 from zero in 10k steps, and then linearly decay to zero in 1.2M steps ( ∼ similar-to \sim 12 epochs). We train the model on 1024 Cloud TPUv3 cores with 16 positive pairs on each core. Therefore the total effective batch size is 16384.
5.1 Image-Text Matching & Retrieval
We evaluate ALIGN on Flickr30K and MSCOCO cross-modal retrieval benchmarks, in both zero-shot and fully fine-tuned settings. We follow (Karpathy & Fei-Fei, 2015 ) and most existing works to obtain the train/test splits. Specifically, for Flickr30K, we evaluate on the standard 1K test set, and finetune on the 30k training set. For MSCOCO, we evaluate on the 5K test set, and finetune on 82K training plus 30K additional validation images that are not in the 5K validation or 5K test sets.
During fine-tuning, the same loss function is used. But there can be false negatives when the batch size is comparable to the total number of training samples. So we reduce the global batch size from 16384 to 2048. We also reduce the initial learning rate to 1e-5 and train for 3K and 6K steps (with linear decay) respectively on Flickr30K and MSCOCO. All the other hyper-parameters are kept the same as pre-training.
Table 1 shows that, compared to previous works, ALIGN achieves SOTA results in all metrics of Flickr30K and MSCOCO benchmarks. In the zero-shot setting, ALIGN gets more than 7% improvement in image retrieval task compared to the previous SOTA, CLIP (Radford et al., 2021 ) . With fine-tuning, ALIGN outperforms all existing methods by a large margin, including those that employ more complex cross-modal attention layers such as ImageBERT (Qi et al., 2020 ) , UNITER (Chen et al., 2020c ) , ERNIE-ViL (Yu et al., 2020 ) , VILLA (Gan et al., 2020 ) and Oscar (Li et al., 2020 ) .
Table 2 reports the performance of ALIGN on Crisscrossed Captions (CxC) retrieval tasks. Again, ALIGN achieves SOTA results in all metrics, especially by a large margin on image-to-text (+22.2% R@1) and text-to-image (20.1% R@1) tasks. Table 3 shows that ALIGN also outperforms the previous SOTA on SITS task with an improvement of 5.7%. One interesting observation is that, despite being much better on inter-modal tasks, ALIGN is not as impressive on intra-modal tasks. For instance, the improvements on text-to-text and image-to-image retrieval tasks (in particular the former) are less significant compared to those on image-to-text and text-to-image tasks. The performance on STS and SIS tasks is also slightly worse than VSE++ and DE I2T . We suspect it is because the training objective of ALIGN focuses on cross-modal (image-text) matching instead of intra-modal matching. Parekh et al. ( 2021 ) suggest multitask learning could produce more balanced representations. We leave it to the future work.
5.2 Zero-shot Visual Classification
If we directly feed the texts of classnames into the text encoder, ALIGN is able to classify images into candidate classes via image-text retrieval. Table 4 compares ALIGN with CLIP on Imagenet and its variants. Similar to CLIP, ALIGN shows great robustness on classification tasks with different image distributions. In order to make a fair comparison, we use the same prompt ensembling method as CLIP. Each classname is expanded with a set of prompt templates defined by CLIP such as “A photo of a {classname}”. The class embedding is computed by averaging the embeddings of all templates followed by an L2-normalization. We find that such ensembling gives 2.9% improvement on ImageNet top-1 accuracy.
5.3 Visual Classification w/ Image Encoder Only
On the ImageNet benchmark, we first freeze the learned visual features and only train the classification head. Afterwards we fine-tune all layers. We use basic data augmentations including random cropping (same as in Szegedy et al. ( 2015 ) ) and horizontal flip. In evaluation we apply a single central crop with ratio of 0.875. Following Touvron et al. ( 2019 ) , we use 0.8 scale ratio between training and evaluation to mitigate the resolution discrepancy introduced by random crop. Specifically, train/eval resolution is 289/360 with frozen visual features, and is 475/600 when fine-tuning all variables.
In both stages of training, we use a global batch size of 1024, SGD optimizer with momentum 0.9, and learning rate decayed every 30 epochs with ratio 0.2 (100 epochs in total). Weight decay is set to zero. With frozen visual features, we use the initial learning rate of 0.1. When fine-tuning all layers with use the initial learning rate of 0.01, and use 10x smaller learning rate on the backbone network compared to the classification head.
Table 5 compares ALIGN with previous methods on the ImageNet benchmark. With frozen features, ALIGN slightly outperforms CLIP and achieves SOTA result of 85.5% top-1 accuracy. After fine-tuning ALIGN achieves higher accuracy than BiT and ViT models, and is only worse than Meta Pseudo Labels which requires deeper interaction between ImageNet training and large-scale unlabeled data. Compared to NoisyStudent and Meta-Pseudeo-Labels which also use EfficientNet-L2, ALIGN saves 44% FLOPS by using smaller test resolution (600 instead of 800).
In VTAB eval, we follow a hyper-parameter sweep as shown in the Appendix I in (Zhai et al., 2019 ) with 50 trials for each task. Each task is trained on 800 images and the hyperparameters are selected using the validation set of 200 images. After the sweep, the selected hyperparameters are used to train on the combined training and validation splits of 1000 images for each task. Table 6 reports the mean accuracy (including the breakdown results on each subgroup) with standard deviation from three fine-tuning runs and shows that ALIGN outperforms BiT-L (Kolesnikov et al., 2020 ) with similar hyper-parameter selection method applied.
To evaluate on smaller fine-grained classification benchmarks, we adopt a simple fine-tuning strategy for all tasks. We use the same data augmentation and optimizer as in ImageNet fine-tuning. Similarly, we first train the classification head and then fine-tune all layers, except with batch norm statistics frozen. The train/eval resolution is fixed at 289/360. We use batch size 256 and weight decay 1e-5. The initial learning rate is set to 1e-2 and 1e-3 respectively, with cosine learning rate decay in 20k steps. Table 7 compares ALIGN with BiT-L (Kolesnikov et al., 2020 ) and SAM (Foret et al., 2021 ) which both apply same fine-tuning hyper-parameters for all tasks. 2 2 2 ViT (Dosovitskiy et al., 2021 ) uses different hyper-parameters for different tasks and hence is not included in comparison. For small tasks like these, details in fine-tuning matter. So we list the baseline results in (Foret et al., 2021 ) without using SAM optimization for a fairer comparison. Our result (average of three runs) is comparable to the SOTA results without tweaking on optimization algorithms.
6 Ablation Study
In the ablation study, we compare model performance mostly on MSCOCO zero-shot retrieval and ImageNet K-Nearest-neighbor (KNN) tasks. 3 3 3 For each image in the validation set of ImageNet, we retrieve its nearest neighbors from the training set w/ pre-trained image encoder. Recall@K metric is calculated based on if the groundtruth label of the query image appears in the top-K retrieved images. We find these two metrics are representative and correlate well with other metrics reported in the section above. If not mentioned, hyper-parameters other than the ablated factor are kept the same as in the baseline model.
6.1 Model Architectures
We first study the performance of ALIGN models using different image and text backbones. We train EfficientNet from B1 to L2 for the image encoder and BERT-Mini to BERT-Large for the text encoder. We add an additional fully-connected layer with linear activation on top of B1, B3, B5 and L2 globally-pooled features to match the output dimension of B7 (640). A similar linear layer is added to all text encoders. We reduce the training steps to 1M in ablation to save some runtime.
Figures 3 shows MSCOCO zero-shot retrieval and ImageNet KNN results with different combinations of image and text backbones. Model quality improves nicely with larger backbones except that the ImageNet KNN metric starts to saturate from BERT-Base to BERT-Large with EfficientNet-B7 and EfficientNet-L2. As expected, scaling up image encoder capacity is more important for vision tasks (e.g., even with BERT-Mini text tower, L2 performs better than B7 with BERT-Large). In image-text retrieval tasks the image and text encoder capacities are equally important. Based on the nice scaling property shown in Figure 3 , we only fine-tune the model with EfficientNet-L2 + BERT-Large as reported in Section 5 .

We then study key architecture hyperparameters including embedding dimensions, number of random negatives in the batch, and the softmax temperature. Table 8 compares a number of model variants to a baseline model (first row) trained with the following settings: EfficientNet-B5 image encoder, BERT-Base text encoder, embedding dimension 640, all negatives in the batch, and a learnable softmax temperature.
Rows 2-4 of Table 8 show that model performance improves with higher embedding dimensions. Hence, we let the dimension scale with larger EfficientNet backbone (L2 uses 1376). Rows 5 and 6 show that using fewer in-batch negatives (50% and 25%) in the softmax loss will degrade the performance. Rows 7-9 study the effect of the temperature parameter in the softmax loss. Compared to the baseline model that learns the temperature parameter (converged to about 1/64), some hand-selected, fixed temperatures could be slightly better. However, we choose to use the learnable temperature as it performs competitively and makes learning easier. We also notice that the temperature usually quickly decrease to only around 1.2x of the converged values in the first 100k steps, and then slowly converges until the end of training.
6.2 Pre-training Datasets
It’s also important to understand how the model performs when trained on different datasets with varying size. For this purpose, we train two models: EfficientNet-B7 + BERT-base and EfficientNet-B3 + BERT-mini on three different datasets: full ALIGN training data, 10% randomly sampled ALIGN training data, and Conceptual Captions (CC-3M, around 3M images). CC-3M is much smaller so we train the model with 1/10 of the default number of steps. All models are trained from scratch. As shown in Table 9 , a large scale training set is essential to allow scaling up of our models and to achieve better performance. For instance, models trained on ALIGN data clearly outperform those trained on CC-3M data. On CC-3M, B7+BERT-base starts to overfit and performs even worse than B3+BERT-mini. Conversely, a larger model is required to fully utilize the larger dataset – the smaller B3+BERT-mini almost saturate at 10% of ALIGN data, while with the larger B7+BERT-base, there is a clear improvement with full ALIGN data.
To understand better how data size scaling wins over the increased noise, we further randomly sample 3M, 6M, and 12M ALIGN training data and compare them with the cleaned CC-3M data on B7+BERT-base model. Table 10 shows that while the ALIGN data performs much worse than CC data with the same size (3M), the model quality trained on 6M and 12M ALIGN data rapidly catches up. Despite being noisy, ALIGN data outperforms Conceptual Captions with only 4x size.
7 Analysis of Learned Embeddings
We build a simple image retrieval system to study the behaviors of embeddings trained by ALIGN. For demonstration purposes, we use an index consisting of 160M CC-BY licensed images that are separate from our training set. Figure 4 shows the top 1 text-to-image retrieval results for a handful of text queries not existing in the training data. ALIGN can retrieve precise images given detailed descriptions of a scene, or fine-grained or instance-level concepts like landmarks and artworks. These examples demonstrate that our ALIGN model can align images and texts with similar semantics, and that ALIGN can generalize to novel complex concepts.

Previously word2vec (Mikolov et al., 2013a , b ) shows that linear relationships between word vectors emerge as a result of training them to predict adjacent words in sentences and paragraphs. We show that linear relationships between image and text embeddings also emerge in ALIGN. We perform image retrieval using a combined image+text query. Specifically, given a query image and a text string, we add their ALIGN embeddings together and use it to retrieve relevant images. 4 4 4 We normalize the text and image embeddings before adding them. We also tried various scale factor and found that a scale of 2 for the text embedding and 1 for the image embedding give best results as shown in the figure, although 1:1 also works well. Figure 5 shows results for a variety of image+text queries. These examples not only demonstrate great compositionality of ALIGN embeddings across vision and language domains, but also show the feasibility of a new paradigm of “search with multi-modal query” that would otherwise be hard using only text query or image query. For instance, one could now look for the “Australia” or “Madagascar” equivalence of pandas, or turn a pair of black shoes into identically-looking shoes with the color of “beige”. Finally, as shown in the last three rows of Figure 5 , removing objects/attributes from a scene is possible by performing subtraction in the embedding space.
8 Multilingual ALIGN Model
One advantage of ALIGN is that the model is trained on noisy web image text data with very simple filters, and none of the filters are language specific. Given that, we further lift the language constraint of the conceptual caption data processing pipeline to extend the dataset to multilingual (covering 100+ languages) and match its size to the English dataset (1.8B image-text pairs). A multilingual model ALIGN mling is trained using this data. We created a new mutlilingual wordpiece vocabulary with size 250k to cover all languages. Model training follows the exact English configuration.
We test the multilingual model on Multi30k, a multilingual image text retrieval dataset extends Flickr30K (Plummer et al., 2015 ) to German (de) (Elliott et al., 2016 ) , French (fr) (Elliott et al., 2017 ) and Czech (cs) (Barrault et al., 2018 ) . The dataset consists of 31,783 images with 5 captions per image in English and German and 1 caption per image in French and Czech. The train/dev/test splits are defined in Young et al. ( 2014 ) . We evaluate the zero-shot model performance of ALIGN and compare it with M 3 P (Huang et al., 2020a ) and UC2 (Zhou et al., 2021 ) . The evaluation metric is mean Recall (mR), which computes the average score of Recall@1, Recall@5 and Recall@10 on image-to-text retrieval and text-to-image retrieval tasks.
Table 11 shows that the zero-shot performance of ALIGN mling outperforms M 3 P on all languages by a large margin, with the largest +57.8 absolution mR improvement on fr. The zero-shot performance of ALIGN mling is even comparable to the fine-tuned (w/ training splits) M 3 P and UC2 except on cs. On en, ALIGN mling performs slightly worse on its counterpart ALIGN EN (trained on EN-only data.)
9 Conclusion
We present a simple method of leveraging large-scale noisy image-text data to scale up visual and vision-language representation learning. Our method avoids heavy work on data curation and annotation, and only requires minimal frequency-based cleaning. On this dataset, we train a simple dual-encoder model using a contrastive loss. The resulting model, named ALIGN, is capable of cross-modal retrieval and significantly outperforms SOTA VSE and cross-attention vision-language models. In visual-only downstream tasks, ALIGN is also comparable to or outperforms SOTA models trained with large-scale labeled data.
10 Social Impacts and Future Work
While this work shows promising results from a methodology perspective with a simple data collection method, additional analysis of the data and the resulting model is necessary before the use of the model in practice. For instance, considerations should be made towards the potential for the use of harmful text data in alt-texts to reinforce such harms. On the fairness front, data balancing efforts may be required to prevent reinforcing stereotypes from the web data. Additional testing and training around sensitive religious or cultural items should be taken to understand and mitigate the impact from possibly mislabeled data.
Further analysis should also be taken to ensure that the demographic distribution of humans and related cultural items like clothing, food, and art do not cause model performance to be skewed. Analysis and balancing would be required if such models will be used in production.
Finally, unintended misuse of such models for surveillance or other nefarious purposes should be prohibited.
Acknowledgements
This work was done with invaluable help from colleagues from Google. We would like to thank Jan Dlabal and Zhe Li for continuous support in training infrastructure, Simon Kornblith for building the zero-shot & robustness model evaluation on ImageNet variants, Xiaohua Zhai for help on conducting VTAB evaluation, Mingxing Tan and Max Moroz for suggestions on EfficientNet training, Aleksei Timofeev for the early idea of multimodal query retrieval, Aaron Michelony and Kaushal Patel for their early work on data generation, and Sergey Ioffe, Jason Baldridge and Krishna Srinivasan for the insightful feedback and discussion.
- Barrault et al. (2018) Barrault, L., Bougares, F., Specia, L., Lala, C., Elliott, D., and Frank, S. Findings of the third shared task on multimodal machine translation. In Proceedings of the Third Conference on Machine Translation: Shared Task Papers , pp. 304–323, 2018.
- Bossard et al. (2014) Bossard, L., Guillaumin, M., and Van Gool, L. Food-101 – mining discriminative components with random forests. In European Conference on Computer Vision , 2014.
- Caron et al. (2020) Caron, M., Misra, I., Mairal, J., Goyal, P., Bojanowski, P., and Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. In Advances in Neural Information Processing Systems , 2020.
- Chen et al. (2020a) Chen, J., Hu, H., Wu, H., Jiang, Y., and Wang, C. Learning the best pooling strategy for visual semantic embedding. In arXiv preprint arXiv:2011.04305 , 2020a.
- Chen et al. (2020b) Chen, T., Kornblith, S., Norouzi, M., and Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of International Conference on Machine Learning , 2020b.
- Chen et al. (2015) Chen, X., Fang, H., Lin, T.-Y., Vedantam, R., Gupta, S., Dollar, P., and Zitnick, C. L. Microsoft coco captions: Data collection and evaluation server. In arXiv preprint arXiv:1504.00325 , 2015.
- Chen et al. (2020c) Chen, Y.-C., Li, L., Yu, L., Kholy, A. E., Ahmed, F., Gan, Z., Cheng, Y., and Liu, J. Uniter: Universal image-text representation learning. In Proceedings of European Conference on Computer Vision , 2020c.
- Deng et al. (2009) Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of Conference on Computer Vision and Pattern Recognition , 2009.
- Desai & Johnson (2020) Desai, K. and Johnson, J. Virtex: Learning visual representations from textual annotations. In arXiv preprint arXiv:2006.06666 , 2020.
- Devlin et al. (2019) Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of Conference of the North American Chapter of the Association for Computational Linguistics , 2019.
- Dosovitskiy et al. (2021) Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of International Conference on Learning Representations , 2021.
- Elliott et al. (2016) Elliott, D., Frank, S., Sima’an, K., and Specia, L. Multi30k: Multilingual english-german image descriptions. In Proceedings of the 5th Workshop on Vision and Language , 2016.
- Elliott et al. (2017) Elliott, D., Frank, S., Barrault, L., Bougares, F., and Specia, L. Findings of the second shared task on multimodal machine translation and multilingual image description. In Proceedings of the Second Conference on Machine Translation, Volume 2: Shared Task Papers , September 2017.
- Faghri et al. (2018) Faghri, F., Fleet, D. J., Kiros, J. R., and Fidler, S. Vse++: Improving visual-semantic embeddings with hard negatives. In Proceedings of the British Machine Vision Conference , 2018.
- Foret et al. (2021) Foret, P., Kleiner, A., Mobahi, H., and Neyshabur, B. Sharpness-aware minimization for efficiently improving generalization. In International Conference on Learning Representations , 2021.
- Frome et al. (2013) Frome, A., Corrado, G. S., Shlens, J., Bengio, S., Dean, J., Ranzato, M. A., and Mikolov, T. Devise: A deep visual-semantic embedding model. In Proceedings of Neural Information Processing Systems , 2013.
- Gan et al. (2020) Gan, Z., Chen, Y.-C., Li, L., Zhu, C., Cheng, Y., and Liu, J. Large-scale adversarial training for vision-and-language representation learning. In Proceedings of Neural Information Processing Systems , 2020.
- Grill et al. (2020) Grill, J.-B., Strub, F., Altché, F., Tallec, C., Richemond, P. H., Buchatskaya, E., Doersch, C., Pires, B. A., Guo, Z. D., Azar, M. G., Piot, B., Kavukcuoglu, K., Munos, R., and Valko, M. Bootstrap your own latent: A new approach to self-supervised learning. arXiv preprint arXiv:2006.07733 , 2020.
- He et al. (2020) He, K., Fan, H., Wu, Y., Xie, S., and Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , June 2020.
- Hendrycks et al. (2020) Hendrycks, D., Basart, S., Mu, N., Kadavath, S., Wang, F., Dorundo, E., Desai, R., Zhu, T., Parajuli, S., Guo, M., Song, D., Steinhardt, J., and Gilmer, J. The many faces of robustness: A critical analysis of out-of-distribution generalization. arXiv preprint arXiv:2006.16241 , 2020.
- Hendrycks et al. (2021) Hendrycks, D., Zhao, K., Basart, S., Steinhardt, J., and Song, D. Natural adversarial examples. CVPR , 2021.
- Hill et al. (2015) Hill, F., Reichart, R., and Korhonen, A. Simlex-999: Evaluating semantic models with (genuine) similarity estimation. Computational Linguistics , 2015.
- Huang et al. (2020a) Huang, H., Su, L., Qi, D., Duan, N., Cui, E., Bharti, T., Zhang, L., Wang, L., Gao, J., Liu, B., Fu, J., Zhang, D., Liu, X., and Zhou, M. M3p: Learning universal representations via multitask multilingual multimodal pre-training. arXiv , abs/2006.02635, 2020a.
- Huang et al. (2020b) Huang, Z., Zeng, Z., Liu, B., Fu, D., and Fu, J. Pixel-bert: Aligning image pixels with text by deep multi-modal transformers. arXiv preprint arXiv:2004.00849 , 2020b.
- Joulin et al. (2015) Joulin, A., van der Maaten, L., Jabri, A., and Vasilache, N. Learning visual features from large weakly supervised data. In European Conference on Computer Vision , 2015.
- Juan et al. (2020) Juan, D.-C., Lu, C.-T., Li, Z., Peng, F., Timofeev, A., Chen, Y.-T., Gao, Y., Duerig, T., Tomkins, A., and Ravi, S. Graph-rise: Graph-regularized image semantic embedding. In Proceedings of ACM International Conference on Web Search and Data Mining , 2020.
- Karpathy & Fei-Fei (2015) Karpathy, A. and Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of Conference on Computer Vision and Pattern Recognition , 2015.
- Karpathy et al. (2014) Karpathy, A., Joulin, A., and Li, F. Deep fragment embeddings for bidirectional image sentence mapping. In Advances in Neural Information Processing Systems , 2014.
- Kiros et al. (2018) Kiros, J., Chan, W., and Hinton, G. Illustrative language understanding: Large-scale visual grounding with image search. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , 2018.
- (30) Kiros, R., Salakhutdinov, R., and Zemel, R. S. Unifying visual-semantic embeddings with multimodal neural language models. arXiv preprint arXiv:1411.2539 .
- Kolesnikov et al. (2020) Kolesnikov, A., Beyer, L., Zhai, X., Puigcerver, J., Yung, J., Gelly, S., and Houlsby, N. Big transfer (bit): General visual representation learning. In Proceedings of European Conference on Computer Vision , 2020.
- Krause et al. (2013) Krause, J., Stark, M., Deng, J., and Fei-Fei, L. 3d object representations for fine-grained categorization. In Proceedings of ICCV Workshop on 3D Representation and Recognition , 2013.
- Krishna et al. (2016) Krishna, R., Zhu, Y., Groth, O., Johnson, J., Hata, K., Kravitz, J., Chen, S., Kalantidis, Y., Li, L.-J., Shamma, D. A., Bernstein, M., and Fei-Fei, L. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision , 2016.
- Kuznetsova et al. (2020) Kuznetsova, A., Rom, H., Alldrin, N., Uijlings, J., Krasin, I., Pont-Tuset, J., Kamali, S., Popov, S., Malloci, M., Kolesnikov, A., Duerig, T., and Ferrari, V. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. International Journal of Computer Vision , 2020.
- Li et al. (2017) Li, A., Jabri, A., Joulin, A., and van der Maaten, L. Learning visual n-grams from web data. In Proceedings of IEEE International Conference on Computer Vision , 2017.
- Li et al. (2021) Li, J., Zhou, P., Xiong, C., and Hoi, S. Prototypical contrastive learning of unsupervised representations. In International Conference on Learning Representations , 2021.
- Li et al. (2019) Li, K., Zhang, Y., Li, K., Li, Y., and Fu, Y. Visual semantic reasoning for image-text matching. In Proceedings of International Conference on Computer Vision , 2019.
- Li et al. (2020) Li, X., Yin, X., Li, C., Zhang, P., Hu, X., Zhang, L., Wang, L., Hu, H., Dong, L., Wei, F., Choi, Y., and Gao, J. Oscar: Object-semantics aligned pre-training for vision-language tasks. In Proceedings of European Conference on Computer Vision , 2020.
- Liu et al. (2019a) Liu, F., Liu, Y., Ren, X., He, X., and Sun, X. Aligning visual regions and textual concepts for semantic-grounded image representations. In Advances in Neural Information Processing Systems , 2019a.
- Liu et al. (2019b) Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., and Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 , 2019b.
- Lu et al. (2019) Lu, J., Batra, D., Parikh, D., and Lee, S. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In Proceedings of Neural Information Processing Systems , 2019.
- Mahajan et al. (2018) Mahajan, D., Girshick, R., Ramanathan, V., He, K., Paluri, M., Li, Y., Bharambe, A., and van der Maaten, L. Exploring the limits of weakly supervised pretraining. In Proceedings of European Conference on Computer Vision , 2018.
- Messina et al. (2020) Messina, N., Amato, G., Esuli, A., Falchi, F., Gennaro, C., and Marchand-Maillet, S. Fine-grained visual textual alignment for cross-modal retrieval using transformer encoders. ACM Transactions on Multimedia Computing, Communications, and Applications , 2020.
- Mikolov et al. (2013a) Mikolov, T., Chen, K., Corrado, G., and Dean, J. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781 , 2013a.
- Mikolov et al. (2013b) Mikolov, T., Sutskever, I., Chen, K., Corrado, G., and Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems , 2013b.
- Misra & Maaten (2020) Misra, I. and Maaten, L. v. d. Self-supervised learning of pretext-invariant representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , June 2020.
- Musgrave et al. (2020) Musgrave, K., Belongie, S., and Lim, S.-N. A metric learning reality check. In Proceedings of European Conference on Computer Vision , 2020.
- Nam et al. (2017) Nam, H., Ha, J.-W., and Kim, J. Dual attention networks for multimodal reasoning and matching. In Proceedings of Conference on Computer Vision and Pattern Recognition , 2017.
- Nilsback & Zisserman (2008) Nilsback, M.-E. and Zisserman, A. Automated flower classification over a large number of classes. In Indian Conference on Computer Vision, Graphics and Image Processing , Dec 2008.
- Parekh et al. (2021) Parekh, Z., Baldridge, J., Cer, D., Waters, A., and Yang, Y. Crisscrossed captions: Extended intramodal and intermodal semantic similarity judgments for ms-coco. In Proceedings of Conference of the European Chapter of the Association for Computational Linguistics , 2021.
- Parkhi et al. (2012) Parkhi, O. M., Vedaldi, A., Zisserman, A., and Jawahar, C. V. Cats and dogs. In IEEE Conference on Computer Vision and Pattern Recognition , 2012.
- Pennington et al. (2014) Pennington, J., Socher, R., and Manning, C. GloVe: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) , 2014.
- Pham et al. (2020) Pham, H., Dai, Z., Xie, Q., Luong, M.-T., and Le, Q. V. Meta pseudo labels. In arXiv preprint arXiv:2003.10580 , 2020.
- Plummer et al. (2015) Plummer, B. A., Wang, L., Cervantes, C. M., Caicedo, J. C., Hockenmaier, J., and Lazebnik, S. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In Proceedings of the International Conference on Computer Vision , 2015.
- Qi et al. (2020) Qi, D., Su, L., Song, J., Cui, E., Bharti, T., and Sacheti, A. Imagebert: Cross-modal pre-training with large-scale weak-supervised image-text data. arXiv preprintarXiv:2001.07966 , 2020.
- Radford et al. (2019) Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I. Language models are unsupervised multitask learners. 2019.
- Radford et al. (2021) Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarawl, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I. Learning transferable visual models from natural language supervision. 2021.
- Raffel et al. (2020) Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research , 2020.
- Recht et al. (2019) Recht, B., Roelofs, R., Schmidt, L., and Shankar, V. Do imagenet classifiers generalize to imagenet? In International Conference on Machine Learning , pp. 5389–5400, 2019.
- Sariyildiz et al. (2020) Sariyildiz, M. B., Perez, J., and Larlus, D. Learning visual representations with caption annotations. arXiv preprint arXiv:2008.01392 , 2020.
- Sharma et al. (2018) Sharma, P., Ding, N., Goodman, S., and Soricut, R. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of Annual Meeting of the Association for Computational Linguistics , 2018.
- Socher et al. (2014) Socher, R., Karpathy, A., Le, Q. V., Manning, C. D., and Ng, A. Y. Grounded compositional semantics for finding and describing images with sentences. Transactions of the Association for Computational Linguistics , 2014.
- Sun et al. (2017) Sun, C., Shrivastava, A., Sigh, S., and Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the International Conference on Computer Vision , 2017.
- Szegedy et al. (2015) Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., and Rabinovich, A. Going deeper with convolutions. In Proceedings of Conference on Computer Vision and Pattern Recognition , 2015.
- Tian et al. (2020) Tian, Y., Krishnan, D., and Isola, P. Contrastive multiview coding. In European Conference on Computer Vision , 2020.
- Touvron et al. (2019) Touvron, H., Vedaldi, A., Douze, M., and Jégou, H. Fixing the train-test resolution discrepancy. In Advances in Neural Information Processing Systems , 2019.
- Wang et al. (2014) Wang, J., Song, Y., Leung, T., Rosenberg, C., Wang, J., Philbin, J., Chen, B., and Wu, Y. Learning fine-grained image similarity with deep ranking. In Proceedings of Conference on Computer Vision and Pattern Recognition , 2014.
- Xie et al. (2020) Xie, Q., Luong, M.-T., Hovy, E., and Le, Q. V. Self-training with noisy student improves imagenet classification. In Proceedings of Conference on Computer Vision and Pattern Recognition , 2020.
- Yalniz et al. (2019) Yalniz, I. Z., Jégou, H., Chen, K., Paluri, M., and Mahajan, D. Billion-scale semi-supervised learning for image classification. arXiv preprint arXiv:1905.00546 , 2019.
- Yang et al. (2019) Yang, Z., Dai, Z., Yang, Y., Carbonell, J. G., Salakhutdinov, R., and Le, Q. V. Xlnet: Generalized autoregressive pretraining for language understanding. In Advances in Neural Information Processing Systems , 2019.
- You et al. (2020) You, Y., Li, J., Reddi, S., Hseu, J., Kumar, S., Bhojanapalli, S., Song, X., Demmel, J., Keutzer, K., and Hsieh, C.-J. Large batch optimization for deep learning: Training bert in 76 minutes. In Proceedings of International Conference on Learning Representations , 2020.
- Young et al. (2014) Young, P., Lai, A., Hodosh, M., and Hockenmaier, J. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics , 2014.
- Yu et al. (2020) Yu, F., Tang, J., Yin, W., Sun, Y., Tian, H., Wu, H., and Wang, H. Ernie-vil: Knowledge enhanced vision-language representations through scene graph. arXiv preprint arXiv:2006.16934 , 2020.
- Zhai & Wu (2019) Zhai, A. and Wu, H.-Y. Classification is a strong baseline for deep metric learning. In Proceedings of the British Machine Vision Conference , 2019.
- Zhai et al. (2019) Zhai, X., Puigcerver, J., Kolesnikov, A., Ruyssen, P., Riquelme, C., Lucic, M., Djolonga, J., Pinto, A. S., Neumann, M., Dosovitskiy, A., Beyer, L., Bachem, O., Tschannen, M., Michalski, M., Bousquet, O., Gelly, S., and Houlsby, N. A large-scale study of representation learning with the visual task adaptation benchmark. arXiv preprint arXiv:1910.04867 , 2019.
- Zhang et al. (2020) Zhang, Y., Jiang, H., Miura, Y., Manning, C. D., and Langlotz, C. P. Contrastive learning of medical visual representations from paired images and text. arXiv preprint arXiv:2010.00747 , 2020.
- Zhou et al. (2021) Zhou, M., Zhou, L., Wang, S., Cheng, Y., Li, L., Yu, Z., and Liu, J. UC2: Universal cross-lingual cross-modal vision-and-language pre-training. arXiv preprint arXiv:2104.00332 , 2021.
- Zoph et al. (2020) Zoph, B., Ghiasi, G., Lin, T.-Y., Cui, Y., Liu, H., Cubuk, E. D., and Le, Q. V. Rethinking pre-training and self-training. In Advances in Neural Information Processing Systems , 2020.
Appendix A Remove Near-Duplicate Test Images from Training Data
To detect near-duplicate images, we first train a separate high-quality image embedding model following (Wang et al., 2014 ) with a large-scale labeled dataset as in (Juan et al., 2020 ) , and then generate 4K clusters via k-means based on all training images of the embedding model. For each query image (from the ALIGN dataset) and index image (from test sets of downstream tasks), we find their top-10 nearest clusters based on the embedding distance. Each image is then assigned to ( 10 3 ) binomial 10 3 10\choose 3 buckets (all possible combinations of 3 clusters out of 10). For any query-index image pair that falls into the same bucket, we mark it as near-duplicated if their embedding cosine similarity is larger than 0.975. This threshold is trained on a large-scale dataset built with human rated data and synthesized data with random augmentation.
Appendix B Evaluation on SimLex-999
The image-text co-training could also help the natural language understanding as shown in Kiros et al. ( 2018 ) . For instance, with language only, it is very hard to learn antonyms. In order to test this capability of ALIGN model, we also evaluate the word representation from ALIGN model 5 5 5 As ALIGN uses the wordpiece tokens, one word can be split into multiple pieces. We feed the wordpieces of a word into ALIGN model and use the [CLS] token representation before the project layers as the word embeddings. on SimLex-999 (Hill et al., 2015 ) , which is a task to compare word similarity for 999 word pairs. We follow Kiros et al. ( 2018 ) to report the results on 9 sub-tasks each contains a subset of word pairs: all, adjectives, nouns, verbs, concreteness quartiles (1-4) , and hard .
. GloVe Picturebook ALIGN all 40.8 37.3 39.8 adjs 62.2 11.7 49.8 nouns 42.8 48.2 45.9 verbs 19.6 17.3 16.6 conc-q1 43.3 14.4 23.9 conc-q2 41.6 27.5 41.7 conc-q3 42.3 46.2 47.6 conc-q4 40.2 60.7 57.8 hard 27.2 28.8 31.7
The results are listed in the Table 12 compared to Picturebook (Kiros et al., 2018 ) and GloVe (Pennington et al., 2014 ) embeddings. Overall the learned ALIGN perform better than Picturebook but slightly worse than GloVe embeddings. What is interesting is that the ALIGN word embeddings has a similar trend of Picturebook embeddings, with better performance on nouns and most concrete categories but worse on adjs and less concrete categories compared to GloVe embeddings. ALIGN word embedding achieves the highest performance on the hard category, which similarity is difficult to distinguish from relatedness. This observation confirmed the hypothesis from Kiros et al. ( 2018 ) that image-based word embeddings are less likely to confuse similarity with relatedness than text learned distributional-based methods.

ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
May 11, 2021
Posted by Chao Jia and Yinfei Yang, Software Engineers, Google Research
Learning good visual and vision-language representations is critical to solving computer vision problems — image retrieval, image classification, video understanding — and can enable the development of tools and products that change people’s daily lives. For example, a good vision-language matching model can help users find the most relevant images given a text description or an image input and help tools such as Google Lens find more fine-grained information about an image.
To learn such representations, current state-of-the-art (SotA) visual and vision-language models rely heavily on curated training datasets that require expert knowledge and extensive labels. For vision applications, representations are mostly learned on large-scale datasets with explicit class labels, such as ImageNet , OpenImages , and JFT-300M . For vision-language applications, popular pre-training datasets, such as Conceptual Captions and Visual Genome Dense Captions , all require non-trivial data collection and cleaning steps, limiting the size of datasets and thus hindering the scale of the trained models. In contrast, natural language processing (NLP) models have achieved SotA performance on GLUE and SuperGLUE benchmarks by utilizing large-scale pre-training on raw text without human labels.
In " Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision ", to appear at ICML 2021 , we propose bridging this gap with publicly available image alt-text data (written copy that appears in place of an image on a webpage if the image fails to load on a user's screen) in order to train larger, state-of-the-art vision and vision-language models. To that end, we leverage a noisy dataset of over one billion image and alt-text pairs, obtained without expensive filtering or post-processing steps in the Conceptual Captions dataset. We show that the scale of our corpus can make up for noisy data and leads to SotA representation, and achieves strong performance when transferred to classification tasks such as ImageNet and VTAB . The aligned visual and language representations also set new SotA results on Flickr30K and MS-COCO benchmarks, even when compared with more sophisticated cross-attention models, and enable zero-shot image classification and cross-modality search with complex text and text + image queries.
Creating the Dataset
Alt-texts usually provide a description of what the image is about, but the dataset is “noisy” because some text may be partly or wholly unrelated to its paired image.
In this work, we follow the methodology of constructing the Conceptual Captions dataset to get a version of raw English alt-text data (image and alt-text pairs). While the Conceptual Captions dataset was cleaned by heavy filtering and post-processing, this work scales up visual and vision-language representation learning by relaxing most of the cleaning steps in the original work. Instead, we only apply minimal frequency-based filtering. The result is a much larger but noisier dataset of 1.8B image-text pairs.
ALIGN: A Large-scale ImaGe and Noisy-Text Embedding
For the purpose of building larger and more powerful models easily, we employ a simple dual-encoder architecture that learns to align visual and language representations of the image and text pairs. Image and text encoders are learned via a contrastive loss (formulated as normalized softmax) that pushes the embeddings of matched image-text pairs together while pushing those of non-matched image-text pairs (within the same batch) apart. The large-scale dataset makes it possible for us to scale up the model size to be as large as EfficientNet-L2 (image encoder) and BERT-large (text encoder) trained from scratch. The learned representation can be used for downstream visual and vision-language tasks.
The resulting representation can be used for vision-only or vision-language task transfer. Without any fine-tuning, ALIGN powers cross-modal search – image-to-text search, text-to-image search, and even search with joint image+text queries, examples below.
Evaluating Retrieval and Representation
The learned ALIGN model with BERT-Large and EfficientNet-L2 as text and image encoder backbones achieves SotA performance on multiple image-text retrieval tasks ( Flickr30K and MS-COCO ) in both zero-shot and fine-tuned settings, as shown below.
ALIGN is also a strong image representation model. Shown below, with frozen features, ALIGN slightly outperforms CLIP and achieves a SotA result of 85.5% top-1 accuracy on ImageNet. With fine-tuning, ALIGN achieves higher accuracy than most generalist models, such as BiT and ViT , and is only worse than Meta Pseudo Labels , which requires deeper interaction between ImageNet training and large-scale unlabeled data.
Zero-Shot Image Classification
Traditionally, image classification problems treat each class as independent IDs, and people have to train the classification layers with at least a few shots of labeled data per class. The class names are actually also natural language phrases, so we can naturally extend the image-text retrieval capability of ALIGN for image classification without any training data .
On the ImageNet validation dataset, ALIGN achieves 76.4% top-1 zero-shot accuracy and shows great robustness in different variants of ImageNet with distribution shifts, similar to the concurrent work CLIP . We also use the same text prompt engineering and ensembling as in CLIP.
Application in Image Search
To illustrate the quantitative results above, we build a simple image retrieval system with the embeddings trained by ALIGN and show the top 1 text-to-image retrieval results for a handful of text queries from a 160M image pool. ALIGN can retrieve precise images given detailed descriptions of a scene, or fine-grained or instance-level concepts like landmarks and artworks. These examples demonstrate that the ALIGN model can align images and texts with similar semantics, and that ALIGN can generalize to novel complex concepts.
Multimodal (Image+Text) Query for Image Search
A surprising property of word vectors is that word analogies can often be solved with vector arithmetic. A common example, "king – man + woman = queen". Such linear relationships between image and text embeddings also emerge in ALIGN.
Specifically, given a query image and a text string, we add their ALIGN embeddings together and use it to retrieve relevant images using cosine similarity , as shown below. These examples not only demonstrate the compositionality of ALIGN embeddings across vision and language domains, but also show the feasibility of searching with a multi-modal query. For instance, one could now look for the "Australia" or "Madagascar" equivalence of pandas, or turn a pair of black shoes into identically-looking beige shoes. Also, it is possible to remove objects/attributes from a scene by performing subtraction in the embedding space, shown below.
Social Impact and Future Work
While this work shows promising results from a methodology perspective with a simple data collection method, additional analysis of the data and the resulting model is necessary before the responsible use of the model in practice. For instance, considerations should be made towards the potential for the use of harmful text data in alt-texts to reinforce such harms. With regard to fairness, data balancing efforts may be required to prevent reinforcing stereotypes from the web data. Additional testing and training around sensitive religious or cultural items should be taken to understand and mitigate the impact from possibly mislabeled data.
Further analysis should also be taken to ensure that the demographic distribution of humans and related cultural items, such as clothing, food, and art, do not cause skewed model performance. Analysis and balancing would be required if such models will be used in production.
We have presented a simple method of leveraging large-scale noisy image-text data to scale up visual and vision-language representation learning. The resulting model, ALIGN, is capable of cross-modal retrieval and significantly outperforms SotA models. In visual-only downstream tasks, ALIGN is also comparable to or outperforms SotA models trained with large-scale labeled data.
Acknowledgement
We would like to thank our co-authors in Google Research: Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig. This work was also done with invaluable help from other colleagues from Google. We would like to thank Jan Dlabal and Zhe Li for continuous support in training infrastructure, Simon Kornblith for building the zero-shot & robustness model evaluation on ImageNet variants, Xiaohua Zhai for help on conducting VTAB evaluation, Mingxing Tan and Max Moroz for suggestions on EfficientNet training, Aleksei Timofeev for the early idea of multimodal query retrieval, Aaron Michelony and Kaushal Patel for their early work on data generation, and Sergey Ioffe, Jason Baldridge and Krishna Srinivasan for the insightful feedback and discussion.
- Machine Intelligence
- Machine Perception
Other posts of interest

May 1, 2024
- Algorithms & Theory ·

April 23, 2024
- Machine Intelligence ·
- Software Systems & Engineering

April 17, 2024
- Human-Computer Interaction and Visualization ·
- Machine Perception ·
- Speech Processing
- Our Mission
Common Core in Action: 10 Visual Literacy Strategies
Do you wish your students could better understand and critique the images that saturate their waking life? That’s the purpose of visual literacy (VL)—to explicitly teach a collection of competencies that will help students think through, think about, and think with pictures.
Standards Support Visual Literacy Instruction
Visual literacy is a staple of 21st century skills, the idea that learners today must “demonstrate the ability to interpret, recognize, appreciate, and understand information presented through visible actions, objects, and symbols , natural or man-made.” Putting aside the imperative to teach students how to create meaningful images, the ability to read images is reflected in the following standards.
Common Core State Standards
- CCSS.ELA-Literacy.RH.6-8.7 : “Integrate visual information (e.g., in charts, graphs, photographs, videos, or maps) with other information in print and digital texts.”
- CCSS.ELA-Literacy.CCRA.R.7 : “Integrate and evaluate content presented in diverse media and formats, including visually and quantitatively, as well as in words.”
- CCSS.ELA-Literacy.CCRA.R.6 : “Assess how point of view or purpose shapes the content and style of a text.”
- CCSS.ELA-Literacy.CCRA.SL.1 : “Prepare for and participate effectively in a range of conversations and collaborations with diverse partners, building on others’ ideas and expressing their own clearly and persuasively.”
National Council of Teachers of English Standards
- Standard 1 : Students read a wide range of print and non-print texts.
Mid-Continent Research for Education and Learning Standards
- Standard 9 : Uses viewing skills and strategies to interpret visual media.
On their own and without explicit, intentional, and systematic instruction, students will not develop VL skills because the language for talking about images is so foreign. Ever heard kids debate the object salience and shot angles of a Ryan Gosling meme? To add to the instructional complexity, visuals come in an assortment of formats, including advertisements, cartoons (including political cartoons), charts and graphs, collages, comic books and graphic novels, diagrams and tables, dioramas, maps, memes, multimodal texts, photos, pictograms, signs, slide shows, storyboards, symbols, timelines, videos.
How to Teach Visual Literacy: Visual Thinking Routines
The VL strategies described in the sections that follow are simple to execute, but powerfully effective in helping students interpret images.
Think-alouds : The think-aloud strategy—typically used to model how adept readers make meaning from a text (demonstrated in the following short video)—can be adapted for reading a visual artifact. After you model how to do it, have learners try this approach with a partner. Encourage elaborate responses. If you need a crash course in visual grammar before implementing this strategy in class, build your background knowledge with Discovering How Images Communicate .
Model Think-Aloud strategy from Derek Fernandez on Vimeo.
Visual Thinking Strategies: Visual Thinking Strategies (VTS) is a specific approach to whole-class viewing and talking about art that primarily uses these questions:
- What do you notice?
- What do you see that makes you say that?
- What more can we find?
VTS encourages students to think beyond the literal by discussing multiple meanings, metaphors, and symbols. Used with all ages—elementary students (see the video below of kindergartners at Huron Valley Schools) up to Harvard medical students—implementation is simple. The weekly VTS lessons from The New York Times are a good place to start.
Visual Thinking Strategies
Asking the 4 Ws: Inspired by Debbie Abilock ’s NoodleTools exercises, I developed the 4 Ws activity to help students make observations, connections, and inferences about an artist’s agenda and develop ideas about a work’s significance:
Five Card Flickr: In Five Card Flickr , players are dealt five random photos. To promote VL, have students follow these steps:
- Jot down one word that they associate with each image.
- Identify a song that comes to mind for one or more of the images.
- Describe what all the images have in common.
- Compare answers with classmates.
During a subsequent discussion, ask students to show what elements of the photo prompted their responses.
Image analysis worksheets: To promote analysis of key features specific to different formats, pick an appropriate tool from the National Archives:
- Photo Analysis
- Cartoon Analysis
- Motion Picture Analysis
- Map Analysis
- Poster Analysis
Step-by-Step: Working With Images That Matter
The following lesson is partially based on Ann Watts Pailliotet’s notion of deep viewing, a process that occurs in three phases:
- Literal observation
- Interpretation
- Evaluation/application
Remember the 1957 photo of Elizabeth Eckford and Hazel Bryan ? Eckford was one of the first African American students to attend the newly desegregated Little Rock High School. In the photo, you see her entering the school grounds while a throng of white students, most prominently an enraged Hazel Bryan, jeer. The photo was disseminated worldwide within a couple of days, uncorking new support for civil rights.
Here are the lesson procedures:
Literal observation phase: Give students a hard copy of the Eckford and Bryan photo. To help them internalize the image, tell them to study it for one minute before turning it over and doodling a version of it from memory. Next, have students write what they observe—what is pictured, how space used used, etc.—in a shared Google Doc.
Interpretation phase: Copy all the student-generated descriptions from the Google Doc, paste them into Tagxedo , and then project the resulting collaborative word cloud for the class to view. Invite students to interpret the word cloud while periodically re-examining the photo. What are the most important words? Which words do they have questions about? What other images are they reminded of, past or present? What messages are implicit and explicit? How did they analyze the photo? What do they understand now that they didn’t before? Then have students help you summarize the conversation.
Evaluation and application phase: Direct students to write about the image’s relevance on notecards. Does the implied purpose of the photo convey ideas that are important? How? Is the image biased? How so? Take the postcards and pin them around the Eckford and Bryan photo to create an instant bulletin board.
To extend the lesson, show the following six-minute video, which narrates how Bryan, as a 20-year-old, apologized in person to Eckford. The video features a contemporary photo of both women, mature now, arm in arm, smiling in front of the once infamous Little Rock High School. Ask students: Does the video alter your reactions to the original image? How? Will you approach other socially charged photos differently? Why?
Final Frame
When reading was taught the traditional way, with printed texts, students accepted the authority of the author and received his or her message as a window on reality. In the 21st century, students need to respectfully question the author’s authority, articulate what is represented and how, and infer what has been excluded and why.
VinVL: Revisiting Visual Representations in Vision-Language Models
Ieee account.
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
Interdisciplinary Graduate Program in Neuroscience
Ashby martin featured in graduate college news article about his neurolinguistic research for betterment of multilingual communities.
At Iowa, Martin studies developmental neurolinguistics, particularly in young children who are bilingual in Spanish and English. His focus is on “numbers as language”, and he examines the neurological impact and visual representation of shifting between the individual’s multiple linguistic repertories through neurological imaging.
Read the entire article here .

VinVL: Revisiting Visual Representations in Vision-Language Models
- Pengchuan Zhang ,
- Xiujun Li ,
- Xiaowei Hu ,
- Jianwei Yang ,
- Lei Zhang ,
- Lijuan Wang ,
- Yejin Choi ,
- Jianfeng Gao
CVPR 2021 | June 2021
This paper presents a detailed study of improving visual representations for vision language (VL)tasks and develops an improved object detection model to provide object-centric representations of images. Compared to the most widely used bottom-up and top-down model [2], the new model is bigger,better-designed for VL tasks, and pre-trained on much larger training corpora that combine multiple public annotated object detection datasets. Therefore, it can generate representations of a richer collection of visual objects and concepts. While previous VL research focuses mainly on improving the vision-language fusion model and leaves the object detection model improvement untouched, we show that visual features matter significantly in VL models. In our experiments we feed the visual features generated by the new object detection model into a Transformer-based VL fusion model OSCAR[21],and utilize an improved approach OSCAR+ to pre-train the VL model and fine-tune it on a wide range of downstream VL tasks. Our results show that the new visual features significantly improve the performance across all VL tasks, creating new state-of-the-art results on seven public benchmarks. Code, models and pre-extracted features are released on GitHub (opens in new tab) .
- Follow on Twitter
- Like on Facebook
- Follow on LinkedIn
- Subscribe on Youtube
- Follow on Instagram
- Subscribe to our RSS feed
Share this page:
- Share on Twitter
- Share on Facebook
- Share on LinkedIn
- Share on Reddit
IMAGES
VIDEO
COMMENTS
Visual Representation refers to the principles by which markings on a surface are made and interpreted. Designers use representations like typography and illustrations to communicate information, emotions and concepts. Color, imagery, typography and layout are crucial in this communication. Alan Blackwell, cognition scientist and professor ...
A similar examination of semantic selectivity for body parts and faces suggests that these modality shifts from visual to linguistic semantic representations also appear along other portions of ...
Furthermore, some visual representations need decoding, and the scientists need to learn how to read these images (i.e., radiologists); therefore, using visual representations in the process of science requires learning a new language that is specific to the medium/methods that is used (i.e., understanding an X-ray picture is different from ...
The roles that interpreting a shared visual representation can play in supportive collaboration is well documented (e.g., Roschelle & Teasley, 1995): Learners have a joint focus for attention and can refer to it nonverbally, and this helps overcome fragmented conversation. Thus, it can serve as an anchor from which to develop common ground.
Language and visual representations are central to all knowledge-based activities, including those in science, health & medicine, and engineering. Word choice, charts, graphs, images, and icons have the power to shape scientific practice, questions asked, results obtained, and interpretations made. ... Visual Representations. Visual ...
Pre-trained representations are becoming crucial for many NLP and perception tasks. While representation learning in NLP has transitioned to training on raw text without human annotations, visual and vision-language representations still rely heavily on curated training datasets that are expensive or require expert knowledge. For vision applications, representations are mostly learned using ...
A visual language is a system of communication using visual elements. ... proportion and colour convey meaning directly without the use of words or pictorial representation. Wassily Kandinsky showed how drawn lines and marks can be expressive without any association with a representational image. From the most ancient cultures and throughout ...
generate and recognize an assortment of visual concepts of increasing complexity and then demonstrate how a prelim-inary visual representation learning system can be trained using models of text. As language models lack the ability to consume or output visual information as pixels, we use code to represent images in our study. Although LLM ...
This makes language-sampled images an excellent source for visual representation learning as they implicitly capture human-like visual invariances. 3.2. Sampling Image Pairs using Language. Given a captioned image dataset, we want to sample im-age pairs that have very similar captions.
Abstract. Pre-trained representations are becoming crucial for many NLP and perception tasks. While representation learning in NLP has transitioned to training on raw text without human annotations, visual and vision-language representations still rely heavily on curated training datasets that are expensive or require expert knowledge.
VinVL: Revisiting Visual Representations in Vision-Language Models Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, ... and thus can generate representations of a richer collection of visual objects and concepts. While previous VL research focuses solely on improving the vision-language fusion model and ...
Vision language pre-training (VLP) has proved effective for a wide range of vision-language (VL) tasks [25, 35, 4, 33, 19, 18, 44, 20]. VLP typically consists of two stages: (1) an object detection model is pre-trained to encode an image and the visual objects in the image to feature vectors, and. (2) a cross-modal fusion model is pre-trained ...
To learn such representations, current state-of-the-art (SotA) visual and vision-language models rely heavily on curated training datasets that require expert knowledge and extensive labels. For vision applications, representations are mostly learned on large-scale datasets with explicit class labels, such as ImageNet, OpenImages, and JFT-300M.
This paper presents a detailed study of improving visual representations for vision language (VL) tasks and develops an improved object detection model to provide object-centric representations of images. Compared to the most widely used \\emph{bottom-up and top-down} model \\cite{anderson2018bottom}, the new model is bigger, better-designed for VL tasks, and pre-trained on much larger ...
language background. They used the strategy to understand their own language. Little is known how this strategy works for university students who learn foreign language. Visualisation can be done internally (by creating mental imagery) and externally (by drawing visual representation). The product of visualising texts
ABSTRACT. While the language portrait (LP) is a visual research method that can make visible speakers' multilingualism, this article considers how and why speakers may use the LP to make elements of their linguistic repertoire invisible.Analysing the portraits created by three primary school students in Luxembourg, I explore why these young people omitted different linguistic resources in ...
The experimental investigation of language-mediated visual attention is a promising way to study the interaction of the cognitive systems involved in language, vision, attention, and memory. Here we highlight four challenges for a mechanistic account of this oculomotor behavior: the levels of representation at which language-derived and vision ...
Chemists routinely use visual representations to investigate relationships and move between the observable, physical level and the invisible particulate level (Kozma, Chin, Russell, ... Most contained language, especially labels and symbolic language such as NaCl. Structure, function, and modality .
VinVL: Making Visual Representations Matter in Vision-Language Models. An improved object detection model to provide object-centric representations of images that is bigger, better-designed for VL tasks, and pre-trained on much larger training corpora that combine multiple public annotated object detection datasets is developed. Expand.
CCSS.ELA-Literacy.CCRA.R.7: "Integrate and evaluate content presented in diverse media and formats, including visually and quantitatively, as well as in words.". CCSS.ELA-Literacy.CCRA.R.6: "Assess how point of view or purpose shapes the content and style of a text.". CCSS.ELA-Literacy.CCRA.SL.1: "Prepare for and participate ...
This paper presents a detailed study of improving visual representations for vision language (VL) tasks and develops an improved object detection model to provide object-centric representations of images. Compared to the most widely used bottom-up and top-down model [2], the new model is bigger, better-designed for VL tasks, and pre-trained on much larger training corpora that combine multiple ...
At Iowa, Martin studies developmental neurolinguistics, particularly in young children who are bilingual in Spanish and English. His focus is on "numbers as language", and he examines the neurological impact and visual representation of shifting between the individual's multiple linguistic repertories through neurological imaging.
Traditionally, natural language processing (NLP) models often use a rich set of features created by linguistic expertise, such as semantic representations. However, in the era of large language models (LLMs), more and more tasks are turned into generic, end-to-end sequence generation problems. In this paper, we investigate the question: what is the role of semantic representations in the era ...
This paper presents a detailed study of improving visual representations for vision language (VL)tasks and develops an improved object detection model to provide object-centric representations of images. Compared to the most widely used bottom-up and top-down model [2], the new model is bigger,better-designed for VL tasks, and pre-trained on much larger training corpora that combine […]